







概要
排名是推荐系统中的一项核心任务,该系统旨在向用户提供项目的有序列表。通常,从标记的数据集中学习排序功能以优化全局性能,从而为每个单独的项目生成一个得分。但是,它可能不是最佳选择,因为评分功能分别应用于每个项目,并且没有明确考虑项目之间的相互影响以及用户的偏好或意图的差异。因此,我们提出了针对推荐系统的个性化重新排名模型。通过直接使用现有的排名特征向量,可以在任何排名算法之后轻松地将提出的重新排名模型部署为后续模块。它通过采用一种transformer结构来有效地编码列表中所有项目的信息,从而直接优化整个推荐列表。具体地说,Transformer应用了一种自我关注机制,该机制直接对整个列表中任何一对项目之间的全局关系进行建模。我们确信,通过引入预训练的embedding向量来学习针对不同用户的个性化编码功能,可以进一步提高性能。在离线基准测试和实际在线电子商务系统上的实验结果表明,提出的重新排名模型得到了显着改进。
原文链接:https://arxiv.org/abs/1904.06813
关键字
学习排名; 重新排名; 推荐系统
1 介绍
在推荐系统中,排名至关重要。 排名算法给出的排名列表的质量对用户的满意度以及推荐系统的收入都有很大的影响。 已经提出了大量的排名算法[4、5、7、15、19、27、32]以优化排名性能。 通常,推荐系统中的排名仅考虑user-item 的交互功能,而不考虑列表中其他项的影响,特别是那些类别是一样的item[8,35]。 尽管pair-wise学习和逐对listwise学习方法试图通过以项目对或项目列表作为输入来解决问题,但它们仅专注于优化损失函数以更好地利用标签(例如点击数据)。 他们没有明确建模要素空间中项目之间的相互影响。
一些工作[1,34,37]倾向于显式地建模项目之间的相互影响,以细化由先前的排名算法给出的初始列表,这被称为重新排名。主要思想是通过将项目内模式编码到特征空间中来构建评分函数。编码特征向量的最新方法是基于RNN的,例如GlobalRerank [37]和DLCM [1]。他们将初始列表顺序输入到基于RNN的结构中,并在每个时间步输出编码的矢量。但是,基于RNN的方法对列表中项目之间的交互进行建模的能力有限。先前编码项的特征信息随着编码距离而降低。受机器翻译中使用的Transformer体系结构[20]的启发,我们建议使用Transformer对项目之间的相互影响建模。 Transformer结构使用自我关注机制,其中任何两个项目都可以直接相互交互,而不会在编码距离上降低。同时,由于并行化,Transformer的编码过程比基于RNN的方法更有效。
