






Hbase简介
1.1 简介
1)Hbase是一个分布式的、多版本的、面向列的开源数据库
2)Hbase利用Hadoop HDFS 作为其文件存储系统,提供高可靠性、搞性能、列存储、可升缩、实时读写、适用于非结构化数据存储的数据库系统
3)Hbase利用Hadoop MapReduce来处理Hbase中的海量数据
4)Hbase利用Zookeeper作为分布式协同服务
1.2 特点
1)数据量大:一个表可以有上亿行,上百万列(列多时,插入变慢)
2)面向列: 面向列(族)的存储和权限控制, 列(族)独立检索
3)稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
4)多版本: 每个cell中的数据可以有多个版本, 默认情况下版本号自动分配, 是单元格插入时的时间戳
5)无类型: HBase中的数据都是字符串,没有类型
6)强一致性:同一行数据的读写只在同一台Region Server上进行
7)有限査询方式:仅支持三种査询方式(单个rowkey査询,通过rowkey的range査询, 全表扫描)
rowkey的range査询, 全表扫描)
8)高性能随机读写
1.3 数据模型
1)行:同一个key对应的所有数据
2)列族:相似的列数据通常被划分成一个列族,建表时确定
3)列:列名在写入时确定
4) Cell及时间戳(版本):
每个cell有任意多的版本
建表时设置每个列族可以保留多少个版本
5)三维有序
SortedMap(RowKey,
List(SortedMap(Column,
List(Value, TimeStamp))))
rowkey(ASC)+ columnLabel(ASC)+ Version(DESC) -> value

1.4 体系架构
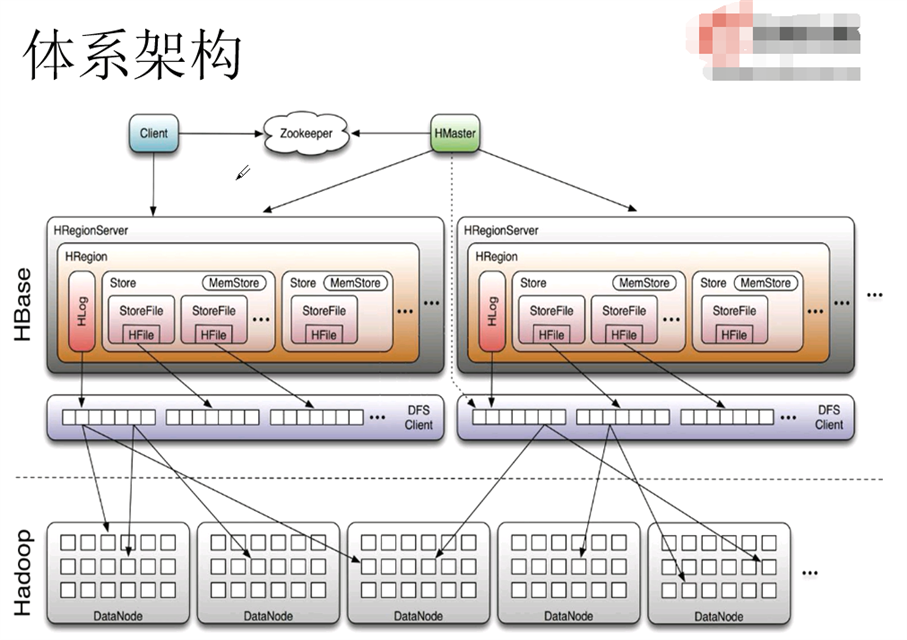
1) Client
包含访问 HBase的接口并维护cache来加快对HBase的访问
2) Zookeeper
保证任何时候,集群中只有一个(H)master;
存贮所有Region的寻址入口;
实时监控Regionserver的上线和下线信息,并实时通知给Master
存储HBase的schema和table元数据
3) (H)Master
为Region server分配region;
负责Region server的负裁均衡;
发现失效的Region server并重新分配其上的region;
