






文章目录
📑前言
在人工智能的浪潮中,视频生成技术正逐渐成为推动技术进步的关键力量。丹摩智算(DAMODEL)作为这一领域的先行者,最近发布了其最新的视频生成模型——CogVideoX-6B。本文将带你深入了解CogVideoX-6B模型的部署与使用,让你领略丹摩智算的强大之处。
一、CogVideoX-6B:智谱清影的突破
智谱 AI 在 8 月 6 日宣布了一个令人兴奋的消息:他们将开源视频生成模型 CogVideoX,目前,其提示词上限为 226 个 token,视频长度为 6 秒,帧率为 8 帧 / 秒,视频分辨率为 720*480,而这仅仅是初代,性能更强参数量更大的模型正在路上。

CogVideoX-6B的核心优势
- 高效的3D变分自编码器:这项技术能够将视频数据压缩至原来的 2%,极大地降低了模型处理视频时所需的计算资源,还巧妙地保持了视频帧与帧之间的连贯性,有效避免了视频生成过程中可能出现的闪烁问题。
- 3D旋转位置编码(3D RoPE)技术:使得模型在处理视频时能够更好地捕捉时间维度上的帧间关系,建立起视频中的长期依赖关系,从而生成更加流畅和连贯的视频序列。
- 端到端的视频理解模型:能够为视频数据生成精确且与内容紧密相关的描述。这一创新极大地增强了 CogVideoX 对文本的理解和对用户指令的遵循能力,确保了生成的视频不仅与用户的输入高度相关,而且能够处理超长且复杂的文本提示。
二、CogVideoX-6B的部署实践流程
2.1 创建丹摩实例
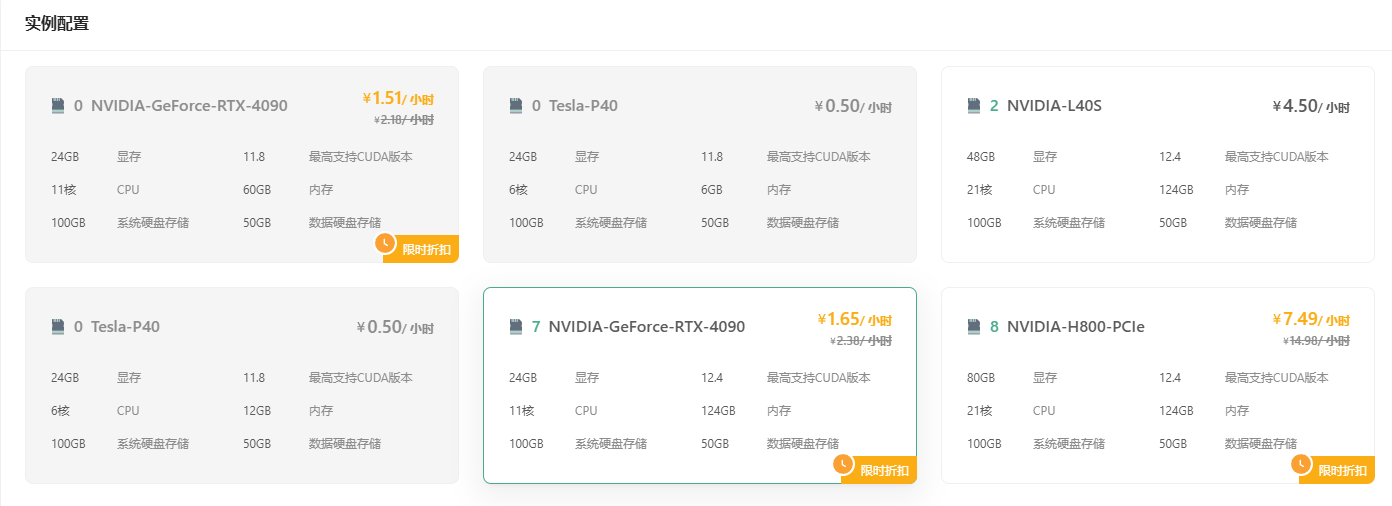
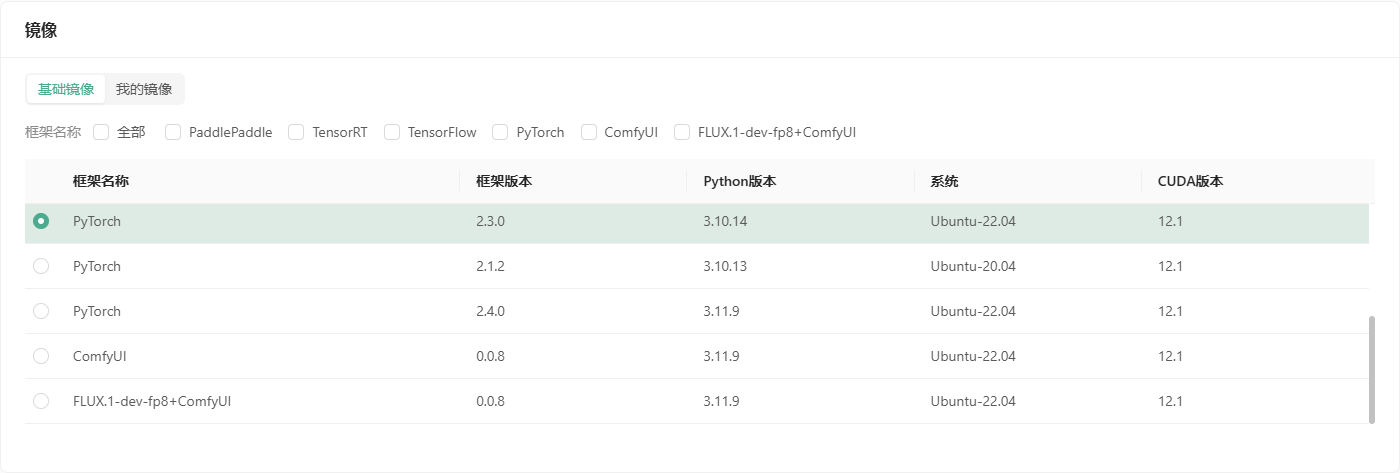
首先进入控制台,选择 GPU 云实例,点击创建实例。由于 CogVideoX 在 FP-16 精度下的推理至少需 18GB 显存,微调则需要 40GB 显存,我们这里可以选择 L40S 显卡(推荐)或者 4090 显卡,硬盘可以选择默认的 100GB 系统盘和 50GB 数据盘,镜像选择 PyTorch2.3.0、Ubuntu-22.04,CUDA12.1 镜像,创建并绑定密钥对,最后启动。

