






为了搞清楚transformer中哪些参数需要做微调可以影响整个模型输入输出,这里我们基于Vision transformer来对transformer的工作过程进行详细的说明,方便后续以代码的形式进行调参设计。这里我们进入 Vision Transformer (ViT) 的世界,通过写一个完整的、简化版的 Vision Transformer 模型,从图像输入开始,一步一步走到分类输出结果来详细的解释transformer的原理及参数要如何进行微调和定义。整个transformer的工作过程主要参照以下几个步骤进行:
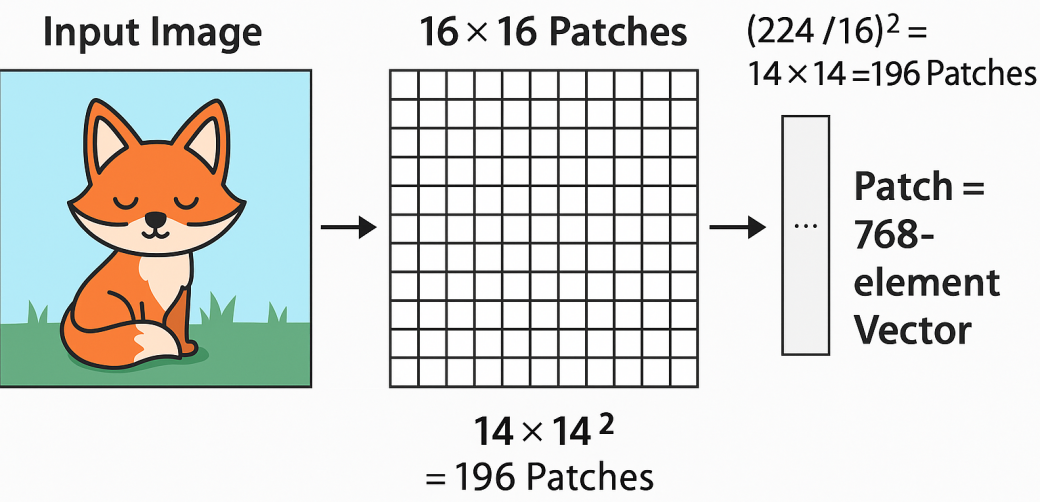
step1:以当前 Patch 为中心进行图像切分
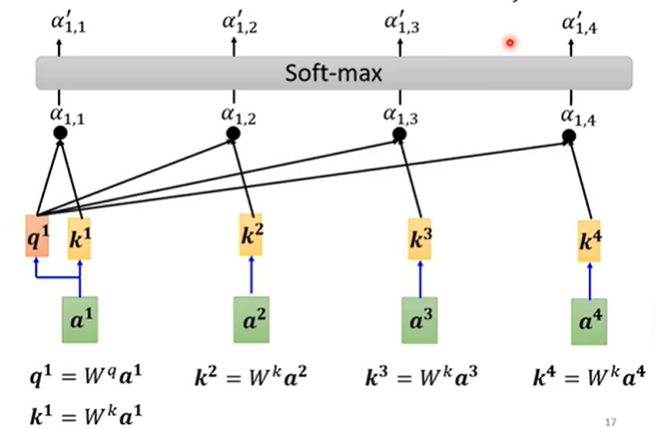
在 Transformer 中,每个 Patch 都会生成 Query (Q)、Key (K) 和 Value (V),这些信息分别来自于每个 Patch 的表示。
比如输入图像是 224×224×3,切成 16×16 的 patch 后,有 (224/16)^2 = 14×14 = 196 个 patch。每个 patch 是 16×16×3 = 768 个像素值。
step2:计算相似度
当前 Patch 使用自己的 Query (Q) 和其他所有 Patch 的 Key (K) 进行比较。这个比较通常是通过计算 Q 和 K 的点积来获得它们的相似度。如果某个 Patch 的 Key 和当前 Patch 的 Query 非常相似,说明这两个 Patch 之间的关系很强,它们的信息会更多地参与到最终的聚合过程中。
step3:加权聚合
