







最近由于工作原因,需要研究OpenCV中的Adaboost级联分类器。我阅读了OpenCV中所有相关得代码,包括检测和训练部分,发现目前OpenCV中的Adaboost级联分类器代码有以下2个特点:
1.OpenCV代码中的实际算法与Paul.Viola论文中的原始算法差异很大。最新的训练和检测代码实现了Haar、LBP和HOG特征接口,同时训练代码中支持DAB、LAB、RAB和GAB共4种Adaboost算法,另外还实现了trim weight方法。
2.OpenCV由于一些历史遗留问题,代码中C结构(CvMat等)和C++结构(Mat::Mat等)共用,难以理解。
可能正是由于这些问题,导致代码极其复杂,没有几个人愿意花费时间去深挖代码。
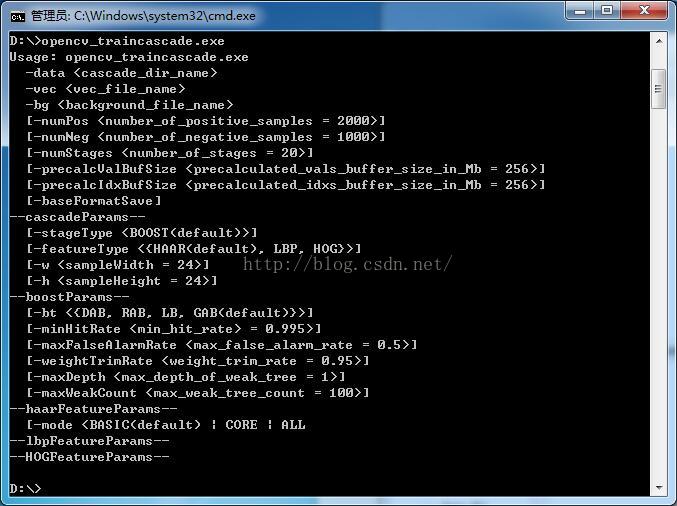
图1 opencv_traincascade.exe训练程序usage界面
图1显示了opencv_traincascade的usage界面,仅仅一个traincascade训练程序就有如此之多的命令。翻遍目前网上介绍Adaboost级联分类器的文章,没有一篇文章能够完整的介绍上面所有命令的原理,甚至有些文章还存在错误,实在让人头疼。
基于知识共享的原则,我把这几个月分析代码的结果写成一个系列分享给出来,希望能够对OpenCV中的Adaboost级联分类器做出“盖棺定论”,同时也让大家也不再像我一样“摸着石头过河”。
本系列文章不追求高深的原理(其实是我水平低),力求简单粗暴、看完就能懂。目前OpenCV中的Adaboost级联分类器支持多种特征,考虑到篇幅问题,我选择用最基础的Haar特征进行分析。下面是本系列文章的基本写作思路:
首先,由Haar为引子,分析XML分类器中各个结点数值的含义,介绍Adaboost级联分类器的树状结构。
然后,以DAB(Discrete Adaboost)为基础,介绍traincascade训练程序的原理。
最后,分析最复杂也是效果最好的的GAB(Gentle Adaboost)。
当然由于作者水平有限,难免出现遗漏和错误,真诚的欢迎各位大侠批评指正!接下来进入正题。
(一)Haar特征的生成
既然是结合Haar特征分析Adaboost级联分类器,那么有必要先对Haar特征进行细致的分析。
Haar特征最先由Paul Viola等提出,后经过Rainer Lienhart等扩展引入45°倾斜特征,成为现在OpenCV所使用的的样子。图2展示了目前OpenCV(2.4.11版本)所使用的共计14种Haar特征,包括5种Basic特征、3种Core特征和6种Titled(即45°旋转)特征。
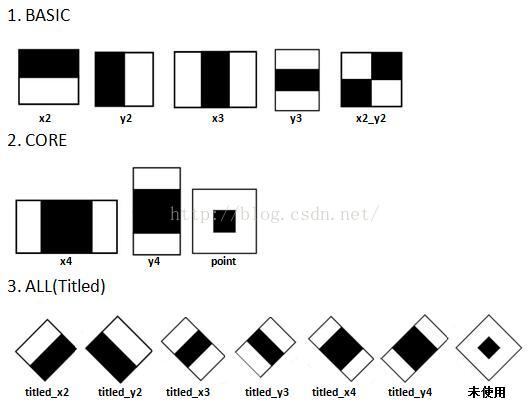
图2 OpenCV中使用的的Haar特征
而图1中haarFeatureParams参数中的mode参数正对应了训练过程中所使用的特征集合:

图3 mode参数
1.如果设置mode为BASIC,则只使用BASIC的5种Haar特征进行训练,训练出的分类器也只包含这5种特征。
2.如果设置mode为CORE,则使用BASIC的5种+CORE的3种Haar特征进行训练。
3.如果设置mode为ALL,则使用BASICA的5种+CORE的3种+ALL的6种Titled共14种特征进行训练。
需要说明,训练程序opencv_trancascade.exe一般默认使用BASIC模式,实际中训练和检测效果已经足够好。不建议使用ALL参数,引入Titled倾斜特征需要多计算一张倾斜积分图,会极大的降低训练和检测速度,而且效果也没有论文中说的那么好。
