






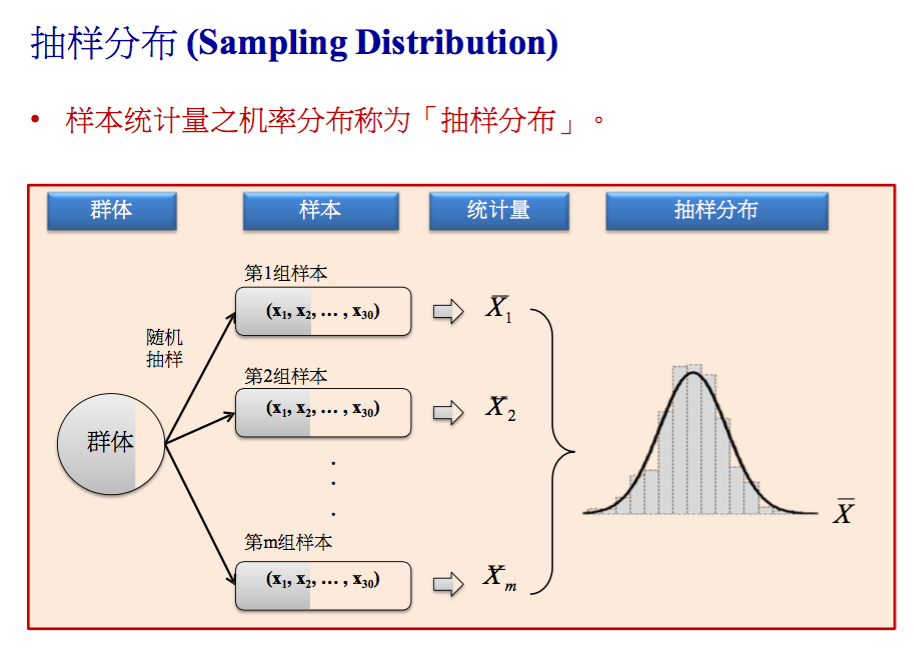
抽样分布与中央极限定理
抽样分布
从群体中抽取样本,样本统计量的几率分布称为抽样分布。
中央极限定理
从均值为 μ ,方差为 σ2 的群体中,以放回抽样的方法抽取样本大小为 n 的样本,当
n 足够大( n>=30 )时,样本均值的抽样分布近似服从均值 μ ,方差 σ2/n 的正态分布。

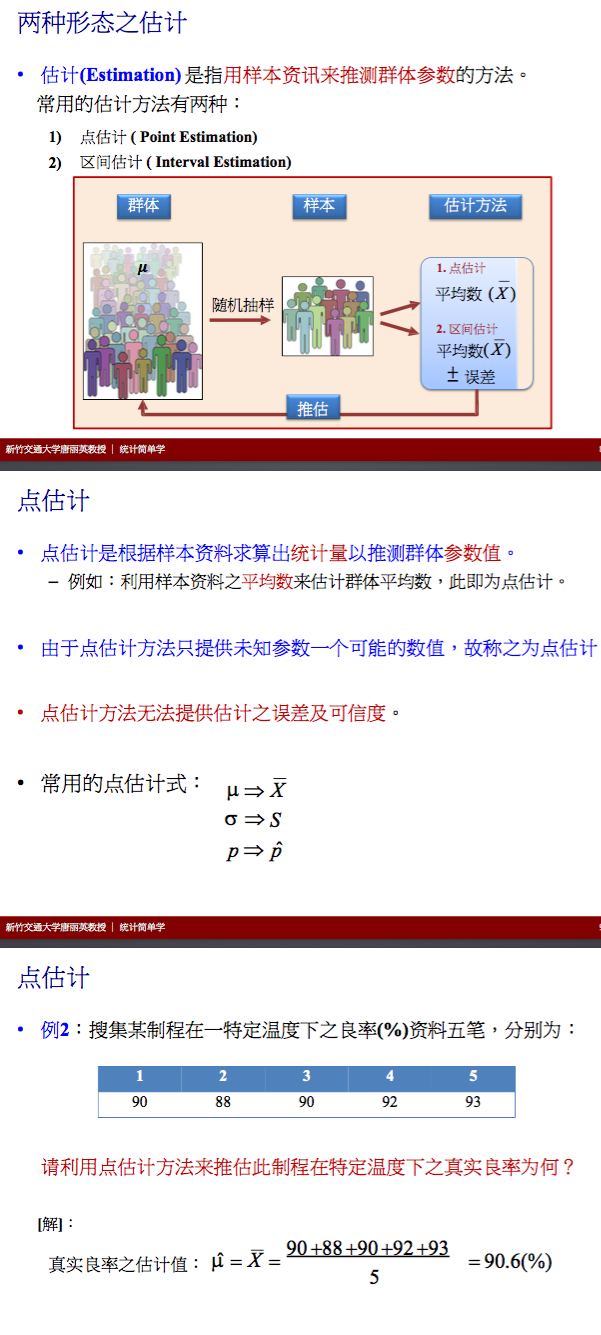
估计方法简介
估计分为
- 点估计
- 区间估计
点估计
区间估计
区间估计,首先找到所求值的点估计,然后根据数据获得所求值得抽样分布,确定信赖水平(可信度),最后得到相应信赖水平下的信赖区间。