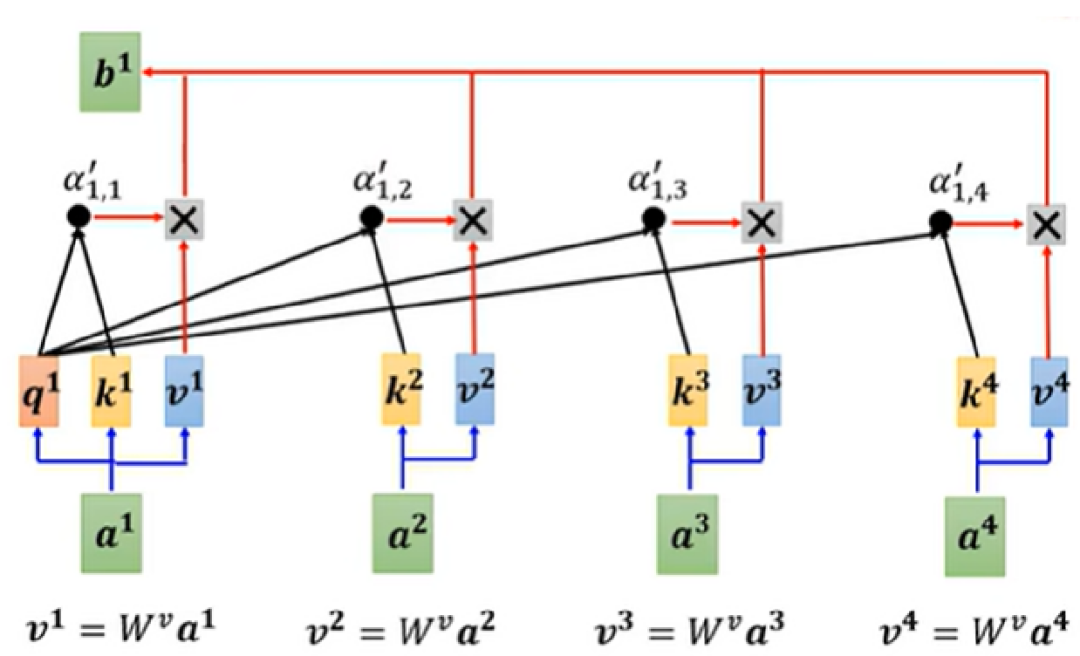
根据计算得到的相似度(注意力权重),Value (V) 中的信息会按照这些权重进行加权和汇聚。高相似度的 Patch(即 Query 和 Key 的点积较大)会给予更大的权重,它们的 Value 信息会在聚合过程中占有更大的比重。低相似度的 Patch则会给予较小的权重,它们的 Value 信息在聚合过程中影响较小。
step4:拼接和聚合
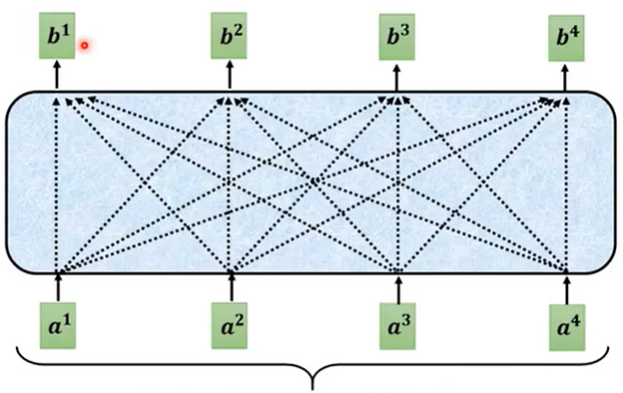
最后,在多个头的情况下,每个头都会根据自己的权重矩阵计算一组加权后的 Value 信息。这些加权的 Value 信息(来自每个头)会被拼接在一起,形成一个包含了所有头信息的最终输出。这个输出会通过后续的网络层进行处理。
1、Transformer架构中的关键参数调节
针对具体到内部的Vision Transformer的参数微调,首先,我应该确认Transformer的主要可调参数。常见的参数包括如下三类:模型架构相关参数、训练参数、数据处理参数。其中,训练参数包括批次大小(batch size)、学习率、模型参数丢弃率、优化器类型选择等。这些和之前大模型基础参数调节类似,文本不在这里做赘述。而是主要关注从transformer本身的模型架构相关的参数进行说明。
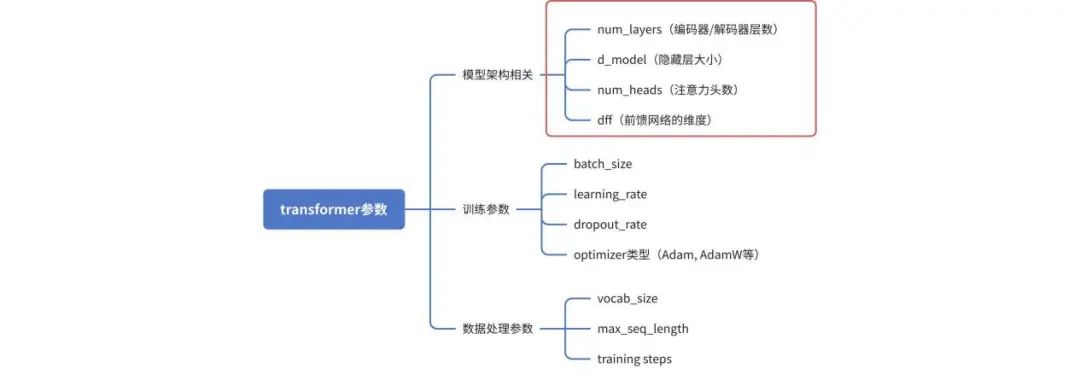
当然也还有其他可能的参数,比如使用位置编码的方式、标签平滑等。这里我们通过简洁的例子,选择最核心的几个参数来做transformer调优,从而充分说明其工作原理即可。
