







问题描述
在我进行seek()的练习使用时出现如题所示的报错
f = open('myfile.txt', 'r', encoding='utf-8')
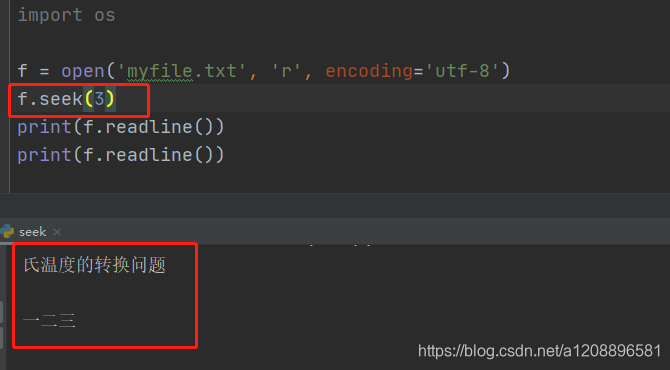
f.seek(8)
print(f.readline())
print(f.readline())
文件内容如下
摄氏温度的转换问题
一二三
三二一
问题解决
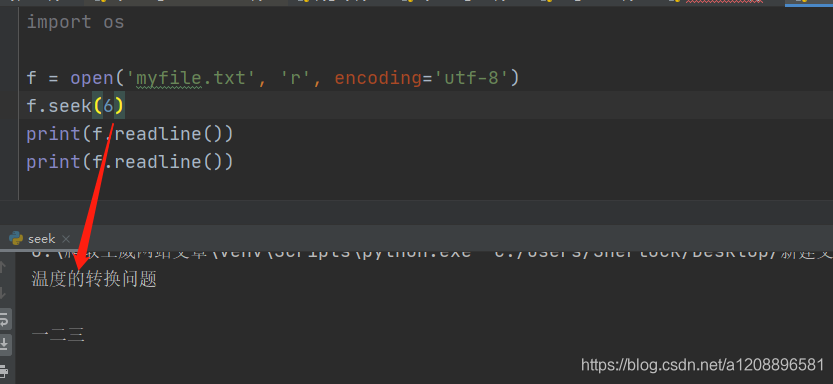
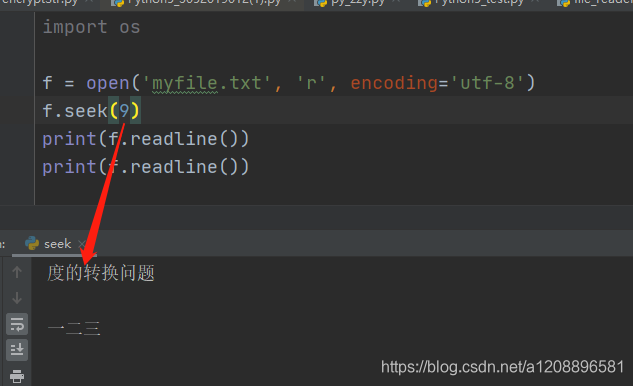
将seek()中的偏移量参数改为3,6,9等3的倍数时,余下字符串正常输出,无报错
如图
相关知识及思路
起初我查找网上教程,以为是编码格式设置问题,但是将编码格式指定后,错误依然存在,于是查找了seek的相关说明:1
概述
seek()方法用于移动文件读取指针到指定位置。语法 seek() 方法语法如下:
fileObject.seek(offset[, whence])
参数
offset – 开始的偏移量,也就是代表需要移动偏移的字节数whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
再次查找utf-8相关知识,发现关于汉字的解释2:
其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
于是猜测是因为seek的偏移量(起初取为8)使得文件读取指针到了一个并不是单个汉字编码结束的地方(即不是三的整数倍),所以剩下的编码并不能按照三字节、三字节、三字节地解读为正确的字符(此处为汉字),故而报错,遂有了题中以3,6,9为偏移量的试探,经验证,结论正确。
至于查到的特别注明以gbk编码读取而成功解决的案例,那可能文件本身就是以gbk编码写入的,总之,什么形式的编码,就以什么编码形式读取,搞好对应之后,也并不一定不出错。
而gbk编码中单个汉字所占字节数,那又是另一个故事了














 6939
6939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