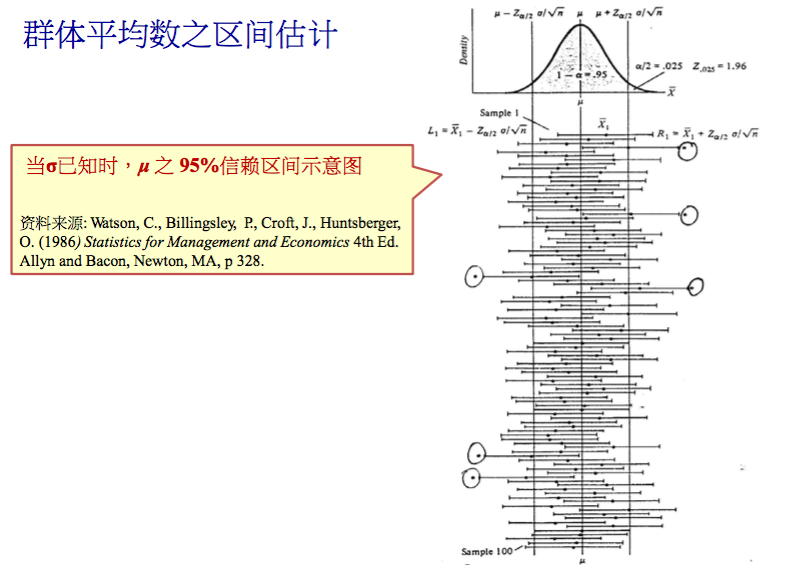
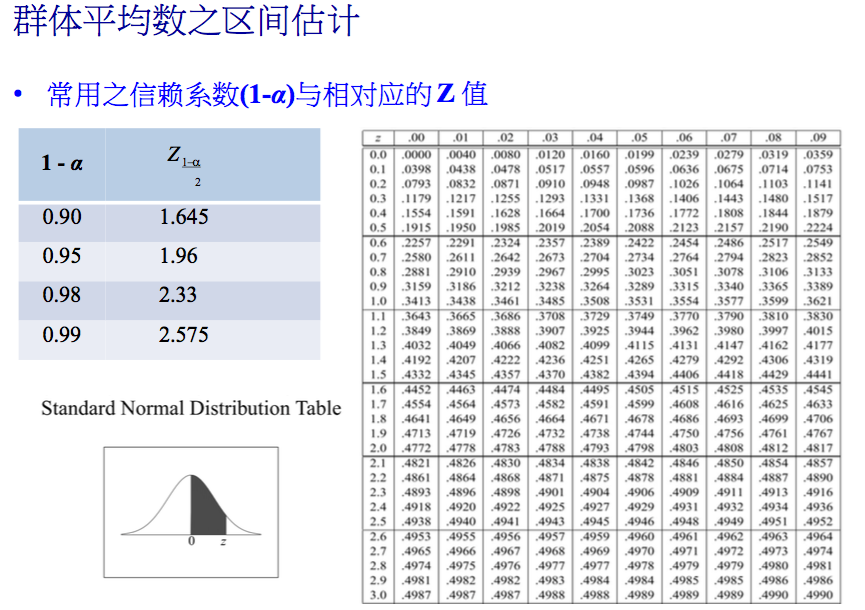
群体平均数 μ 的(1- α )信赖区间
总体原则
- 根据中心极限定理,n足够大时,样本平均值的抽样分布近似为正态分布,可以用z分布或者t分布来近似。
- 当群体方差已知的时候,不需要使用样本方差去估计总体方差,使用z检验。
- 当群体方差未知的时候,原则上应使用样本方差估计总体方差,使用t检验。但是当样本数目大于30的时候,t检验和z检验结果相当接近,为了方便计算采用z检验。
方差已知