2.2 配置环境和依赖
平台已预置了调试好的代码库,您可开箱即用,以下是配置方法:
- 拉取代码仓库:进入 JupyterLab 后,打开终端,首先拉取 CogVideo 代码的仓库。
wget http://file.s3/damodel-openfile/CogVideoX/CogVideo-main.tar
- 解压缩代码仓库:
tar -xf CogVideo-main.tar
- 安装依赖:进入 CogVideo-main 文件夹,输入安装对应依赖。
cd CogVideo-main/
pip install -r requirements.txt

2.3 模型与配置文件
除了配置代码文件和项目依赖,还需要上传 CogVideoX 模型文件和对应的配置文件。
- 下载模型:平台已为您预置了 CogVideoX 模型,您可内网高速下载,执行以下命令:
cd /root/workspace
wget http://file.s3/damodel-openfile/CogVideoX/CogVideoX-2b.tar
- 解压缩模型:
tar -xf CogVideoX-2b.tar
三、开始运行
3.1 调试
进入 CogVideo-main 文件夹,运行 test.py 文件:
cd /root/workspace/CogVideo-main
python test.py
test.py 代码内容如下,主要使用 diffusers 库中的 CogVideoXPipeline 模型,加载了一个预训练的 CogVideo 模型,然后根据一个详细的文本描述( prompt),生成对应视频:
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
# prompt里写自定义想要生成的视频内容
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
pipe = CogVideoXPipeline.from_pretrained(
"/root/workspace/CogVideoX-2b", # 这里填CogVideo模型存放的位置,此处是放在了数据盘中
torch_dtype=torch.float16
).to("cuda")
# 参数do_classifier_free_guidance设置为True可以启用无分类器指导,增强生成内容一致性和多样性
# num_videos_per_prompt控制每个prompt想要生成的视频数量
# max_sequence_length控制输入序列的最大长度
prompt_embeds, _ = pipe.encode_prompt(
prompt=prompt,
do_classifier_free_guidance=True,
num_videos_per_prompt=1,
max_sequence_length=226,
device="cuda",
dtype=torch.float16,
)
video = pipe(
num_inference_steps=50,
guidance_scale=6,
prompt_embeds=prompt_embeds,
).frames[0]
export_to_video(video, "output.mp4", fps=8)
运行成功后,可以在当前文件夹中找到对应 prompt 生成的 output.mp4 视频。

