






💖前言
在如今的数据驱动时代,数据获取已成为各类应用和分析的核心组成部分。无论是股市行情、社交媒体动态,还是AI模型训练,都离不开大量数据的支持。从我个人的经验来看,数据采集无疑是其中最具挑战的一环。我曾尝试分析评论情感倾向在不同时段、不同事件或话题下的变化趋势,并探究情感波动的背后原因。为了完成这一任务,我需要收集超过100万条的数据,而其中最难的部分无疑是编码部分——需要处理各种复杂情况并应对反爬机制。
今天,我们来聊一聊如何使用API进行数据采集。即使是零代码基础的伙伴,也能轻松上手哦!
一、💫爬虫为什么难?
爬虫开发并不简单,主要因为它面临着多个挑战。许多网站设置了反爬虫机制,如IP封禁、验证码验证和JavaScript动态加载等,开发者需要使用代理IP池或模拟用户行为来绕过这些防护。大多数网站结构不稳定,HTML标签和页面布局经常变化,导致爬虫需要不断调整抓取规则。爬虫也有可能涉及合法性问题,必须遵守目标网站的政策和法律规定。这使得爬虫的开发像是一场“打怪”之旅,需要不断克服障碍,才能稳定地采集到有效的高质量数据。
二、💫采集API介绍
API(Application Programming Interface,应用程序编程接口)是网站或应用提供的一种数据交互方式。通过API,开发者可以直接向网站服务器发送请求,并获得结构化的数据(通常是JSON或XML格式)。这一过程更加规范、稳定且通常更高效。
优点:
数据结构化:API通常返回结构化的数据,易于解析和处理。
稳定性和效率:API的调用通常是官方支持的,稳定性较高,数据更新也比较及时。
合法性:使用API获取数据通常是符合网站使用规定的方式。
无页面解析:不需要解析HTML页面,避免了网页抓取中可能遇到的HTML结构变化问题。
最近使用了一个非常简便的高级爬虫工具——亮数据的Scraper APIs,它提供了一种爬虫接口,能够绕过IP限制、验证码和加密等问题。用户无需编写反爬虫机制或动态网页处理代码,而且后续不需要任何维护,便可以轻松获取Tiktok、Amazon、Linkedin、Github、Instagram等全球主流网站的数据。对于那些代码基础较弱或不想投入大量时间编写爬虫程序的用户来说,这无疑是一个极为便捷的解决方案。
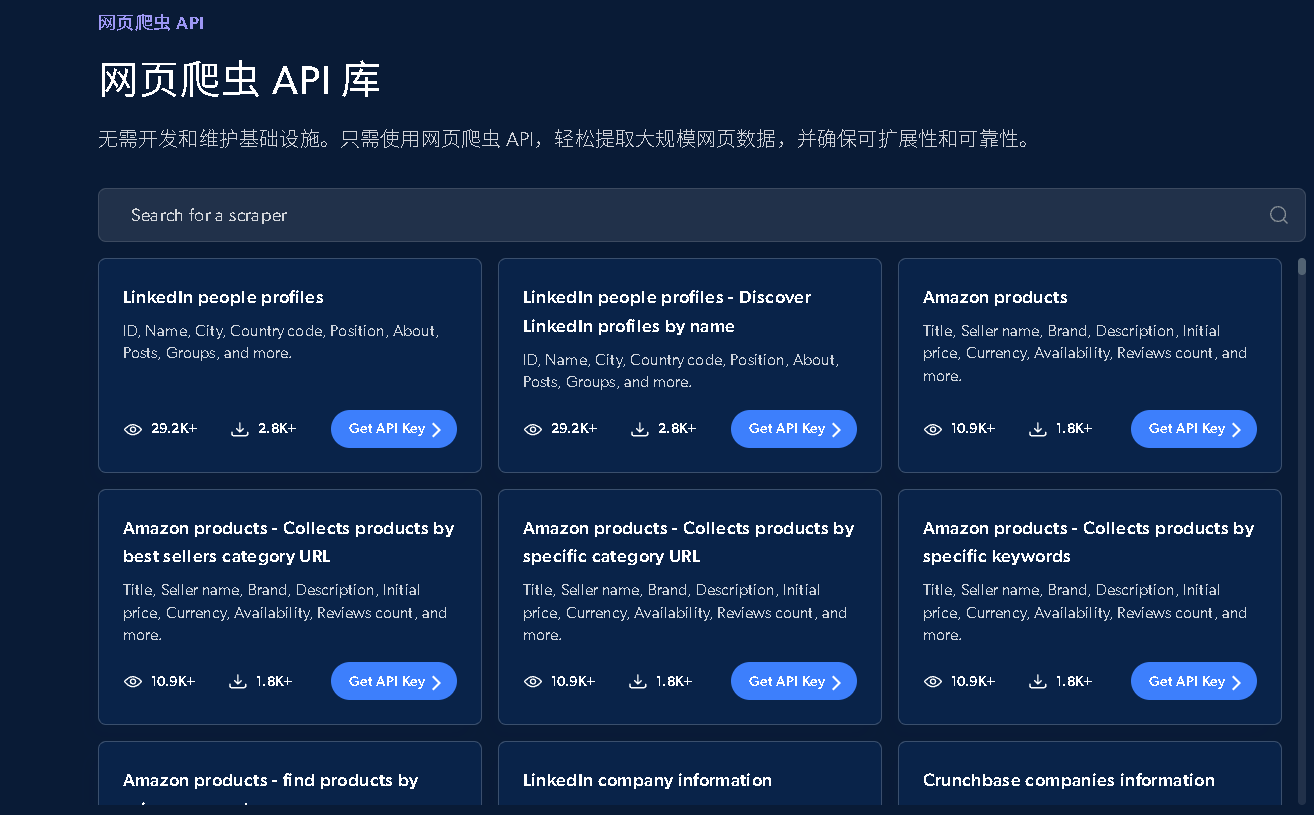
三、💫如何使用Scraper APIs?
