









rocksdb提供benchmark工具来对自身性能进行全方位各个纬度的评估,包括顺序读写,随机读写,热点读写,删除,合并,查找,校验等性能的评估,十分好用。
1. 工具编译
这里使用的是cmake的方式,主要是为了在自己用户下指定对应的第三方库的路径(glfags等)以及指定是否开启rocksdb自己的压缩算法编译,否则直接make 原生的Makefile问题较多且 db_bench所依赖的一些库都没法自动链接进去(zstd,snappy等压缩算法 默认是不编译到db_bench中的)
如果你的db_bench工具已经安装好了,可以跳过当前步骤,如果没有编译好,不想这么麻烦,可以直接看下面,会提供一个整体的便捷编译脚本。
基本流程如下:
- 下载rocksdb源码
如果需要指定对应的版本,可以下载好之后执行git clone https://github.com/facebook/rocksdb.git
git branch xxx切换到对应版本的分支 - 第三方库的编译安装
a. gflags
b. 安装a. git clone https://github.com/gflags/gflags.git b. cd gflags c. mkdir build && cd build #以下DCMAKE_INSTALL_PREFIX 之后的路径为自己想要安装的路径,如果有root权限且可以安装到系统目录下,那么可以不用指定prefix选项,BUILD_SHARED_LIBS选项表示开启编译gflags的动态库,否则默认不编译动态库 d. cmake .. -DCMAKE_INSTALL_PREFIX=/xxx -DBUILD_SHARED_LIBS=1 -DCMAKE_BUILD_TYPE=Release e. make && make install #增加gflags的include 和 lib库的路径到系统库下面,如上面未指定路径,则系统默认安装在 #/usr/local/gflags f. 编辑当前用户下的bashrc,添加如下内容: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/xxx/gcc-5.3/lib64:/xxx/gflags/lib export LIBRARY_PATH=$LIBRARY_PATH:/xxx/gflags/includesnappy
sudo yum install snappy snappy-devel
c. 安装zlib
yum install zlib zlib-devel
d. 安装bzip2
yum install bzip2 bzip2-devel
e.安装lz4
yum install lz4-devel
f. 安装zstardardwget https://github.com/facebook/zstd/archive/v1.1.3.tar.gz mv v1.1.3.tar.gz zstd-1.1.3.tar.gz tar zxvf zstd-1.1.3.tar.gz cd zstd-1.1.3 make && sudo make install - 生成makefile
cd rocksdb && mkdir build #以下的prefix路径需要指定安装gflags的prefix路径,否则编译过程中无法链接到gflags的库 #如果cmake 版本过低,使用cmake3 #DWITH_xxx 表示开启几个压缩算法的编译选项,否则运行db_bench时rocksdb产生数据压缩的时候无法找到对应的库 cmake .. -DCMAKE_PREFIX_PATH=/xxx -DWITH_SNAPPY=1 -DWITH_LZ4=1 -DWITH_ZLIB=1 -DWITH_ZSTD=1 -DCMAKE_BUILD_TYPE=Release=release - 编译
以上会通过上级目录的CMakeList.txt 在当前目录生成Makefile,最终执行编译make -j
成功后db_bench工具会在当前目录下生成。
编译脚本如下,那一些压缩算法的lib还是需要提前装好的。
#!/bin/sh
set -x
# build gflags
function build_gflags()
{
local source_dir
local build_dir
# dir is exists, there is no need to clone again
if [ -e "gflags" ] && [ -e "gflags/build" ]; then
return
fi
git clone https://github.com/gflags/gflags.git
if [ $? -ne 0 ]; then
echo "git clone gflags failed."
