









MapReduce是一种离线批式计算框架,与Spark streaming、flink等流式计算框架不同,其输入数据是固定不可变的,延时较高,适合处理大批量实时分析的场景。
MapReduce源于:2004年12月Google发表的论文,其特点:
1)易于编程;
2)良好的扩展性;
3)高容错性;
4)适合PB级以上海量数据离线处理
应用场景:
流量统计/单词统计/最流行的K个搜索词/复杂算法实现
MR编程模型:

MR执行过程
1)数据会被切割成数据分片;-Split
2)数据片段以key和value的形式被读进来,默认是以行下标作为key,以行的内容作为value。-InputFormat
3)数据会传入Map中进行处理,处理逻辑由用户自定义,在处理完后以key和value形式输出;-Mapper
4)输出的数据经过shuffle,shuffle主要进行数据的排序、分组和合并等操作,shuffle处理的数据不会对原数据进行改变。默认以ASCII码排序-Shuffle
5)数据随后传给Reduce进行处理,处理完后生成k3和v3-Reducer
6)Reduce处理完后的数据会被写到hdfs的某个目录中。-Output
注意:Map-Reduce的思想就是“分而治之”。
Mapper负责“分”,即把“复杂的任务”分解为若干简单的任务执行。
Map处理数据在内存中(buffer in memory),内存放不下时,spill到disk上。
实例:WordCount
首先在pom文件中引入需要添加的依赖pom.xml:
<properties>
<project.build.directory>.</project.build.directory>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<maven.version>3.5.0</maven.version>
<hadoop.version>2.6.5</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
(一)Mapper端代码:
package cn.sendto.wordcount;
/**
* @Author: lf
* @Date: 2020-07-16 18:51
* @Version 1.0
*/
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable intValue = new IntWritable(1);
private Text keyword = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
// 空格分词
String[] str = value.toString().split(" ");
for (String item: str) {
if(item.isEmpty()) {
continue;
}
keyword.set(item);
context.write(keyword, intValue);
}
}
}
继承Reducer类,传入Mapper的输入k,v和输出k,v类型:
输入k:LongWritable=>行offset;输入v:Text=>行内容
输出:k=>Text;输出v:IntWritable=>行号
Writable=>序列化的
重新实现map方法:主要的业务逻辑
(二)Reducer
package cn.sendto.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @Author: lf
* @Date: 2020-07-17 9:43
* @Version 1.0
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable wordNum = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException{
int sum = 0;
for(IntWritable i: value) {
sum += i.get();
}
wordNum.set(sum);
context.write(key, wordNum);
}
}
继承Reduce类:Reducer<Text, IntWritable,Text, IntWritable >
//Mapper的输出时reduce的输入
reduce方法Text, Iteratable, Context
求和运算,结束后通过context.write()写入
(三)主入口
package cn.sendto.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* @Author: lf
* @Date: 2020-07-17 10:22
* @Version 1.0
*/
public class MRRunJob {
public static void main(String[] args) {
Configuration conf = new Configuration();
// NameNode ip
conf.set("fs.defaultFS", "hdfs://10.45.154.209:8020");
// conf.set("mapreduce.framework.name","local");
Job job = null;
try {
job = Job.getInstance(conf, "mywc");
} catch (IOException e1) {
e1.printStackTrace();
}
job.setJarByClass(MRRunJob.class);
// Mapper类名
job.setMapperClass(WordCountMapper.class);
// Reducer类名
job.setReducerClass(WordCountReducer.class);
// Map输出key类型、value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
try {
// 读取文件的位置
FileInputFormat.setInputPaths(job, new Path("/user/LF/data/input/"));
FileOutputFormat.setOutputPath(job, new Path("/user/LF/data/output/"));
//提交job给hadoop集群,等待作业完成后main方法才会结束
boolean f = job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
主要是设置hdfs地址、创建job实例、设置map、reduce的相关类,以及Map的输出k,V类型。注意输出目录的地址不能存在,否则无法执行。
上面所有准备好后,还需要对hadoop内部的NativeIO文件进行修改,否则会报:Exception in thread “main” java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.native.NativeID$Windows.access
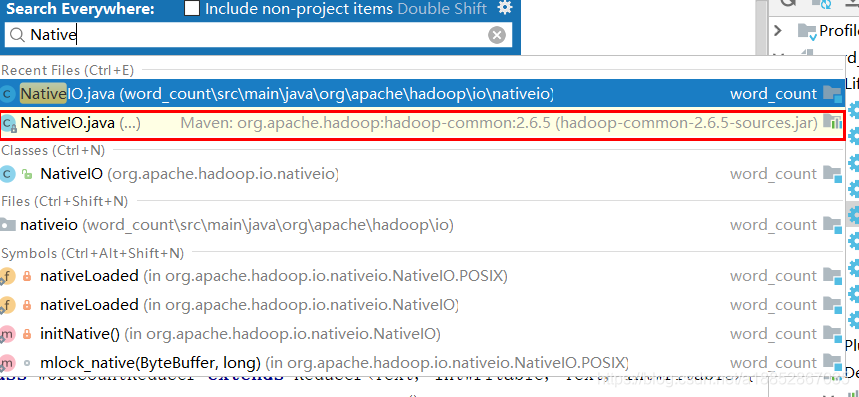
1)首先打开文件NativeIO
方法:按两次shift,搜索NativeIO文件,选中红色框区域内容,点击进去,复制其文件内容
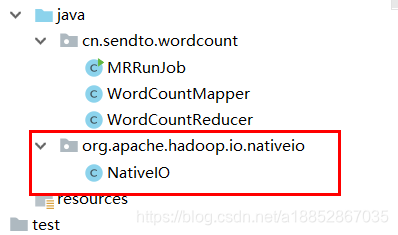
2)创建org.apache.hadoop.io.nativeio包,创建NativeIO类,用复制内容替换NativeIO中内容
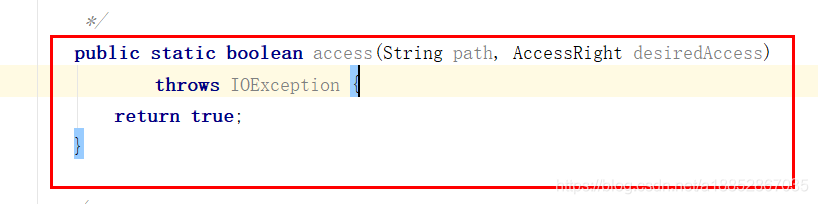
3)在NativeIO类中找到access0返回值所在的方法,将返回参数改成return true。如下图所示。
这样即可本地运行。
集群运行方式:
maven打包后,放到需要指定的服务器上,输入命令:
hadoop jar word_count-1.0-SNAPSHOT.jar cn.sendto.wordcount.MRRunJob
格式:hadoop jar xx.jar 主类名














 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









