









爬取内容
爬取源网站
北京二手房 https://bj.lianjia.com/chengjiao/
爬取内容
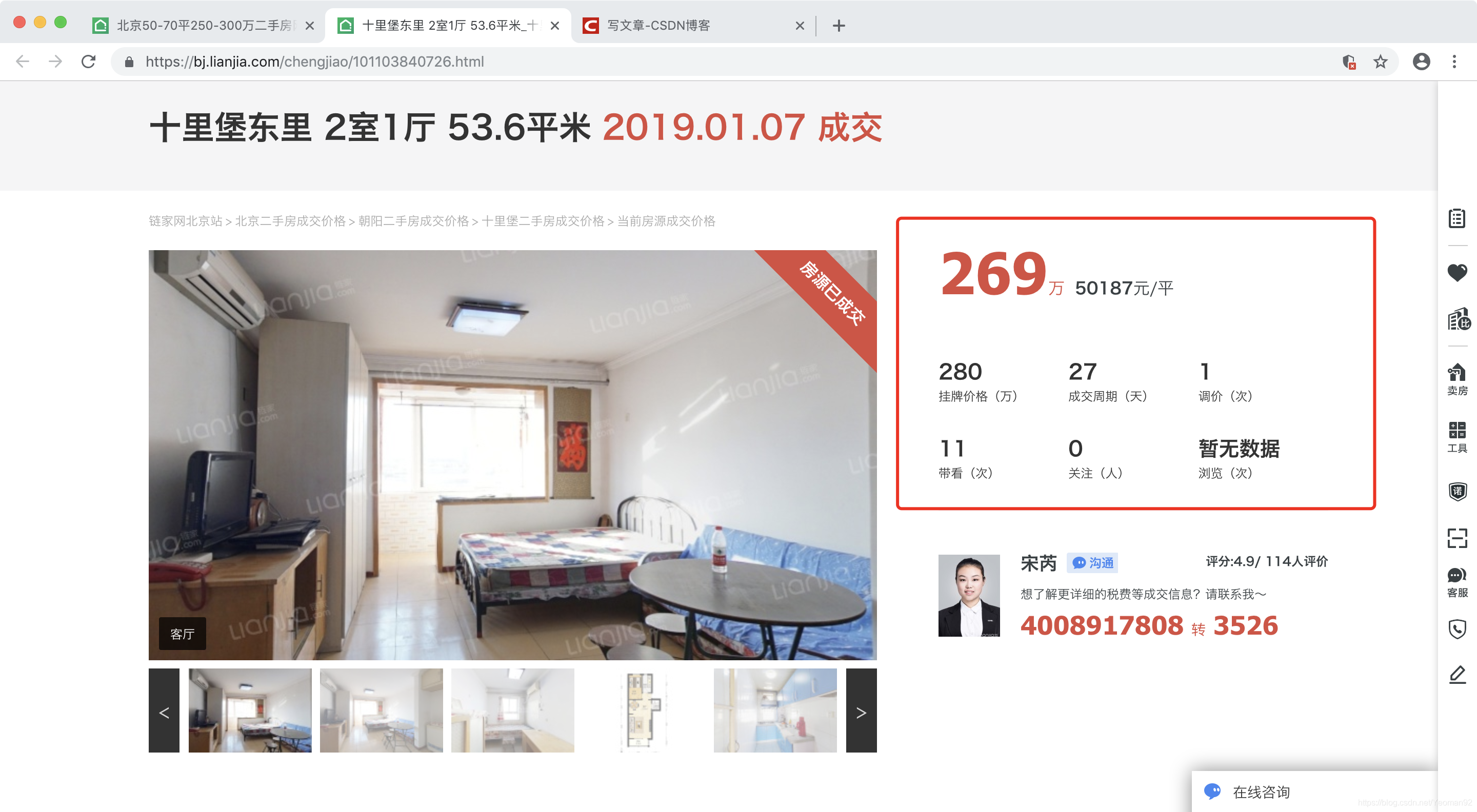
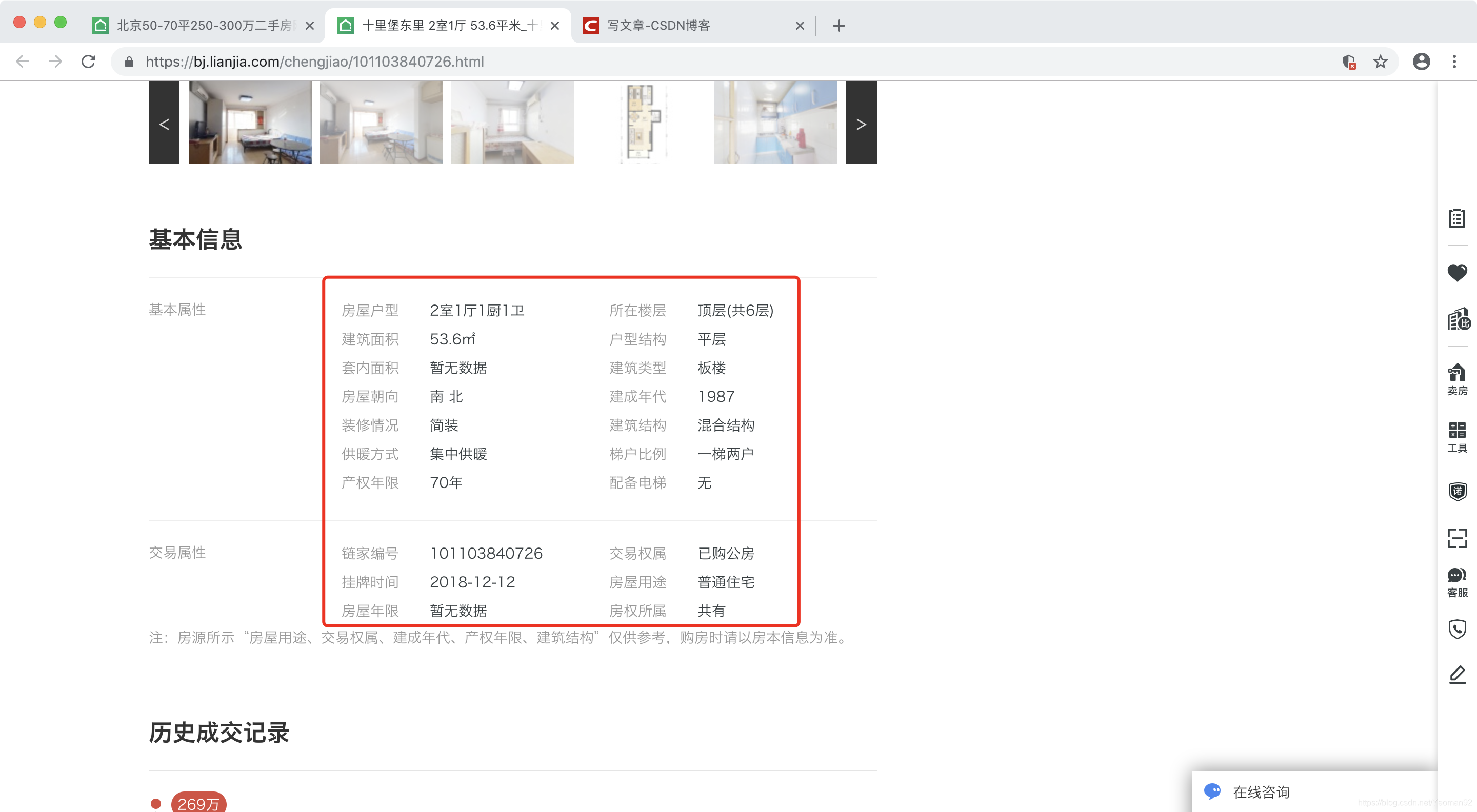
爬取思路
- 通过不同的条件组合,来尽量获取多的数据(因为有100页的限制)
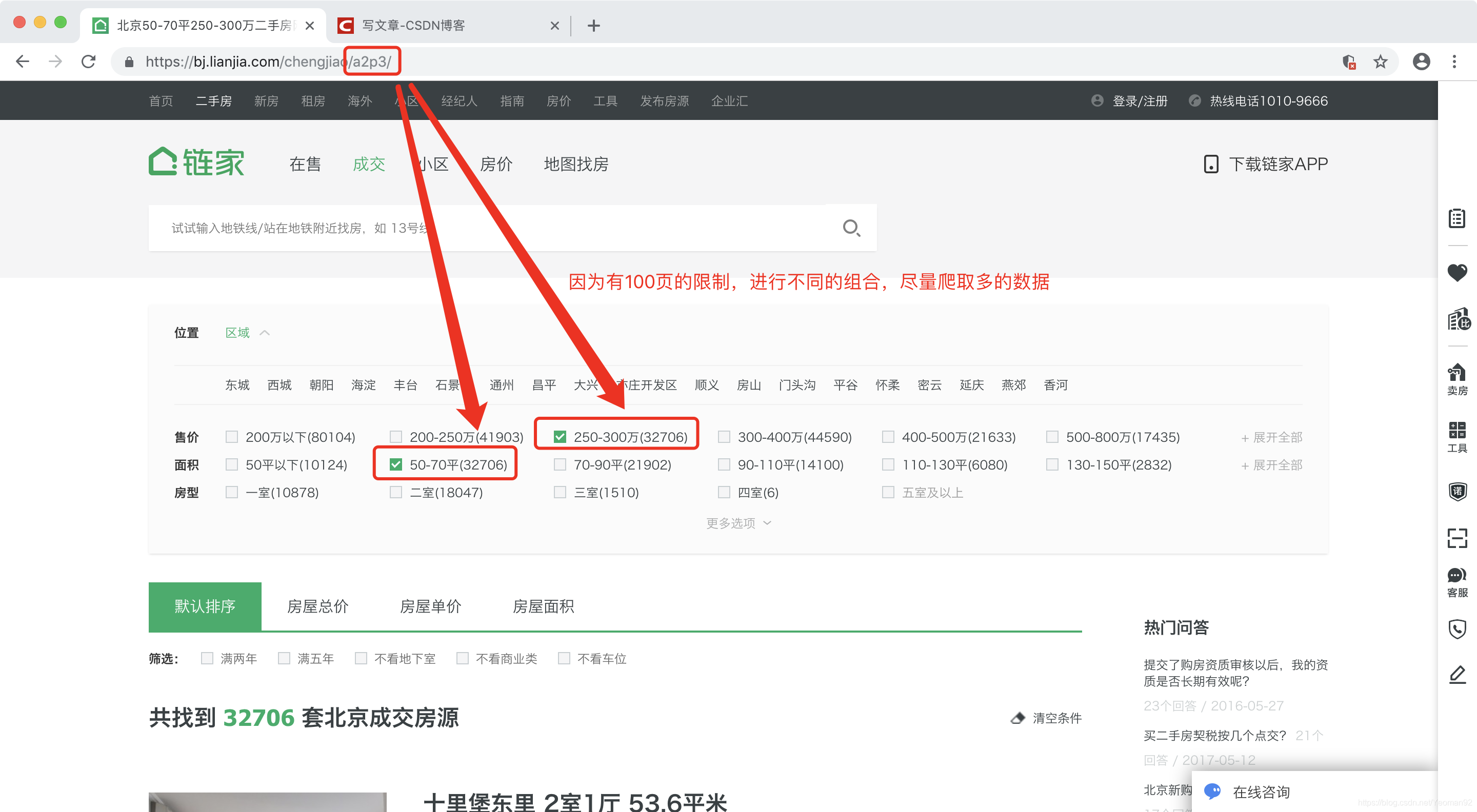
- 获取当前页的房屋url
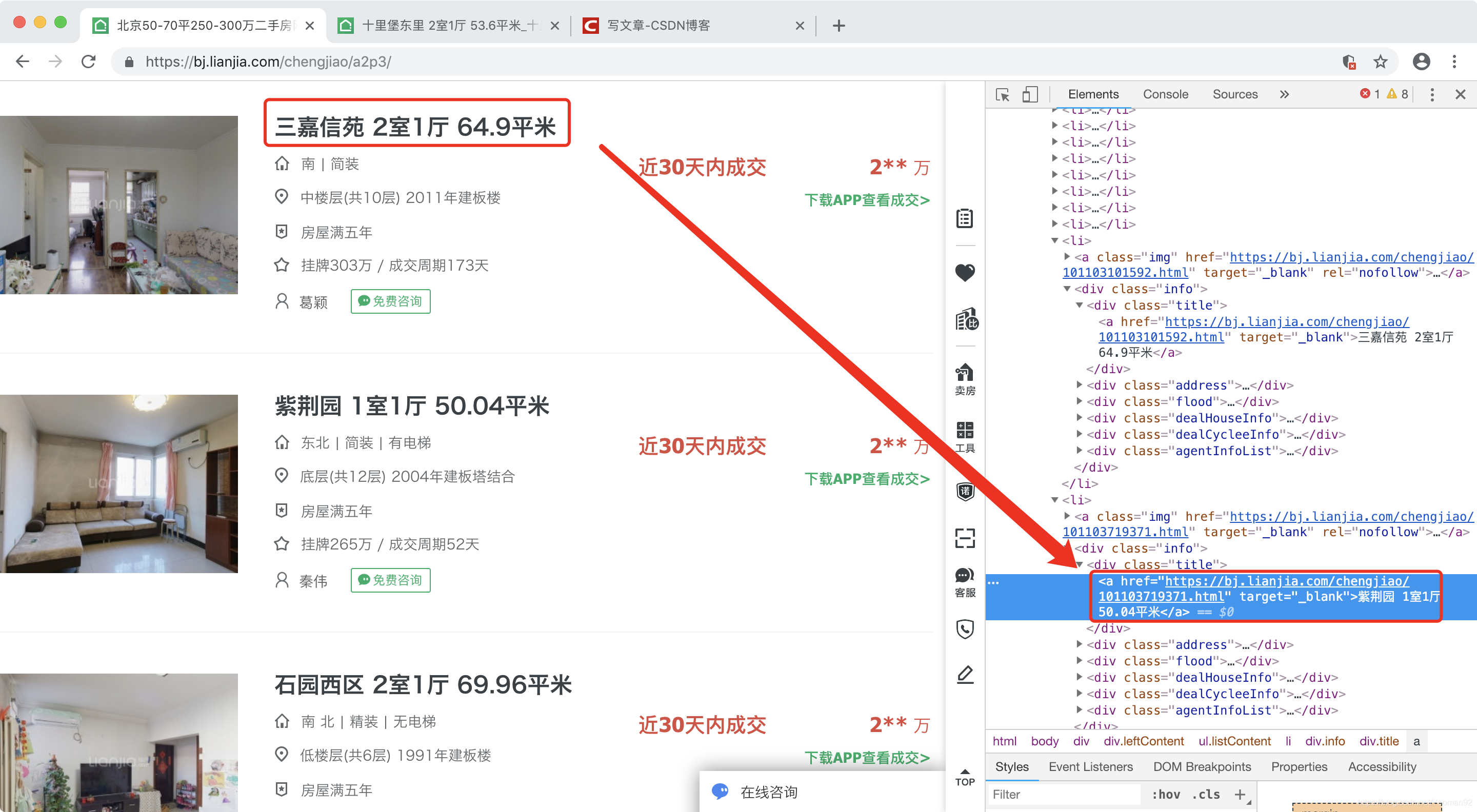
- 翻页保存每一页的房屋url,并把url写到本地
- 读取房屋url,爬取每个房屋的具体信息
爬取的数据
代码
获取房屋url
import urllib.request
import ssl
from lxml import etree
import re
import threading
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
# 获取页面
def get_page(url):
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html
# 获取当前的总页数
def get_page_num(url):
try:
html = get_page(url)
pagenum = re.findall(r'"totalPage":(.+?),"curPage"', html)[0]
except:
pagenum = 0
pagenum = int(pagenum)
return pagenum
# 获取当前页所有房子的url
def get_house_url_current_page(url):
flag = ''
list_house_url_current_page = []
try:
html = get_page(url)
selector = etree.HTML(html)
# 获取成交时间
deal_date = selector.xpath('/html/body/div[5]/div[1]/ul/li[last()]/div/div[2]/div[2]/text()')[0]
# print(deal_date)
# 获取年份
deal_year = deal_date[:4]
if deal_year == '近30天':
pass
elif deal_year == '2018':
house_url_list_li = selector.xpath('/html/body/div[5]/div[1]/ul/li')
for li in house_url_list_li:
house_url = li.xpath('div/div[1]/a/@href')[0]
# print(house_url)
list_house_url_current_page.append(house_url)
else:
flag = 'yearError'
except:
pass
# print(list_house_url_current_page)
return list_house_url_current_page, flag