fi
cd gflags
source_dir=$(pwd)
build_dir=$source_dir/build
mkdir -p "$build_dir"/ \
&& cd "$build_dir"/ \
&& cmake3 .. -DCMAKE_INSTALL_PREFIX="$build_dir" -DBUILD_SHARED_LIBS=1 -DBUILD_STATIC_LIBS=1 \
&& make \
&& make install \
&& cd ../../
}
git submodule update --init --recursive
build_gflags
SOURCE_DIR=$(pwd)
BUILD_DIR="$SOURCE_DIR"/build
GFLAGS_DIR=gflags/build
# for using multi cores parallel compile
NUM_CPU_CORES=$(grep "processor" -c /proc/cpuinfo)
if [ -z "${NUM_CPU_CORES}" ] || [ "${NUM_CPU_CORES}" = "0" ] ; then
NUM_CPU_CORES=1
fi
mkdir -p "$BUILD_DIR"/ \
&& cd "$BUILD_DIR"
cmake3 "$SOURCE_DIR" -DCMAKE_BUILD_TYPE=Release -DWITH_SNAPPY=ON -DWITH_TESTS=OFF -DCMAKE_PREFIX_PATH=$GFLAGS_DIR
make -j $NUM_CPU_CORES
2. 基本性能压测
由于db_bench工具的选项太多了,这里直接提取社区的测试方式
核心是benchmark,它代表本次测试使用的压测方式,benchmark的列表如下
fillseq -- write N values in sequential key order in async mode
fillseqdeterministic -- write N values in the specified key order and keep the shape of the LSM tree
fillrandom -- write N values in random key order in async mode
filluniquerandomdeterministic -- write N values in a random key order and keep the shape of the LSM tree
overwrite -- overwrite N values in random key order in async mode
fillsync -- write N/100 values in random key order in sync mode
fill100K -- write N/1000 100K values in random order in async mode
deleteseq -- delete N keys in sequential order
deleterandom -- delete N keys in random order
readseq -- read N times sequentially
readtocache -- 1 thread reading database sequentially
readreverse -- read N times in reverse order
readrandom -- read N times in random order
readmissing -- read N missing keys in random order
readwhilewriting -- 1 writer, N threads doing random reads
readwhilemerging -- 1 merger, N threads doing random reads
readrandomwriterandom -- N threads doing random-read, random-write
prefixscanrandom -- prefix scan N times in random order
updaterandom -- N threads doing read-modify-write for random keys
appendrandom -- N threads doing read-modify-write with growing values
mergerandom -- same as updaterandom/appendrandom using merge operator. Must be used with merge_operator
readrandommergerandom -- perform N random read-or-merge operations. Must be used with merge_operator
newiterator -- repeated iterator creation
seekrandom -- N random seeks, call Next seek_nexts times per seek
seekrandomwhilewriting -- seekrandom and 1 thread doing overwrite
seekrandomwhilemerging -- seekrandom and 1 thread doing merge
crc32c -- repeated crc32c of 4K of data
xxhash -- repeated xxHash of 4K of data
acquireload -- load N*1000 times
fillseekseq -- write N values in sequential key, then read them by seeking to each key
randomtransaction -- execute N random transactions and verify correctness
