









转载自:http://blog.csdn.net/wei_guo_xd/article/details/78579473

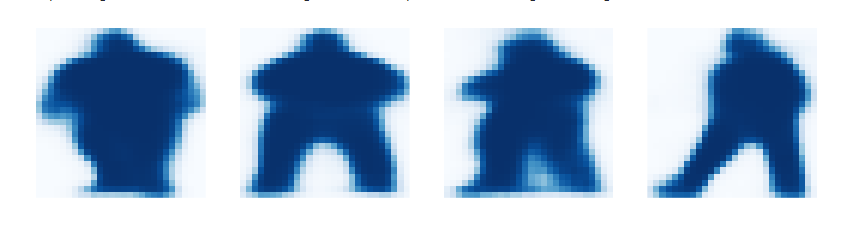

matterport/Mask_RCNN官方教程
这是一个基于python3,keras和tensorflow的mask rcnn模型。这个模型对图像中的每一个目标实例产生候选框和分割掩膜。这个模型基于特征金字塔网络(Feature Pyramid Network, FPN)和 一个ResNet101骨架。

这个版本包括:
- Mask R-CNN基于FPN和ResNet101创建的源代码.
- MS COCO的训练代码
- MS COCO的预训练模型
- jupyter notebook,里面包含了检测步骤的每一步的可视化
- 并行模型类用于多GPU训练
- 在MS COCO上的评价函数
- 用于训练自己的数据的例子
代码以文档形式呈现,容易拓展。如果你使用它们在你的研究当中,请考虑引用这个版本。如果你的研究方向是三维视觉,你可能发现我们最近发布的Matterport3D数据集也很好用。这个数据集收集于我们的愿意开源的客户,用于三维重建。
开始:
- demo.ipynb 最简单的开始方式。展示了使用一个在MS COCO上预训练的模型在你的图片上实现图像分割。包括了在任意图片上实现图像检测和实例分割的代码。
- train_shapes.ipynb 展示了怎么训练Mask R-CNN用自己的数据集。这个教程包括了一个玩具数据集来演示训练一个新数据集。
- model.py util.py config.py 这些文件包括主要的Mask RCNN实现。
- inspect_data.ipynb 这个教程展示了不同的预处理步骤来准备训练数据
- inspect_model.ipynb 这个教程深度解析了mask rcnn执行目标检测和语义分割的每一步。
- inspect_weights.ipynb 这个教程考察了训练模型的权重,寻找异常值和反常的模式。
一步步的检测:
为了帮助调试和理解模型,这儿有3个notebook(inspect_data.ipynb, inspect_model.ipynb, inspect_weights.ipynb) 提供一系列的可视化,允许我们一步步的运行这个模型,观察每一步的输出。下面是一些例子:
- anchor (候选区域)排序和筛选
可视化第一阶段候选区域产生网络(RPN)的每一步,展示正样本和负样本以及调整后的位置