# 获取某个区所有的房屋url
def get_house_url_current_district(district_url_list):
list_house_url = []
for district_url in district_url_list:
# print(district_url)
pagenum = get_page_num(district_url)
if pagenum == 0:
print('-------')
pagenum = get_page_num(district_url)
print(pagenum)
print(district_url)
print('+++')
for i in range(1, pagenum+1):
url = district_url + 'pg' + str(i)
print(url)
list_house_url_current_page, flag = get_house_url_current_page(url)
if flag == 'yearError':
break
list_house_url.append(list_house_url_current_page)
# print(list_house_url)
# 把所有的url拼接成字符串,便于写入本地
str_url = ''
for row in list_house_url:
for url in row:
str_url += url + '\n'
return str_url
# 把url写到本地
def write_house_url(write_str, district):
path_file = "./data_url/house/" + district + ".txt"
with open(path_file, 'w') as file:
file.write(write_str)
# 组合所有区的搜索条件url
def get_search_url_all_district():
# 各地区url
district_url = [
'https://bj.lianjia.com/chengjiao/changping/',
'https://bj.lianjia.com/chengjiao/chaoyang/',
'https://bj.lianjia.com/chengjiao/fengtai/',
'https://bj.lianjia.com/chengjiao/haidian/',
'https://bj.lianjia.com/chengjiao/xicheng/'
]
# 组合搜索
# 面积(50以下,50-70,70-90,90-110,110-130,130-150,150-200,200以上)
search_area = ['a1', 'a2', 'a3', 'a4', 'a5', 'a6', 'a7', 'a8']
# 价格
search_price = ['p1', 'p2', 'p3', 'p4', 'p5', 'p6', 'p7', 'p8']
# 组合搜索条件url
search_url = []