方差未知且为大样本

信赖区间的含义
95%信赖区间的含义是:样本数目不变的情况下,做一百次实验,得到一百个置信区间,共有95个置信区间包含了群体的真值。置信度为95%。
因为100个置信区间有95个都会包含真值,所以我们用95%置信度的置信区间包含真值的可能性就很大。
信赖区间与z值图
例子

方差未知
t分布区间估计公式

t分布简介

t分布性质
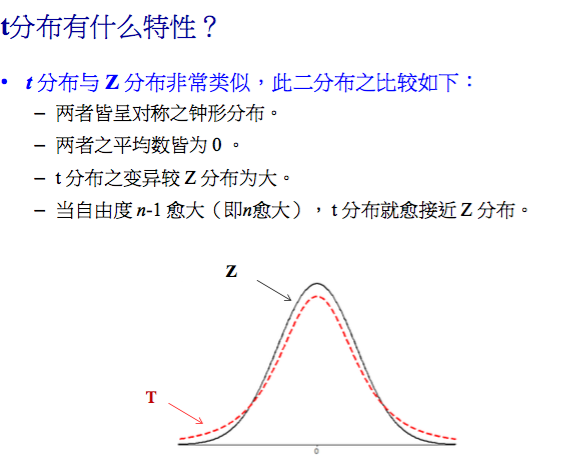
t分布几率表与t值计算
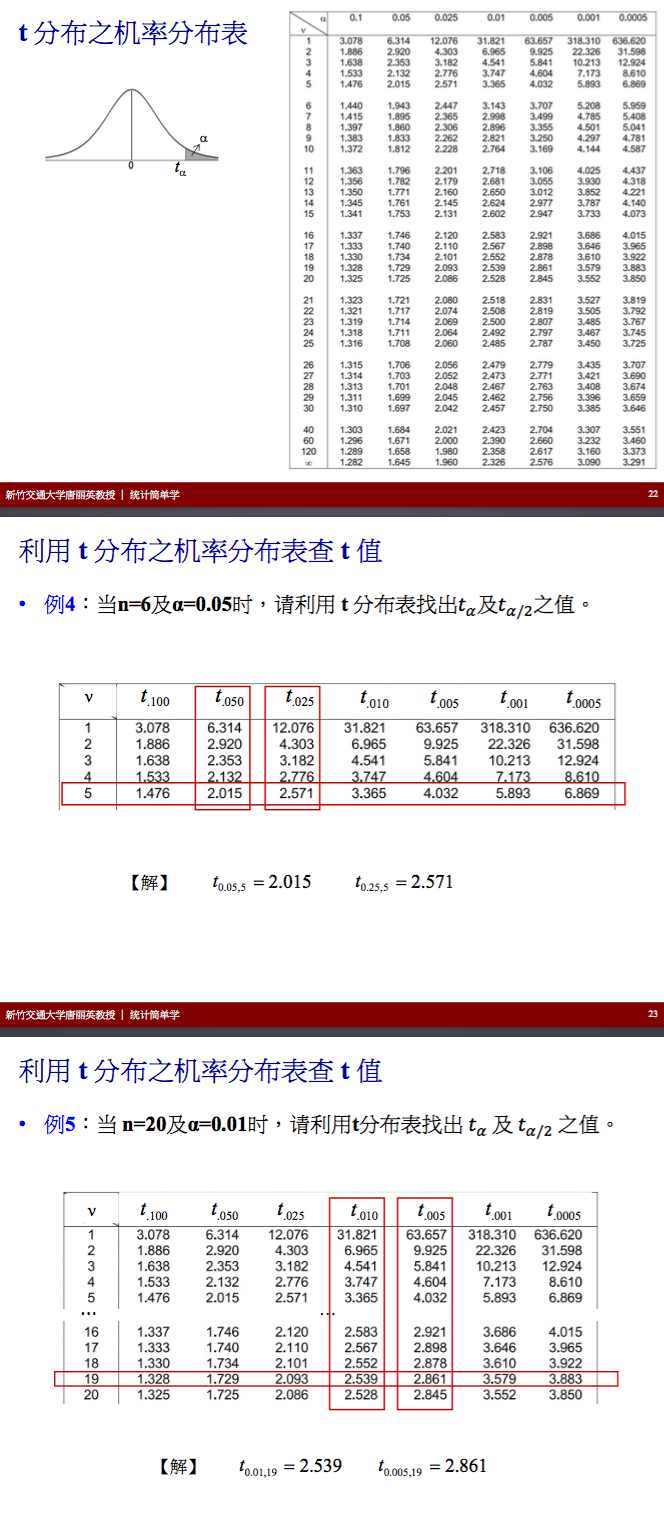
例子