在实际中,Haar特征可以在检测窗口中由放大+平移产生一系列子特征,但是白:黑区域面积比始终保持不变。
如图4,以x3特征为例,在放大+平移过程中白:黑:白面积比始终是1:1:1。首先在红框所示的检测窗口中生成大小为3个像素的最小x3特征;之后分别沿着x和y平移产生了在检测窗口中不同位置的大量最小3像素x3特征;然后把最小x3特征分别沿着x和y放大,再平移,又产生了一系列大一点x3特征;然后继续放大+平移,重复此过程,直到放大后的x3和检测窗口一样大。这样x3就产生了完整的x3系列特征。

图4 x3特征平移+放大产生一系列子特征示意图
那么这些通过放大+平移的获得的子特征到底有多少个?Rainer Lienhart在其论文中给出了完美的解释:假设检测窗口大小为W*H,矩形特征大小为w*h,X和Y为表示矩形特征在水平和垂直方向的能放大的最大比例系数:
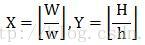
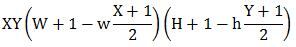
对应于之前的x3特征,当x3特征在24*24大小的检测窗口中时(此时W=H=24,w=3,h=1,X=8,Y=24),一共能产生27600个子特征。除x3外其他一般矩形特征数量计算方法类似,这里不做赘述。另外,我为认为title特征(即图5中的45°rotated reactangle)实用性一般,不再介绍,请查阅论文。
(二)计算Haar特征值
看到这里,您应该明白了大量的Haar特征是如何产生的。当有了大量的Haar特征用于训练和检测时,接下来的问题是如何计算Haar特征值。
按照OpenCV代码,Haar特征值=白色区域内图像像素和 x 权重 - 黑色区域内图像像素和 x 权重:
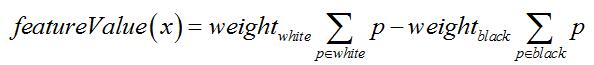
对于x3和y3特征,weightwhite = 1且weightblack = 2;对于point特征,weightwhite
= 1且weightblack = 8;其余11种特征均为weightwhite = weightblack = 1。这也就是其他文章中提到的所谓“白色区域像素和减去黑色区域像素和”,只不过是加权相减而已(在XML文件中,每一个Haar特征都被保存在2~3个形如<x
y width height weight>的标签中,其中x和y代表Haar矩形左上角点以检测窗口的左上角为原点的坐标,width和height代表矩形框的宽和高,而weight则对应了上面说的权重值,例如图6中的左边Haar特征应该表示为<4 2 12 8 1.0>和<4 2 12 4 -2.0>)。
为什么要设置这种加权相减,而不是直接相减?请仔细观察图2中的特征,不难发现x3、y3、point特征黑白面积不相等,而其他特征黑白面积相等。设置权值就是为了抵消面积不等带来的影响,保证所有Haar特征的特征值在“灰度分布绝对均匀的图像”中为0(这种图像不存在,只是理论中的)。
了解了特征值如何计算之后,再来看看不同的特征值的含义是什么。我选取了MIT人脸库中2706个大小为20*20的人脸正样本图像,计算如图6位置的Haar特征值,结果如图7。
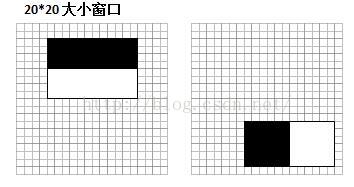
图6 Haar特征位置示意图(左边对应人眼区域,右边无具体意义)