randomreplacekeys -- randomly replaces N keys by deleting the old version and putting the new version
timeseries -- 1 writer generates time series data and multiple readers doing random reads on id
-
创建一个db,并写入一些数据
./db_bench --benchmarks="fillseq"
但是这样并不会打印更多有效的元信息DB path: [/tmp/rocksdbtest-1001/dbbench] fillseq : 2.354 micros/op 424867 ops/sec; 47.0 MB/s -
创建一个db,并打印一些元信息
./db_bench --benchmarks="fillseq,stats"
--benchmarks表示测试的顺序,支持持续叠加。本次就是顺序写之后打印db的状态信息。
这样会打印db相关的stats信息,包括db的stat信息和compaction的stat信息DB path: [/tmp/rocksdbtest-1001/dbbench] # 测试顺序写的性能信息 fillseq : 2.311 micros/op 432751 ops/sec; 47.9 MB/s ** Compaction Stats [default] ** Level Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) CompMergeCPU(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- L0 1/0 28.88 MB 0.2 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 60.6 0.48 0.31 1 0.477 0 0 Sum 1/0 28.88 MB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 60.6 0.48 0.31 1 0.477 0 0 Int 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 60.6 0.48 0.31 1 0.477 0 0 ** Compaction Stats [default] ** Priority Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) CompMergeCPU(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- High 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 60.6 0.48 0.31 1 0.477 0 0 Uptime(secs): 2.3 total, 2.3 interval Flush(GB): cumulative 0.028, interval 0.028 AddFile(GB): cumulative 0.000, interval 0.000 AddFile(Total Files): cumulative 0, interval 0 AddFile(L0 Files): cumulative 0, interval 0 AddFile(Keys): cumulative 0, interval 0 Cumulative compaction: 0.03 GB write, 12.34 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.5 seconds Interval compaction: 0.03 GB write, 12.50 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.5 seconds Stalls(count): 0 level0_slowdown, 0 level0_slowdown_with_compaction, 0 level0_numfiles, 0 level0_numfiles_with_compaction, 0 stop for pending_compaction_bytes, 0 slowdown for pending_compaction_bytes, 0 memtable_compaction, 0 memtable_slowdown, interval 0 total count ** File Read Latency Histogram By Level [default] ** ** DB Stats ** Uptime(secs): 2.3 total, 2.3 interval Cumulative writes: 1000K writes, 1000K keys, 1000K commit groups, 1.0 writes per commit group, ingest: 0.12 GB, 53.39 MB/s Cumulative WAL: 1000K writes, 0 syncs, 1000000.00 writes per sync, written: 0.12 GB, 53.39 MB/s Cumulative stall: 00:00:0.000 H:M:S, 0.0 percent Interval writes: 1000K writes, 1000K keys, 1000K commit groups, 1.0 writes per commit group, ingest: 124.93 MB, 54.06 MB/s Interval WAL: 1000K writes, 0 syncs, 1000000.00 writes per sync, written: 0.12 MB, 54.06 MB/s Interval stall: 00:00:0.000 H:M:S, 0.0 percent更多的meta operation操作如下
- compact 对整个数据库进行合并
- stats 打印db的状态信息
- resetstats 重置db的状态信息