除了项目之间的交互之外,还应考虑交互的个性化编码功能以在推荐器系统中重新排名。 推荐系统的重新排名是特定于用户的,具体取决于用户的偏好和意图。 对于对价格敏感的用户,“价格”功能之间的交互在重新排名模型中应该更为重要。 典型的全局编码功能可能不是最佳的,因为它忽略了每个用户的特征分布之间的差异。 例如,当用户专注于价格比较时,具有不同价格的相似商品往往会在列表中进行汇总。 当用户没有明显的购买意图时,推荐列表中的项目趋向于更加多样化。 因此,我们在Transformer结构中引入了个性化模块,以表示用户的偏好和项目交互的意图。
本文的主要贡献如下:
•问题。我们提出了一种推荐系统中的个性化重新排名问题,据我们所知,这是第一次将个性化信息明确引入大型在线系统的重新排名任务中。实验结果证明了将用户的表示形式引入列表表示形式以进行重新排名的有效性。
•模型。我们使用配备了个性化嵌入功能的Transformer来计算初始输入列表的表示形式(这个列表就是我们精排之后的输出List),并输出重新计算得到的排名得分。与基于RNN的方法相比,自我关注机制使我们能够以更加有效和高效的方式对任意两个项目之间的用户特定的影响关系进行建模。
•数据。我们发布了本文中使用的大规模数据集(电子商务重新排名数据集)。该数据集是根据真实世界的电子商务推荐系统构建的。数据集中的记录包含带有用户购买、曝光的标签和特征。
•评估。我们进行了离线和在线实验,这表明我们的方法大大优于最新方法。在线A / B测试表明,我们的方法为实际系统带来了更高的点击率和更多的收入。
2 相关工作
我们的工作旨在精排模型给出的排序列表。 在这些基本排名中,学习排名是广泛使用的方法之一。 根据其使用的损失函数,可以分为三类:point- wise[12, 21], pairwise[6, 18, 19], and listwise[5, 7, 14, 19, 27, 32, 33],其中point- wise就是预估的时候,用同一批特征对每个app进行打分,得到的top应用可能是非常相似的应用,list-wise除了打分之外,还会考虑打分列表中每个item之间的相互影响关系,parewise是随机从一个用户的行为中拿出两个样本,根据这两个样本得到的loss进行更新模型参数。 所有这些方法都学习了全局计分功能,在其中可以全局地学习某个特征的权重。 但是,特征的权重应该不仅能够知道项目之间的交互,而且还应该知道用户与项目之间的交互。
与我们的工作最接近的是[1-3、37],它们都是重新排序的方法。他们使用整个初始列表作为输入,并以不同的方式对项目之间的复杂依赖性进行建模。 [1]使用单向GRU [10]将整个列表的信息编码为每个item的表示形式。 [37]使用LSTM [17],[3]使用指针网络[29]不仅对整个列表信息进行编码,而且由解码器生成排序后的列表。对于那些使用GRU或LSTM编码项目相关性的方法,编码器的容量受编码距离的限制。在我们的论文中,我们使用transformer-like encoder,基于self-attention机制,对O(1)距离中两个项目之间的相互作用进行建模。此外,对于那些使用解码器生成有序列表的方法,它们不适合需要严格等待预估耗时的在线排名系统。由于顺序解码器使用在时间t -1处选择的项作为输入来选择在时间t处的项,因此它无法并行化,需要进行n次推断,其中n是输出列表的长度。 [2]提出了可以并行化的分组评分函数,在对项目进行计分时可以并行化,但是其计算成本很高枚举列表中项目的所有可能组合。
