






一个例子
根据Auto数据集中的数据,建立mpg~hoursepower之间的线性关系。
问题
有如下的问题:
- 在
X
和
Y 之间是否存在关系? - 在
X
和
Y 之间关系的强度如何? - 在
X
和
Y 之间关系是正相关还是负相关? - 当horsepower是98时,95%的置信区间和预测区间分别是多少?
- 画出线性回归图
- 画出诊断图
答案
1.先对数据做初步的描述性分析
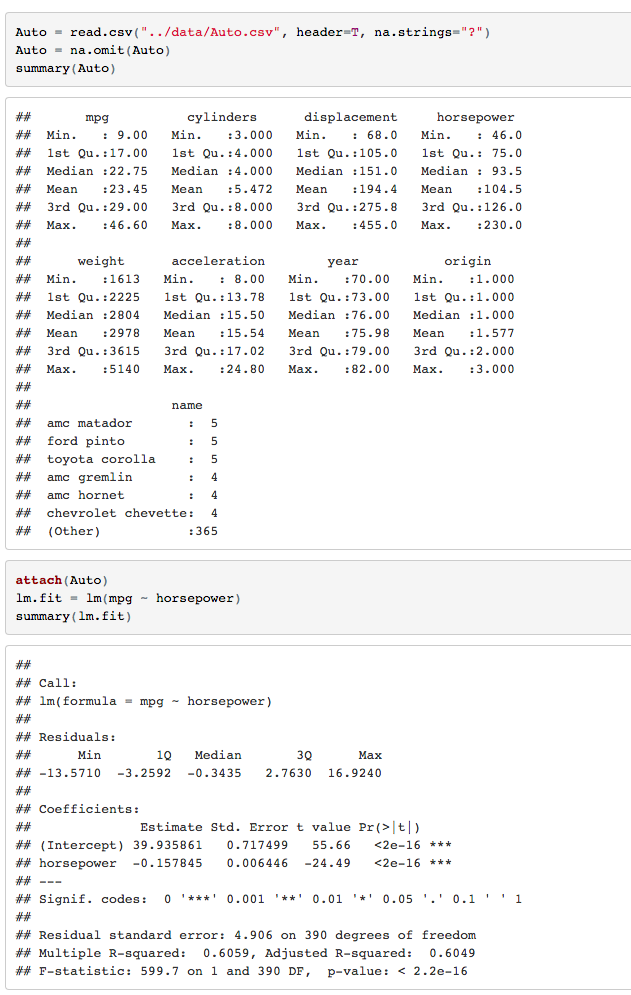
对单个的predicter做是否有效(不等于0)的检验可以使用t-test,但是对整体做是否有效(至少有一个系数不等于0)则需要用F-test。
由上图中,F-statistic:599.7 on 1 and 390 DF, p-value<2.2e-16。
假定虚无假说(所有的系数都为0)为真,因为F检定远远大于1并且其对应的p值非常靠近0,因此我们拒绝虚无假说,承认数据显著性(statistically significant),predicter和responser之间是有关系的。
2.判断模型的强弱有两种方法(RSE和R2)
- RSE:mpg的平均值为23.4459184,lm.fit的RSE(residual standard error)为4.906,两者相除表明残差率为20.92%。