接下来,我们确认在kaggle上采用感知常用的PyTorch框架。同时,要能通过改变参数进行分析对比,可能需要用到网格搜索或随机搜索。这里我们仍旧应用到GPU云资源上进行参数调优,由于Kaggle的运行时可能资源有限,不能进行大规模的超参数调优,所以需要选几个关键参数进行简单比较。比如如下简单的Vision Transformer中,主要通过初始化transformer的函数进行传参。

2、基于patch size拆分大小进行fine tunning
在讲清楚patch size的调节之前,我们需要白话Vision Transformer工作时的patch拆分原理。
2.1.1、输入图像 → 切分成 patch;
如下图表示一种patch的不同大小拆分及相关热图的示意图:
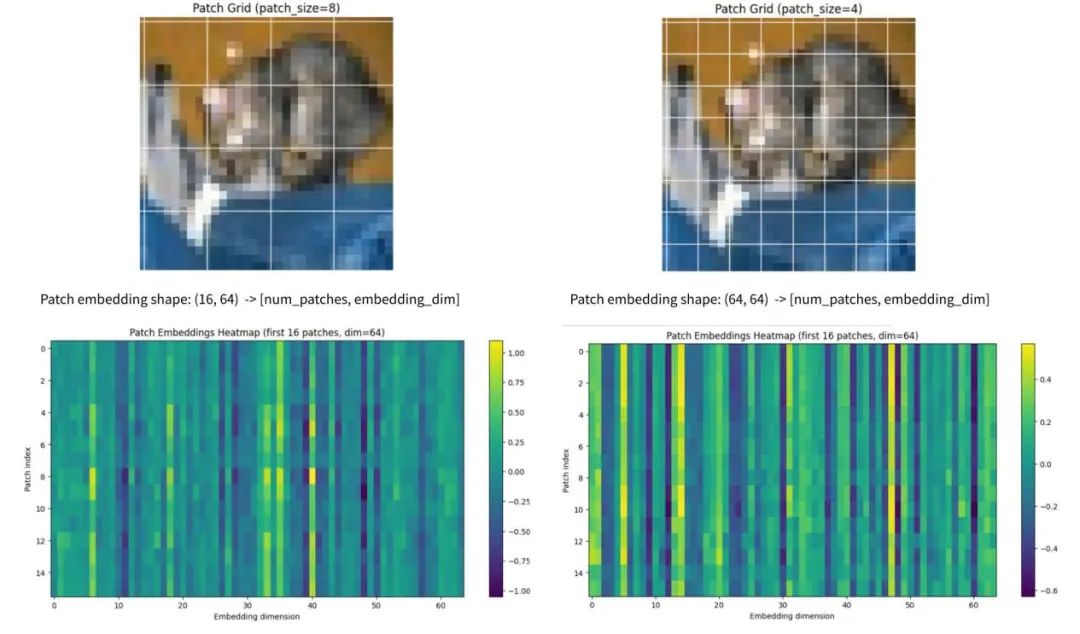
2.1.2、每个 patch → 映射成一个向量(embedding);
每个 patch 展平成一维向量后(shape: 768),通过一个线性层(通常是 nn.Linear(768, hidden_size))映射到 transformer 的隐空间维度。实际上V ≈ 图像中各 patch 的语义特征表达。
Embedding[0,1,2...,n] =
[patch_1: [0.2, 0.8, 0.1], # 比如偏重纹理信息
patch_2: [0.6, 0.1, 0.3], # 偏重颜色
patch_3: [0.3, 0.4, 0.9]] # 偏重边缘
......
patch_n: [0.3, 0.4, 0.9]] # xxx
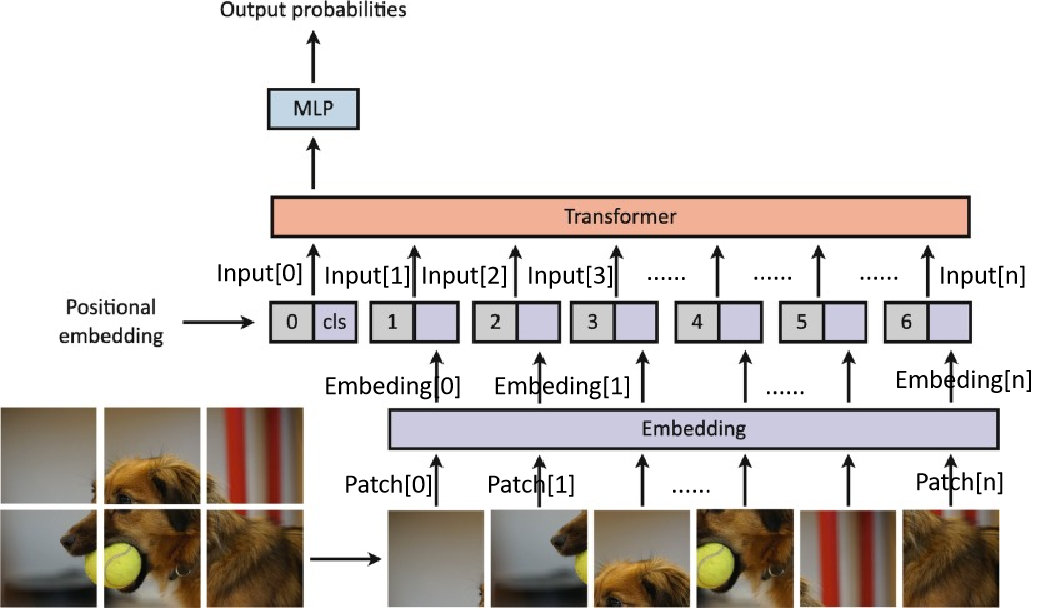
最终输入编码:
Input[0]=Embeding[0]+Position[0];
Input[1]=Embeding[1]+Position[1];
......
