







前言
postgresql 作为关系型数据库 且支持各种数据类型的存储,那大宽表存储或者对于超大attribute(列)的存储肯定需要特殊的存储技术来避免性能问题。因为PG 的 heap 表存储引擎是通过page 来管理行(tuple)数据的,且对于行数据的insert和update都是将page加载到内存中,完成操作之后再通过checkpointer子进程刷到磁盘上。读的时候也是先把要读的page加载到内存中,而且还有vacuum子进程来进行过期行数据的清理。如果“大value” 参与这个过程 且用户只要读 或者 修改一个tuple的某几个非大value属性,那也会伴随着巨量io的损耗。
本质上是和单机lsm-tree 存储引擎遇到的大value问题一样,heap 表引擎的tuple数据 insert/update可以看作是append-only形态的,vacuum 清理过期数据也和 compaction 清理过期数据的性质一样,PG这里考虑的情况和细节更多一些而已。lsm-tree 的解决方案是k/v分离,而我们heap表引擎的解决方案是 TOAST(The Oversized Attributes Storage Technique),也是将当前数据表的 “大value” 存储到一个额外的 toast表,因为只存储大 attribute,所以其他的正常的 attribute还是保存在原本要存储的表对应的page中,读/update 大 attr 之外的属性的话就不需要读 toast表的数据了。
接下来我们看看使用 以及 实现上的一些细节。
TOAST 基本策略 及 相关存储策略生效方式
当然,PG 的TOAST方案有几种可选的类型,并不是所有分辨出来的大value 都一股脑塞进toast表中。
heap 引擎中 对 “大value” 的识别是如果一个tuple 数据总大小超过 一个page的1/4(默认一个page的大小是8K,也就是tuple 除了header 之外的部分占用2000Bytes),则认为这个tuple 是需要使用toast 方式存储的。
我们创建一个如下的表:
testdb=# CREATE TABLE c(
a integer,
b numeric,
c text,
d json
);
拥有 text 和 json 两个文本属性的列,查看这个表的attribute属性。
testdb=# SELECT attname, atttypid::regtype, attstorage
from pg_attribute where attrelid='c'::regclass and attnum > 0;
attname | atttypid | attstorage
---------+----------+------------
a | integer | p
b | numeric | m
c | text | x
d | json | x
(4 rows)
-- 或者 \d+ c; 也能够看到
Table "public.c"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
a | integer | | | | plain | |
b | numeric | | | | main | |
c | text | | | | extended | |
d | json | | | | extended | |
Access method: heap
能够看到 attstorage 属性列中拥有 几种不同的类型:p, m, x。
我们能够在 FormData_pg_attribute 结构体的源代码中看到对这几个 attr-storage属性的注释描述:
CATALOG(pg_attribute,1249,AttributeRelationId) BKI_BOOTSTRAP BKI_ROWTYPE_OID(75,AttributeRelation_Rowtype_Id) BKI_SCHEMA_MACRO
{
...
/*----------
* attstorage tells for VARLENA attributes, what the heap access
* methods can do to it if a given tuple doesn't fit into a page.
* Possible values are
* 'p': Value must be stored plain always
* 'e': Value can be stored in "secondary" relation (if relation
* has one, see pg_class.reltoastrelid)
* 'm': Value can be stored compressed inline
* 'x': Value can be stored compressed inline or in "secondary"
* Note that 'm' fields can also be moved out to secondary storage,
* but only as a last resort ('e' and 'x' fields are moved first).
*----------
*/
char attstorage;
...