- R2:lm.fit的R2为0.606,意味着mpg有60.6%的方差可以被horsepower解释。
3.相关关系是负相关,因为horsepower的coefficient系数为负。
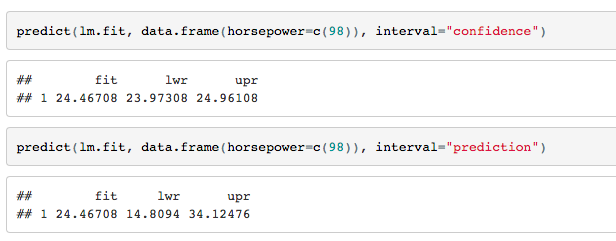
4.置信区间和预测区间如下
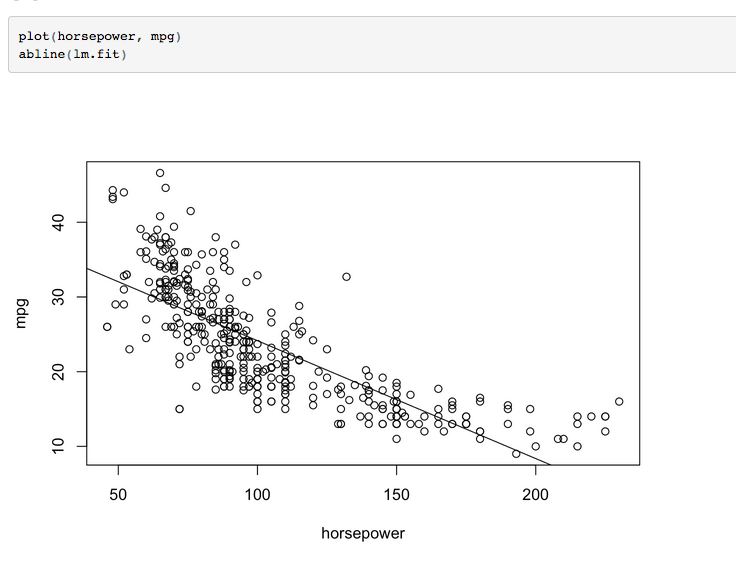
5.线性回归图如下
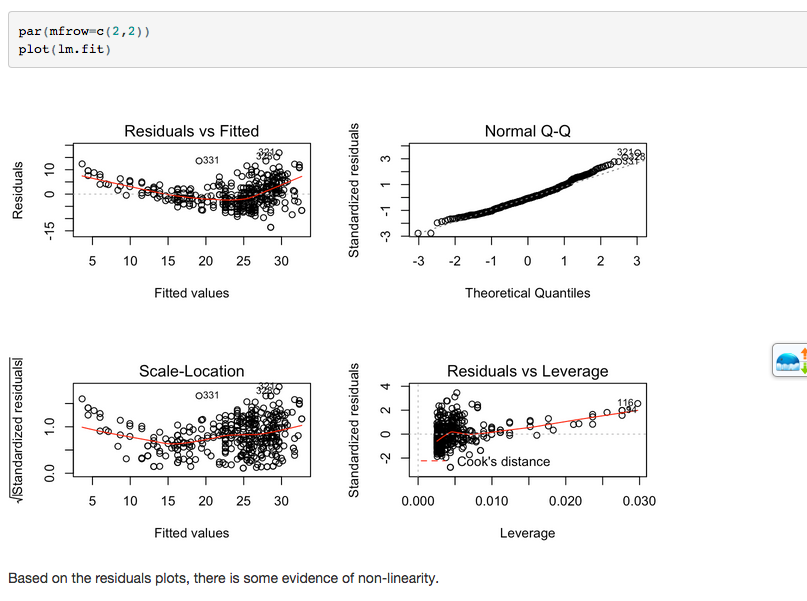
6.诊断图如下
线性回归
回归概述
ϵ 项捕获了所有的误差情况,例如模型非线性、X包含不完全、测量误差等。同时默认误差项 ϵ 独立于 X 。
一些参数
RSS(residual sum of squares)
用样本参数去估计群体参数有多精确,引入了standard error of μ̂
其值域会随着n的增大皱缩,表示了估计量到真实量之间的距离。
对于线性回归

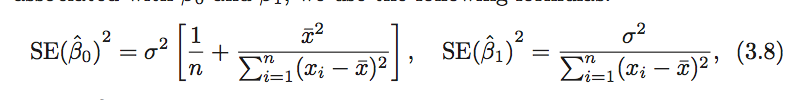
其中,
σ2=Var(ϵ)
。为了让上式有效,应该假定误差项
ϵ
独立不相关且方差一样,但即使不满足问题也不是特别大。
同时,注意到当x分布越广,
SE(β1^)