for url in district_url:
url_list = []
for area in search_area:
for price in search_price:
url_ = url + area + price + '/'
url_list.append(url_)
search_url.append(url_list)
return search_url
def main(index):
list_district = ['changping', 'chaoyang', 'fengtai', 'haidian', 'xicheng']
# 切换不同的区 0,1,2,3,4代表不同的区--'changping', 'chaoyang', 'fengtai', 'haidian', 'xicheng
district = list_district[index]
search_url = get_search_url_all_district()
district_url_list = search_url[index]
write_str = get_house_url_current_district(district_url_list)
write_house_url(write_str, district)
if __name__ == '__main__':
# 这里根据需求调节线程数
for index in range(0, 5):
thread = threading.Thread(target=main, args=(index,))
thread.start()
获取房屋具体信息
import urllib.request
import ssl
from lxml import etree
import re
import csv
import threading
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
# 获取页面
def get_page(url):
page = urllib.request.urlopen(url, timeout=15)
html = page.read().decode('utf-8')
return html
# 读取文件
def read_file(path_file):
with open(path_file, 'r') as file:
lines = file.readlines()
return lines
# 把中文数字转为阿拉伯数字
def zw2alb(zw):
zwsy = ['零', '一', '两', '三', '四', '五', '六', '七', '八', '九', '十', '十一', '十二', '十三', '十四',
'十五', '十六', '十七', '十八', '十九', '二十']
return zwsy.index(zw)
# 解析页面,获取数据
def get_data(html):
list_data = []
selector = etree.HTML(html)
# 交易时间
TradeTime = selector.xpath('/html/body/div[4]/div/span/text()')[0].replace('成交', '').replace(' ', '')
