







前言
本次使用的云服务器分别是:阿里云服务器、华为云服务器以及百度云服务器。配置均为2核4G1M,仅作为学习使用。
软件方面:
xshell6
xtp6
jdk1.8
hadoop3.1.3
节点名称
阿里云:node1
华为云:node2
百度云:node3
服务器基本配置
创建好实例后,首先要进行连接。本实验使用的是xshell6连接工具。这里以阿里云为例。
- 打开云服务控制台,找到IP地址,记录公网和私网IP;
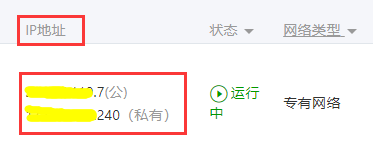
通俗来说公网IP相当于你的身份证,是唯一的;私网IP相当于你的姓名,在你们家是唯一的,但是在外面可能有很多人和你重名。
- 打开xshell工具,新建会话,将公网IP填入主机;
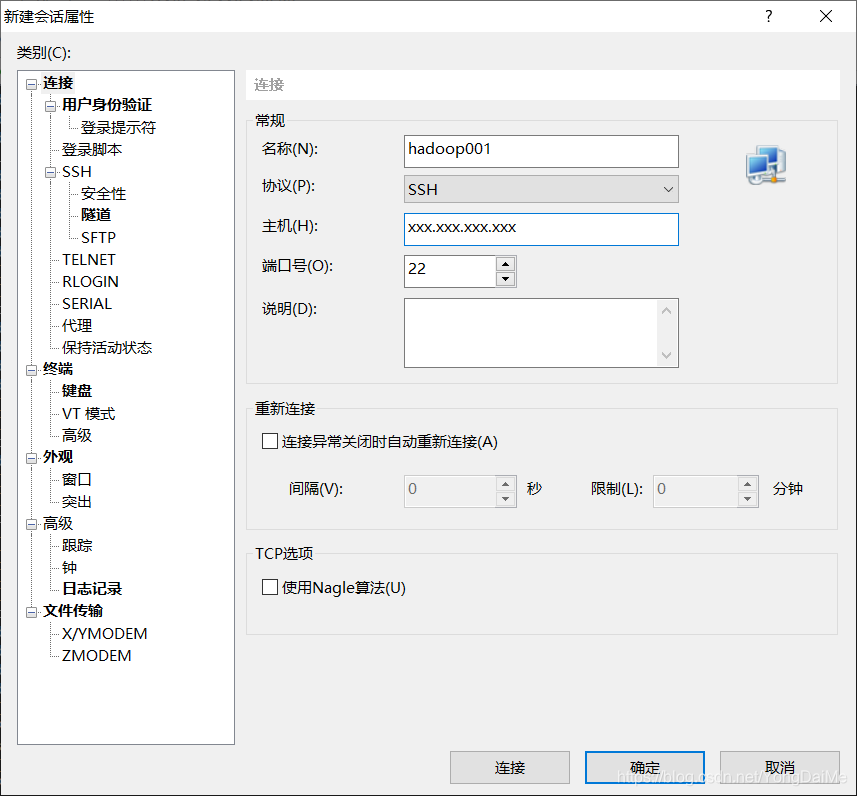
- 第一次登录时,用户名为root,密码为创建实例时输入的密码。如果忘记密码,可以重置。
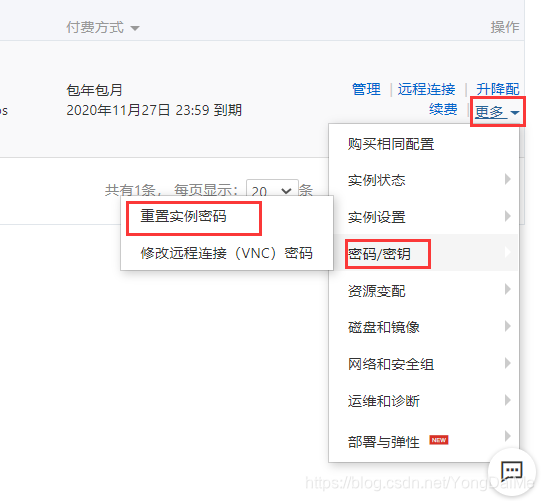
- 重复以上步骤,先用shell工具连接三台实例;
- 登录成功后,先修改主机名。然后配置/etc/hosts文件。配置时需注意,在哪台实例上,就把该实例的私网IP和其他实例的公网IP写入;
