







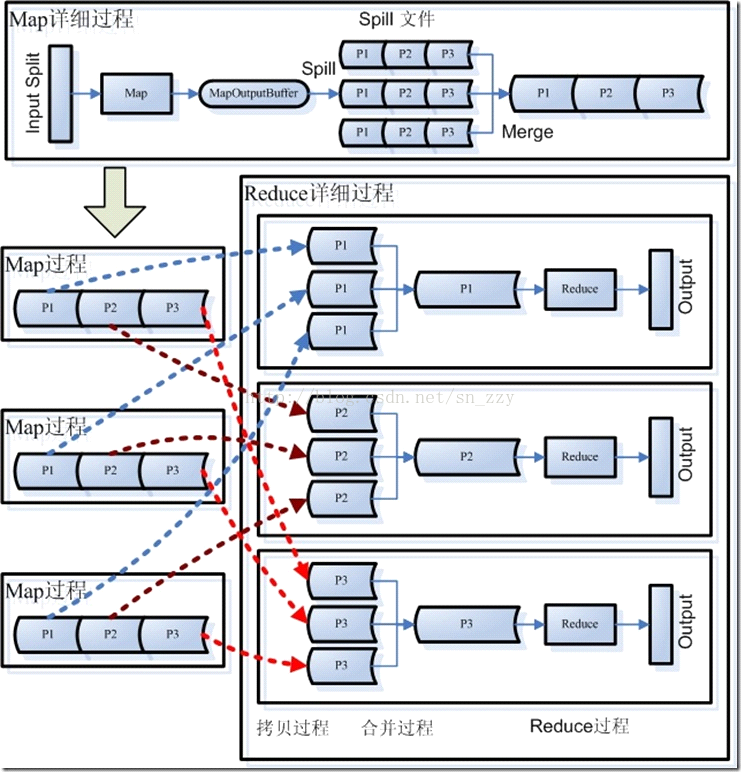
map/reduce简单的原理介绍
Hadoop Map/Reduce框架为每一个InputSplit产生一个map任务,而每个InputSplit是由该作业的InputFormat产生的。
然后,框架为这个任务的InputSplit中每个键值对调用一次 map(WritableComparable, Writable, OutputCollector, Reporter)操作。通过调用 OutputCollector.collect(WritableComparable,Writable)可以收集输出的键值对。
Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,
则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),
如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
Hive外部表,编写正则表达式解析Nginx日志
nginx日志的format配置:
'$proxy_add_x_forwarded_for - $remote_user [$time_local] "$request"'
'$status $request_body "$http_referer"'
'"$http_user_agent" "$http_x_forwarded_for" $request_time $upstream_response_time';
生成的日志大致格式:
218.202.xxx.xxx – - [2014-08-19 22:17:08.446671] “POST /xxx/xxx-web/xxx HTTP/1.1″ 200 stepid=15&tid=U753HifVPE0DAOn%2F&output=json&language=zh_CN&session=114099628&dip=10920&diu=DBDBF926-3210-4D64-972A7&xxx=056a849c70ae57560440ebe&diu2=2DFDB167-1505-4372-AAB5-99D28868DCB5&shell=e3209006950686f6e65352c3205004150504c450000000000000000000000000000&compress=false&channel=&sign=438BD4D701A960CD4B7C1DE36AA8A877&wua=0&appkey=0&adcode=150700&t=0 HTTP/1.1″ 200 302 “-” “xxx-iphone” 31.0ms
hive建表的语句:
CREATE EXTERNAL TABLE xxx_log(
host STRING,
log_date STRING,
method STRING,
uri STRING,
version STRING,
STATUS STRING,
flux STRING,
referer STRING,
user_agent STRING,
reponse_time STRING
)
PARTITIONED BY(YEAR STRING, MONTH STRING, DAY STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES ( "input.regex" = "([^ ]*)\\s+-\\s+-\\s+\\[([^\]]*)\\]\\s+\"([^ ]*)\\s+(.*?)\\s+([^ ]*)\"\\s+(-|[0-9]*)\\s+(-|[0-9]*)\\s+\"(.+?|-)\"\\s+\"(.+?|-)\"\\s+(.*)",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %5$s %6$s %7$s %8$s %9$s %10$s" ) STORED AS TEXTFILE;
然后,将数据导入表中
方法1. 将指定路径下的文件导入,不移动文件
ALTER TABLE nugget_aos_log ADD partition (YEAR='2014', MONTH='08',DAY='19') location '/user/xxx/xx/year=2014/month=08/day=19';
或者
方法2. 导入指定文件,并将文件移动到用户的存储路径下
LOAD DATA inpath '/user/xxx/xx/2014/08/19' overwrite INTO TABLE xxx_log partition (YEAR='2014', MONTH='08',DAY='19');
接下来就可以查询表中的数据,做验证
hive>select * from xxx_log limit 100;
可能会碰到的情况,你的正则表达式在正则表达式工具(推荐:RegexBuddy)中,没有问题,但是在hive表显示时,每个字段值都是NULL,这说明正则表达式存在错误。这个时候可以用下面的办法解决,在hive中执行下面的命令:
hive>describe extended tablename;
– 查看表的详细信息,其中包括了hive表实际的input.regex正则表达式的值,看看建表的正则表达式转义字符是否缺少。
正则表达式的问题解决之后,再drop table xxx_log,再重新建表,导数据。最后能看到,nginx日志被拆分到了hive表的字段中,接下来就可以进行各种统计了。
hive 用户手册
Usage Examples
Creating tables
