









对稀疏矩阵进行转置操作,按照老师讲的,有两种办法。我用的是第一种最简单的,从上到下一行一行得走,虽然速度很慢,但是简单。
说实话这个题目很讨厌,我们定义的三元组里面mu表示的是行数,但是题目要求输入的m表示的是列数,这就很容易搞混了。
但是我们不用n和m表示行和列,而是用线性代数里面的r表示行,c表示列,这样做不容易错,反正它先输入的永远是行,后输入的永远是列。
其中进行转置操作的函数function,感觉很像咱们上学期用过的“冒泡排序”。
为什么答案都对但是仍然WA的原因:
首先,大概率就是输出输入的问题,也就是说,问题十有八九都出在了printf和scanf这两个函数上
下面我分情况讨论一下允许的输入格式:
1.输入两个正整数:
scanf("%d%d",&m,&n); 正确
scanf("%d %d",&m,&n); 正确
2.输入矩阵三元组:(我就栽在这个地方了mmp)
scanf("%d%d%d",&i,&j,&x);
if(i==0&&j==0&&x==0) break; 错误!
scanf("%d %d %d",&i,&j,&x);
if(i==0&&j==0&&x==0) break; 错误!
(具体为什么错误我也不清楚,反正这样做就是不对,不是RE就是WA)
(4.17日最新更新:上面的两个错误,好像又可以AC通过了,搞得我很懵圈)
(懵圈过后,我就开始怀疑,之前WA的原因,十有八九是因为我把“&&”写成了“&”)
scanf("%d",&i);
getchar();
scanf("%d",&j);
getchar();
scanf("%d",&x);
if(i==0&&j==0&&x==0) break; 正确!
3.输出转置后的矩阵三元组:
printf("%d %d %d\n"...) 正确!
printf("%d %d %d \n"...) 正确!
其次,小概率不是输入输出的问题,而是样例输出给的不够好,题目本身有问题!
为什么呢?因为如果你输入这样:

它的意思并不是下面这个矩阵:
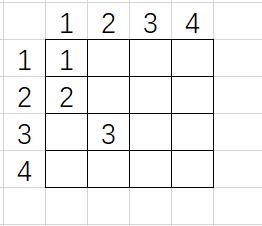
它表示的其实是这个矩阵!!!
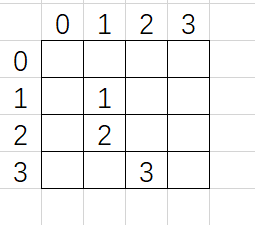
没想到叭!我就是第二次栽到了这里。
那这又是什么意思呢?意思就是:
在测试用例中,存在一种情况,比如说:
4 4
1 0 1
2 1 2
3 2 3
0 0 0
其中,1 0 1这种奇葩数据,它居然能拿得出来!!!
也就是说,在我们编写“矩阵转置”函数时,如果把第1层函数头写成下面这样子,是不对的:
for(int fre=1;fre<=p1->nu;fre++){
正确的应该是下面这样子:
for(int fre=0;fre<p1->nu;fre++){
下面是我AC的代码,希望能帮到大家:
最后如果对大家有所帮助,希望大家可以加关注哦。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<math.h>
typedef struct Triple{
int i,j;
int x;
}Triple;
typedef struct TSMatrix{
Triple data[1000];
int mu,nu,tu;
}TSMatrix;
TSMatrix* CreateEmptyTsmatrix(){
TSMatrix *p=(TSMatrix*)malloc(sizeof(TSMatrix));
if(p==NULL){
printf("Out of space!\n");
}else{
p->mu=0;
p->nu=0;
p->tu=0;
return p;
}
}
void Insert(TSMatrix *p,int i,int j,int x,int k){
p->data[k].i=i;
p->data[k].j=j;
p->data[k].x=x;
p->tu=p->tu+1;
}
void BuildTsmatrix(TSMatrix* p){
int k=0;
while(1){
int i,j,x;
scanf("%d",&i);
getchar();
scanf("%d",&j);
getchar();
scanf("%d",&x);
if(0==i&&0==j&&0==x) break;
//如果输入0?0?0,那么最终i=0,j=1,x=0,这样矩阵中的元素就输入完毕了
else{
Insert(p,i,j,x,k);
k++;
}
}
}
void Output(TSMatrix* p){
for(int k=0;k<p->tu;k++){
printf("%d %d %d \n",
p->data[k].i,
p->data[k].j,
p->data[k].x);
}
}
void Transposition(TSMatrix* p1,TSMatrix* p2){//矩阵的转置
int k2=0;
for(int fre=0;fre<p1->nu;fre++){
//1次fre能够完成p1中1列的转置
//比如说,fre=0,把p1中第1列转置完成,变成p2的第1行
//然后fre=1,把p1中第2列转置完成,变成p2的第2行
//......
//最后fre=p1->nu-1,把p1的最后一列转置完成,变成p2的第p1->nu行
for(int k1=0;k1<p1->tu;k1++){
//完成p1中1列的转置时,从data[0]元素开始,挨个往下看,
if(p1->data[k1].j==fre){
//如果先找到了一个元素,它的列数正好是fre-1,那就放到p2里面
Insert(p2,
p1->data[k1].j,
p1->data[k1].i,
p1->data[k1].x,
k2);
k2++;//k2仅且仅需要初始化1次,所以k2的定义放在所有循环的外面
}
}
}
}
int main(){
TSMatrix* p1=CreateEmptyTsmatrix();//p1放原矩阵
TSMatrix* p2=CreateEmptyTsmatrix();//p2放转置矩阵
int r,c;
scanf("%d%d",&r,&c);//p1的行数为r,列数为c
p2->nu=p1->mu=r;
p2->mu=p1->nu=c;
BuildTsmatrix(p1);
Transposition(p1,p2);
Output(p2);
return 0;
}实在不行的话,点个赞也可以哦。














 2321
2321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