}
这几种关于 attribute 的存储策略其各自的作用如下:
p -- plain,主要用于已知固定长度的attribute 的存储,这种attr的类型包括(integer, boolean, bit等),对于这种类型的 attr 存储并不会使用 toast技术。m -- main,这种存储策略在遇到比较长的 attr 的时候要求先尝试对该 attr进行压缩,压缩后的数据大小能够满足前面提到的非 “大value” 的场景时则继续留在当前page,否则就将这一些长的attribute数据单独存储到toast 表中。x -- extended,允许压缩attributes 以及 压缩后的数据大小超过 1/4 page时存储到toast 表中,未超过1/4大小的情况 压缩后的数据就直接存储到原表的page中。。e -- external,前面的c表中没有这个属性,允许将较长的未经过压缩的attributes数据存储到 toast表中。
我们可以通过命令ALTER TABLE c ALTER COLUMN d SET STORAGE external;修改attrstorage策略。
这里反复提到的 toast 额外的表 可以看作是一个单独为 前面 c 表建立的存储 大attribute 的表,它在主搜索路径上是隐藏的,可以从 pg_class 表中看到:
testdb=# SELECT relnamespace::regnamespace, relname
FROM pg_class
WHERE oid = (
SELECT reltoastrelid
FROM pg_class WHERE relname = 'c'
);
relnamespace | relname
--------------+----------------
pg_toast | pg_toast_16450
(1 row)
testdb=# \d+ pg_toast.pg_toast_16450;
TOAST table "pg_toast.pg_toast_16450"
Column | Type | Storage
------------+---------+---------
chunk_id | oid | plain
chunk_seq | integer | plain
chunk_data | bytea | plain
在toast表中,我们能够看到总共只有三列,chunk_id, chunk_seq 和 chunk_data,其中 chunk_id和chunk_seq 会被用来建立索引,加速针对当前 toast表的访问;chunk_id可以理解为对原本 超大attribute 数据的分区(以tuple方式管理,每一个chunk作为一个toast-table 中的元组,PG 默认期望一个page存储>=4个元组)。
testdb=# SELECT indexrelid::regclass FROM pg_index
WHERE indrelid = (
SELECT oid
FROM pg_class WHERE relname = 'pg_toast_16450'
);
indexrelid
-------------------------------
pg_toast.pg_toast_16450_index
(1 row)
testdb=# \d pg_toast.pg_toast_16450_index;
Unlogged index "pg_toast.pg_toast_16450_index"
Column | Type | Key? | Definition
-----------+---------+------+------------
chunk_id | oid | yes | chunk_id
chunk_seq | integer | yes | chunk_seq
primary key, btree, for table "pg_toast.pg_toast_16450"
接下来我们看看toast 中的 extended 策略特性,因为它最具有代表性,也最有可能产生“大value”,text 这样的 attr 类型在默认场景都是使用 extended 策略,extended 特性主要是针对 “大value” 属性压缩之后允许原地存储 ,如果压缩失败则直接放入到toast table中。
extended 原地存储场景
testdb=# insert into c values (1, 2.0, 'foo', '{}');
INSERT 0 1
testdb=# update c set c=repeat('A',5000);
UPDATE 1
testdb=# select * from pg_toast.pg_toast_16450;;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
尝试为 c(text) 字段插入5000 bytes的字符,因为都是有规律的字母 ‘A’,会被 pg_lzcompress 算法进行压缩,压缩后的数据依然能够存储到 c表的page中,就会原地存储,这也是上面查看 toast 表中数据为空的原因。
extended 存储到toast表中的场景
插入随机字符串,pg_lz 算法会压缩失败。
testdb=# UPDATE c SET c = (
SELECT string_agg( chr(trunc(65+random()*26)::integer), '')
FROM generate_series(1,5000)
)
RETURNING left(c,10) || '...' || right(c,10);
?column?
-------------------------
QHZSRFSBRO...AARGJDDJIJ
(1 row)
UPDATE 1
testdb=# SELECT chunk_id,
chunk_seq,
length(chunk_data),
left(encode(chunk_data,'escape')::text, 10) || '...' ||
right(encode(chunk_data,'escape')::text, 10)
FROM pg_toast.pg_toast_16450;
chunk_id | chunk_seq | length | ?column?