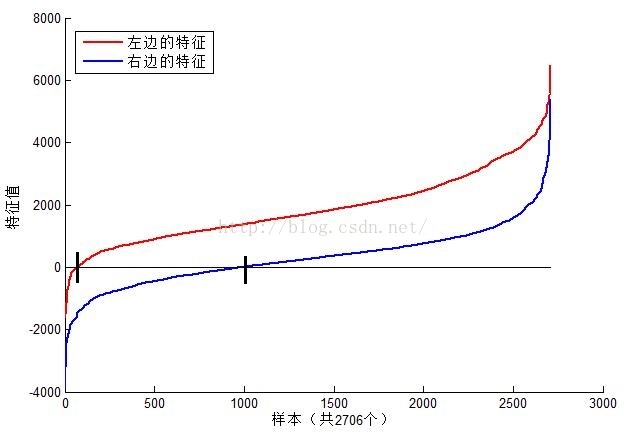
图7 图6的2个Haar特征在MIT人脸样本中特征值分布图(左边特征结果为红色,右边蓝色)
可以看到,图6中2个不同Haar特征在同一组样本中具有不同的特征值分布,左边特征计算出的特征值基本都大于0(对样本的区分度大),而右边特征的特征值基本均匀分布于0两侧(对样本的区分度)。所以,正是由于样本中Haar特征值分布不均匀,导致了不同Haar特征分类效果不同。显而易见,对正负样本区分度越大的特征分类效果越好,即红色曲线对应图6中的的左边Haar特征分类效果好于右边Haar特征。
那么看到这里,应该理解了下面2个问题:
1. 在检测窗口通过平移+放大可以产生一系列Haar特征,这些特征由于位置和大小不同,分类效果也不同;
2. 通过计算Haar特征的特征值,可以有将图像矩阵映射为1维特征值,有效实现了降维。
(三)Haar特征值归一化
本节属于实现细节,只关心原理的朋友可以跳过。
细心的朋友可能已经从图7中发现,仅仅一个12*18大小的Haar特征计算出的特征值变化范围从-2000~+6000,跨度非常大。这种跨度大的特性不利于量化评定特征值,所以需要进行“归一化”,压缩特征值范围。假设当前检测窗口中的图像为i(x,y),当前检测窗口为w*h大小(例如图6中为20*20大小),OpenCV采用如下方式“归一化”:
1. 计算检测窗口中图像的灰度值和灰度值平方和:
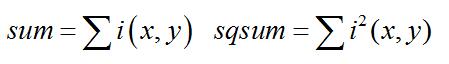
2. 计算平均值:
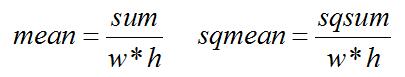
3. 计算归一化因子:
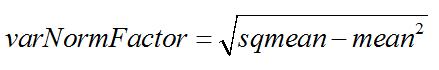
4. 归一化特征值:
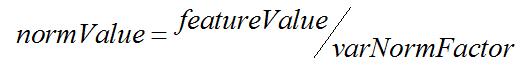
之后使用归一化后的特征值normValue与阈值对比(见下节)。
(四)积分图
积分图是被各种文章写了无数次,考虑到文章完整性,我硬着头皮再写一遍。
之前我们分析到,仅仅在24*24大小的窗口,通过平移+缩放就可以产生数十万计大小不一、位置各异的Haar特征。在一个窗口内就有这么多Haar特征,而检测窗口是不断移动的,那么如何快速的计算这些Haar特征的特征值就是一个非常重要的问题了,所以才需要引入积分图。
对于图像中任何一点i(x,y),定义其积分图为ii(x,y)为:
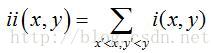
其中i(x',y')为点(x',y')处的原始灰度图。这样就定义了一张类似于数学中“积分”的积分图。有了积分图ii(x,y)后,只需要做有限次操作就能获得任意位置的Haar特征值。
-------------------------------------------
参考文献:
[1] Paul Viola and Michael J. Jones. Rapid Object Detection using a Boosted Cascade of Simple Features. IEEE CVPR, 2001.
[2] Rainer Lienhart and Jochen Maydt. An Extended Set ofHaar-like Features for Rapid Object Detection. IEEE ICIP 2002, Vol. 1, pp. 900-903, Sep. 2002.