Scraper APIs是亮数据专门为批量采集数据而开发的接口,支持上百个网站,200多个专门API采集器。下面我们开始实战演示使用Scraper APIs,非常简单。
✏️无代码抓取器方式
1、首先是 注册登录。
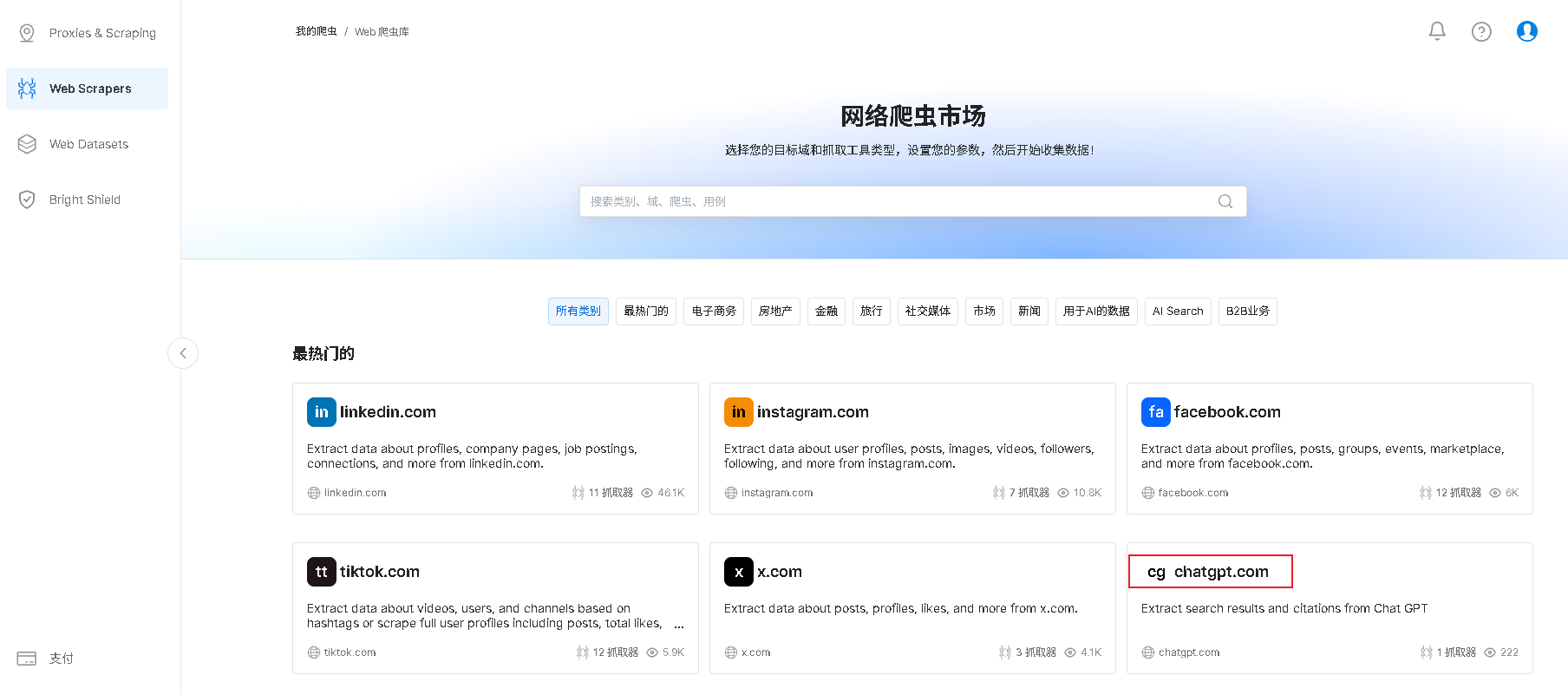
2、登录后点击Web Scrapers栏目进入网络爬虫市场,如下图:
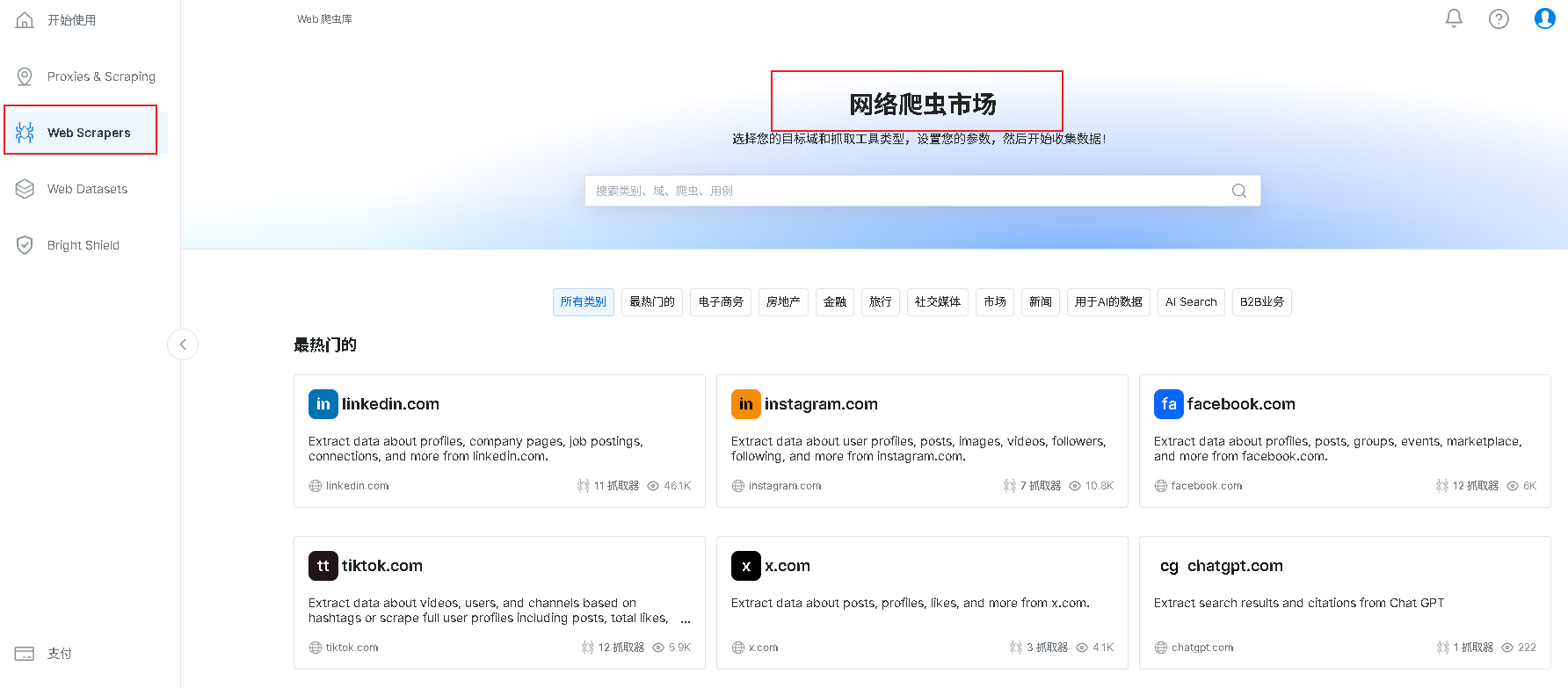
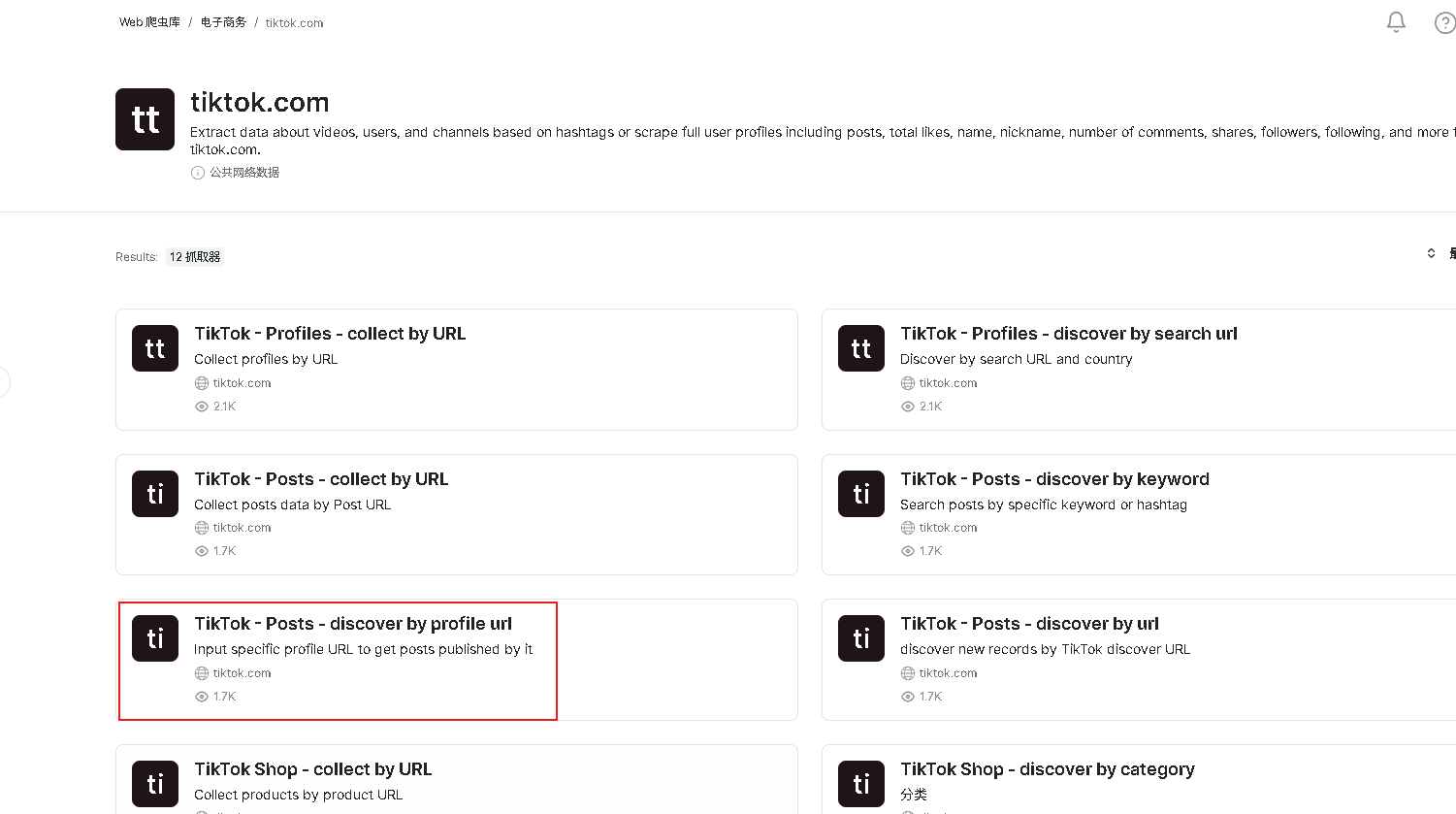
3、在网络爬虫市场你能看到各种网站的API数据采集器,下面就以Tiktok为例讲下采集器的使用。首先点击tiktok.com,进入Tiktok API界面,会有各种各样数据类别采集器,包括电商商品、短视频、评论等。