Input[n]=Embeding[n]+Position[n];
后面我们会详细介绍,这些input如何进行注意力的计算。
2.1.3、Input(Embedding+Position) → 线性变换 → 得到 Q、K、V;
Q = X * W_Q + b_Q
K = X * W_K + b_K
V = X * W_V + b_V
X 是 embedding 后的 patch 序列Input,shape 为 [num_patches, d_model]。W_Q, W_K, W_V 是可训练的矩阵,初始化为随机值,随着训练不断更新。学习过程:通过反向传播获得最优 Q/K/V 映射。整个过程如下:
初始时,W_Q, W_K, W_V 是随机初始化的。模型根据预测结果计算 loss(例如分类误差)。反向传播算法会将损失函数关于每个权重矩阵的梯度反向传导回来,更新权重。
W_Q ← W_Q - learning_rate * ∂Loss/∂W_Q
W_K ← W_K - learning_rate * ∂Loss/∂W_K
W_V ← W_V - learning_rate * ∂Loss/∂W_V
这里我们需要重点说明一下这个输入token变换到权重W_Q、W_K、W_V 是 可学习的线性变换权重矩阵,它们在模型训练过程中通过反向传播算法自动学习得到。随着迭代,W_Q/K/V 学会如何将每个 patch 表示映射为适合注意力机制的 Query、Key 和 Value。因此,可以说transformer更新注意力权重的过程就是我们常见的神经网络前向传播和反向更新权重的过程。W_Q、W_K、W_V 是全连接层的权重参数,通过模型训练使用梯度下降自动学习得出,目的是生成能够有效进行注意力计算的向量表示。

Query (Q):是当前 Patch(比如图像的某个区域)需要关注的对象(或者说它想要从其他 Patch 中获取的信息)。
Key (K):是其他所有 Patch 的特征信息,它们提供了与 Query 的相似度比较。
Value (V):这里可以将 Value (V) 理解为 Patch 的内容信息。在图像任务中,这通常是图像块的像素信息,或者是经过卷积神经网络提取出来的特征表示。在每个头的聚合过程中,最终会得到一个新的表示,它融合了多个 Patch 之间的关系和各自的特征信息。
如果是多头注意力,会将 Q、K、V 划分为多个 head,d_head = hidden_dim // num_heads 是每个头的维度(比如 hidden_dim=512,num_heads=8,d_head=64)。
讲到这里,我们可以开始对transformer做第一步参数调优了。