群体比率值
P
的(1-α )信赖区间

群体方差 σ2 的(1- α )信赖区间
公式

卡方分布及其几率表
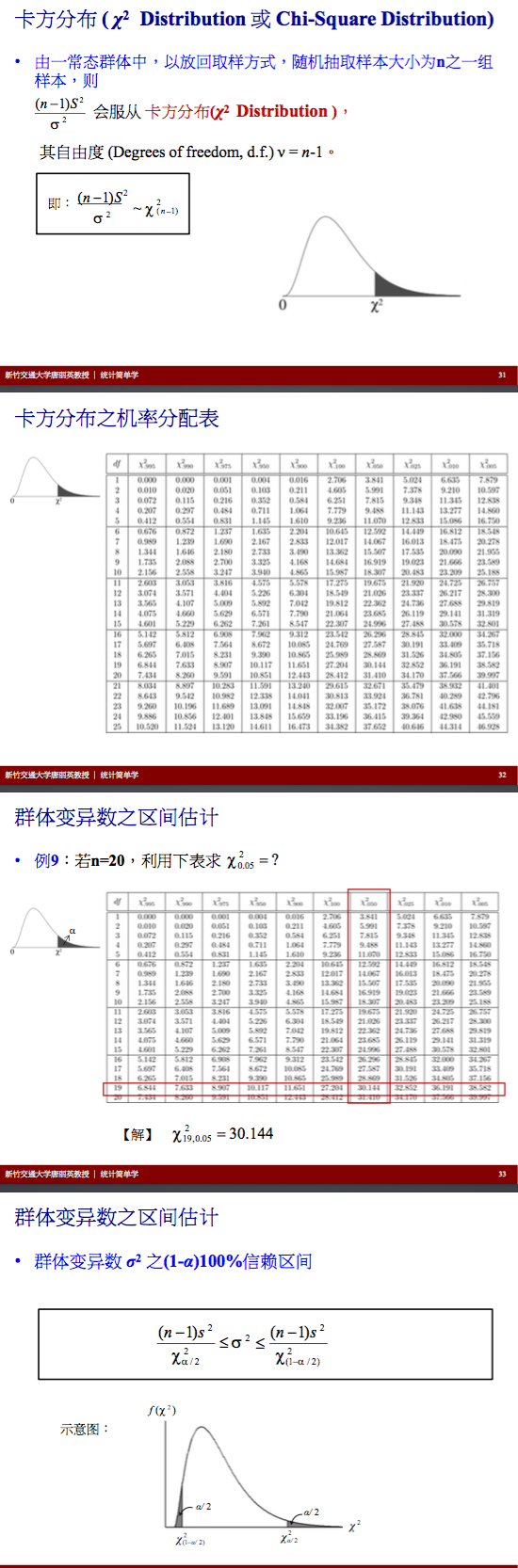
例子
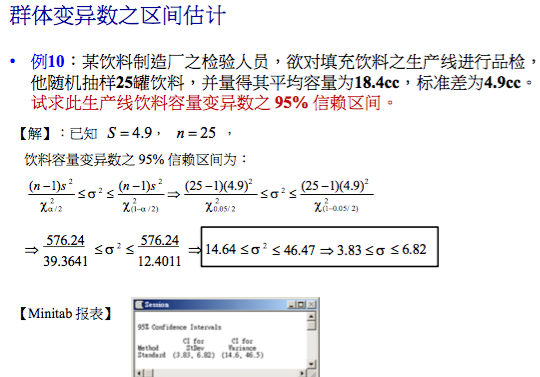
样本大小之决定
样本大小的决定,受限于误差和置信度。
估计平均数时