我们这里选择TikTok - Posts - Discover by Profile URL 通过个人资料网址抓取相关作品信息。
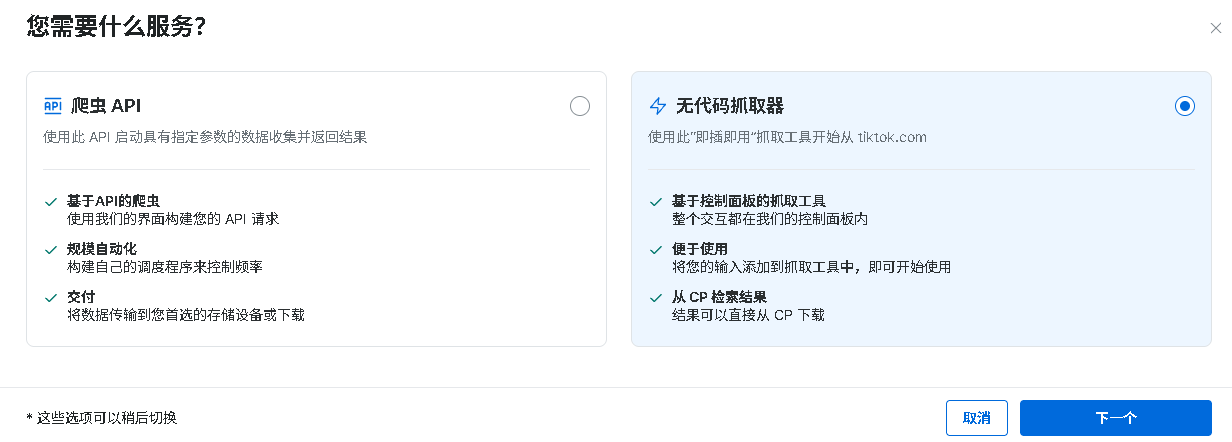
4、点击后会有两种使用方式,各有各的优点,适配不同场景,首先我们先介绍一下无代码抓取器,顾名思义不需要编写任何代码,整个过程直接在官方服务器内部进行处理,我们只需要传递相关信息即可。
5、点击无代码抓取器后,开始进行配置相关信息,其中url是必填项,必须是个人资料的网址,其他的都是可选的,可以在num_of_posts中设置爬取帖子的数量,posts_to_not_include和start_date、end_date设置进行进行排除结果,what_to_collect选择要收集的内容类型:帖子、转发、两者或点赞的帖子,post_type选择视频帖子或是图片帖子。