# try:
# TradeTime = selector.xpath('/html/body/div[4]/div/span/text()')[0].replace('成交', '').replace(' ', '')
# except:
# TradeTime = 'null'
print(TradeTime)
list_data.append(TradeTime)
# 成交周期
try:
Cycle = selector.xpath('/html/body/section[1]/div[2]/div[2]/div[3]/span[2]/label/text()')[0]
except:
Cycle = 'null'
# print(Cycle)
list_data.append(Cycle)
# 关注人数
try:
Followers = selector.xpath('/html/body/section[1]/div[2]/div[2]/div[3]/span[5]/label/text()')[0]
except:
Followers = 'null'
#print(Followers)
list_data.append(Followers)
# 总价
try:
TotalPrice = selector.xpath('/html/body/section[1]/div[2]/div[2]/div[1]/span/i/text()')[0]
TotalPrice = int(TotalPrice) * 10000
except:
TotalPrice = 'null'
#print(TotalPrice)
list_data.append(TotalPrice)
# 单价
try:
Price = selector.xpath('/html/body/section[1]/div[2]/div[2]/div[1]/b/text()')[0]
except:
Price = 'null'
#print(Price)
list_data.append(Price)
# 建筑面积
try:
Square = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[3]/text()')[0].replace(' ', '').replace('㎡', '')
except:
Square = 'null'
#print(Square)
list_data.append(Square)
# 房屋户型
try:
HouseType = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[1]/text()')[0]
except:
HouseType = 'null'
#print(HouseType)
# 卧室数目
try:
LivingPos = HouseType.index('室')
Living = HouseType[LivingPos-1]
except:
Living = 'null'
#print(Living)
list_data.append(Living)