管理用户对table的增册改査操作
4) (H)RegionServer
负责维护region, 处理对这些region的I/O请求;
负责切分在运行过程中变得过大的 region
两个重要的表:
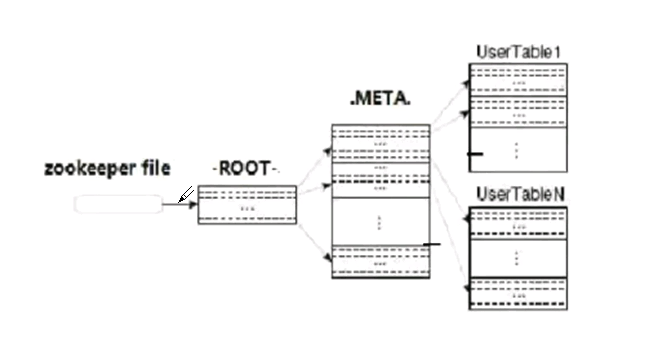
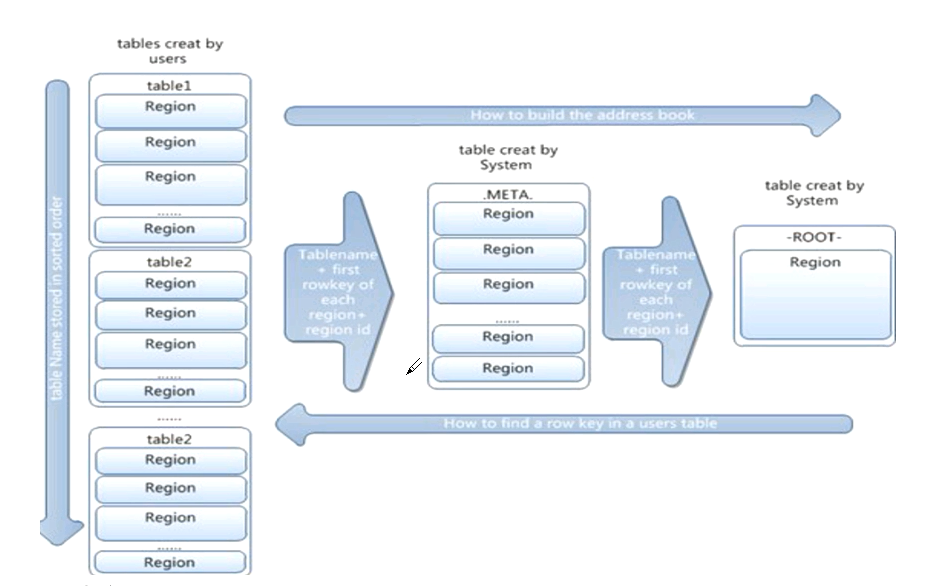
5) ROOT表
记录META表中每个region的位置,ROOT表最多只有一个region
Zookeeper中记录了ROOT表的location
6)META表
记录各个表中每个region所在的region server,META表可能包含多个region
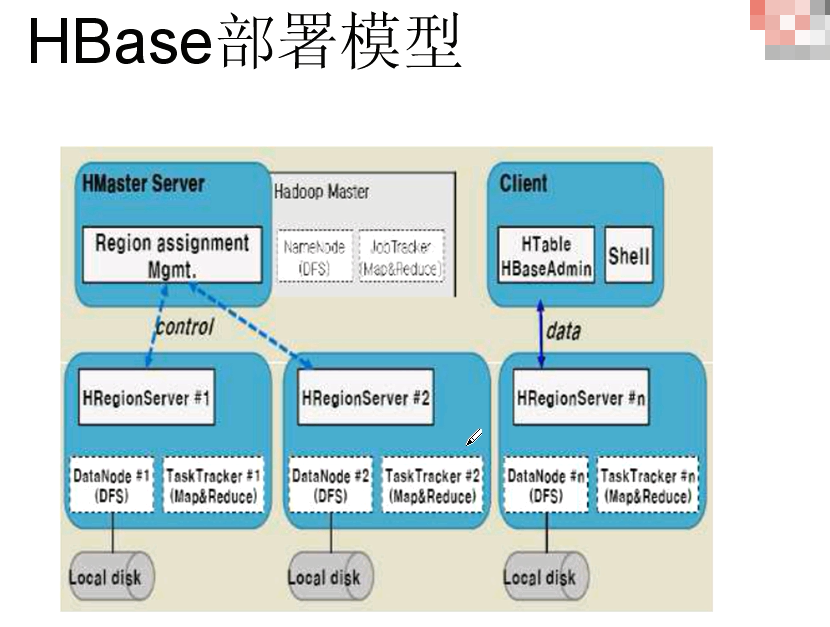
1.5 Hbase部署模型
1.6 Hbase操作
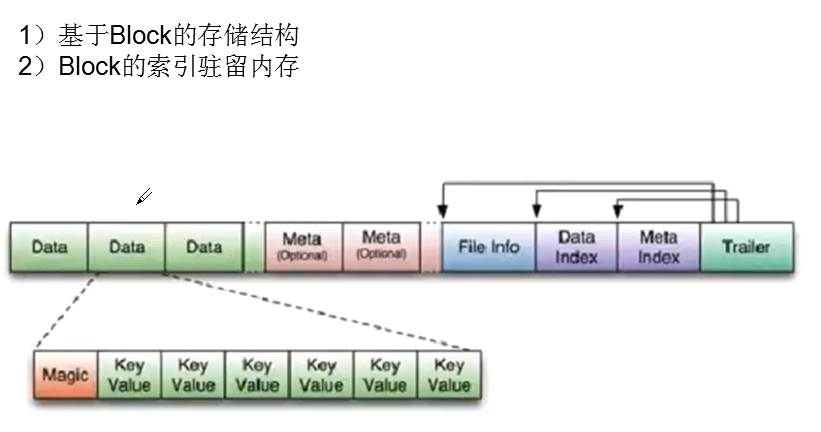
1)flush
内存容量有限,需要定期将内存中的数据flush到磁盘
每次flush, 每个region的每个column family都会产生一个HFile
读取操作, regionserver会把多个HFile数据归并到一起