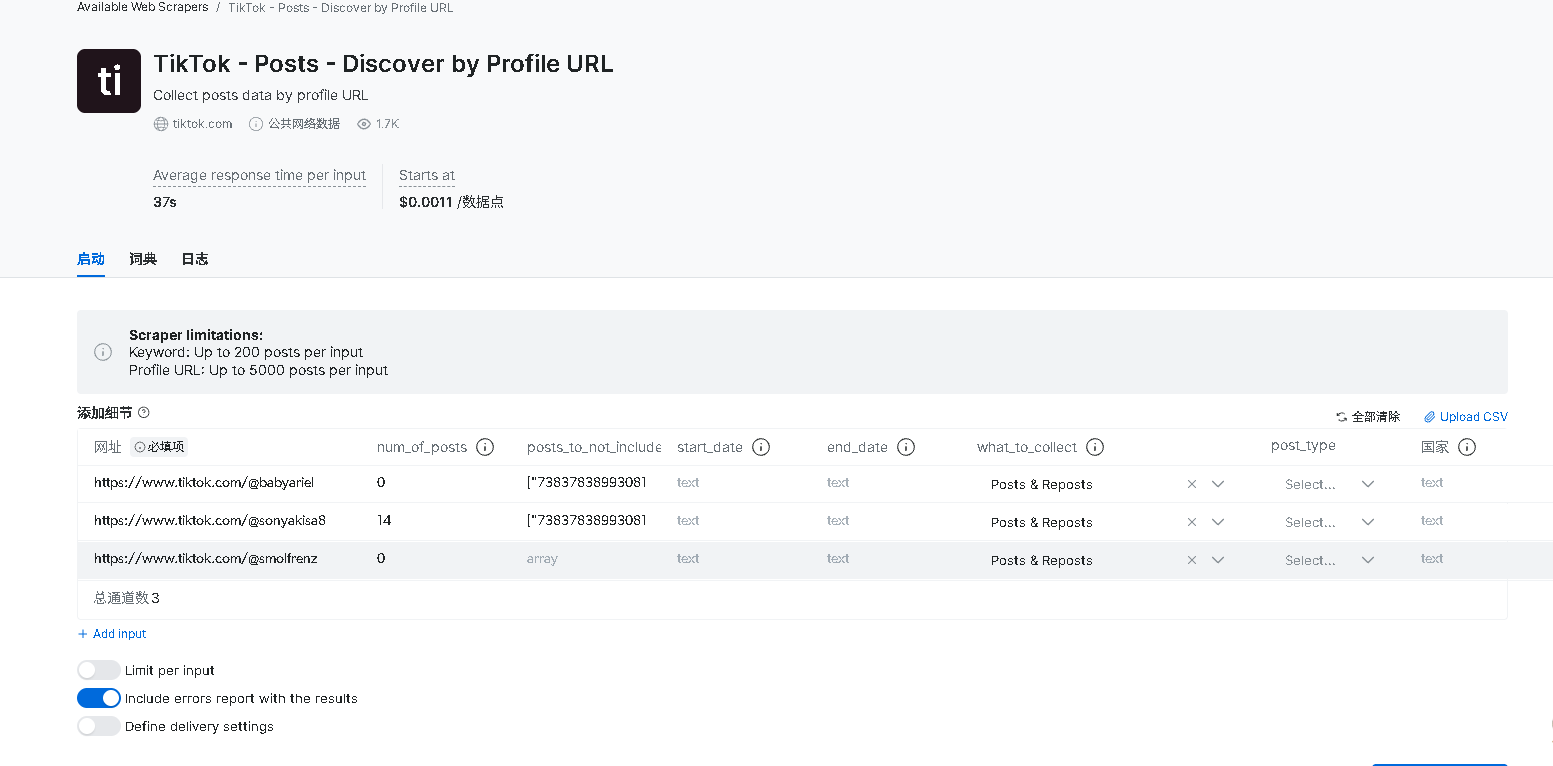
你发送数据请求后爬下来的数据就会临时存储到亮数据平台上,也可以在下面的Define delivery settings按钮中,可以选择交付方式,可以存储到亚马逊、谷歌、微软、阿里的云端服务上。配置好后,点击Start collecting就会触发爬取程序,只需要耐心等待就能获取到数据集了。整个过程十分简单,只需要配置即可。
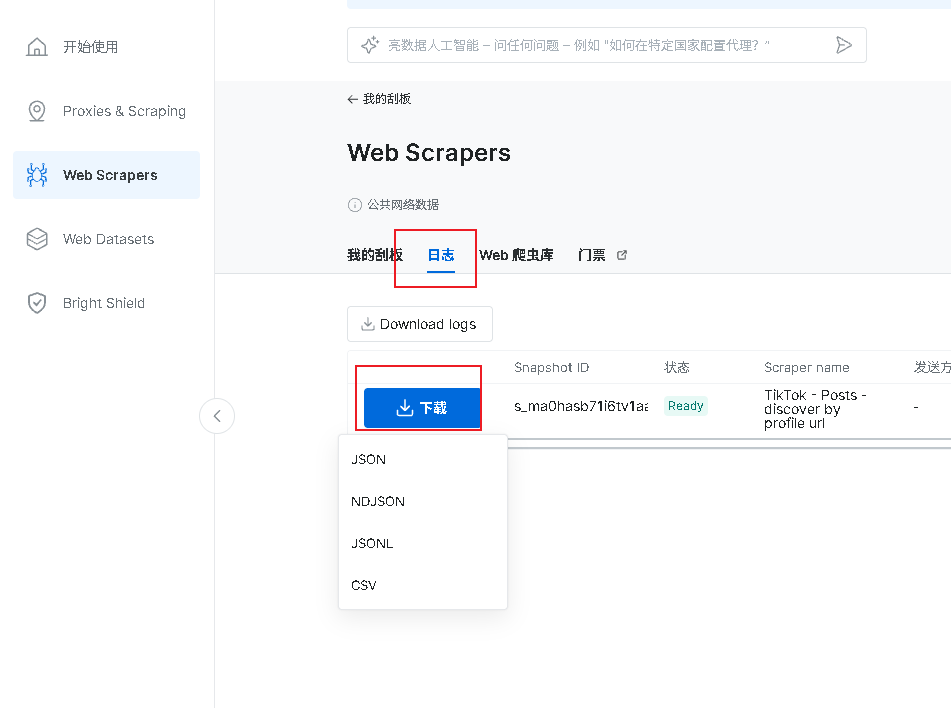
6、获取数据,在日志板块,当状态为Ready,即可下载结果,可以选择需要的格式进行下载。
至此,整个流程结束,对于我们来说,非常简单,那么中间Scraper API帮我们做了什么呢?
Scraper API 通过云端服务简化了 TikTok 数据抓取,自动处理了请求发送、登录模拟、IP代理、动态内容加载、验证码识别和数据解密等复杂技术环节,最终返回数据。这避免了我们直接面对技术挑战和高维护成本的代码编写工作。
✏️爬虫代码API方式
上面我们介绍了无代码方式,下面我们来使用代码进行。
Scraper API 提供了 Python 访问接口,通过 requests 库获取数据,操作起来非常简单。
使用 Python 实现数据抓取有两个主要优点:
支持批量自动提交 URL 地址,无需手动逐个复制。
可以对抓取到的数据进行进一步的处理、清洗和存储,通过与 Pandas、Numpy 等库的结合,操作变得更加高效和便捷。
步骤也很简单,首先是触发请求,获取返回的snapshot_id,等待数据抓取完成后,通过snapshot_id获取对应的响应数据!