----------+-----------+--------+-------------------------
16456 | 0 | 1996 | QHZSRFSBRO...ITNHVALVFT
16456 | 1 | 1996 | CHHPRAVYDP...RTMDGGNKTW
16456 | 2 | 1008 | ENBXUMTZGG...AARGJDDJIJ
(3 rows)
因为pg_lz 算法压缩失败,对于text 字段还是会保留5000bytes,本地存储肯定是达到 “大value” 的标准了,所以会被放入到toast table中。在toast tabale中被拆分为了三个chunk,每一个chunk 的大小维持在 <= page_size/4 ,这个时候存储的是未压缩的数据。
接下来我们看看toast机制的代码实现。
TOAST 机制 的实现
最终对于 “大value” 的处理形态类似如下图,图中没有办法展示其他各种情况的处理细节,toast 表出现的形态基本一样:
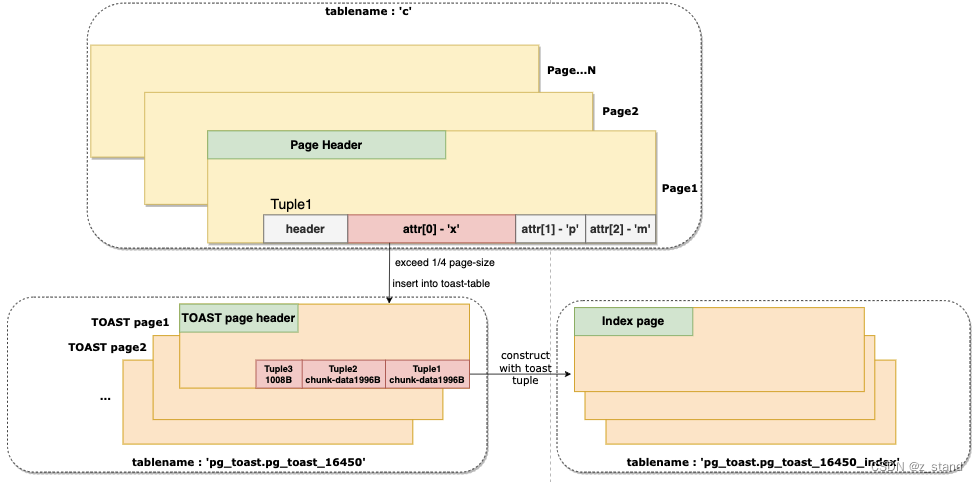
针对某一个超大attr的处理 如果压缩失败,则会按照最大chunk-size 被拆分为多个tuple存储到 toast表中(前面演示的c表 c列的处理情况),并对应建立一个toast表的index 用于读时候的加速访问。
关于 TOAST 完整的处理流程如下:
- 遍历
attstorage策略为extended和external的 attr,从最长的 attr开始。extended策略会对当前 attr 的数据先进行压缩,如果当前attr 压缩后的数据超过了 1/4 page的大小,会直接将当前 attr的数据(未压缩的)移动到 TOAST表。external策略的处理方式是一样的,只是不会对数据进行压缩而已。 - 如果最长的 attr 的数据已经被压缩/移动到 TOAST 表中了,但是整个tuple的大小还是超过1/4 page,则将 存储策略为
extended或者external的attr 都移动到 TOAST表中。 - 如果还是无法满足tuple 大小的限制(大宽表场景,有非常多的attr,PG默认的 一行 attr个数上限是 1600个),会尝试压缩
main策略的 attr,但是会让压缩后的数据继续保留在原本的table page中,不进行移动。 - 如果还是无法满足存储需求,那就将压缩后的
mainattrs 移动到 TOAST table中。
前面提到的 tuple大小的限制在12.12版本还没有相关的配置,在14版本之后有一个
toast_tuple_targetguc配置可以让用户指定这个阈值的大小。12.12版本中,默认是TOAST_TUPLE_THRESHOLD宏定义,大概就是2000bytes,不过会随着page-size的变化而变化,page-size在编译的时候指定了其他的大小,那这里还会变化的。
接下来看看代码细节。
TOAST 写链路的实现
在 heap_insert --> heap_prepare_insert 中会生成后续要放入到page的tuple,这个时候已经能够拿到所有当前tuple要插入的 attr数据。
static HeapTuple
heap_prepare_insert(Relation relation, HeapTuple tup, TransactionId xid,
CommandId cid, int options)
{
/* 处理一些tuple header,设置 c_tid, t_xmax 等 */
...
