






 本文深入探讨Hive SQL的高级应用,包括内部表与外部表的区别、分区表的创建与查询、表关联查询的优化策略,以及如何利用Hive进行大规模数据处理,提升查询效率。
本文深入探讨Hive SQL的高级应用,包括内部表与外部表的区别、分区表的创建与查询、表关联查询的优化策略,以及如何利用Hive进行大规模数据处理,提升查询效率。
1.查看mysql中metastore数据存储结构
Metastore中只保存了表的描述信息(名字,列,类型,对应目录)
使用SQLYog连接itcast05 的mysql数据库
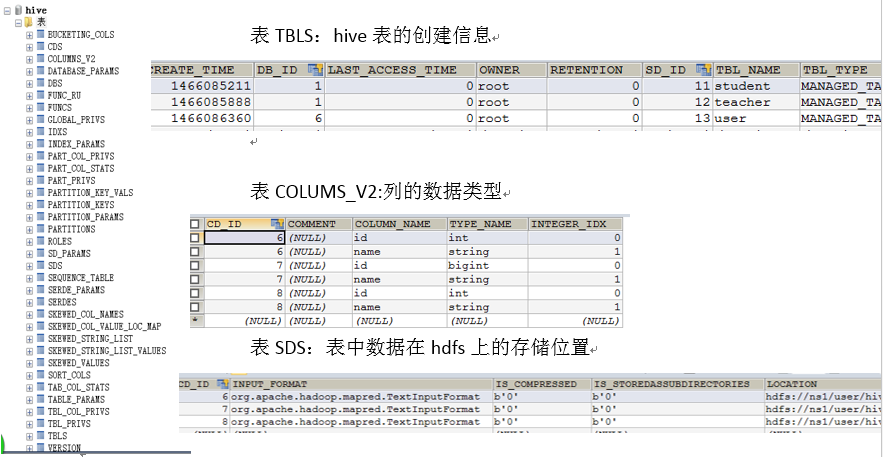
查看hive数据库的表结构:
2.建表(默认是内部表(先建表,后有数据))
(建表时必须指定列的分隔符)
create table trade_detail(
id bigint,
account string,
income double,
expenses double,
time string)
row format delimited fields terminated by '\t';
3.Hive状态下执行Hadoop hdfs命令
在使用hive shell 的时候,我们有时候需要操作hdfs
Hive为我们提供了在hive命令行下hdfs的shell:
,例如:
dfs -ls /;
dfs -mkdir /data;
dfs -put /root/student.txt;
用法和hdfs下是一样的,只是细微的差别
和Hadoop命令稍微有些差别,前面是dfs开头,后面以“;”结尾
4.创建–外部表(先有数据,后建表)
先上传数据文件 a.txt b.txt 到hdfs:/data目录下,
a.txt 和 b.txt 中的内容都是:
后执行创建表的命令:

create external table ext_student (
id int,
name string)
row format delimited fields terminated by '\t'
location '/data';
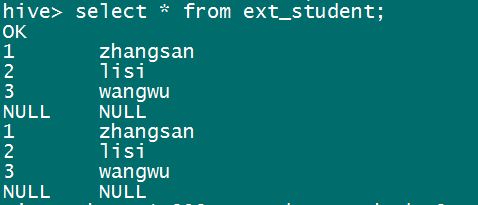
创建完成后使用命令:select * from ext_student; 查看表中内容:
再次上传数据文件 pep.avi
到 hdfs:/data 目录下,后执行全表扫描:select * from ext_student;
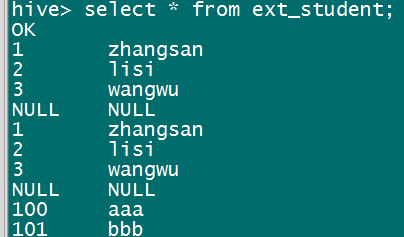
说明:只要将这个数据放到 hdfs:/data 表所指定的目录下,hive就能将这个表中的数据读取出来(内部表和外部表都支持,但也存在特殊情况读不出)
为什么把文件丢到对应目录下就能把数据读出来?
答:因为metastore记录了这张表和数据的映射关系
SDS表中的内容:

5.创建–分区表
建分区表是为了提高数据的查询效率,按照省份、年份、月份等分区
创建一个外部分区表(External Table ):
(表名:beauties 指向文件:beauty)
create external table beauties (
id bigint,
name string,
size double)
partitioned by (nation string)
row format delimited fields terminated by ‘\t’
location ‘/beauty’ ;
show create table beauties;
执行完成之后发现hdfs根目录下有beauty文件夹。
准备好3个数据文件: b.c b.j b.a
载入数据文件,同时指定分区:



load data local inpath '/root/b.c' into table beauties partition (nation='China');
查看表中是否成功load数据:
突发奇想:能否像平常使用外部表一样,在 hdfs:/beauty 目录下创建一个文件夹 nation=Japan ,然后将b.j 文件上传到这个目录下,数据就可以查出来了?