2.1.4 基于patch size拆分大小进行fine tunning

如下是基于不同patch size拆分大小所运行的结果。
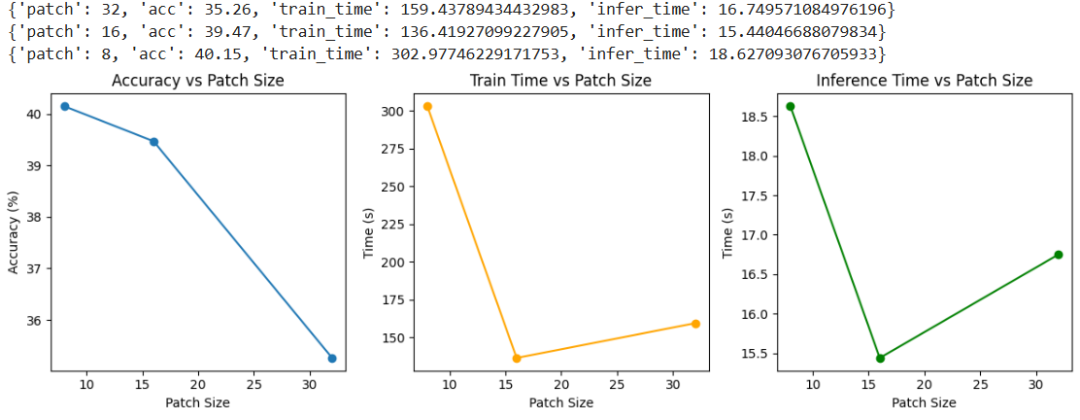
基于如上图所示,我们可以得出如下分析:
(1) 精度 acc 随 patch 变小而提升
Patch 越小 → 每张图被切得越细 → 能保留更丰富的局部细节 → 模型学习能力增强。所以 acc 从 35.26(patch=32) 提升到 40.15(patch=8)是合理的。
(2)训练时间与 patch size 的关系
patch 越小 → 输入 token 越多 → self-attention 的计算复杂度为 O(N^2),N 为 patch 数量。所以训练时间从 patch=16 的 136 秒增长到 patch=8 的 302 秒,符合预期。patch=32 看起来训练时间略高于 patch=16,可能受到了 batch size、I/O 或其他训练开销影响(合理波动)。
(3)推理时间也随 patch 变小略有上升
同样道理,token 数变多 → 推理时的计算也更多。patch=8 的推理时间比 patch=32 增长约 2 秒,符合预期。
从如上分析可知,图像的 patch 拆分方式直接决定了 ViT 的表示能力与计算复杂度。最佳的 patch 大小应根据任务场景、数据特点和硬件资源权衡选择。默认的 16×16 通常是一个合理起点,但可以通过实验进一步调优。
在资源受限或追求最优性价比的场景(如边缘设备部署、自动驾驶、机器人等)下。要找到 patch size 与计算时间、精度之间的最佳平衡点,本质上就是一个多目标优化问题,你需要综合考量精度(Accuracy)、训练/推理时间(Efficiency)、资源消耗(Memory/Compute)。比如根据任务场景选择最优 compromise:如果在服务器端训练为主,关注精度 → 小 patch 更好,如果部署在端上、关注实时性 → 较大 patch 更实用。
3、Transformer 头数 (num_heads)的FineTunning
我们知道,在transformer中,主要是通过划分不同的注意力头来实现对应的图像patch的关系映射,这样通过QKV矩阵查询就可以很快的定位到与当前patch最相近的patch了。因此,基于这样的核心思想,我们设置关于patch的不同划分原则,这就可以看成是head的划分。
如下图表示了整个transformer的参数调节及组合关系:
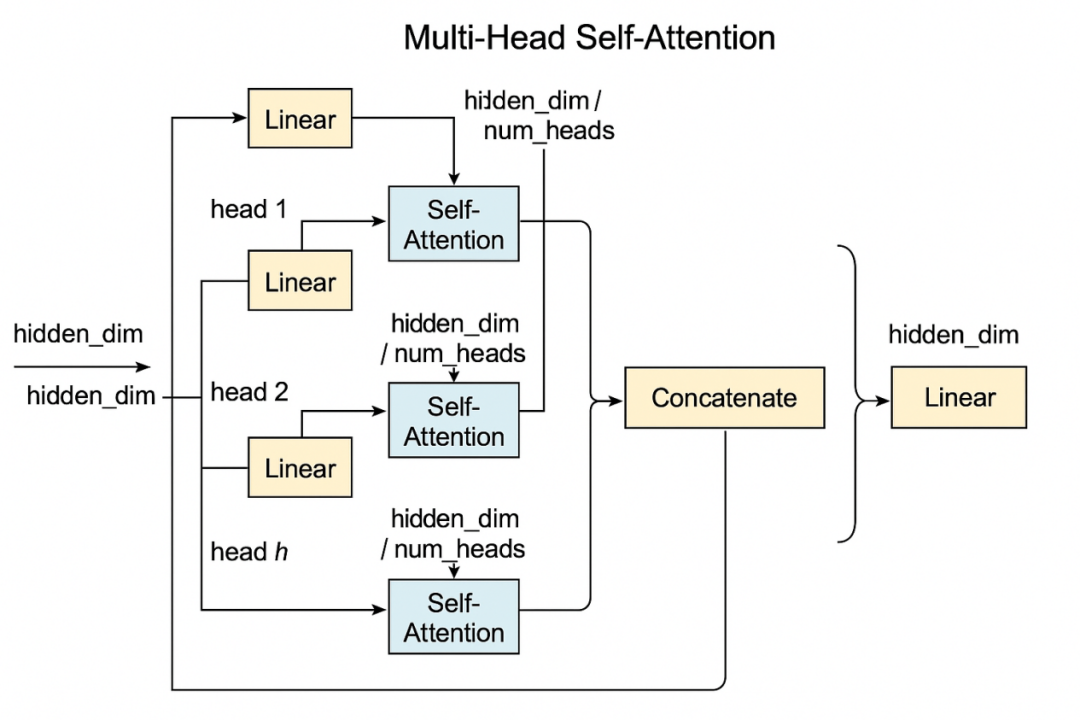