1.OpenCV代码中的实际算法与Paul.Viola论文中的原始算法差异很大。最新的训练和检测代码实现了Haar、LBP和HOG特征接口,同时训练代码中支持DAB、LAB、RAB和GAB共4种Adaboost算法,另外还实现了trim weight方法。
2.OpenCV由于一些历史遗留问题,代码中C结构(CvMat等)和C++结构(Mat::Mat等)共用,难以理解。
可能正是由于这些问题,导致代码极其复杂,没有几个人愿意花费时间去深挖代码。
图1 opencv_traincascade.exe训练程序usage界面
图1显示了opencv_traincascade的usage界面,仅仅一个traincascade训练程序就有如此之多的命令。翻遍目前网上介绍Adaboost级联分类器的文章,没有一篇文章能够完整的介绍上面所有命令的原理,甚至有些文章还存在错误,实在让人头疼。
基于知识共享的原则,我把这几个月分析代码的结果写成一个系列分享给出来,希望能够对OpenCV中的Adaboost级联分类器做出“盖棺定论”,同时也让大家也不再像我一样“摸着石头过河”。
本系列文章不追求高深的原理(其实是我水平低),力求简单粗暴、看完就能懂。目前OpenCV中的Adaboost级联分类器支持多种特征,考虑到篇幅问题,我选择用最基础的Haar特征进行分析。下面是本系列文章的基本写作思路:
首先,由Haar为引子,分析XML分类器中各个结点数值的含义,介绍Adaboost级联分类器的树状结构。
然后,以DAB(Discrete Adaboost)为基础,介绍traincascade训练程序的原理。
最后,分析最复杂也是效果最好的的GAB(Gentle Adaboost)。
当然由于作者水平有限,难免出现遗漏和错误,真诚的欢迎各位大侠批评指正!接下来进入正题。
(一)Haar特征的生成
既然是结合Haar特征分析Adaboost级联分类器,那么有必要先对Haar特征进行细致的分析。
Haar特征最先由Paul Viola等提出,后经过Rainer Lienhart等扩展引入45°倾斜特征,成为现在OpenCV所使用的的样子。图2展示了目前OpenCV(2.4.11版本)所使用的共计14种Haar特征,包括5种Basic特征、3种Core特征和6种Titled(即45°旋转)特征。
图2 OpenCV中使用的的Haar特征
而图1中haarFeatureParams参数中的mode参数正对应了训练过程中所使用的特征集合:
图3 mode参数
1.如果设置mode为BASIC,则只使用BASIC的5种Haar特征进行训练,训练出的分类器也只包含这5种特征。
2.如果设置mode为CORE,则使用BASIC的5种+CORE的3种Haar特征进行训练。
3.如果设置mode为ALL,则使用BASICA的5种+CORE的3种+ALL的6种Titled共14种特征进行训练。
需要说明,训练程序opencv_trancascade.exe一般默认使用BASIC模式,实际中训练和检测效果已经足够好。不建议使用ALL参数,引入Titled倾斜特征需要多计算一张倾斜积分图,会极大的降低训练和检测速度,而且效果也没有论文中说的那么好。
在实际中,Haar特征可以在检测窗口中由放大+平移产生一系列子特征,但是白:黑区域面积比始终保持不变。
如图4,以x3特征为例,在放大+平移过程中白:黑:白面积比始终是1:1:1。首先在红框所示的检测窗口中生成大小为3个像素的最小x3特征;之后分别沿着x和y平移产生了在检测窗口中不同位置的大量最小3像素x3特征;然后把最小x3特征分别沿着x和y放大,再平移,又产生了一系列大一点x3特征;然后继续放大+平移,重复此过程,直到放大后的x3和检测窗口一样大。这样x3就产生了完整的x3系列特征。
图4 x3特征平移+放大产生一系列子特征示意图
那么这些通过放大+平移的获得的子特征到底有多少个?Rainer Lienhart在其论文中给出了完美的解释:假设检测窗口大小为W*H,矩形特征大小为w*h,X和Y为表示矩形特征在水平和垂直方向的能放大的最大比例系数:
图5 特征数量计算示意图
则如图5,在检测窗口Window中,一般矩形特征(upright rectangle)的数量为:对应于之前的x3特征,当x3特征在24*24大小的检测窗口中时(此时W=H=24,w=3,h=1,X=8,Y=24),一共能产生27600个子特征。除x3外其他一般矩形特征数量计算方法类似,这里不做赘述。另外,我为认为title特征(即图5中的45°rotated reactangle)实用性一般,不再介绍,请查阅论文。
(二)计算Haar特征值
看到这里,您应该明白了大量的Haar特征是如何产生的。当有了大量的Haar特征用于训练和检测时,接下来的问题是如何计算Haar特征值。
按照OpenCV代码,Haar特征值=白色区域内图像像素和 x 权重 - 黑色区域内图像像素和 x 权重:
对于x3和y3特征,weightwhite = 1且weightblack = 2;对于point特征,weightwhite