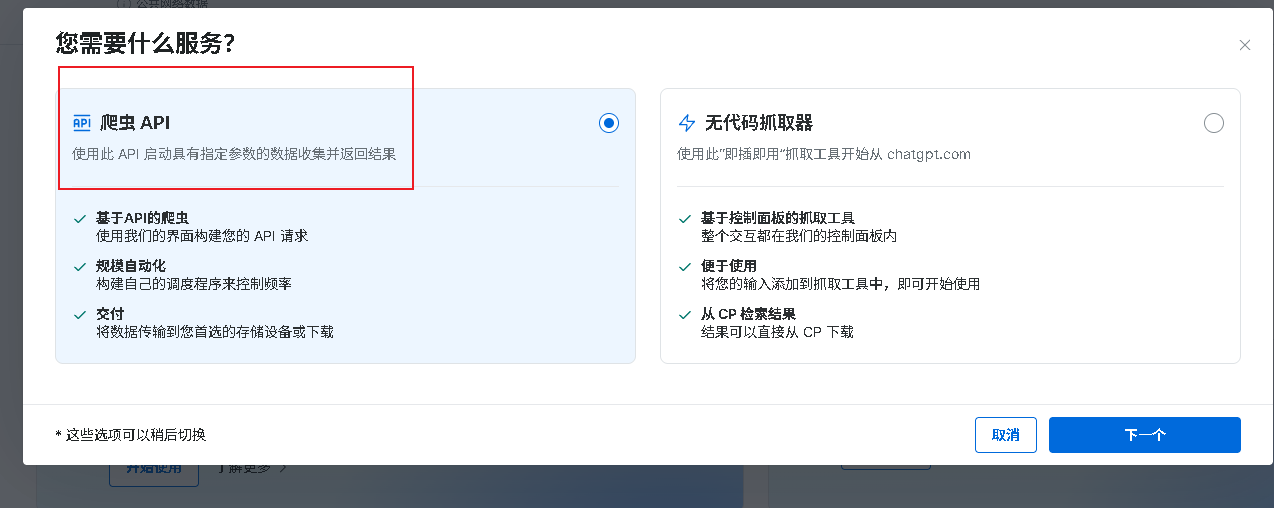
1. 这里我以 抓取chatgpt结果为例,点击后,选择爬虫api的方式,如下图:
2.需要先获取到令牌和dataset_id的值,如下图:
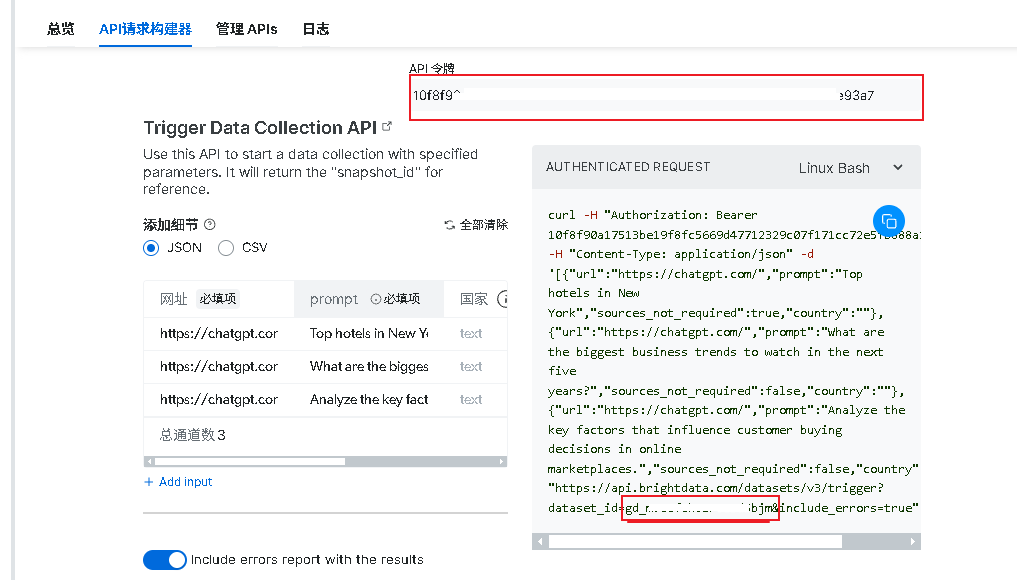
3.来到代码,首先定义一个方法,用来触发请求并返回 snapshot_id,如下:
def trigger_request(headers, querystring, payload):
"""触发请求并返回 snapshot_id"""
response = requests.post(url_trigger, json=payload, headers=headers, params=querystring)
# 错误处理
if response.status_code not in [200, 201, 202, 203, 204]:
print(f"请求失败,状态码: {response.status_code}")
return None
response_data = response.json()
snapshot_id = response_data.get("snapshot_id")
if not snapshot_id:
print("未返回 snapshot_id")
return None
return snapshot_id
拿到snapshot_id后,定义一个方法,通过snapshot_id获取Scraper API处理完请求后的结果,因为Scraper API服务器处理请求需要时间,过程中使用while每个30秒获取一下响应,直到拿到,代码如下:
def get_snapshot_data(snapshot_id, headers):
"""获取 snapshot 数据"""
snapshot_url = url_snapshot.format(snapshot_id)
while True:
try:
response = requests.get(snapshot_url, headers=headers, timeout=60)
if response.status_code not in [200, 201, 202, 203, 204]:
print(f"请求失败,状态码: {response.status_code}")
time.sleep(30)
continue
response_data = response.json()
status = response_data.get('status')
if not status:
binary_content = response.content
# 将二进制数据保存为文件
with open('response.json', 'wb') as file:
file.write(binary_content)
print("数据已保存为 response.json")
with open('response.json', 'r', encoding='utf-8') as file:
json_data = json.load(file)
process_answer_data(json_data) # 处理结果
break
else:
print("结果尚未完成,等待 30 秒后重新请求...")
