









简述
最近发现一篇有趣的论文。关于限制性的kMeans. 主要思想是基于boosting principle的COP-kMeans。所以,我就先研究了下COP-kMeans。
COP-kMeans
是一种限制性聚类算法。限制性的含义很简单,就是需要考虑到有些节点在聚类前,我们就知道了这个两个节点是应该放在一起,还是应该分开。
所以,这里有两类。最简单的想法,就是这里用一个二维矩阵来存储这个信息。
COP-kMeans,从名字上看,就知道这是一个基于kMeans的算法。
Python实现
- 比较奇怪的点,这里我使用了一个函数内的函数定义。主要是考虑到了封闭性所以这样实现~
- 关于使用: 在策略上,我用了最简单的策略。而且还存在有病态初始化的可能。所以,可能会出现一只被报错的情况~ 不用担心,多进行几次测试就好了,或者,你也可以直接改我的代码~
- 代码实现上,基于我之前写过的k-Means. 只是加了一个验证的部分而已~
- 耗时上也比kMeans要高,毕竟每次都需要检查两个表~
补充说明
在评论区的小哥提示下,我做了con的补充。意外发现代码有些小问题。这里补充下。
- Con1和Con2是两个限制矩阵,大小规模为n*n,n为X的长度,即元素数量。
- Con1是要保证在一个组的限制,Con2是要保证不在一个组的限制
- 没有限制就为0,存在限制就非0.
def COP_K_means(X, n_clusters=3, Con1=None, Con2=None):
clusters = np.random.choice(len(X), n_clusters)
clusters = X[clusters]
labels = np.array([-1 for i in range(len(X))])
def validata_constrained(d, c, Con1, Con2):
for dm, value in enumerate(Con1[d]): # should in the same group
if value == 0:
continue
if labels[dm] == -1 or labels[dm] == c: # has not allocated or ...
continue
if labels[dm] != -1 and labels[dm] != c: # has allocated
return False
for dm, value in enumerate(Con2[d]): # cannot in the same group
if value == 0:
continue
if labels[dm] == -1 or labels[dm] != c: # has not allocated or ...
continue
if labels[dm] != -1 and labels[dm] == c: # has allocated
return False
return True
while True:
labels_new = np.array([-1 for i in range(len(X))])
for i, xi in enumerate(X):
close_list = np.argsort([np.linalg.norm(xi - cj) for cj in clusters])
unexpect = True
for index in close_list:
if validata_constrained(i,index, Con1, Con2):
unexpect = False
labels_new[i] = index
break
if unexpect:
raise Exception("Can not utilize COP-k-Means algorithm inside the dataset.")
if sum(labels != labels_new) == 0:
break
for j in range(n_clusters):
clusters[j] = np.mean(X[np.where(labels_new == j)], axis=0)
labels = labels_new.copy()
return labels
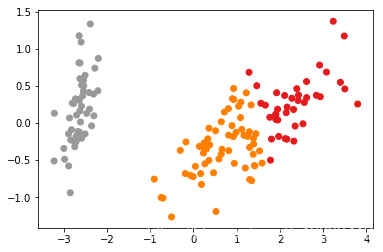
- 效果~ 可以跟之前的kMeans进行对比















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











