







Web服务器收到客户端的http请求,会针对每一次请求,分别创建一个用于代表请求的request对象、和代表响应的response对象。
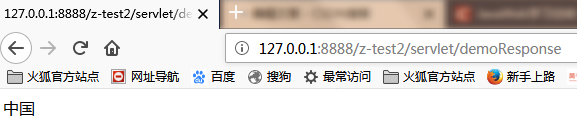
看一下结果:
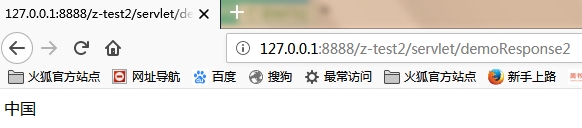
查看一下结果:
request和response对象即然代表请求和响应,那我们要获取客户机提交过来的数据,只需要找request对象就行了。要向客户机输出数据,只需要找response对象就行了。
一、HttpServletResponse对象常见应用
1.1、使用OutputStream流向客户端浏览器输出中文数据
public class demoResponse extends HttpServlet {
private static final long serialVersionUID = 4312868947607181532L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
outputChineseByOutputStream(response);//使用OutputStream流输出中文
}
/**
* 使用OutputStream流输出中文
* @param request
* @param response
* @throws IOException
*/
public void outputChineseByOutputStream(HttpServletResponse response) throws IOException{
/**使用OutputStream输出中文注意问题:
* 在服务器端,数据是以哪个码表输出的,那么就要控制客户端浏览器以相应的码表打开,
* 比如:outputStream.write("中国".getBytes("UTF-8"));//使用OutputStream流向客户端浏览器输出中文,以UTF-8的编码进行输出
* 此时就要控制客户端浏览器以UTF-8的编码打开,否则显示的时候就会出现中文乱码,那么在服务器端如何控制客户端浏览器以以UTF-8的编码显示数据呢?
* 可以通过设置响应头控制浏览器的行为,例如:
* response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据
*/
String data = "中国";
OutputStream outputStream = response.getOutputStream();//获取OutputStream输出流
response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
/**
* data.getBytes()是一个将字符转换成字节数组的过程,这个过程中一定会去查码表,
* 如果是中文的操作系统环境,默认就是查找查GB2312的码表,
* 将字符转换成字节数组的过程就是将中文字符转换成GB2312的码表上对应的数字
* 比如: "中"在GB2312的码表上对应的数字是98
* "国"在GB2312的码表上对应的数字是99
*/
/**
* getBytes()方法如果不带参数,那么就会根据操作系统的语言环境来选择转换码表,如果是中文操作系统,那么就使用GB2312的码表
*/
byte[] dataByteArr = data.getBytes("UTF-8");//将字符转换成字节数组,指定以UTF-8编码进行转换
outputStream.write(dataByteArr);//使用OutputStream流向客户端输出字节数组
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}看一下结果:
1.2、使用PrintWriter流向客户端浏览器输出中文数据
public class demoResponse2 extends HttpServlet {
private static final long serialVersionUID = 4312868947607181532L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
outputChineseByPrintWriter(response);//使用PrintWriter流输出中文
}
/**
* 使用PrintWriter流输出中文
* @param request
* @param response
* @throws IOException
*/
public void outputChineseByPrintWriter(HttpServletResponse response) throws IOException{
String data = "中国";
//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
//response.setHeader("content-type", "text/html;charset=UTF-8");
response.setCharacterEncoding("UTF-8");//设置将字符以"UTF-8"编码输出到客户端浏览器
/**
* PrintWriter out = response.getWriter();这句代码必须放在response.setCharacterEncoding("UTF-8");之后
* 否则response.setCharacterEncoding("UTF-8")这行代码的设置将无效,浏览器显示的时候还是乱码
*/
PrintWriter out = response.getWriter();//获取PrintWriter输出流
/**
* 多学一招:使用HTML语言里面的<meta>标签来控制浏览器行为,模拟通过设置响应头控制浏览器行为
* out.write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'/>");
* 等同于response.setHeader("content-type", "text/html;charset=UTF-8");
*/
out.write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'/>");
out.write(data);//使用PrintWriter流向客户端输出字符
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}查看一下结果:
注意点:
1)在开发过程中,如果希望服务器输出什么浏览器就能看到什么,那么在服务器端都要以字符串的形式进行输
出。如果使用PrintWriter流输出数字,那么也要先将数字转换成字符串后再输出。
2)文件下载注意事项:编写文件下载功能时推荐使用OutputStream流,避免使用PrintWriter流,
因为OutputStream流是字节流,可以处理任意类型的数据,而PrintWriter流是字符流,
只能处理字符数据,如果用字符流处理字节数据,会导致数据丢失。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