MovieLens User Ratings
CREATE TABLE u_data (
userid INT,
movieid INT,
rating INT,
unixtime STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Apache Access Log Tables
add jar ../build/contrib/hive_contrib.jar;
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\") ([^ \"]*|\"[^\"]*\"))?",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)
STORED AS TEXTFILE;
Control Separated Tables
CREATE TABLE mylog (
name STRING, language STRING, groups ARRAY<STRING>, entities MAP<INT, STRING>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS TEXTFILE;
Loading tables
MovieLens User Ratings
Download and extract the data:
wget http://www.grouplens.org/system/files/ml-data.tar+0.gz
tar xvzf ml-data.tar+0.gz
Load it in:
LOAD DATA LOCAL INPATH 'ml-data/u.data'
OVERWRITE INTO TABLE u_data;
Running queries
MovieLens User Ratings
SELECT COUNT(1) FROM u_data;
Running custom map/reduce jobs
MovieLens User Ratings
Create weekday_mapper.py:
import sys
import datetime
for line in sys.stdin:
line = line.strip()
userid, movieid, rating, unixtime = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([userid, movieid, rating, str(weekday)])
Use the mapper script:
CREATE TABLE u_data_new (
userid INT,
movieid INT,
rating INT,
weekday INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (userid, movieid, rating, unixtime)
USING 'python weekday_mapper.py'
AS (userid, movieid, rating, weekday)
FROM u_data;
SELECT weekday, COUNT(1)
FROM u_data_new
GROUP BY weekday;
Note: due to a bug in the parser, you must run the "INSERT OVERWRITE" query on a single line
hadoop map数目的分析和调整
Hadoop中在计算一个JOB需要的map数之前首先要计算分片的大小。计算分片大小的公式是:
goalSize = totalSize / mapred.map.tasks
minSize = max {mapred.min.split.size, minSplitSize}
splitSize = max (minSize, min(goalSize, dfs.block.size))
totalSize是一个JOB的所有map总的输入大小,即Map input bytes。参数mapred.map.tasks的默认值是2,我们可以更改这个参数的值。计算好了goalSize之后还要确定上限和下限。
下限是max {mapred.min.split.size, minSplitSize} 。参数mapred.min.split.size的默认值为1个字节,minSplitSize随着File Format的不同而不同。
上限是dfs.block.size,它的默认值是64兆。
举几个例子,例如Map input bytes是100兆,mapred.map.tasks默认值为2,那么分片大小就是50兆;如果我们把mapred.map.tasks改成1,那分片大小就变成了64兆。
计算好了分片大小之后接下来计算map数。Map数的计算是以文件为单位的,针对每一个文件做一个循环:
1. 文件大小/splitsize>1.1,创建一个split,这个split的大小=splitsize,文件剩余大小=文件大小-splitsize
2. 文件剩余大小/splitsize<1.1,剩余的部分作为一个split
举几个例子:
1. input只有一个文件,大小为100M,splitsize=blocksize,则map数为2,第一个map处理的分片为64M,第二个为36M2. input只有一个文件,大小为65M,splitsize=blocksize,则map数为1,处理的分片大小为65M (因为65/64<1.1)
