







Apriori算法
第一次写博客,看这个算法的目的是为毕设开题做准备,以及以后的复习所做的笔记。Apriori属于无监督学习,对数据关联规矩进行挖掘的算法。
关联规则是形如X ⇒ Y的蕴含式,其中X,Y分别是I的真子集,并且X ∪ Y= ∅ 。X称为规则的前提,Y规则的结果。关联规则翻译X中项目出现时,Y中的项目也跟着出现的规律。 —— 《数据挖掘算法原理与实现》
1.Apriori算法的预备知识
关联的支持度:
关联规则的置信度:
最小值支持度:关联规则的最低重要程度 (自己确定的阈值。)
最小置信度:关联规则必须满足的最低可靠程度。
tips:
1.统计学核心:用样本估计总体。
2.95%的几率落在50%到60%之间,95%为置信度,又称置信水平,(50%-60%)为置信区间。
参考:https://www.zhihu.com/question/26419030?sort=created
2.Apriori算法过程
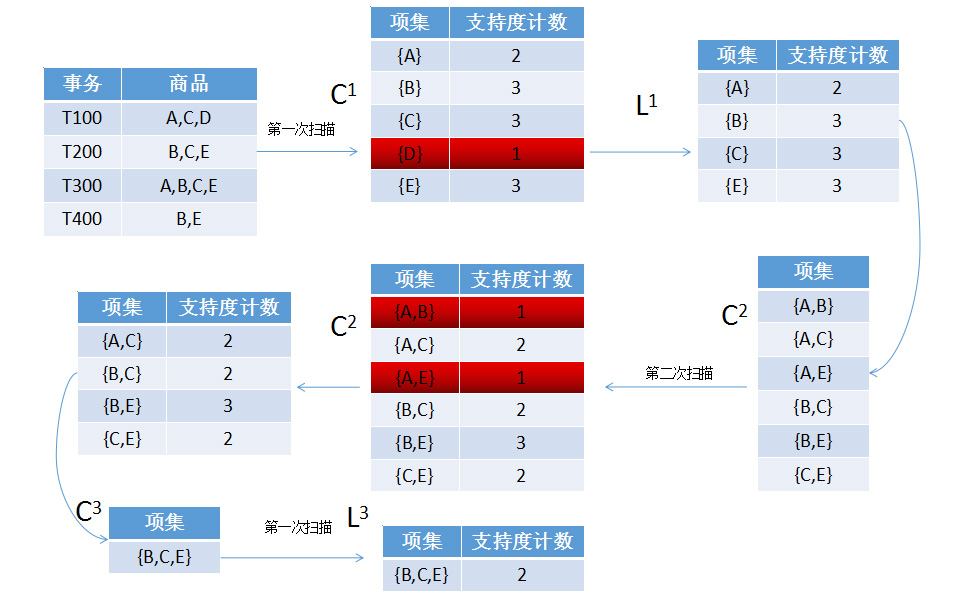
以上图为例:数据库中存储的商品订单,事务即订单ID,商品用A,B,C,D等来表示,最小支持度为2首先进行第一次对订单数据的扫描,(第一次的扫描和后几次的是不太一样的),以项集为单位,支持度为项集中的商品在订单中同时出现的次数,即项集中商品的关联度。然后发现{D}的支持度为1小于2,所以删除(这个步骤叫做剪枝步)。然后,集合L 1 与自身做连接产生下一个集合C 2 (这个步骤叫做连接步)。在剪枝步和连接步中有两个重要的概念:
频繁项集:如果项集的相对支持度满足预定义的最小支持度阈值,则I是频繁项集。(其中项集是按照从小到大的顺序排列的)。
项目集空间理论核心:频繁项目集的子集仍是频繁项目集;非频繁项目集的超集是非频繁项目集。
连接步的步骤:如果项集的前K-2个项相同,则可以连接,连接的结果为两个项集的并集(K为第K次扫描的K)。
剪枝步的步骤:根据上面的第二个概念中的“非频繁项目集的超集是非频繁项目集”删除项目集,which子集包含非频繁项目集(即图中标红的项集),然后删除支持度小于2的项集。
然后连接步,剪枝步,进行迭代,直到L为空。
核心:使用候选项集寻找频繁项集(方法:连接步,剪枝步)。逐层搜索,迭代。
Apriori算法描述
输入:数据库D,最小支持度阈值min_sup。
输出:D中的频繁项集。
(1)Begin
(2)L
1=1
-频繁项集;
(3)for
(k=2;Lk−1≠∅;k++)
do begin
(4)
Ck−1=Apriori
_
gen(Lk−1)
; { 调用函数
Apriori
_
gen(Lk−1)
通过频繁(
k−1)
- 项集产生候选
k
- 项集}
(5)for所有数据集
(6))
(7)for所有候选集
c∈Ct
; do
(8)
c.count++
;
(9)end;
(10)
Lk=
{
c∈Ct|c.count≥min
_
sup
}
(11)end
(12)end
(13)
Return
L1∪L2∪Lk∪…∪Lm















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