# 在三台实例上分别修改主机名 [root@xasdfaffefsgfgerere ~]$ hostnamectl set-hostname node1 # 阿里云实例 [root@fsdgdgnfhfhhdgfggsf ~]$ hostnamectl set-hostname node2 # 华为云实例 [root@dsfsfghfyjkjgjgghfh ~]$ hostnamectl set-hostname node3 # 百度云实例 # 修改主机名后重新连接xshell即可看到更改后的主机名。# 配置hosts文件,让三台实例互相识别 [root@node1 ~]$ vim /etc/hosts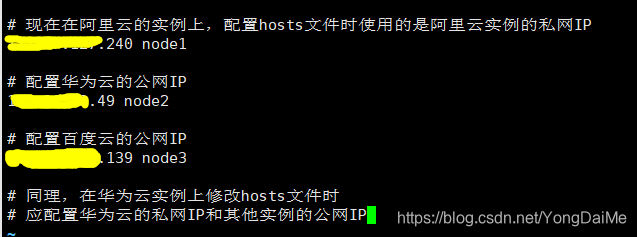
在三台实例上依次执行以上步骤。执行完成后进行验证:在三台实例上分别执行:[root@node1 ~]$ ping node1 [root@node1 ~]$ ping node2 [root@node1 ~]$ ping node3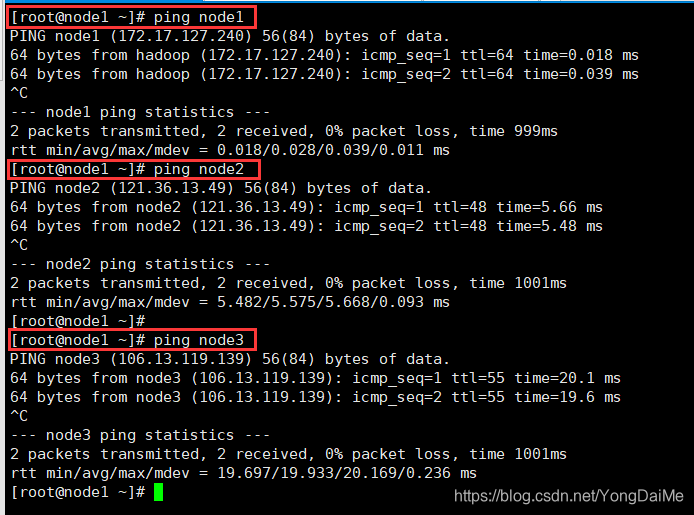
