







天天AC,日日惊喜。每天学点算法,每天进步一点点。
1.哈希表的定义
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。(维基)
个人的理解:举个例子,你想去图书馆找本书,你不会从第一本找到最后一本,你会看下那本书是归为小说类还是 IT 类,然后直接去那一类里面查找,哈希表就相当于图书的归类。
哈希表和数组的区别:可以想象一下,你通过数组下标直接去找到数组的值,而哈希表是根据关键字 k ,计算 f(k)去找到值。
哈希表结构上介于链表和二叉树之间,哈希表是一个固定大小的数组,数组的每个元素是一个链表(单向或双向)的头指针。如果Key一样,则在一起,如果Key不一样,则不在一起。哈希表的查询是飞快的。因为它不需要从头搜索,它利用Key的“哈希算法”直接定位,查找非常快,各种数据库中的数据结构基本都是它。但带来的问题是,哈希表的尺寸、哈希算法。
- 若关键字为
 ,则其值存放在
,则其值存放在 的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系
的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系 为散列函数(Hash function),按这个思想建立的表为散列表。
为散列函数(Hash function),按这个思想建立的表为散列表。
- 对不同的关键字可能得到同一散列地址,即
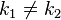 ,而
,而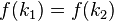 ,这种现象称碰撞(Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数
,这种现象称碰撞(Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数 和处理碰撞的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象”作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
和处理碰撞的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象”作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
- 若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少碰撞。
2.构造散列函数
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
- 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即
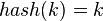 或
或 ,其中
,其中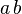 为常数(这种散列函数叫做自身函数)
为常数(这种散列函数叫做自身函数) - 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即
 ,
,  。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生碰撞。
。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生碰撞。
3.处理碰撞的方法
为了知道碰撞产生的相同散列函数地址所对应的关键字,必须选用另外的散列函数,或者对碰撞结果进行处理。在算法导论里面介绍了三种方法:开放寻址,单独链表,双散列。
4.查找效率
数据本身分布是否均匀,还有就是散列表的载荷因子。
散列表的载荷因子定义为: = 填入表中的元素个数 / 散列表的长度
= 填入表中的元素个数 / 散列表的长度
= 填入表中的元素个数 / 散列表的长度














 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