if (relation->rd_rel->relkind != RELKIND_RELATION &&
relation->rd_rel->relkind != RELKIND_MATVIEW)
{
/* toast table entries should never be recursively toasted */
Assert(!HeapTupleHasExternal(tup));
return tup;
}
else if (HeapTupleHasExternal(tup) || tup->t_len > TOAST_TUPLE_THRESHOLD)
/* toast 写入入口,因为我们是insert链路,所以这里参数中的 oldtup 是NULL */
return toast_insert_or_update(relation, tup, NULL, options);
else
return tup;
}
接下来就会进入 toast_insert_or_update 处理 TOAST 写入的逻辑。
前面会先进行数据准备,重要的几个数据属性如下:
HeapTuple
toast_insert_or_update(Relation rel, HeapTuple newtup, HeapTuple oldtup,
int options)
{
...
bool toast_isnull[MaxHeapAttributeNumber]; // 快速判断某一个 attr的数据部分是否为空
Datum toast_values[MaxHeapAttributeNumber]; // 当前tuple 每一个attr 的data数据
...
// 解析传入的tuple,并填充toast_values部分
heap_deform_tuple(newtup, tupleDesc, toast_values, toast_isnull);
...
}
填充好了需要的数据结构之后,就进入到了前面说的基本步骤中了
步骤一: 优先处理 e 和 x 的存储策略,找出 当前所有的toast_values 其中最长的attr 进行压缩,如果压缩失败,则整个 attr数据 都存储到toast表中。
// heap_compute_data_size 预先计算当前tuple的总大小是否超过了阈值
while (heap_compute_data_size(tupleDesc,
toast_values, toast_isnull) > maxDataLen)
{
...
// 遍历一轮所有的attr, 找出最大的attr的下标 以及 大小。
for (i = 0; i < numAttrs; i++)
{
Form_pg_attribute att = TupleDescAttr(tupleDesc, i);
if (toast_action[i] != ' ')
continue;
if (VARATT_IS_EXTERNAL(DatumGetPointer(toast_values[i])))
continue; /* can't happen, toast_action would be 'p' */
if (VARATT_IS_COMPRESSED(DatumGetPointer(toast_values[i])))
continue;
if (att->attstorage != 'x' && att->attstorage != 'e')
continue;
if (toast_sizes[i] > biggest_size)
{
biggest_attno = i;
biggest_size = toast_sizes[i];
}
}
...
// 尝试压缩找出的这个 attr 的data数据。
i = biggest_attno;
if (TupleDescAttr(tupleDesc, i)->attstorage == 'x')
{
old_value = toast_values[i];
new_value = toast_compress_datum(old_value);
// 压缩成功则保存toast状态,并释放当前tuple对应的data部分的数据
if (DatumGetPointer(new_value) != NULL)
{
/* successful compression */
if (toast_free[i])
pfree(DatumGetPointer(old_value));
...
}
else
{
/* incompressible, ignore on subsequent compression passes */
toast_action[i] = 'x';
}
}
else
{
/* 标记无法进行压缩 */
toast_action[i] = 'x';
}
// 压缩失败,则尝试将attr对应的 toast_values 中的数据存储到 toast 表中。
if (toast_sizes[i] > maxDataLen &&
rel->rd_rel->reltoastrelid != InvalidOid)
{
old_value = toast_values[i];
toast_action[i] = 'p';
toast_values[i] = toast_save_datum(rel, toast_values[i],
toast_oldexternal[i], options);
if (toast_free[i])
pfree(DatumGetPointer(old_value));
...