# 客厅数目
try:
DrawingPos = HouseType.index('厅')
Drawing = HouseType[DrawingPos - 1]
except:
Drawing = 'null'
#print(Drawing)
list_data.append(Drawing)
# 厨房数目
try:
KitchenPos = HouseType.index('厨')
Kitchen = HouseType[KitchenPos - 1]
except:
Kitchen = 'null'
#print(Kitchen)
list_data.append(Kitchen)
# 卫生间数目
try:
BathPos = HouseType.index('卫')
Bath = HouseType[BathPos - 1]
except:
Bath = 'null'
#print(Bath)
list_data.append(Bath)
# 总楼层与所处楼层
try:
Floor = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[2]/text()')[0]
Floor = Floor.replace(' ', '').replace('楼层', '').replace('共', '').replace('层', '').replace('(', ' ').replace(')', '')
except:
Floor = 'null'
#print(Floor)
list_data.append(Floor)
# 建筑风格(建筑类型)
try:
Type = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[6]/text()')[0].replace(' ', '')
except:
Type = 'null'
#print(Type)
list_data.append(Type)
# 房屋朝向
try:
Orientation = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[7]/text()')[0].strip()
except:
Orientation = 'null'
#print(Orientation)
list_data.append(Orientation)
# 建造时间
try:
Contime = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[8]/text()')[0].replace(' ', '')
except:
Contime = 'null'
#print(Contime)
list_data.append(Contime)
# 装修风格
try:
Decoration = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[9]/text()')[0].replace(' ', '')
except:
Decoration = 'null'
#print(Decoration)
list_data.append(Decoration)