2. 候选框精调
下图展示了一个例子,对于最终的检测结果(虚线),以及精调运用在它们上面(实线)。这是第二个阶段。
3.掩膜产生
产生的掩膜的例子,这些被尺度化接着放到合适的位置
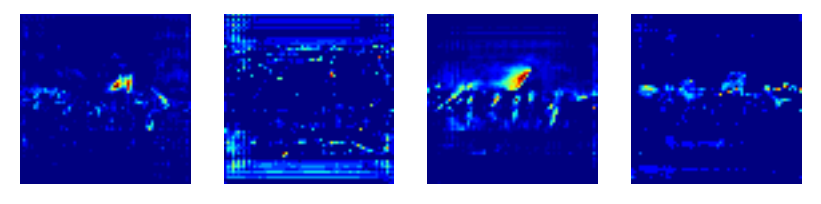
4.层激活
通常这是非常有利的,观察不同层的激活值,来寻找训练模型的错误(都是0值或者随机的噪声)
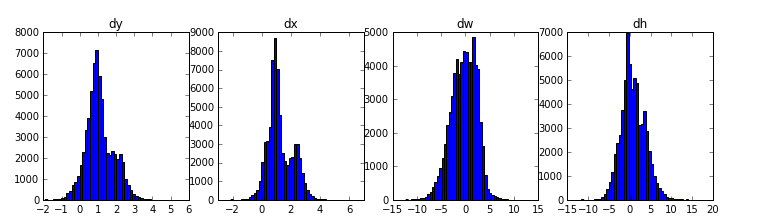
5.权重直方图
另一个有用的调试工具是观察权重直方图,这个在inspect_weights.ipynb教程里。
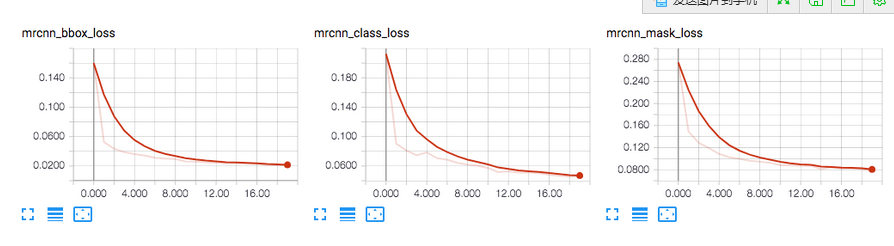
6. tensorboard训练日志
tensorboard是另外一个重要的调试和可视化工具。这个模块用来记录损失以及保存权重
7.组合不同的模块得到最终的结果
在MS COCO上训练:
我们提供了一个在MS COCO上预训练好的权重文件使得用户很容易开始。你可以使用这些权重作为一个起始点来训练你自己的模型。训练和评估代码在coco.py 。你可以导入这个模块在jupyter notebook 或者直接运行它们利用命令行向下面所示:
#训练一个新模型微调自预训练的COCO权重
python3 coco.py train –dataset=/path/to/coco/ –model=coco
#训练一个新模型微调自预训练的ImageNet权重
python3 coco.py train –dataset=/path/to/coco/ –model=imagenet
#继续训练一个模型利用你之前已经训练过的模型
python3 coco.py train –dataset=/path/to/coco/ –model=/path/to/weights.h5
#继续训练最后的模型,这个模块会找到最后训练出来的模型
python3 coco.py train –dataset=/path/to/coco/ –model=last
你也可以用以下代码评估COCO模型
python3 coco.py evaluate –dataset=/path/to/coco/ –model=last
训练设置,学习率以及其他参数在coco.py里面设置。
利用你自己的数据集训练:
为了训练你自己的数据集你需要修改下面两个类:
Config : 这个类包括了默认的配置,修改你需要改变的属性。
Dataset: 这个类使得你可以使用新数据集用于训练不需要改变模型的代码。它也支持加载多个数据集同时,如果你想检测的目标不是在同一个数据集里这会非常有用。
Dataset是一个基类。为了使用它,创建一个继承自它的新类,增加函数指向你的数据集。可以在util.py和train_shapes.ipynb和coco.py里看它的用法。
和官方论文的差别:
这个版本大部分和官方论文一样,但是也有一部分我们做出了修改,为了代码的简便和通用性。下面是一些我们知道的区别。如果你遇到了其他不同的地方,请让我们知道。
- 图像尺度变换:为了支持在每一个批次当中训练多幅图像,我们把所有图像都变换到了同一尺寸。例如,1024像素*1024像素的MS COCO图像。我们保留了这个纵横比,所以如果一副图像不是正方形的,我们会在周围补上0.在这篇文章里采样是遵循这样的原则:最短边是800像素,长边调整为1000像素。
- 边界框: 一些数据集提供边界框,另外一些仅仅提供掩膜。为了支持在多元数据集上进行训练,我们选择忽视来自于数据集的边界框,利用我们的模型自动产生它们。我们选择包括掩膜所有像素的最小框作为目标的边界框。这样就可以简化实现,同时也使得图像增强更加容易实现,有些图像增强方式在边界框上难以实现,例如图像旋转。为了验证我们的方法,我们和COCO数据集提供的边界框进行了比较。我们发现大约2%的边界框相差了1个像素或者更多,0.05%的边界框相差5个像素或者更多,0.01%的边界框相差10个像素或者更多。
- 学习率:这篇文章使用了0.02的学习率,但是我们发现这太大了,经常导致权重扩散,尤其当使用一个小batch size。这可能是由于caffe和tensorflow计算梯度的方式不一样(求和vs平均,沿着不同batch和gpu).或者,官方模型使用了梯度裁剪来避免这个问题。我们没有使用梯度裁剪,也没有把这个值设得特别大。我们发现更小的学习率收敛得更快,我们我们使用了更小的收敛率。
- anchor 滑动幅度:特征金字塔的最小层有一个4像素的滑动幅度相对于输入图像,所以anchors每隔4个像素被产生。为了减少计算和内存占用,我们采用了2个像素的滑动幅度,以此来减少4倍的anchor数目,同时对精度没有显著的影响。
贡献:
对这个版本的贡献会很受欢迎。你可以做的贡献的例子如下:
- 速度的提升。例如重写一些tensorflow或者cython里的python代码。
- 在替他的数据集上训练。
- 精度上的提升。
- 可视化以及例子。
你也可以加入我们团队,帮助构建更多项目。














 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