- levelstats 打印每一层的文件个数以及每一层的占用的空间大小
- sstables 打印sst文件的信息
对应的sstables和levelstats显示信息如下
--- level 0 --- version# 2 --- 7:30286882[1 .. 448148]['00000000000000003030303030303030' \ seq:1, type:1 .. '000000000006D6933030303030303030' seq:448148, type:1](0) --- level 1 --- version# 2 --- --- level 2 --- version# 2 --- --- level 3 --- version# 2 --- --- level 4 --- version# 2 --- --- level 5 --- version# 2 --- --- level 6 --- version# 2 --- Level Files Size(MB) -------------------- 0 1 29 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 -
单独随机写测试
相关的参数可以自己配置,这里仅仅列出一部分参数
可以通过./db_bench --help自己查看想要的配置参数,当然配置前需要对各个参数有一定的了解。./db_bench \ --benchmarks="fillrandom,stats,levelstats" \ --enable_write_thread_adaptive_yield=false \ --disable_auto_compactions=false \ --max_background_compactions=32 \ --max_background_flushes=4 \ --write_buffer_size=536870912 \ --min_write_buffer_number_to_merge=2 \ --max_write_buffer_number=6 \ --target_file_size_base=67108864 \ --max_bytes_for_level_base=536870912 \ --compression_type=none \ #关闭压缩 --num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止 --duration=30 \ #持续IO的时间是30秒 --threads=1000\ #并发1000个线程 --value_size=8192\ #value size是8K --key_size=16 \ #key size 16B --enable_pipelined_write=true \ --db=./db_bench_test \ #指定创建db的目录 --wal_dir=./db_bench_test \ #指定创建wal的目录 --allow_concurrent_memtable_write=true \ #允许并发写memtable --disable_wal=false \ --batch_size=1 \ --sync=false \ #是否开启sync在这个workload下,每一次benchmark db_bench都会重新创建db,可能是遗留原因。而有的时候,我们想要在原有db之前追加一定条目的请求,并不希望之前的db被清理掉。可以这样简单更改一下db_bench的代码:
我们使用fillrandomworkload的时候,搭配use_existing_db=1默认会退出
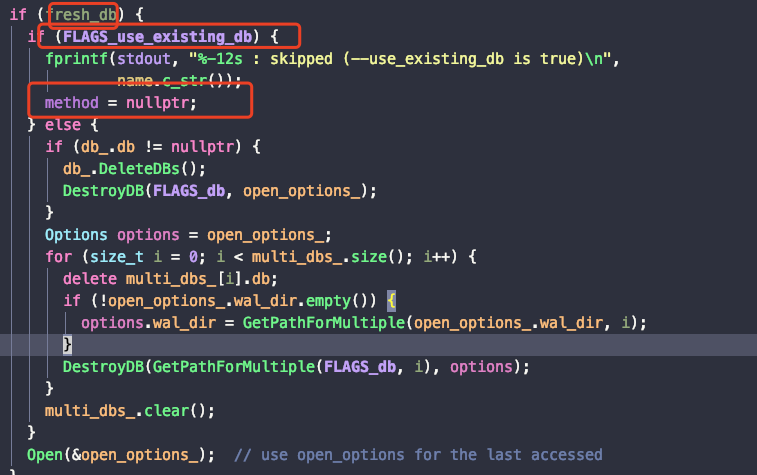
这个时候我们只需要将,fillrandom workload下的fresh_db 更改为false就可以继续测试了,每一次fillrandom都会在之前的基础上增加条目,而不会destory之前的db。

-
随机读
使用之前fillrandom创建的db,进行随机读取,需要开启use_existing_keys=1和use_existing_db=1,否则都会是not-found,被bloom-filter过滤,不会命中之前写入的数据。./db_bench \ --benchmarks="fillseq,stats,readrandom,stats" --enable_write_thread_adaptive_yield=false \ --disable_auto_compactions=false \ --max_background_compactions=32 \ --max_background_flushes=4 \ --write_buffer_size=536870912 \ --min_write_buffer_number_to_merge=2 \ --max_write_buffer_number=6 \ --target_file_size_base=67108864 \ --max_bytes_for_level_base=536870912 \ --use_existing_keys=1 \ #建议使用已存在key进行读,否则就一直被filter过滤掉,打不到磁盘,测试不精确 --use_existing_db=1 \ --cache_size=2147483648 \ #2G的block-cache,默认是8M,实际生产环境,如果read-heavy应该设置为内存大小的三分之一。 --num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止 --duration=30 \ #持续IO的时间是30秒 --threads=1000 \ #并发1000个线程 --value_size=8192 \ #value size是8K --key_size=16 \ #key size 16B --enable_pipelined_write=true \ --db=./db_bench_test \ #指定创建db的目录 --wal_dir=./db_bench_test \ #指定创建wal的目录 --allow_concurrent_memtable_write=true \ #允许并发写memtable --disable_wal=false \如果要测试热点读,可以指定参数
