







filebeat作为日志采集agent, 是需要部署到生产服务器上的.不理解filebeat的工作机制,不了解filebeat在实际生产使用中的内存使用将会给你带来意想不到的麻烦.
有些文章说filebeat内存消耗很少,不会超过100M, 这简直是不负责任的胡说,假如带着这样的认识把filebeat部署到生产服务器上就等着哭吧.
filebeat在空载情况(没有日志可采集)下的确不会有大的内存开销,但在有大量的日志需要采集时,filebeat的内存占用是没有固定值的, 那有没有理论值呢?答案是有, 为啥这么说,看下面公式:
bytes_each_log * spool_size * M + a*N
其中, bytes_each_log是单条日志大小, spool_size是配置文件里配置项, M是单条日志在内存里的溢价系数(>1), N表示采集的文件个数,a为常数.
spool_size的默认值是2048, 好多人估计都不会配置这个项,也会因此埋下祸根(OOM):
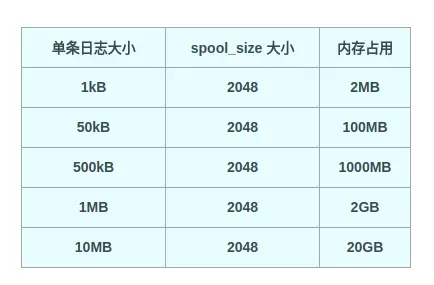
假设忽略a*N部分的内存开销, 单条日志的内存溢价为3, 一旦出现单条日志大于50KB且有瞬间爆发量的时候, filebeat的内存占用将大于300MB,是不是有点吓人!如果出现了极端情况,单条日志>10M,即使filebeat会截断到10M那也是20GB!!是不是腿都软了!!!
filebeat在实际使用过程中内存>300M,甚至15GB的情况浣熊都遇到过, 内存超过300M几乎经常遇到,基本都是因为客户没有按照吩咐的去做导致的; 15GB的那次有点意外和惊喜, 客户在自己的日志文件里打了大量的二进制文件(后来知道真相的我眼泪掉下来...), 大量的二进制文件触发了10MB规则,还好吃掉15GB内存后filebeat因OOM退出了,没有带来严重的损失.
那怎么样才能避免以上内存灾难呢?划重点了,快快拿出小本本记录:
(1)每个日志生产环境生产的日志大小,爆发量都不一样, 要根据自己的日志特点设定合适的spool_size值;什么叫合适,至少能避免内存>200MB的灾难;
(2)在不知道日志实际情况(单条大小,爆发量), 务必把spool_size设置上,建议128或者256;
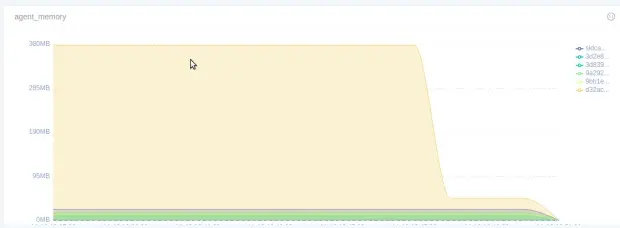
最后分享张实践图片:
单条日志为45KB, spool_size为2048的内存开销,陡坡下是spool_size调整为128的效果.















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