越小。这和我们的直觉相符合:当数据分布越广泛,对斜率的估计越准确。
值得注意的是,虽然
σ2
(误差项的方差)未知,但是可以从数据集中估计出来,使用的方法为residual standard error,其公式为
RSE可以被用来计算置信区间(confidence intervals),95%的置信区间意味着有95%的概率区间包含真实值,区间具体为
同时, SE(β1^) 还可以进行系数的假设检验,即是否系数离0足够远。如果 SE(β1^) 比较小,那么即使比较小的系数值,检验结果也可能是数据显著的。
通常,我们计算t统计量。
上式测量了 β1 距离0有多少个 SE(β1^) 。如果X和Y真的没有关系,那么我们期望t值会有n-2自由度的t分布(钟形曲线,如果n>30则很接近正态曲线)。
模型精度
RSE
RSE(residual standard error)
RSE通常被认为the lack of fit of the model。如果RSE很小,一般认为模型与数据配合地很好。
R2
R2可以用来衡量多个变量的共同作用效果,相关系数cor一般用来衡量一对变量的相关性。
重要的问题
X和Y之间是否存在关系
使用F检定
F足够大于1则可以证明数据显著性,更具体可以使用p-value。
决定重要的变量
- forward selection:从0变量开始逐个重复增加变量。
- back selection: 从全模型开始移除最大的P值变量。
- mixed selection:先增加,增加的过程中删除变大的且不满足p值要求的变量。
模型拟合
当加入新的变量,R2总是提高的,但是RSE不一定,两者都要参考决定适合的模型。
预测
预测区间比置信区间更广。
协同作用
hierarchical principle所述:如果我们包含了两个变量的协同作用,那么初始作用也得包括,即使p值检定不是数据显著。
非线性关系
可以利用多项式构建非线性关系。
潜在的问题
非线性
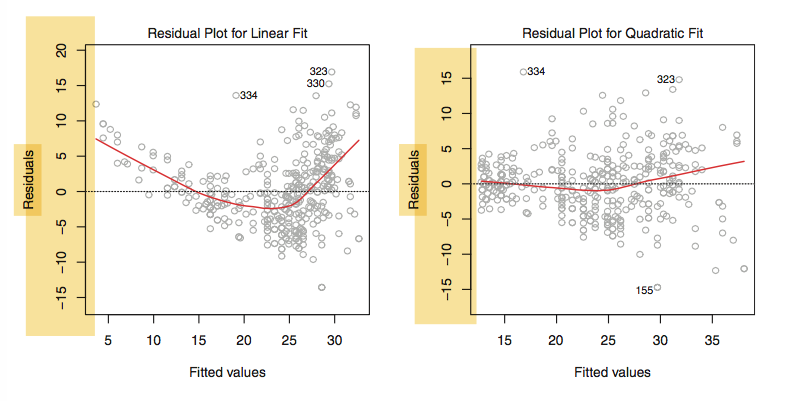
我们可以尝试
logX,X‾‾√,X2
等非线性参数。
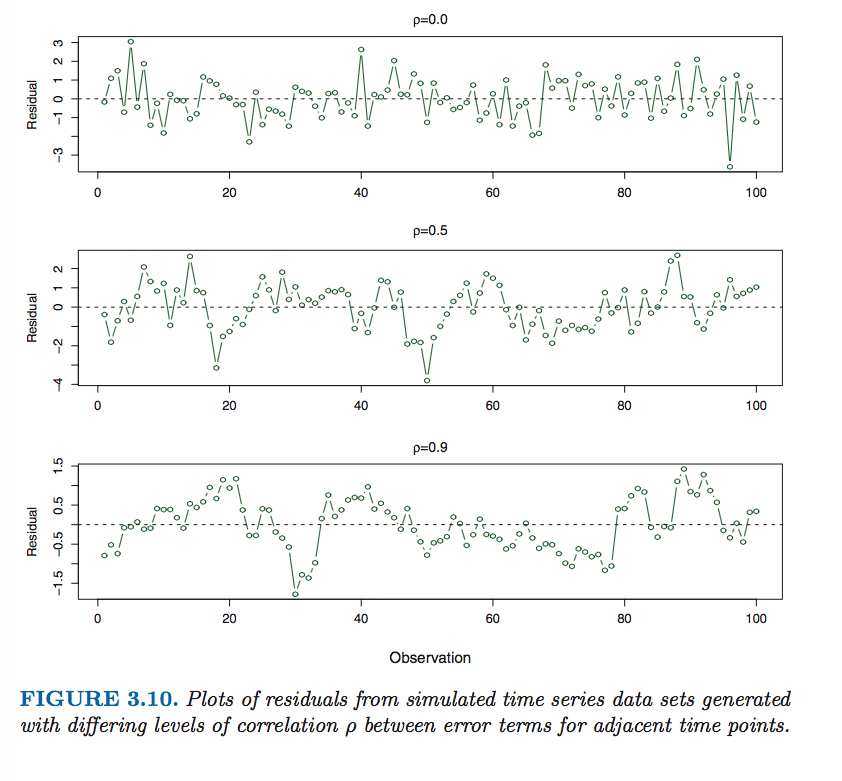
误差项的相关性
如果误差项相关,那么置信区间将会比应该的更窄,变得没有保障。
误差项的非常数
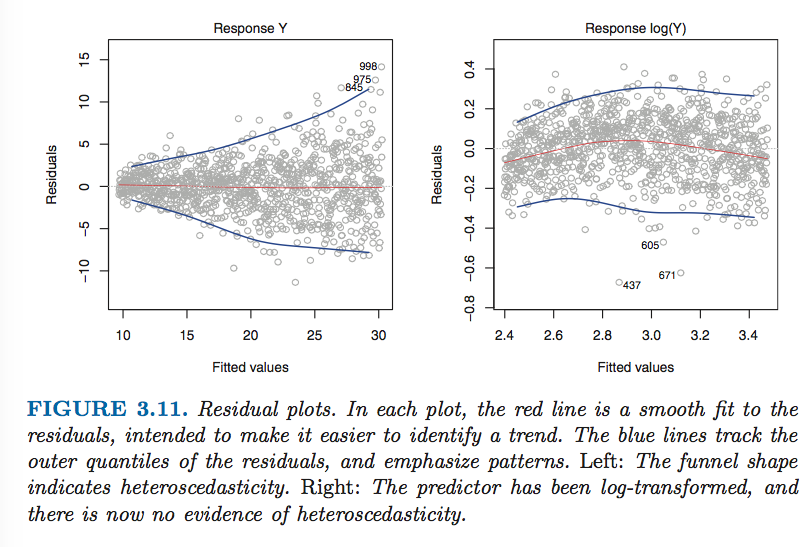
遇到上述情况,可以使用
logY、Y‾‾√
。
越值点
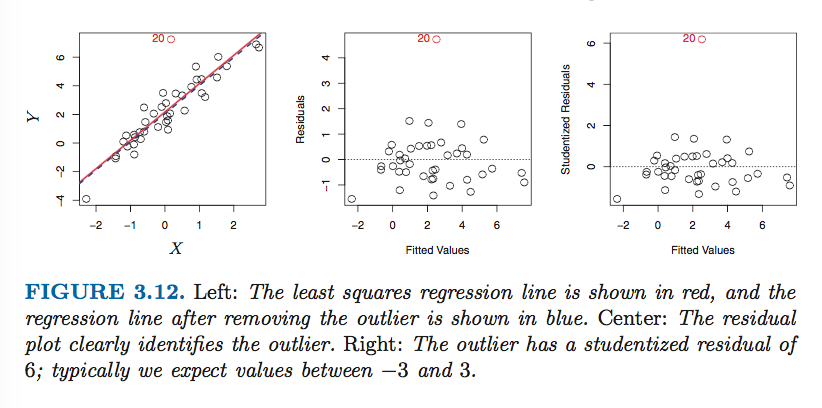
通常把studentized residual>3的点认为是outlier。