--key_id_range=100000,表示生成的key的范围是在100000范围内,该测试需要在benchmark中增加timeseries -
读写混合readwhilewriting
9个线程读,一个线程写./db_bench \ --benchmarks="readwhilewriting,stats" --enable_write_thread_adaptive_yield=false \ --disable_auto_compactions=false \ --max_background_compactions=32 \ --max_background_flushes=4 \ --write_buffer_size=536870912 \ --min_write_buffer_number_to_merge=2 \ --max_write_buffer_number=6 \ --target_file_size_base=67108864 \ --max_bytes_for_level_base=536870912 \ --use_existing_keys=1 \ #建议使用已存在key进行读,否则就一直被filter过滤掉,打不到磁盘,测试不精确 --use_existing_db=1 \ --cache_size=2147483648 \ #2G的block-cache,默认是8M,实际生产环境,如果read-heavy应该设置为内存大小的三分之一。 --num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止 --duration=30 \ #持续IO的时间是30秒 --threads=1000\ #并发1000个线程 --value_size=8192\ #value size是8K --key_size=16 \ #key size 16B --enable_pipelined_write=true \ --db=./db_bench_test \ #指定创建db的目录 --wal_dir=./db_bench_test \ #指定创建wal的目录 --allow_concurrent_memtable_write=true \ #允许并发写memtable --disable_wal=false \ -
随机读随机写 ReadRandomWriteRandom
随机读一个请求,随机写一个请求,可以指定读写比,readwritepercent;默认是90%的读,可以降低读的比例
需要注意开启--use_existing_keys=1和--use_existing_db=1./db_bench \ --benchmarks="readrandomwriterandom,stats" --enable_write_thread_adaptive_yield=false \ --disable_auto_compactions=false \ --max_background_compactions=32 \ --max_background_flushes=4 \ --write_buffer_size=536870912 \ --min_write_buffer_number_to_merge=2 \ --max_write_buffer_number=6 \ --target_file_size_base=67108864 \ --max_bytes_for_level_base=536870912 \ --use_existing_keys=1 \ #建议使用已存在key进行读,否则就一直被filter过滤掉,打不到磁盘,测试不精确 --use_existing_db=1 \ #建议打开,使用已经存在的db --cache_size=2147483648 \ #2G的block-cache,默认是8M,实际生产环境,如果read-heavy应该设置为内存大小的三分之一。 --readwritepercent=50 \ #指定读写比 1:1,一次随机读,对应一次随机写 --num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止 --duration=30 \ #持续IO的时间是30秒 --threads=1000\ #并发1000个线程 --value_size=8192\ #value size是8K --key_size=16 \ #key size 16B --enable_pipelined_write=true \ --db=./db_bench_test \ #指定创建db的目录 --wal_dir=./db_bench_test \ #指定创建wal的目录 --allow_concurrent_memtable_write=true \ #允许并发写memtable --disable_wal=false \
3. 便捷Benchmark.sh 自动匹配workload
ps: 需要注意的是benchmark.sh 中很多参数并不是默认的,而是官方给的一些适配当前benchmark workload 的系列优化之后的参数,所以如果大家想要测试自己的option,这个方法并不推荐,还是使用上面的db_bench方式来测试。
因为db_bench选项太多,而测试纬度很难做到统一(可能一个memtable大小的配置都会导致测试出来的写性能相关的的数据差异很大),所以官方给出了一个benchmark.sh脚本用来对各个workload进行测试。
该脚本能够将db_bench测试结果中的stats信息进行统计汇总打印(qps,),更放方便查看。
这个测试需要将编译好的db_bench二进制文件和./tools/benchmark.sh放到同一个目录下, 直接跑 benchmark.sh 脚本就可以了(具体方式见下面详细命令),测试项可以参考官方给出的workload,Performance Benchmarks
-
随机插入
bulkload,制造好数据集
这里的随机插入是指单纯的随机写,且禁掉自动compaction,将当前请求插入完成之后会再进行手动compaction
DB_DIR="./db" NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 benchmark.sh bulkload