= 1且weightblack = 8;其余11种特征均为weightwhite = weightblack = 1。这也就是其他文章中提到的所谓“白色区域像素和减去黑色区域像素和”,只不过是加权相减而已(在XML文件中,每一个Haar特征都被保存在2~3个形如<x
y width height weight>的标签中,其中x和y代表Haar矩形左上角点以检测窗口的左上角为原点的坐标,width和height代表矩形框的宽和高,而weight则对应了上面说的权重值,例如图6中的左边Haar特征应该表示为<4 2 12 8 1.0>和<4 2 12 4 -2.0>)。
为什么要设置这种加权相减,而不是直接相减?请仔细观察图2中的特征,不难发现x3、y3、point特征黑白面积不相等,而其他特征黑白面积相等。设置权值就是为了抵消面积不等带来的影响,保证所有Haar特征的特征值在“灰度分布绝对均匀的图像”中为0(这种图像不存在,只是理论中的)。
了解了特征值如何计算之后,再来看看不同的特征值的含义是什么。我选取了MIT人脸库中2706个大小为20*20的人脸正样本图像,计算如图6位置的Haar特征值,结果如图7。
图6 Haar特征位置示意图(左边对应人眼区域,右边无具体意义)
图7 图6的2个Haar特征在MIT人脸样本中特征值分布图(左边特征结果为红色,右边蓝色)
可以看到,图6中2个不同Haar特征在同一组样本中具有不同的特征值分布,左边特征计算出的特征值基本都大于0(对样本的区分度大),而右边特征的特征值基本均匀分布于0两侧(对样本的区分度)。所以,正是由于样本中Haar特征值分布不均匀,导致了不同Haar特征分类效果不同。显而易见,对正负样本区分度越大的特征分类效果越好,即红色曲线对应图6中的的左边Haar特征分类效果好于右边Haar特征。
那么看到这里,应该理解了下面2个问题:
1. 在检测窗口通过平移+放大可以产生一系列Haar特征,这些特征由于位置和大小不同,分类效果也不同;
2. 通过计算Haar特征的特征值,可以有将图像矩阵映射为1维特征值,有效实现了降维。
(三)Haar特征值归一化
本节属于实现细节,只关心原理的朋友可以跳过。
细心的朋友可能已经从图7中发现,仅仅一个12*18大小的Haar特征计算出的特征值变化范围从-2000~+6000,跨度非常大。这种跨度大的特性不利于量化评定特征值,所以需要进行“归一化”,压缩特征值范围。假设当前检测窗口中的图像为i(x,y),当前检测窗口为w*h大小(例如图6中为20*20大小),OpenCV采用如下方式“归一化”:
1. 计算检测窗口中图像的灰度值和灰度值平方和:
2. 计算平均值:
3. 计算归一化因子:
4. 归一化特征值:
之后使用归一化后的特征值normValue与阈值对比(见下节)。
(四)积分图
积分图是被各种文章写了无数次,考虑到文章完整性,我硬着头皮再写一遍。
之前我们分析到,仅仅在24*24大小的窗口,通过平移+缩放就可以产生数十万计大小不一、位置各异的Haar特征。在一个窗口内就有这么多Haar特征,而检测窗口是不断移动的,那么如何快速的计算这些Haar特征的特征值就是一个非常重要的问题了,所以才需要引入积分图。
对于图像中任何一点i(x,y),定义其积分图为ii(x,y)为:
其中i(x',y')为点(x',y')处的原始灰度图。这样就定义了一张类似于数学中“积分”的积分图。有了积分图ii(x,y)后,只需要做有限次操作就能获得任意位置的Haar特征值。
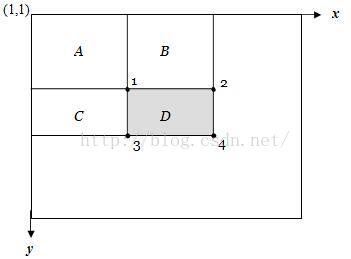
图8 积分图计算Haar矩形框示意图
如图8,如果要计算D区域内像素和,只需计算ii(x1,y1)-ii(x2,y2)-ii(x3,y3)+ii(x4,y4),其中ii是积分图,(x1,y1)、(x2,y2)、(x3,y3)和(x4,y4)分别代表图8中的1 2 3 4点的图像坐标。显然可以通过此方法快速计算图像中任意位置和大小的Haar特征。此处Titled特征积分图不再讲解,请查阅论文。-------------------------------------------
参考文献:
[1] Paul Viola and Michael J. Jones. Rapid Object Detection using a Boosted Cascade of Simple Features. IEEE CVPR, 2001.
[2] Rainer Lienhart and Jochen Maydt. An Extended Set ofHaar-like Features for Rapid Object Detection. IEEE ICIP 2002, Vol. 1, pp. 900-903, Sep. 2002.














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









