







一、如何高效率地实现k近邻法?
在SIFT图像特征匹配等应用中,需要在高维特征空间中快速找到距离目标图像特征最近邻的那个特征点,往往需要进行比较的特征向量的数量很大,如果进行朴素最近邻搜索,也就是依次计算目标点和每一个待匹配特征的距离,然后再算出最短距离这样的策略,那么特征匹配算法的时间复杂度将会高得令人难以接受。因此,我们需要借助一种存储和表示k维数据的数据结构,既能够方便地存储k维数据,又能够进行高效率的搜索。
二、k-d树的基本思想
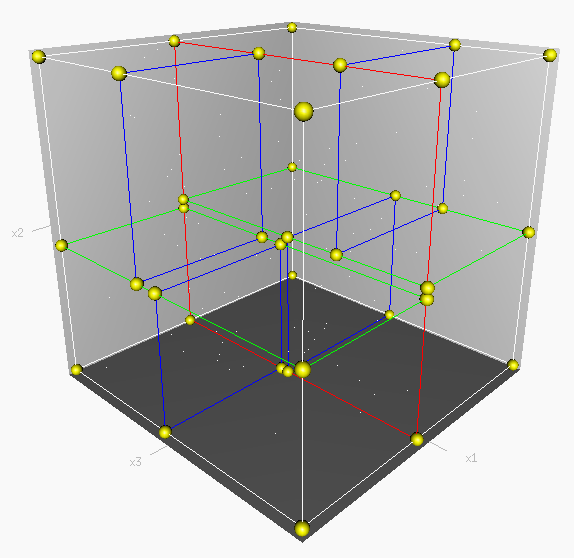
k-d树由斯坦福大学本科生Jon Louis Bentley于1975年首次提出。k-d树是每个节点都为k维点的二叉树。其中k表示存储的数据的维度,d就是dimension的意思。所有非叶子节点可以视作用一个超平面把空间分割成两部分。在超平面左边的点代表节点的左子树,在超平面右边的点代表节点的右子树。超平面的方向可以用下述方法来选择:每个节点都与k维中垂直于超平面的那一维有关。因此,如果选择按照x轴划分,所有x值小于指定值的节点都会出现在左子树,所有x值大于指定值的节点都会出现在右子树。这样,超平面可以用该x值来确定,其法矢为x轴的单位向量。一个三维空间内的3-d树如下所示:
当特征空间维度大于20时,k-d tree算法的性能会剧烈下降,对于高维数据,David Lowe在1997的一篇文章中提出一种近似算法best-bins-first,可以有效改善这种情况。
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形结构。kd树从本质上来说是二叉树,表示对k维空间的一个划分。构造kd树相当于不断地用垂直于坐标轴的超平面切分k维空间,构成一系列的k维超矩形区域,kd树的每一个结点都对应于一个超矩形区域,非叶结点的左右子树分别表示划分得到的两个区域。在2维情形,当划分超平面平行于x轴时,在划分超平面以下的数据点将存储在此划分结点的左子树,在超平面以上的点存储在此划分结点右子树;若划分超平面平行于y轴,在划分超平面左侧的数据点将存储在此划分结点的左子树,在超平面右侧的点存储在此划分结点右子树。
构造kd树的方法:首先构造根节点,根节点对应于整个k维空间,包含所有的实例点,(至于如何选取划分点,有不同的策略。最常用的是一种方法是:对于所有的样本点,统计它们在每个维上的方差,挑选出方差中的最大值,对应的维就是要进行数据切分的维度。数据方差最大表明沿该维度数据点分散得比较开,这个方向上进行数据分割可以获得最好的分辨率;然后再将所有样本点按切分维度的值进行排序,位于正中间的那个数据点选为分裂结点。)。然后利用递归的方法,分别构造k-d树根节点的左右子树。在超矩形区域上选择一个坐标轴(切分维度)和一个分裂结点,以通过此分裂结点且垂直于切分方向坐标轴的直线作为分隔线,将当前超矩形区域分隔成左右或者上下两个子超矩形区域,对应于分裂结点的左右子树的根节点。实例也就被分到两个不相交的区域中。重复此过程直到子区域内没有实例点时终止。终止时的结点为叶结点。
通常依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数为切分点,这样得到的kd树是平衡的,但并不一定能保证检索的效率最优。
三、k-d tree的实现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5916
5916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