time.sleep(30)
except requests.RequestException as e:
print(f"请求发生错误: {e}")
time.sleep(30)
下一步是定义一个方法,用来简单提取需要的响应数据字段,代码如下:
def process_answer_data(data):
try:
# 通过字典访问每个字段
url = data.get("url", "无链接")
prompt = data.get("prompt", "无问题")
answer_text = data.get("answer_text", "无回答")
links_attached = data.get("links_attached", [])
citations = data.get("citations", [])
timestamp = data.get("timestamp", "无时间戳")
# 输出结果
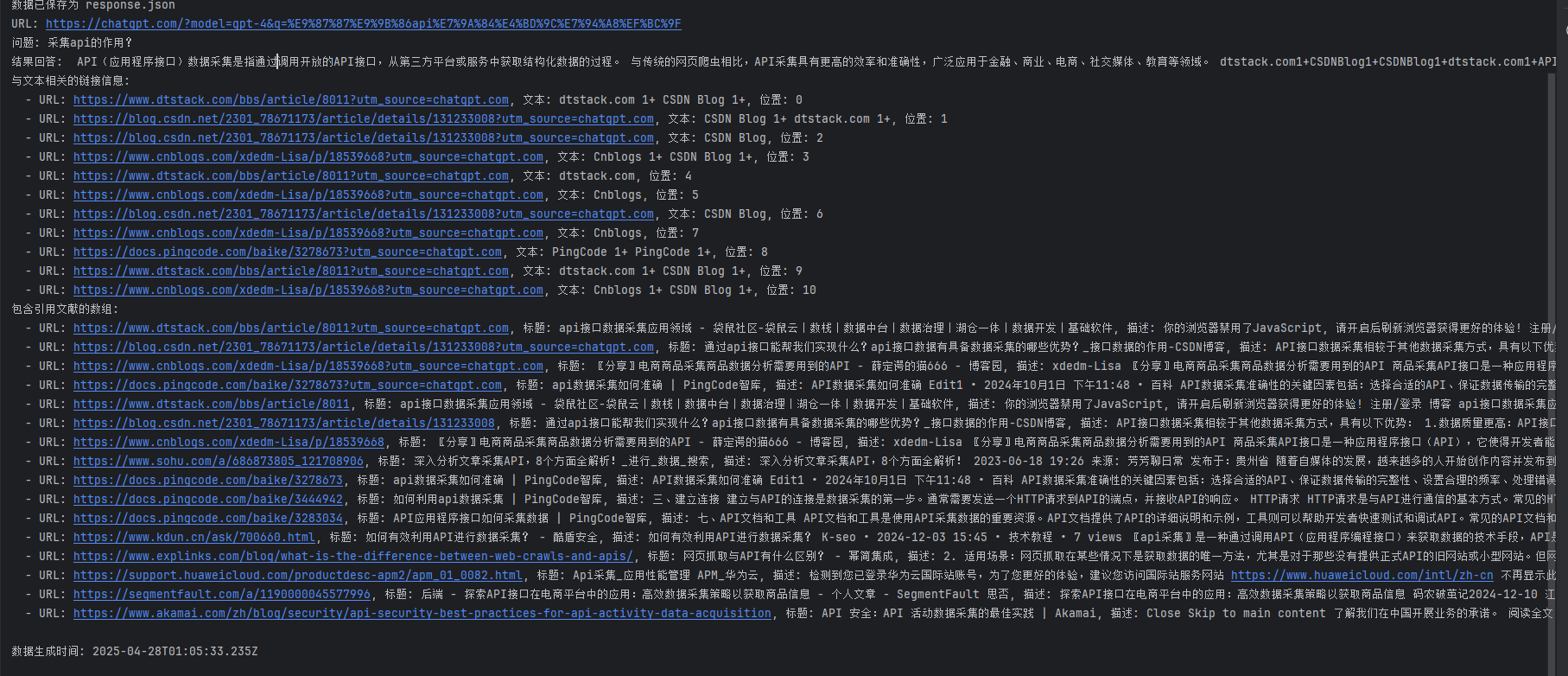
print(f"URL: {url}")
print(f"问题: {prompt}")
print(f"结果回答: {answer_text.replace(' ', '')}")
if links_attached:
print("与文本相关的链接信息:")
for link in links_attached:
print(f" - URL: {link['url']}, 文本: {link['text']}, 位置: {link['position']}")
else:
print("与文本相关的链接信息: 无链接")
if citations:
print("包含引用文献的数组:")
for citation in citations:
print(
f" - URL: {citation['url']}, 标题: {citation['title']}, 描述: {citation['description']}, 图标: {citation['icon']}, 域名: {citation['domain']}")
else:
print("包含引用文献的数组: 无引用")
print(f"\n数据生成时间: {timestamp}")
except Exception as e:
print(f"发生错误: {e}")
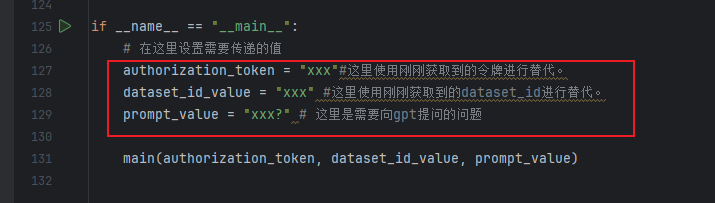
下一步开始执行代码,传入相关的信息,如下图:
执行结果如下,这里我只是提取出一些字段进行打印,具体需要什么字段可以在数据处理的时候更改。
完整代码:
import requests
import json
import time
# 配置参数
url_trigger = "https://api.brightdata.com/datasets/v3/trigger"
url_snapshot = "https://api.brightdata.com/datasets/v3/snapshot/{0}"
headers = {
"Authorization": "", # 这里设置为空,后面会动态设置
"Content-Type": "application/json"
}
querystring = {"dataset_id": "", "type": "url_collection"} # 这里的 dataset_id 会在 main 函数中设置
payload = {
"url": "https://chatgpt.com/",
"prompt": "", # 这里的 prompt 会在 main 函数中设置
"country": ""
}
def trigger_request(headers, querystring, payload):
"""触发请求并返回 snapshot_id"""
response = requests.post(url_trigger, json=payload, headers=headers, params=querystring)
# 错误处理
if response.status_code not in [200, 201, 202, 203, 204]:
print(f"请求失败,状态码: {response.status_code}")
return None
response_data = response.json()
snapshot_id = response_data.get("snapshot_id")
if not snapshot_id:
print("未返回 snapshot_id")
return None
return snapshot_id
def get_snapshot_data(snapshot_id, headers):
"""获取 snapshot 数据"""
snapshot_url = url_snapshot.format(snapshot_id)
while True:
try:
response = requests.get(snapshot_url, headers=headers, timeout=60)
if response.status_code not in [200, 201, 202, 203, 204]:
print(f"请求失败,状态码: {response.status_code}")
time.sleep(30)
continue