实际上,Transformer 本身不做特征提取,它处理的是已编码好的“patch token”之间的关系!这里基于一个简化版 Transformer 架构,主要用于对比隐藏层/多头结构对模型计算复杂度和性能的影响。
这里需要说明:
head_size与hidden_dim之间有如下关系:
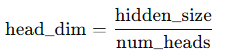
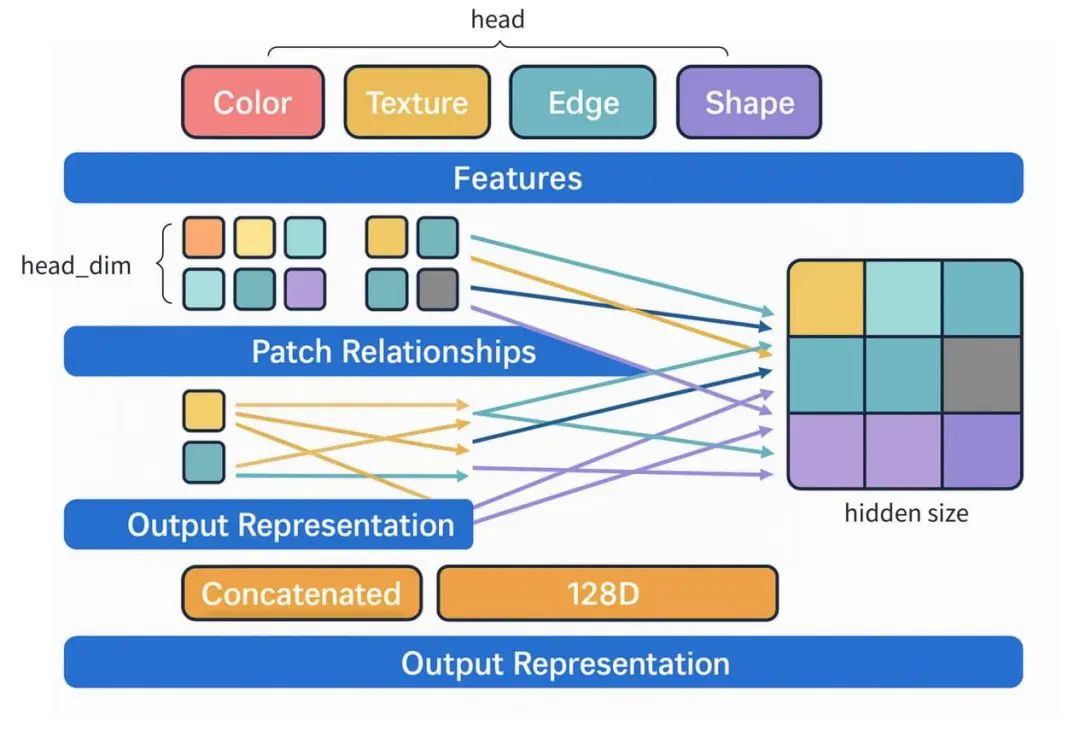
最后再将多个 head 的输出拼接起来,送入一个线性层:
![]()
调整 Transformer 中多头自注意力的头数 (num_heads) 或隐藏层维度 (hidden_dim),从而影响计算复杂度。原则上,hidden_dim 越大,模型越复杂,参数和计算量越多,精度可能只是略有提升。num_heads 不能超过 hidden_size,否则会报错。使用 thop.profile 获取 FLOPs(或 MACs)和参数量。在小数据和轻量模型上可快速评估趋势。
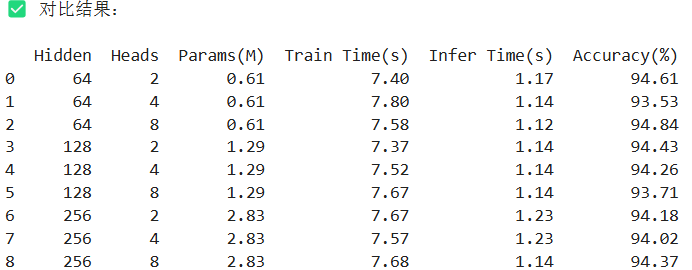
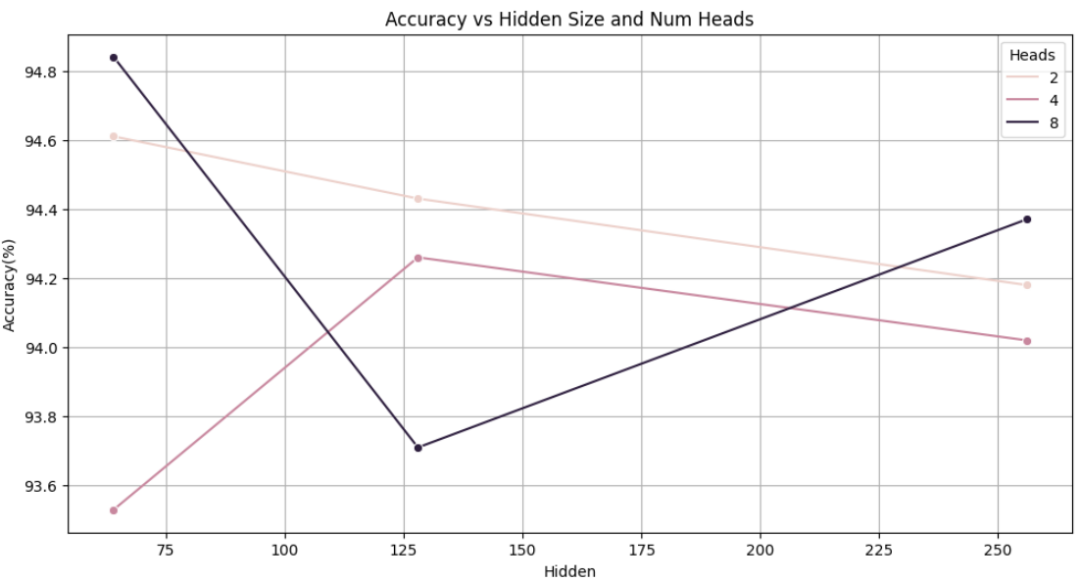
(1)模型参数量 (Params)
同一 hidden_size 下,无论 num_heads 取 2、4 还是 8,参数量保持不变。这是因为 num_heads 只是将 hidden_size 拆分成多个部分,并不增加整体维度,所以不会显著增加参数。hidden_size 提高,则参数量相应上升(从 0.61M → 1.29M → 2.83M)。
说明:参数量与 hidden_dim 成正比,和 num_heads 几乎无关。
(2)训练时间 (Train Time)
所有训练时间都集中在 7.3 - 7.8 秒之间,说明训练过程已经足够短,不足以形成太大的性能瓶颈。hidden_size 提高时,训练时间稍微增加,但浮动范围不大。多头对训练时间影响也不大,说明模型并未因为多头带来明显的额外计算负担。
说明:在小模型 + 小数据量下,训练时间并非关键瓶颈。
(3)推理时间 (Infer Time)
推理时间集中在 1.12s - 1.23s,略随 hidden_size 增长而增加。num_heads 数量变化对推理时间影响几乎可以忽略。
说明:模型推理效率对 hidden_dim 敏感,但对 num_heads 不敏感。
(4) 精度 (Accuracy)
这是最关键的维度之一,规律和趋势如下:
在 hidden_size = 64 时,随着 head 数增加,准确率总体略有提升,尤其是从 head=2 到 head=8(93.5% ➝ 94.8%)。在 hidden_size = 128 时,精度略有下降趋势(94.4% ➝ 93.7%),说明模型可能出现轻微过拟合或不稳定。hidden_size = 256 时,精度基本稳定(94.0~94.3%),但并未因为更大的维度而带来显著提升。
说明:增加 num_heads 有助于捕捉更多多样化的注意力模式,有时会提升性能。但若 hidden_size 太小(如 64),拆分成过多 heads 会导致每个 head 的维度太小(如 64 / 8 = 8),造成表示能力不足。若 hidden_dim 太大,模型虽表达力强,但也可能导致冗余或过拟合。
因此,建议如果是在一个计算资源敏感的系统上部署(比如边缘设备),hidden_size=64, heads=2~4 是性价比很高的选择;如果追求最优精度,不介意训练时间和参数,hidden=64~128, head=8 是不错的方向。多头的效果不是线性提升的,它依赖于合适的 hidden_size 来支撑其表达能力。
4、前馈网络FFN的维度mlp_dim调节
Transformer 的 FFN 就是「对注意力计算后每个 token 的结果做一次小型的全连接神经网络」处理,使模型在捕捉 token 之间依赖的基础上,还能进一步提取每个 token 自身更深层的语义或图像特征。
Transformer 中的前馈网络(FFN)本质上与传统神经网络中的前向传播原理相同,区别只是:

设定 token 特征维度(hidden_dim) ⟶ 决定每个 head 的维度 ⟶ 给定 num_heads 后确定 hidden_size ⟶ 决定 token 向量维度 ⟶ 决定前馈网络输入/输出维度 ⟶ 决定 mlp_dim(一般是其 2x 或 4x)
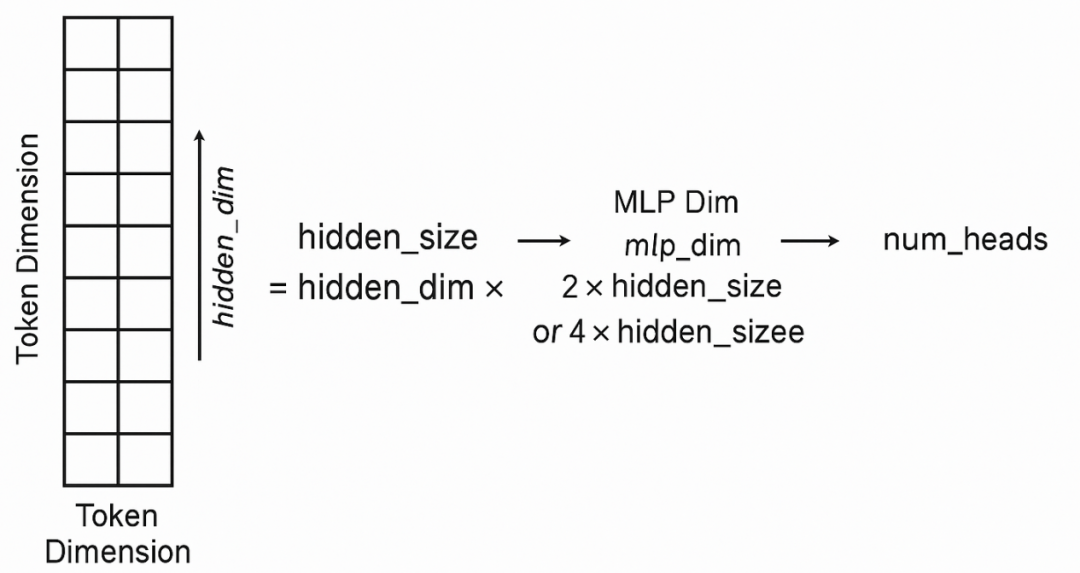
(1)hidden_size = hidden_dim × num_heads:
每个 head 的维度是 hidden_dim,总共 num_heads 个 head ⟶
所以整个输入 token 的维度必须是 hidden_size = hidden_dim × num_heads;
(2)token 的维度 = hidden_size
Transformer 中每个输入 token 的向量维度就是 hidden_size,也就是输入到 Q/K/V 的维度。Q/K/V 线性层、Attention 输入输出、LayerNorm 输入输出、Residual Add 等都基于这个维度工作。
(3)MLP 的中间维度(mlp_dim)是 hidden_size 的某个倍数