3 重新排序模型的公式表达
在本节中,我们首先提供有关学习推荐系统的排名和重新排名方法的一些初步知识。 然后,我们提出了我们要解决的问题。 本文中使用的符号在表1中。
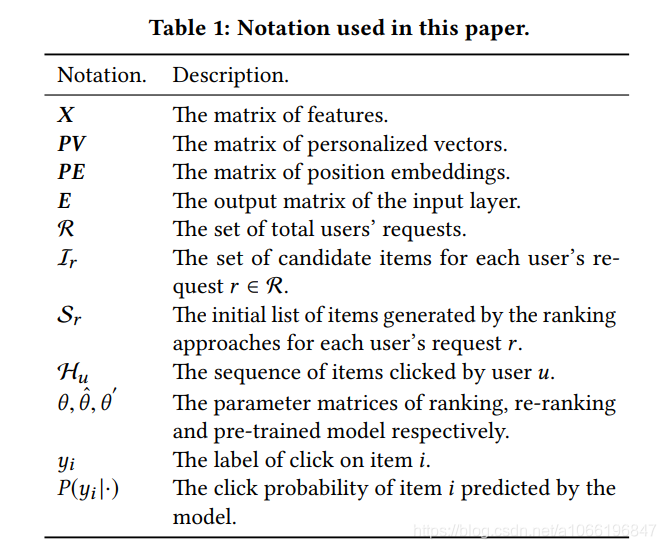
学习排名(通常标记为LTR)方法被广泛用于实际工作系统中的排名,以生成信息检索[18,22]和推荐[14]的有序列表(也就是搜索算法、推荐算法)。 LTR方法基于item的特征向量学习全局评分功能。 具有此全局功能的LTR方法通过对候选集中的每个项目评分来输出有序列表。 通常通过最小化以下损失函数L来学习此全局评分函数:
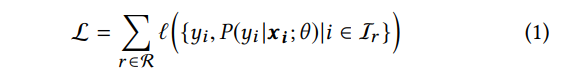

其中R是推荐系统中所有用户的请求,I(r)是请求 r belongs R时筛选出来的候选集(也就是召回模型的结果),x(i)代表了item i的特征空间,y(i)是Item i的label(点击与否),P(yi |xi ; θ)是在给定“排序模型”有着θ参数时候,item i的点击概率,L是计算y(i)和P(yi |xi ; θ)的损失数值
但是,xi不足以学习良好的评分功能。 我们发现推荐系统的排名应考虑以下额外信息:
(a)项目对之间的相互影响[8,35];
(b)用户与项目之间的互动。
项目对之间的相互影响可以直接从现有LTR模型为请求r给出的初始列表Sr = [i1,i2,...,in]中获悉。 Works [1] [37] [2] [3]提出了更好地利用项目对的互信息的方法。 但是,很少有作品考虑用户和项目之间的交互。 项对的相互影响程度因用户而异。 在本文中,我们引入了个性化矩阵PV来学习特定于用户的编码功能,该功能可以对项对之间的个性化相互影响进行建模。 模型的损失函数可以
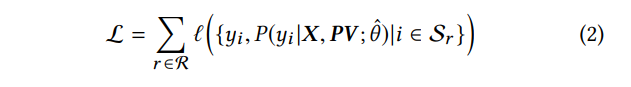
其中Sr是由先前的排名模型给出的初始列表。 θˆ是我们的重新排名模型的参数。 X是列表中所有项目的特征矩阵。
4 个性化重新排名模型
在本节中,我们首先概述我们建议的个性化重新排序模型(PRM)。 然后我们详细介绍了我们的模型。
4.1模型架构
PRM模型的体系结构如图1所示。该模型由三部分组成:输入层,编码层和输出层。 它采用先前排序方法生成的项目的初始列表作为输入,并输出重新排序的列表。 详细结构将在以下各节中分别介绍。
4.2 输入层