3. input只有一个文件,大小为129M,splitsize=blocksize,则map数为2,第一个map处理的分片为64M,第二个为65M
4. input有两个文件,大小为100M和20M,splitsize=blocksize,则map数为3,第一个文件分为两个map,第一个map处理的分片为64M,第二个为36M,第二个文件分为一个map,处理的分片大小为20M
5. input有10个文件,每个大小10M,splitsize=blocksize,则map数为10,每个map处理的分片大小为10M
再看2个更特殊的例子:
1. 输入文件有2个,分别为40M和20M,dfs.block.size = 64M, mapred.map.tasks采用默认值2。那么splitSize = 30M ,map数实际为3,第一个文件分为2个map,第一个map处理的分片大小为30M,第二个map为10M;第二个文件分为1个map,大小为20M
2. 输入文件有2个,分别为40M和20M,dfs.block.size = 64M, mapred.map.tasks手工设置为1。
那么splitSize = 60M ,map数实际为2,第一个文件分为1个map,处理的分片大小为40M;第二个文件分为1个map,大小为20M
通过这2个特殊的例子可以看到mapred.map.tasks并不是设置的越大,JOB执行的效率就越高。同时,Hadoop在处理小文件时效率也会变差。
根据分片与map数的计算方法可以得出结论,一个map处理的分片最大不超过dfs.block.size * 1.1 ,默认情况下是70.4兆。但是有2个特例:
1. Hive中合并小文件的map only JOB,此JOB只会有一个或很少的几个map。
2. 输入文件格式为压缩的Text File,因为压缩的文本格式不知道如何拆分,所以也只能用一个map。
考虑采用合适的压缩器(压缩速度vs性能)对输出进行压缩,提高HDFS的写入性能。
每个reduce不要输出多个文件,避免生成附属文件。我们一般用附属文件来记录统计信息,如果这些信息不多的话,可以使用计数器。
为输出文件选择合适的格式。对于下游消费者程序来说,用zlib/gzip/lzo等算法来对大量文本数据进行压缩往往事与愿违。因为zlib/gzip/lzo文件是不能分割的,只能整个进行处理。这会引起恶劣的负载均衡和故障恢复问题。作为改善, 可以使用SequenceFile和TFile格式,它们不但是压缩的,而且是可以分割的。
如果每个输出文件都很大(若干GB),请考虑使用更大的输出块(dfs.block.size)。
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;
map数目调整
public static void setMinInputSplitSize(Job job,long size) {
job.getConfiguration().setLong("mapred.min.split.size", size);
}
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong("mapred.min.split.size", 1L);
}
public static void setMaxInputSplitSize(Job job,long size) {
job.getConfiguration().setLong("mapred.max.split.size", size);
}
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong("mapred.max.split.size",Long.MAX_VALUE);
}
如上我们可以看到,Hadoop在这里实现了对mapred.min.split.size和mapred.max.split.size的定义,且默认值分别为1和Long的最大。因此,我们在程序只需重新赋值给这两个值就可以控制InputSplit分片的大小了。
3.假如我们想要设置的分片大小为10MB
则我们可以在MapReduce程序的驱动部分添加如下代码:
TextInputFormat.setMinInputSplitSize(job,1024L);//设置最小分片大小
TextInputFormat.setMaxInputSplitSize(job,1024×1024×10L);//设置最大分片大小
UDF永久生效
hive根据不同的参数匹配evaluate();
udf比较简单一行生成一行,对一行进行计算,
udaf聚合函数比较麻烦,有merge函数等,在不同的map函数中和reduce中进行。
udtf有一行生成多行或者多列,initialize和progress以及close等,在建表的时候运用,可以用序列化和正则
来做到相同的效果 见http://www.uroot.com/archives/1059
在HIVE_HOME的bin目录下新建一个.hiverc的文件,把写好的udf的注册语句写在这里就可以类似HIVE内置的用法一样用
原理是,在运行./hive命令时,同时会加载HIVE_HOME/bin/.hiverc and $HOME/.hiverc作为初始化所需要的文件
在.hiverc文件中加入以下内容:
add jar /run/jar/Avg_test.jar
create temporary function avg_test 'hive.udaf.Avg';















 7517
7517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