mlp_dim = 2 * hidden_size 或 4 * hidden_size 是常用经验值。所以,一旦你确定了 hidden_size,那就可以据此设定 mlp_dim。
5、Transformer 编码器/解码器层数 num_layers
ViT 模型中的编码器/解码器层数 num_layers 对应 nn.TransformerEncoderLayer 的堆叠次数。与token维度的关系中,有经验上的共同增长规律(层数越多,token维度越大,模型更稳定、更强)。num_layers 通常影响模型深度,深度增加 → 表达能力增强,但计算开销和过拟合风险也增加。
用较大的 hidden_dim 却使用较浅编解码层数,可能无法发挥模型的表达潜力。num_layers 的设计在实践中大多是基于经验和调研结果,再结合任务特点进行微调,而不是通过某个明确的理论公式推导得到。可以理解为它属于超参数中的结构超参数。比如,num_layers与hidden_dim虽然没有硬性绑定关系,但通常经验如下:
•hidden_dim = 512 → num_layers = 6~8
•hidden_dim = 768 → num_layers = 12
•hidden_dim = 1024 → num_layers = 24
这里我们通过实验设计不同的num_layers=[2,4,6],得出整个transformer的模型精度、训练和推理时间如下:

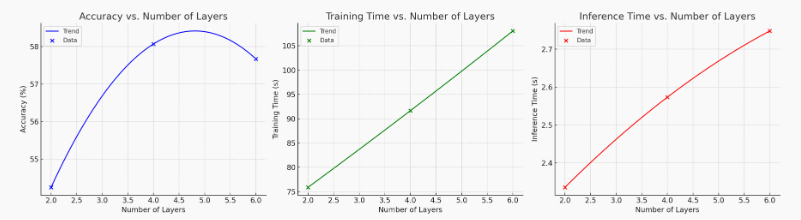
从运行结果看出,训练/推理时间随层数线性增长近似成立:每多加一层 Transformer Block,参数量、计算量成线性增加,因此训练和推理时间大致按线性或次线性增长。而精度增长不是线性的:前期提升明显(如从 2→4 层),因为模型有更强表征能力,后期趋于饱和甚至下降(4→6层略降)。有可能是数据较少或模型太大导致过拟合,学习率未匹配更深网络,epoch 设置不足以训练更多层,层间权重更新干扰导致不收敛。
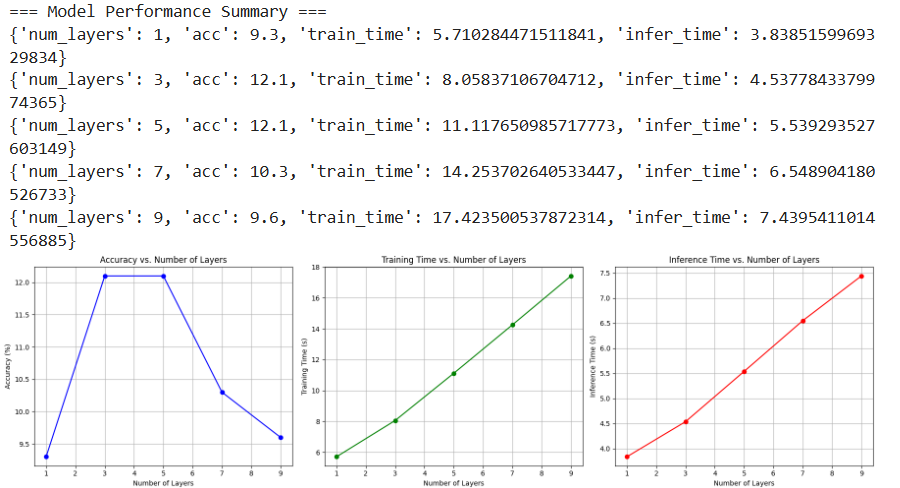
如果想要找到最佳编解码层,那么需要设置更多的num_layer来寻找最佳值。如下表示了分别设置num_layer为1,3,5,7,9层所带来的精度结果和对应的时间消耗。从下图中可以看出,整个编解码层数的设计在3-5之间可以实现精度最优。再加大num_layer层,则不一定会进一步增加检测精度,甚至会引起精度降低。这样通过类似抛物线的最高点,就可以找到最优的num_layers设置区间为3~5。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