# 建筑结构、材料
try:
Structure = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[10]/text()')[0].replace(' ', '')
except:
Structure = 'null'
#print(Structure)
list_data.append(Structure)
# 梯户比
try:
LiftHu = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[12]/text()')[0].replace(' ', '')
except:
LiftHu = 'null'
#print(LiftHu)
try:
Ti = re.findall(r'(.+?)梯', LiftHu)[0]
Ti = zw2alb(Ti)
Hu = re.findall(r'梯(.+?)户', LiftHu)[0]
Hu = zw2alb(Hu)
except:
pass
try:
LiftRatio = round(Ti / Hu, 3)
except:
LiftRatio = 'null'
#print(LiftRatio)
list_data.append(LiftRatio)
# 是否有电梯
try:
Elevator = selector.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[14]/text()')[0].replace(' ', '')
except:
Elevator = 'null'
if Elevator == '有':
Elevator = 1
elif LiftRatio != 'null':
Elevator = 1
else:
Elevator = 0
#print(Elevator)
list_data.append(Elevator)
# 房屋年限是否满五年
try:
Rights = selector.xpath('//*[@id="introduction"]/div[1]/div[2]/div[2]/ul/li[5]/text()')[0].replace(' ', '')
except:
Rights = 'null'
if Rights == '满五年':
Rights = 1
else:
Rights = 0
#print(Rights)
list_data.append(Rights)
# 周边是否有地铁
try:
Subway = selector.xpath('//*[@id="house_feature"]/div/div[1]/div[2]/a/text()')
except:
Subway
isSubway = 0
for item in Subway:
if item == '地铁':
isSubway = 1
break
Subway = isSubway
#print(Subway)
list_data.append(Subway)
# print(list_data)
return list_data
# 把数据写入到excel
def write_data(file_path, mode, row_data):