2)compaction (归并)
flush操作产生的HFile会越来越低,需要归并来减少HFile的数量
旧数据会被清理
3) split
HFile大小增长到某个阈值就会split, 同时把Regionsplit成两个region,这两个
region被分发到其他不同的region server上
4) scan
hbase原生提供的方法,顺序扫库;
当然可以使用mapreduce并发扫库的方法
5) Bulk Load
快速导入大批量数据的方法
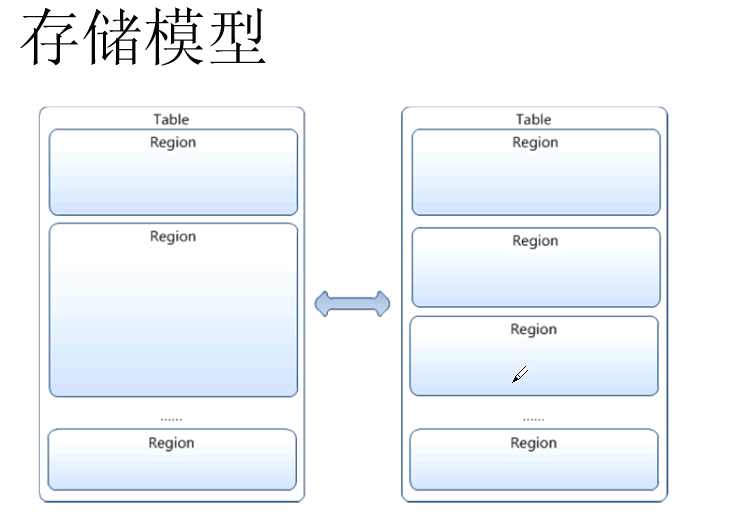
1.7 存储模型:
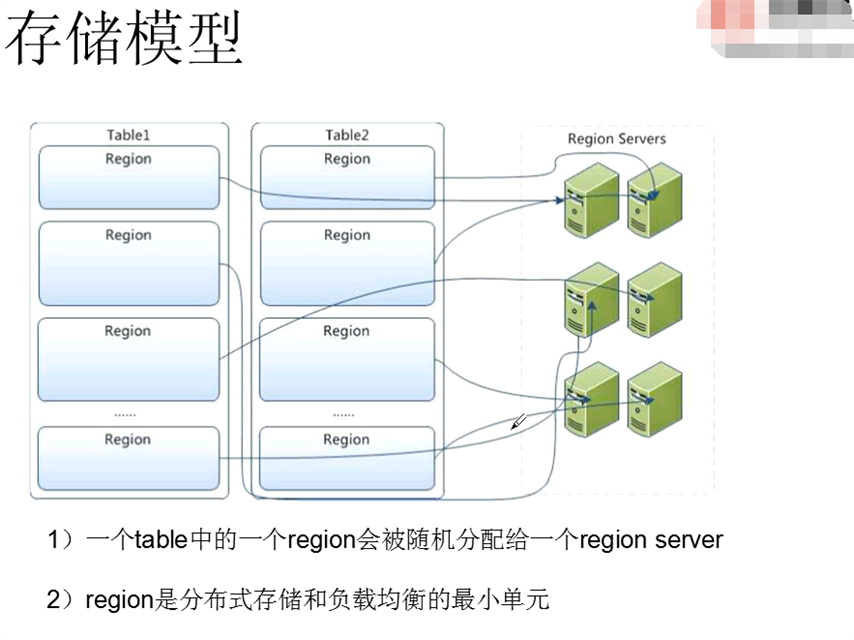
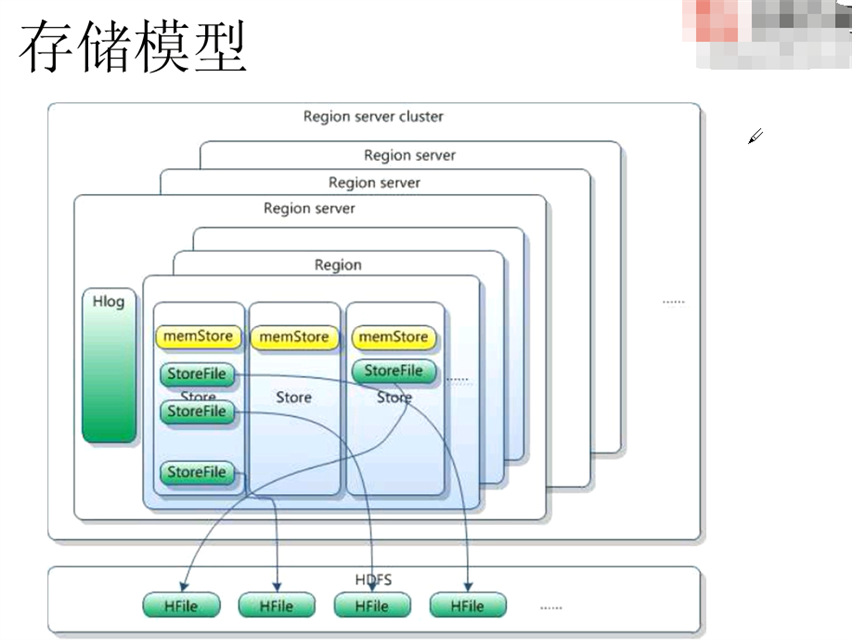
最开始 table 只有一个region,但是随着数据的put,到达某个阈值的时候,一个大的region会split成几个小的region,被分散到其他region server















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