如图即为成功。不过需要注意的是:笔者在操作华为云实例的时候遇到一个问题是无法ping通外网,经过一番折腾后将安全组更改为Sys-default解决了这个问题 - 一般在生产环境下,不同模块都有不同的用户完成。为了贴合实际生产,我们新建一个hadoop用户。
创建好hadoop用户后,将该用户写入sudoers文件中。[root@node1 ~]$ useradd hadoop # 新建一个用户hadoop [root@node1 ~]$ passwd hadoop # 为hadoop用户创建密码[root@node1 ~] vim /etc/sudoers
需要注意的是,保存时应该用wq!命令保存。 - 切换到hadoop用户,开始搭建hadoop环境
[root@node1 ~] su hadoop
特别强调,以上步骤要在三台实例上的root用户下进行。创建hadoop用户后,可以将xshell连接中的配置进行更改,方便操作。
Hadoop完全分布式搭建
在这一部分我将不再赘述,只列出相应的步骤,网上已经有太多搭建的教程了。我的博客中也有。
- 登录hadoop用户,配置SSH免密登录。若没有ssh目录,可以先使用命令ssh node1自动创建。
- 安装JDK,这个很简单,解压后配置环境变量即可。不过需要注意的时,在使用华为云服务器的时候,我忽略了一个细节:华为云服务器的镜像是ARM的,因此应该使用ARM版的JDK。