}
}
其中比较重要的两个函数:
-
函数
toast_compress_datum的实现 是 PG 自实现的 lz算法,学习的是Adisak Pochanayon 提出的SLZ 算法的思想,本质上其实也是 LZ77 版本的算法。通过构造 全局的字典来对重复的输入字符进行编码,PG这里实现的版本对解压缩性能更为友好,但是并不适合超大value,因为数据字典需要常驻内存才能保证解压缩的高效匹配性能。在PG 所支持的大多数数据存储场景还是能够满足性能需求的,这个算法还是值得研究的(pg 这里代码细节上做了很多处理,短时间内细节没有看的太明白 😐)。 -
函数
toast_save_datum用来将当前attr 数据 添加到toast 表中,该函数的核心逻辑如下:-
在 当前rel 表下面的table-space中 创建一个
toastrel来标识一个toast表,用来存储 toast数据。 -
创建一个
toastrel对应的 index表validIndex,用来加速对 toast 表的访问。 -
计算好当前 attr 在toast中要存储的数据大小
data_todo -
data_todo 大小的attr 数据未写入之前,循环写入。每一次写一个chunk的数据,在page-size 大小为 8K 的情况下每一个chunk的大小为 1996B。每一个chunk 封装为一个tuple
heap_form_tuple函数来构造tuple,通过heap_insert插入 toast_rel 对应的 toast表中;紧接着通过index_insert插入 这个toast 对应的index 表中。
循环第四步,直到完成当前 attr 所有的数据都写入到tuple中。这部分的 代码实现比较简单,这里就不贴了。
-
需要注意的是在将 当前 attr 数据移动到toast 表之后会返回一个指向toast 表的指针给tuple,这个pointer本质上是一个 varatt_external数据结构对象,保存的是toast 表relid以及value在toast表中的id,能够用作后续读原始tuple的时候能够从toast 表中进行读取。
继续回到 toast_insert_or_update 函数。
步骤二: 如果当前tuple 剩下的attr 总大小还是超过限制,则处理剩下attr 中所有为 e 或者 x 存储策略的attr。所有能够压缩的的且大小超过 maxDataLen 的 attr之前都已经处理完了,剩下的主要是处理之前不能压缩的了,逻辑比较简单:
// 除了check tuple-size 之外还需要确保 toast 表是有效的,这样才能将 attr 移动到toast表中。
while (heap_compute_data_size(tupleDesc,
toast_values, toast_isnull) > maxDataLen &&
rel->rd_rel->reltoastrelid != InvalidOid)
{
...
// 对于剩下的,未压缩的attr 还是按照从大到小进行处理
for (i = 0; i < numAttrs; i++)
{
Form_pg_attribute att = TupleDescAttr(tupleDesc, i);
if (toast_action[i] == 'p')
continue;
if (VARATT_IS_EXTERNAL(DatumGetPointer(toast_values[i])))
continue; /* can't happen, toast_action would be 'p' */
if (att->attstorage != 'x' && att->attstorage != 'e')
continue;
if (toast_sizes[i] > biggest_size)
{
biggest_attno = i;
biggest_size = toast_sizes[i];
}
}
...
toast_values[i] = toast_save_datum(rel, toast_values[i],
toast_oldexternal[i], options);
...