总体来说这个随机插入结果相比于默认配置是偏高的,benchmark.sh中的脚本对memtable相关的配置如下:
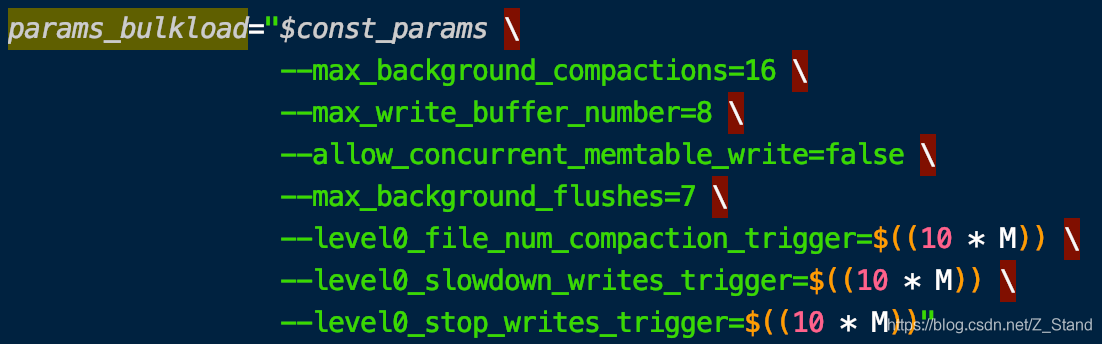
很明显性能肯定好于默认配置,好处是官方有一个在指定硬件之下的workload测试结果,可以进行对比参考。 -
随机写,覆盖写
在上一次已有的数据基础上进行测试,会覆盖写9亿条key
DB_DIR="./db" NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 DURATION=5400 benchmark.sh overwrite -
读时写,9个线程读,一个线程写
这里的读是从已经存在的key中进行读
DB_DIR="./db" NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 DURATION=5400 benchmark.sh readwhilewriting -
随机读
DB_DIR="./db" NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 DURATION=5400 benchmark.sh readrandom
4. 上限的benchmark及参数
欢迎大家补充各自的上限 workload 。
4.1 随机写
单进程 32个线程,32个db,各自的写吞吐会以秒计形态输出到一个report.csv。这里线程数 和 db数可以根据自己环境的cpu核心情况而定,基本不用担心write-stall问题。
./db_bench \
--benchmarks=fillrandom,stats \
--readwritepercent=90 \
--num=3000000000 \
--threads=32 \
--db=./db \
--wal_dir=./db \
--duration=3600 \
-report_interval_seconds=1 \
--key_size=16 \
--value_size=128 \
--max_write_buffer_number=16 \
-max_background_compactions=32 \
-max_background_flushes=16 \
-subcompactions=8 \
-num_multi_db=32 \
-compression_type=none
如果想要支持 direct_io 写,可以打开
--use_direct_io_for_flush_and_compaction=true,这个配置是在写sst时 也就是flush & compaction 生效。
如果想要测试 mmap 写,则可以打开
--mmap_write=true
4.2 完全随机读
随机读想要命中所有的key,需要打开 use_existing_db=1 和 use_existing_keys=1。
需要注意的是 use_existing_keys 开启之后不能直接读多db,只能读单个db,因为它会在真正执行读workload 之前从这一个db内scan 所有的key 到一个数组中,同时 配置的 --num 选项是失效的,这里会填充扫描上来的key的个数。
使用这个配置之后 worklaod 不会立即启动,会卡一会扫描完所有的key之后才真正开始随机读(读的过程是生成随机下标来进行访问)。
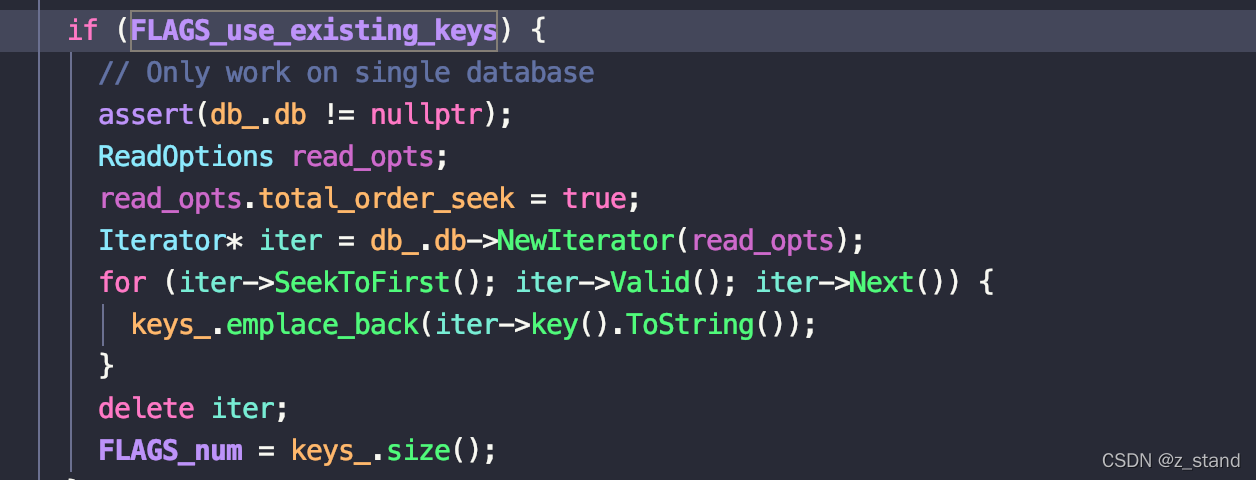
这个测试是使用默认大小的block_cache (8MB),以及 开启bloom filter,因为我们是use_existing_keys,那bloom filter基本没什么用。
$DB_BENCH \
--benchmarks=readrandom,stats \
--num=3000000000 \
--threads=40 \
--db=./db \
--wal_dir=./db \
--duration="$DURATION" \
--statistics \
-report_interval_seconds=1 \
--key_size=16 \
--value_size=128 \
-use_existing_db=1 \
-use_existing_keys=1 \
-compression_type=none \
想要测试 direct 读,添加-use_direct_reads=true,那么读就不会用os pagecache了,这里可以搭配-cache_size=1073741824 以及其他block_cache的配置进行测试,来看rocksdb的block_cache 相比于os pagecache的收益。
想要测试 mmap 读,添加-mmap_read=true 即可。
4.3 热点读
这里基本是使用之前的配置,主要是增加一个数据倾斜的配置 read_random_exp_range,它会用来产生倾斜的随机下标。

这个值越大,下标的倾斜越严重(可以理解为key-range 越小)。
$DB_BENCH \
--benchmarks=readrandom,stats \
--num=3000000000 \
--threads=40 \
--db=./db \
--wal_dir=./db \
--duration="$DURATION" \
--statistics \
-report_interval_seconds=1 \
--key_size=16 \
--value_size=128 \
-use_existing_db=1 \
-use_existing_keys=1 \
-compression_type=none \
-read_random_exp_range=0.8 \
以上所有的workload 最后的结果
可以通过 tail -f report.csv 查看 吞吐
secs_elapsed,interval_qps
1,3236083
2,2877314
3,2645623
4,2581939
5,2655481
6,2038635
7,2226018
8,2366941
...
后面可以通过python 绘图脚本系列简单记录进行曲线绘图。














 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