估计比率时

回顾

R语言实践
#第一组为均值0的正态分布,第二组为均值0.1的正态分布
data = rnorm(100)
data2 = rnorm(100,mean = 0.1)
#画数据的密度图和直方图
plot(density(data))
hist(data)
#检验数据是否是正态分布
#p<0.05则拒绝正态分布的假设
shapiro.test(data)
shapiro.test(data2)
qqnorm(data);qqline(data,col=2)
qqnorm(data2);qqline(data2,col=2)
#对数据的平均数用t检验,查看95%置信区间以及平均数的显著程度。
t.test(data)
t.test(data,conf.level = 0.9)
t.test(data2,mu=0.1)
#自定义函数,可以求已知或未知群体方差的任意alpha水平的平均数的置信区间
confint <- function(x,sigma=-1,alpha=0.05) {
n = length(x)
xb = mean(x)
#z-distribution
if(sigma>=0){
tmp = sigma/sqrt(n)*qnorm(1-alpha/2)
df = n
}
else{
tmp = sd(x)/sqrt(n)*qt(1-alpha/2,n-1)
df = n-1
}
data.frame(mean=xb,df=df,a=xb-tmp,b=xb+tmp)
}
confint(data)
confint(data2)
#对比例进行检定
prop.test(83,100,.75,conf.level = .9)
prop.test(30,500,.75)
binom.test(83,100,.75,conf.level = .9)
#对方差进行检定
var.interval = function(data,conf.level=0.95){
df = length(data)-1
chilower = qchisq((1-conf.level)/2,df)
chiupper = qchisq((1-conf.level)/2,df,lower.tail = FALSE)
v = var(data)
c(df*v/chiupper, df*v/chilower)
}
#对置信区间取样,解释置信区间
#lizard tail length data
lizard = c(6.2,6.6,7.1,7.4,7.6,7.9,8,8.3,8.4,8.5,8.6,
8.8,8.8,9.1,9.2,9.4,9.4,9.7,9.9,10.2,10.4,10.8,
11.3,11.9)
#采样数据
n.draw = 100
mu = 9
n = length(lizard)
SD = sd(lizard)
draws = matrix(rnorm(n.draw*n,mu,SD),n)
#针对100个样本,分别计算其置信区间
get.conf.int = function(x) t.test(x)$conf.int
conf.int = apply(draws,2,get.conf.int)
sum(conf.int[1,] <= mu & mu<=conf.int[2,])
#可视化
plot(range(conf.int),c(0,1+n.draw),type="n",xlab="mean tail length",ylab="sample run")
for(i in 1:n.draw) lines(conf.int[,i],rep(i,2),lwd=2)
abline(v=9,lwd=2,lty=2,col=2)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