}
步骤三: tuple大小还是超过了限制的大小,主要是处理 attrstorage 为 m的场景,即尝试压缩该类型的attr,并直接存储在本地tuple中,逻辑基本同上。
步骤四: 将压缩后的 m 类型的attr 移动到 toast 表中,逻辑基本同上。
进入到 步骤三和四 的逻辑基本就是大宽表了,这个时候只能是一步步尝试,让tuple大小满足要求。
完成以上步骤之后,函数 toast_insert_or_update 还需要构造一个新的tuple,保存的是之 或前压缩后的数据 ,或 移动到toast 之后的指针,将新的tuple返回。
因为以上处理的其实是 heap_insert的逻辑,如果是heap_update,则还需要提前将旧的tuple数据读出来,在这个函数中完成更新。
整个 TOAST 方式的写入链路还是比较清晰的,对于 “大 attribute” 的数据 或者 大宽表的处理还是对性能有比较大的影响的,可能需要压缩、建立toast表、toast索引表;虽然说PG 本身的heap表写链路也是操作 存储于内存中的 page,后续才会刷盘,但每一个heap_insert 都伴随着一次wal page的写入,对于大value场景(大attr),而且它的toast插入可能会伴随多个heap_insert,超大value 对性能本身还是有比较大的影响的。
TOAST 读链路的实现
读链路本身是会先把要读的page加载到内存中,通过 bfmgr 管理起来;要读的tuple 则会从page中进行逐个解析,和上层的查询语句的要求做比对。
针对 带有 toast 属性且已经分离存储的 tuple的 读取调用栈如下:
* frame #0: 0x000000010025d6f4 postgres`heapam_index_fetch_tuple
frame #1: 0x000000010026ab44 postgres`index_fetch_heap + 64
frame #2: 0x000000010026abc0 postgres`index_getnext_slot + 64
frame #3: 0x000000010026a440 postgres`systable_getnext_ordered + 28
frame #4: 0x000000010026406c postgres`toast_fetch_datum + 280
frame #5: 0x000000010026442c postgres`heap_tuple_untoast_attr + 60
frame #6: 0x0000000100538b58 postgres`text_to_cstring + 24
frame #7: 0x00000001005602ec postgres`FunctionCall1Coll + 80
frame #8: 0x000000010022ffe8 postgres`printtup + 376
frame #9: 0x00000001003676cc postgres`standard_ExecutorRun + 308
frame #10: 0x00000001004814ac postgres`PortalRunSelect + 244
frame #11: 0x00000001004810fc postgres`PortalRun + 468
frame #12: 0x0000000100480240 postgres`exec_simple_query + 768
frame #13: 0x000000010047e3d4 postgres`PostgresMain + 2852
frame #14: 0x000000010041c3b8 postgres`BackendRun + 404
frame #15: 0x000000010041ba3c postgres`ServerLoop + 2376
frame #16: 0x0000000100419618 postgres`PostmasterMain + 3652
frame #17: 0x00000001003a659c postgres`main + 636
本质上会先读取 toast 表对应的index表,利用 chunk_id 或者 chunk_seq 两个index-key 索引到对应的chunk_data中,然后 解压缩对应的 attr 或者 根据 原表中的toast_pointer中的va_valueid
将所有的与这个 id 相等的tuple都顺序读出来(一个 attr 可能会被拆分为多个tuple 存储到toast表中),从toast 中读取的逻辑主要是在 toast_fetch_datum 函数中。
结语
从TOAST 这个特性的推出中,我们能够看到后来业界对这种类型数据存储的需求是如何推动整个数据库体系的演进的:
- 随着互联网的普及 对 文档(json – 极易分析)类型、k/v (超大规模的社交图谱、知识图谱)这样的弱关系型数据有巨量的存储需求,这一些存储需求我们的关系型数据库功能过于复杂而导致性能上无法满足存储需求,所以nosql的出现也是必然的。
- 但时代又期望能够在这种类型的数据中进行像 SQL 一样的极为方便的关系模型的建立以及搜索,又有了NewSQL 。
- 如今大家期望更易用,成本更低,只能让这一套体系又上云了,从而将数据库访问模式做成 SaaS(software-as-a-service) 服务。
现如今 随着计算和存储资源的弹性调度,这一些原本是单机PG的瓶颈 而现在则 不再是瓶颈,对于 TOAST 这样的存储技术所面对的存在于关系型数据库中的存储需求也随着 上云的过程发生了一些变化。云存储是底层分布式形态且有网络延迟,如何 提升 catalog 表 和 数据表底层对 有 toast 需求的数据的存储性能和访问性能 还需要一些更为独特的读写方式。
参考
- 《postgresql_internals-14_parts1-3_en.pdf》
- postgresql - REL_12_STABLE 源码














 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