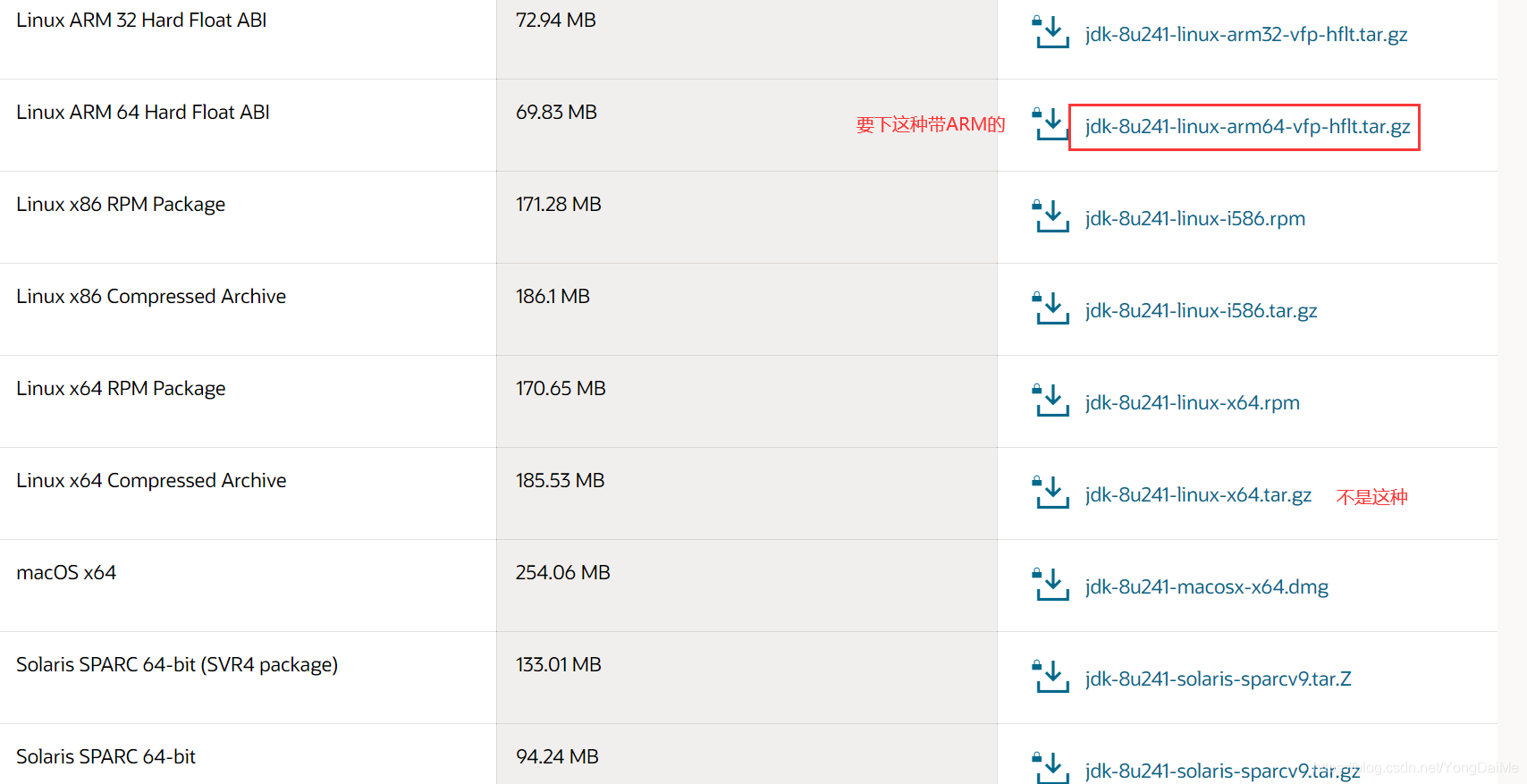
单击此处跳转各版本JDK下载地址 - 配置JDK环境变量,记得source配置文件。scp命令分发;
- 解压Hadoop,修改配置文件,配置环境变量,通过scp命令分发(这个过程非常的慢,因为带宽只有1M,我分发了一两个小时),初始化,启动HDFS和MapReduce。注意主机名不要写错。
- 为了能在本地访问NameNode Web页面,需要开放端口。你的NameNode配置在哪台云服务器上,就在该服务器上开放端口,这里以阿里云为例:
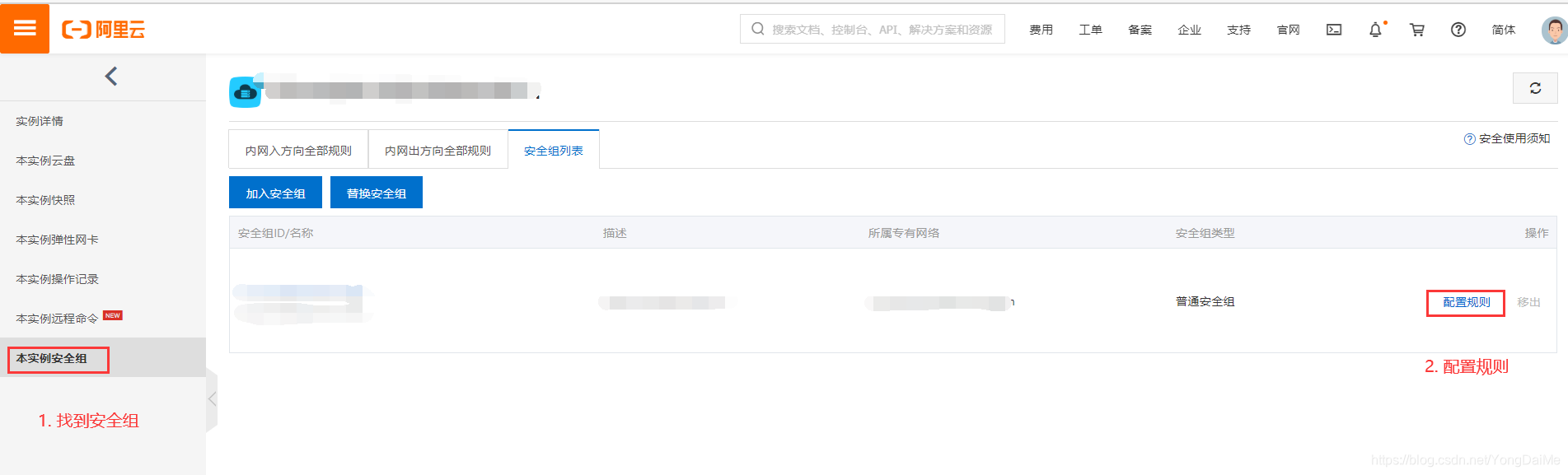
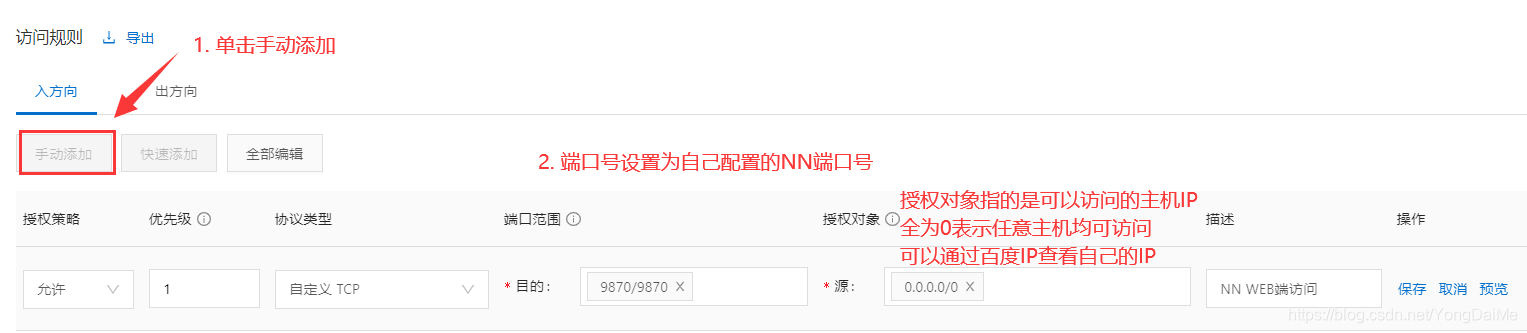
- 到此就可以通过公网IP:9870(看个人配置)的方式直接访问NN页面了。
- 若想通过主机名的方式访问,需要修改本地的 “C:\Windows\System32\drivers\etc\hosts” 文件,将主机名和IP填入(全都是公网IP)














 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