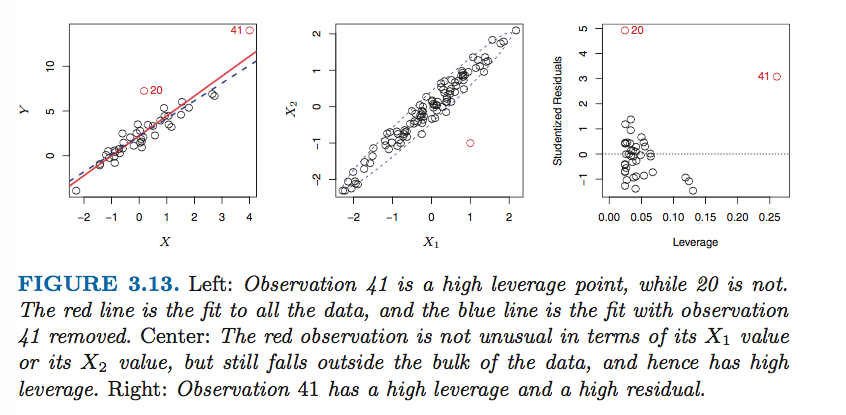
杠杆点
越值点只有杠杆足够大时,才有很大的效果。
共线性
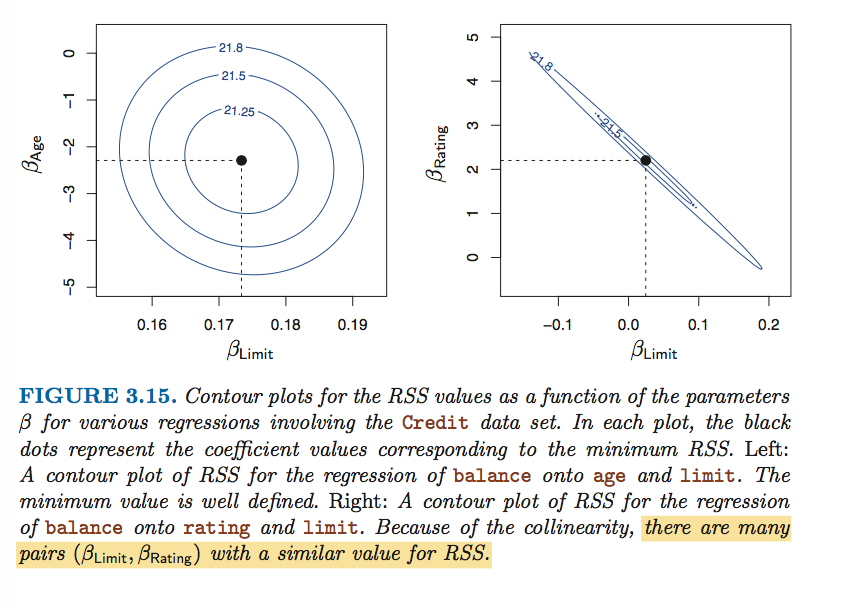
共线性会导致最值的RSS的范围变大,导致系数估计的不确定性增大(置信区间变大),
SE(β)
变大,t值变小,很可能导致显著性检验失败,偏向于虚无假设。
检查共线性,有两种方法:
1.相关矩阵:适应与成对变量的共线性
2.VIF(variance inflation factor),其超过5和10则意味着共线性的存在。
线性回归与KNN的比较
线性回归是参数性的方法,事先假定了模型,KNN则不然,其K值越小,灵活性越大,意味着更高的variance和更小的bias。
理论上,非参数的方法在线性情况下略差于LR,在非线性的情况下极好于LR。
但是,现实情况一般是高维的,维度的增高对LR的MSE影响较小,但是对KNN的影响极大,在高维空间中会造成样本数的相对减少,名之curse of dimension。
参考
- ISLR Fourth Printing














 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