response_data = response.json()
status = response_data.get('status')
if not status:
binary_content = response.content
# 将二进制数据保存为文件
with open('response.json', 'wb') as file:
file.write(binary_content)
print("数据已保存为 response.json")
with open('response.json', 'r', encoding='utf-8') as file:
json_data = json.load(file)
process_answer_data(json_data) # 处理结果
break
else:
print("结果尚未完成,等待 30 秒后重新请求...")
time.sleep(30)
except requests.RequestException as e:
print(f"请求发生错误: {e}")
time.sleep(30)
def process_answer_data(data):
try:
# 通过字典访问每个字段
url = data.get("url", "无链接")
prompt = data.get("prompt", "无问题")
answer_text = data.get("answer_text", "无回答")
links_attached = data.get("links_attached", [])
citations = data.get("citations", [])
timestamp = data.get("timestamp", "无时间戳")
# 输出结果
print(f"URL: {url}")
print(f"问题: {prompt}")
print(f"结果回答: {answer_text.replace(' ', '')}")
if links_attached:
print("与文本相关的链接信息:")
for link in links_attached:
print(f" - URL: {link['url']}, 文本: {link['text']}, 位置: {link['position']}")
else:
print("与文本相关的链接信息: 无链接")
if citations:
print("包含引用文献的数组:")
for citation in citations:
print(
f" - URL: {citation['url']}, 标题: {citation['title']}, 描述: {citation['description']}, 图标: {citation['icon']}, 域名: {citation['domain']}")
else:
print("包含引用文献的数组: 无引用")
print(f"\n数据生成时间: {timestamp}")
except Exception as e:
print(f"发生错误: {e}")
def main(authorization, dataset_id, prompt_value):
# 设置 headers, querystring, 和 payload
headers["Authorization"] = f"Bearer {authorization}"
querystring["dataset_id"] = dataset_id
payload["prompt"] = prompt_value
snapshot_id = trigger_request(headers, querystring, payload)
if snapshot_id:
print(f"触发请求成功,snapshot_id: {snapshot_id}")
get_snapshot_data(snapshot_id, headers)
else:
print("无法触发请求,请检查 API 配置")
if __name__ == "__main__":
# 在这里设置需要传递的值
authorization_token = "xxx"#这里使用刚刚获取到的令牌进行替代。
dataset_id_value = "xxx" #这里使用刚刚获取到的dataset_id进行替代。
prompt_value = "xxx?" # 这里是需要向gpt提问的问题
main(authorization_token, dataset_id_value, prompt_value)
💖结语
Scraper API 为数据抓取提供了一个强大而便捷的解决方案。无论你是个人开发者还是企业团队,它都能帮助你轻松绕过技术难题,快速获取所需的数据,让你可以节省大量的时间和精力,专注于更有价值的分析和应用。
拥抱技术的力量,简化数据抓取流程,提升你的工作效率。未来,数据将继续主导决策和创新,而 Scraper API 将是你迈向成功的一把利器。
看到这里,如果小伙伴们有相同的数据采集需求,或是作为初学者想要拓宽视野,不妨立即行动, 点击免费试用,体验亮数据的强大功能!
如果你想更进一步,或是代表公司,推荐和官方数据专家进行约谈,以便让官方数据专家为我们量身定制最佳解决方案。点击约谈,(注册要使用公司邮箱)。


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