输入层的目标是准备初始列表中所有项目的综合表示,并将其提供给编码层。 首先,我们有一个固定长度的初始顺序列表S = [i1,i2,...,in],由先前的排序方法给出。 与先前的排序方法相同,我们有一个原始特征矩阵X∈(Rn×dfeature),这个特征矩阵意思就是说,精排模型给出N个item结果,那么X就是N行,每行都是对应的一个appid的特征矩阵(这个特征矩阵里面有user特征、app特征、user与app的交互特征)

个性化向量(PV)。对两个appid的特征向量进行编码可以对它们之间的相互影响进行建模,但是这些影响可能影响用户的程度尚不清楚。 需要学习特定于用户的编码功能。 尽管整个初始列表可以部分反映用户的偏好,但是对于强大的个性化编码功能而言,这还不够。 如图1(b)所示,我们将原始特征矩阵X∈Rn×dfeature与个性化矩阵PV∈Rn×dpv合并,得到中间嵌入矩阵E′∈Rn×(dfeature + dpv),如图1所示。 公式3。PV由预训练模型产生,该模型将在以下部分中介绍。 PV的性能增益将在评估部分中介绍。
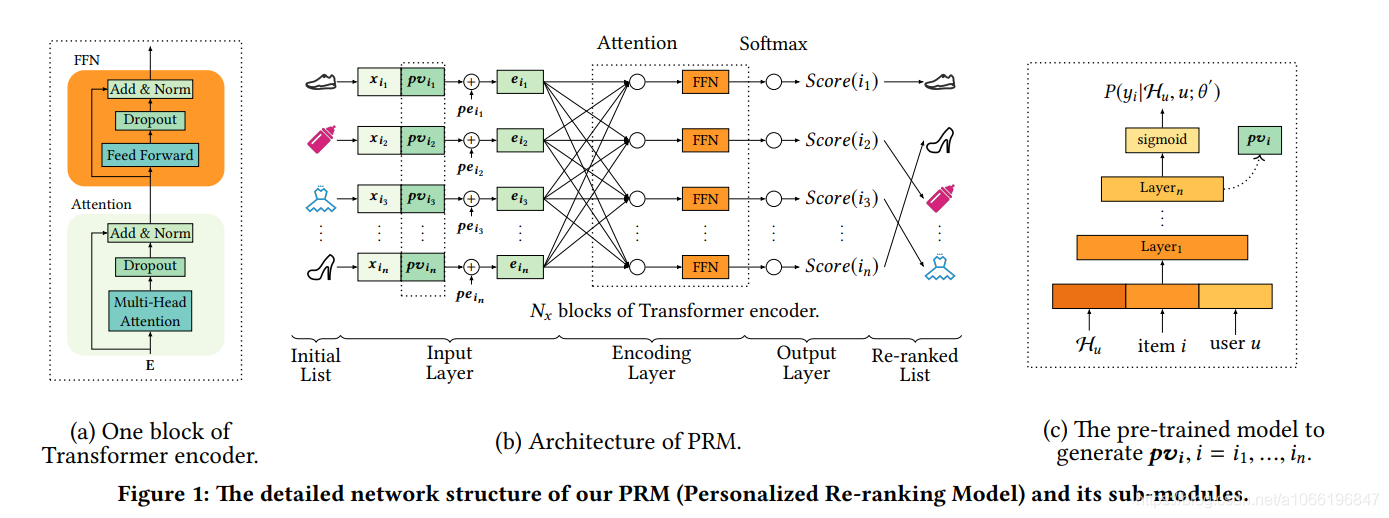
位置编码(PE)。 为了利用初始列表中的顺序信息,我们将位置嵌入PE∈Rn×(dfeature + dpv)注入到输入嵌入中。 然后,可以使用公式4计算编码层的嵌入矩阵。在本文中,使用了一种可学习的PE,我们发现它略胜于[28]中使用的固定位置嵌入。
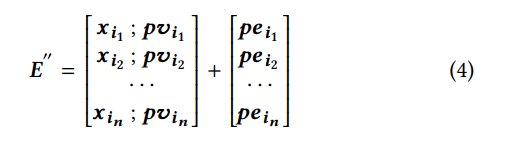
最后,我们使用一个简单的前馈网络来转换特征矩阵 E∈R(n×(dfeature + dpv))到E∈R(n×d),其中d是每个编码层的输入向量的潜在维数。 E可以是公式5
![]()
4.3 编码层
图1(a)中编码层的目标是整合项目对和其他额外信息的相互影响,包括用户偏好和初始列表S的排名顺序。为了实现这一目标,我们采用了 类似于Transformer的编码器,因为与基于RNN的方法相比,Transformer [28]已被证明在许多NLP任务中都是有效的,特别是在机器翻译中,因为其强大的编码和解码能力[10,11,17]。 Transformer中的自我注意机制特别适合我们的重新排序任务,因为它可以直接模拟任意两个项目之间的相互影响,而无需考虑它们之间的距离。 没有距离衰减,Transformer可以捕获初始列表中彼此远离的项目之间的更多交互。 如图1(b)所示,我们的编码模块由Nx个块的Transformer编码器组成。 每个块(图1(a))包含一个attention层和一个前馈网络(FFN)层。
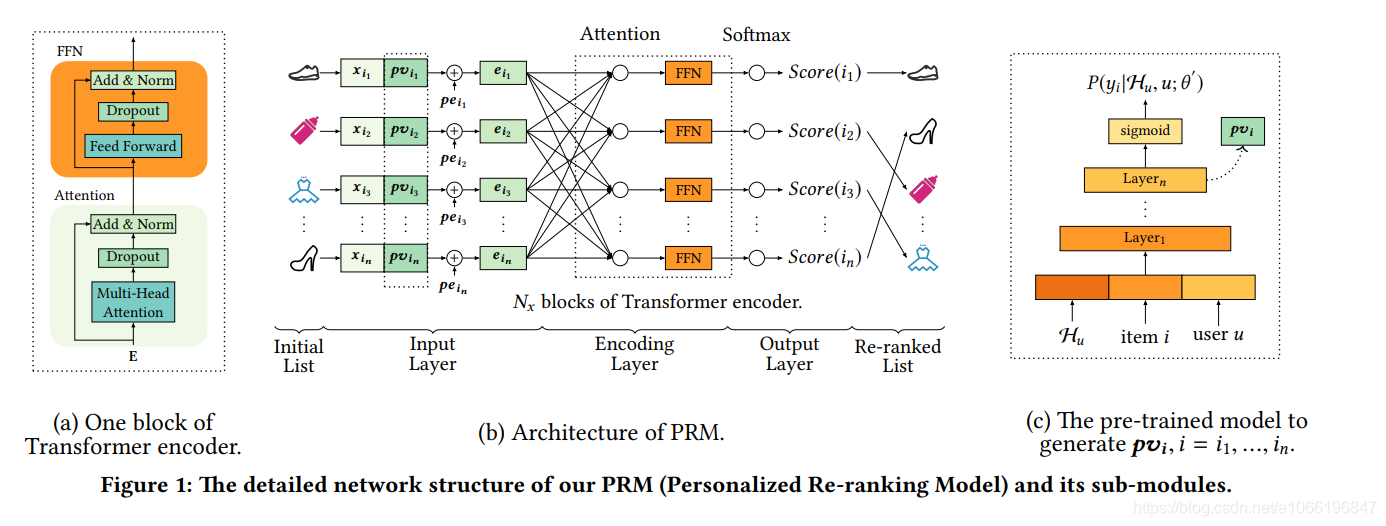
Attention Layer :我们在本文中用到的 attention function如图6