答:不行! 因为在载入数据的时候,metastore是不知道你将这个文件放到 /beauty/nation=Japan/ 目录下的。
拯救方法:通知hive在元数据库中添加一个beauties表的分区记录
alter table beauties add partition (nation=’Japan’) location “/beauty/nation=Japan/”
添加分区后,metastore中SDS表多了一条 记录:

再次查询beauties表,发现b.j中的数据也能查询出来了:
分区表的使用优势:
select * from beauties where nation=’China’;
在数据量很大的时候,建分区表可以提高查询效率,就不需要将整张表数据筛选对比之后再输出,因为数据在hdfs中直接是以分区存储的,所以使用类似”nation”等分区字段是可以直接把数据取出的
删除分区:
alter table beauties drop if exists partition (nation ='Japan') ;
注:这里的 if exists 字段呢,是一个检查分区是否存在的字段,存在则删除,不存在也不会报错说分区不存在啦
建内部分区表(Managed Table)
create table td_part(
id bigint,
account string,
income double,
expenses double,
time string)
partitioned by (logdate string)
row format delimited fields terminated by '\t';
普通表和分区表区别:有大量数据增加的需要建分区表
create table book (
id bigint,
name string)
partitioned by (pubdate string)
row format delimited fields terminated by '\t';
分区表加载数据
(hive自己的语法)
load data local inpath './book.txt'
overwrite into table book
partition (pubdate='2010-08-22');
local inpath –>从本地磁盘加载,不是hdfs
overwrite –>以覆盖的方式将数据写入book表中
以下创建表的方式少了“overwrite”,则是以追加方式将数据加载到hive表中:
load data local inpath '/root/data.am'
into table beauty
partition (nation="USA");
使用分区字段查询表中的数据
select nation, avg(size) from beauties group by nation order by avg(size);
6. 表关联查询
查询举例:
需求:
对 trade_detail 按照账户进行分组,求出每个账户的总支出总结余,然后和 user_info 进行表关联,取出名称。
在mysql中一条查询语句就能完成关联查询:
select t.account,u.name,t.income, t.expenses, t.surplus
from user_info u join (
select account,sum(income) as income,sum(expenses) as expenses,sum(income-expenses) as surplus
from trade_detail group by account
) t
on u.account = t.account
但是数据量一大,这个查询过程将变得极其漫长
所以我们使用hive来完成:
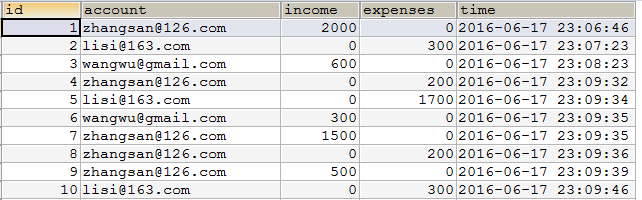
a) 首先要将2张表中的数据导入hdfs中,同样,我们也可以将mysql中的数据直接导入到hive表里面:
Mysql中的表: trade_detail表:
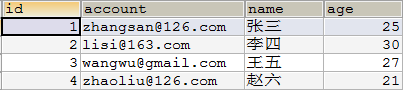
user_info表:
b) 在hive中创建表
trade_detail表:
create table trade_detail (
id bigint,
account string,
income string,
expenses string ,
times string)
row format delimited fields terminated by ‘\t’;
user_info表:
create table user_info (
id int,
account string,
name string,
age int)
row format delimited fields terminated by ‘\t’;
c) 使用Sqoop 将mysql中trade_detail的数据导入hive中
./sqoop import
--connect jdbc:mysql://192.168.1.102:3306/itcast
--username root
--password 123
--table trade_detail
--hive-import
--hive-overwrite
--hive-table trade_detail
--fields-terminated-by '\t';
可能会出现如下的错误:

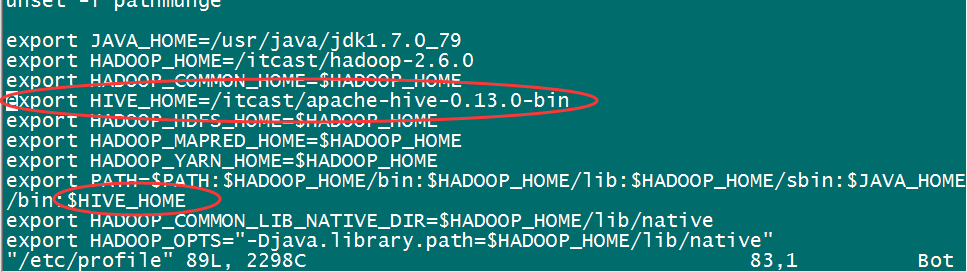
原因是没有将hive添加到环境变量:
解决:
1)编辑 /etc/profile 文件,添加HIVE_HOME:
2)source /etc/profile 刷新配置
3)使用 which 命令查看是否添加成功:
ok
4)再次执行sqoop命令,发现sqoop导入正在执行,可以看到map-reduce工作正在执行,在web浏览器上查看执行完成之后的结果文件:

Sqoop导入执行成功!
d) 使用Sqoop 将mysql中user_info的数据导入hive的user_info中
./sqoop import
--connect jdbc:mysql://192.168.1. 102:3306/itcast
--username root
--password 123
--table user_info
--hive-import
--hive-overwrite
--hive-table user_info
--fields-terminated-by '\t';
e) hive执行关联查询语句之后的结果:
select t.account,u.name,t.income, t.expenses, t.surplus
from user_info u join (
select account,sum(income) as income,sum(expenses) as expenses,sum(income-expenses) as surplus
from trade_detail group by account
) t
on u.account = t.account;


















 9982
9982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