with open(file_path, mode, newline='') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(row_data)
def main(index):
list_district = ['changping', 'chaoyang', 'fengtai', 'haidian', 'xicheng']
list_district_ch = ['昌平', '朝阳', '丰台', '海淀', '西城']
district = list_district[index]
district_ch = list_district_ch[index]
# 文件写的路径
file_write_path = './data/' + district + '.csv'
# 写excel标题
row_title = ['URL', 'District', 'TradeTime', 'Cycle', 'Followers', 'TotalPrice', 'Price', 'Square', 'Living',
'Drawing', 'Kitchen', 'Bath', 'Floor', 'Type', 'Orientation', 'Contime', 'Decoration', 'Structure',
'LiftRatio', 'Elevator', 'Rights', 'Subway']
write_data(file_write_path, 'w', row_title)
# 文件读取路径
file_read_path = './data_url/house/' + district + '.txt'
list_url = read_file(file_read_path)
for url in list_url:
url = url.replace('\n', '')
print(url)
try:
html = get_page(url)
row_data = get_data(html)
# 获取成交日期
deal_date = row_data[0]
# 获取年份
deal_year = int(deal_date[:4])
# 筛选2018年的数据
if deal_year > 2018:
continue
if deal_year < 2018:
break
row_data.insert(0, district_ch)
row_data.insert(0, url)
print(row_data)
# 写数据
write_data(file_write_path, 'a', row_data)
except:
pass
if __name__ == '__main__':
# 这里根据需求调节线程数
for index in range(0, 5):
thread = threading.Thread(target=main, args=(index,))
thread.start()














 9382
9382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