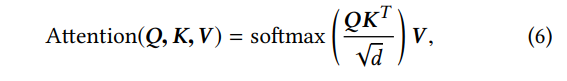
其中矩阵Q,K,V分别表示query词,keys和values。 d是矩阵K的维数,采用根号以避免内积的大值。 softmax用于将内积的值转换为值向量V的权重。 在我们的论文中,我们使用self-attention,其中Q,K和V是从相同矩阵产生的。
为了对更复杂的相互影响建模,我们使用多个attention,如公式7所示:
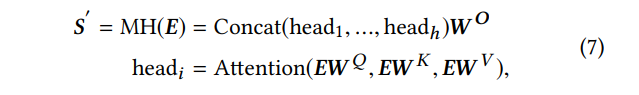
其中W Q,W K,WV∈R(d×d)。 W O∈R(hd×dmodel)是投影矩阵。 h是header的数量。 不同h值的影响将在下一部分的消融研究中进行学习。
前馈网络。 此位置的功能前馈网络(FFN)主要是为了增强模型非线性和不同尺寸的输入向量之间的相互作用。
堆叠编码层。 在这里我们使用一个attention模块,其次是位置式FFN作为Transformer的一部分[28]编码器。 通过堆叠多个块,我们可以变得更加复杂和高阶的共同信息
4.4输出层
输出层的功能主要是为每个项i = i1,...,in生成一个分数(在图1(b)中标记为Score(i))。我们使用一个线性层,后跟一个softmax层。 softmax层的输出是每个item的点击概率

去重新排序。 分数(i)的公式为:
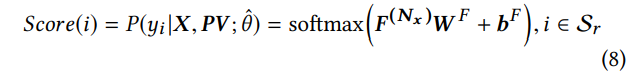
4.5个性化模块
在本节中,我们介绍计算个性化矩阵PV的方法,该矩阵代表用户和item之间的关系。一种简单的方法是通过PRM模型去学习PV,其中的PRM模型是以端到端的方式进行建模来计算损失。然而,如第3节所述,重新排序的任务是获取之前模型输出的排序结果。在重新排序中最重要的一点是学习到用户的一般偏好。 因此,我们利用预先训练的神经网络来生成用户的个性化嵌入PV向量,然后将其用作附加功能对于PRM模型。预训练的神经网络的学习数据是来自平台的整个“浏览”日志。图1(c)显示本文使用的预训练模型的结构。sigmoid层输出点击概率(P(yi| Hu,u; θ))。这个公式意义是:在给定用户的浏览历史的Hu情况下,用户u点击item的概率。用户的辅助信息包括性别,年龄和购买水平等。该模型的损失由公式10中所示的逐点交叉熵函数表示。
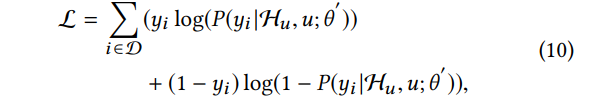
其中D是在平台上向用户u显示的项目集。 θ是预训练模型的参数矩阵。 yi是点击概率。 受工作启发[13],我们在sigmoid层前面加入了一个隐藏层作为 pvi 个性化向量,到我们的 PRM 层
剩下的是实验结果,有兴趣的可以从论文中去看














 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