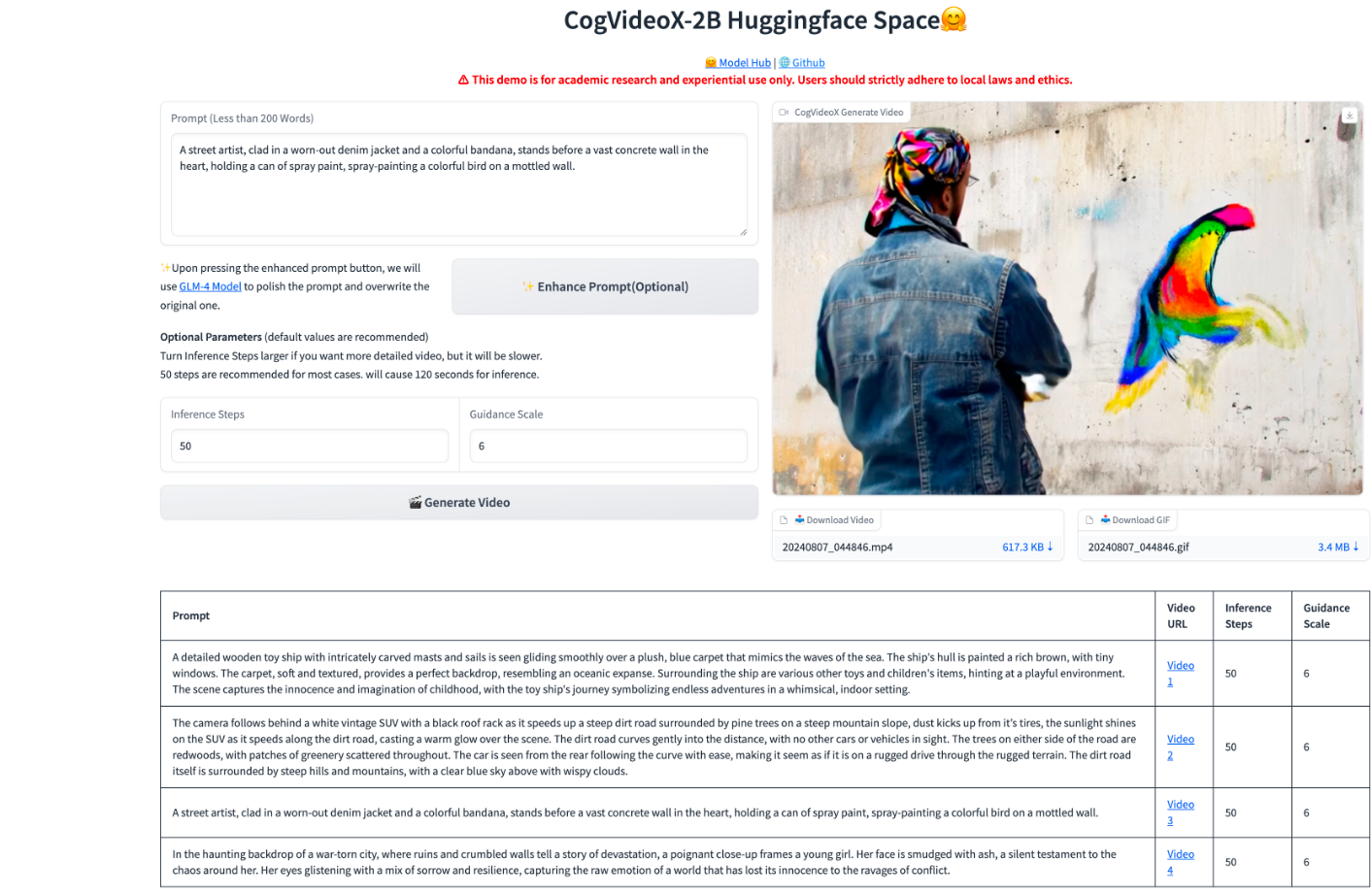
3.2 WebUI
模型官方也提供了 webUIDemo,进入 CogVideo-main 文件夹,运行 gradio_demo.py 文件:
cd /root/workspace/CogVideo-main
python gradio_demo.py
运行后我们可以看到,访问路径是本地 url http://0.0.0.0:7870。
此时我们需要通过丹摩平台提供的端口映射能力,把内网端口映射到公网。
















 9989
9989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











