







博客核心内容:
1、进程中常用的一些方法
2、多进程解决Socket网络编程中的案例详解
3、进程之间的相互通信(IPC)
4、进程同步(加锁的机制)
| 1、进程中常用的一些方法 |
源代码:
class Process(object):
def __init__(self, group=None, target=None, name=None, args=(), kwargs={}):
self.name = ''
self.daemon = False
self.authkey = None
self.exitcode = None
self.ident = 0
self.pid = 0
self.sentinel = None
def run(self):
pass
def start(self):
pass
def terminate(self):
pass
def join(self, timeout=None):
pass
def is_alive(self):
return False ①p1.start()的含义:执行完p1.start()之后并不表示p1对象所对应的进程立即得到执行,p1.start()执行完之后只是表明了p1对象所对应的进程具有了可以被cpu执行的资格,但是具体哪个进程先执行,哪个进程后执行则是由操作系统进行控制的,Pycharm解释器不能够直接越过操作系统对硬件cpu进行控制,因此在实际开发过程中不能够依赖进程优先级来决定进程运行的次序,start()方法可以理解为向操作系统发起一个进程调度的申请。
②p1.join():主进程等待p1进程执行完毕之后才执行,注意:是主进程处于等待的状态,而子进程p1是处于运行的状态,join表示的是主进程处于等待状态,子进程在后台还处于运行的状态。
③self.daemon = False:默认情况下,创建的进程不是主进程的守护进程,如果self.daemon = True表示创建的子进程是主进程的守护进程。
守护进程的概念:进程分为前台运行的进程和后台运行的进程,其中守护进程属于后台运行的进程。
守护进程的效果:主进程运行完毕之后,守护进程也死掉了。
如何做到主进程运行完毕之后将我们开启的子进程都给回收掉:利用守护进程,将相应的子进程设置为守护进程,这样主进程运行完毕之后,相应的守护进程就会被回收掉。
设置的方法:在p1.start之前将p1.daemon = True,默认情况下daemon属性的数值为False.
④子进程是依赖于主进程的:正常情况下,只有各个子进程运行完毕之后,主进程才算执行完毕,即主进程会等待各个子进程的执行。
⑤在Windows当中,起进程的操作一定要放在main函数当中.
示例程序1:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
import random
def talk(name):
print('%s is talking'%name)
time.sleep(random.randint(1,3))
print('%s is talkend'%name)
if __name__ == '__main__':
p1 = Process(target=talk,args=('Alex',))
p2 = Process(target=talk, args=('egon',))
p3 = Process(target=talk, args=('lidong',))
p4 = Process(target=talk, args=('zhengheng',))
p_list = [p1,p2,p3,p4]
for p in p_list:
p.start()
#主进程只有在各个子进程执行完毕之后,才会向下执行.
for p in p_list:
p.join()运行结果:
Alex is talking
egon is talking
lidong is talking
zhengheng is talking
lidong is talkend
Alex is talkend
zhengheng is talkend
egon is talkend
主进程执行完毕!| 2、多进程解决Socket网络编程中的案例详解 |
服务端代码示例:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import socket
import os
from multiprocessing import Process
socket_server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
socket_server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
socket_server.bind(('127.0.0.1',8080))
socket_server.listen(5)
"""
多进程通信的思路:主进程负责建立连接
子进程负责:进行通信
在整个过程当中,并发的实际上是通信循环,即conn
"""
def talk(conn):
while True:
try:
cli_msg = conn.recv(1024).decode('utf-8')
if not cli_msg: break
print('客户端发送过来的消息是:%s' % cli_msg)
conn.send(cli_msg.upper().encode('utf-8'))
# 若客户端终止链接,则服务端也应该终止链接,但是不应该终止监听状态
except Exception as e:
print(e)
break
# 若客户端终止链接,则服务端也应该终止链接,但是不应该终止监听状态
conn.close()
if __name__ == '__main__':
while True:
#并发的肯定是链接循环
print('等待建立连接中.......')
conn,address = socket_server.accept()
print('客户端与服务端已经建立了连接.....')
print("客户端的地址是:\033[41;1m\033[0m", address)
"""
客户端与服务端建立连接后,双方开始进行通信
"""
#来一个任务,建立一个链接
p = Process(target=talk,args=(conn,))
p.start()
print('-'*20)
socket_server.close()客户端代码示例:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import socket
socket_client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#客户端向服务端发送链接请求
socket_client.connect(('127.0.0.1',8080))
"""
双方建立连接后开始进行通信
utf-8格式发送过去的,则以utf-8格式进行解析
"""
while True:
msg = input('>:').strip()
if not msg:continue
socket_client.send(msg.encode('utf-8'))
print('消息已经发送!')
server_msg = socket_client.recv(1024).decode('utf-8')
print('服务端发送过来的消息是:%s'%server_msg)
socket_client.close()运行效果展示:
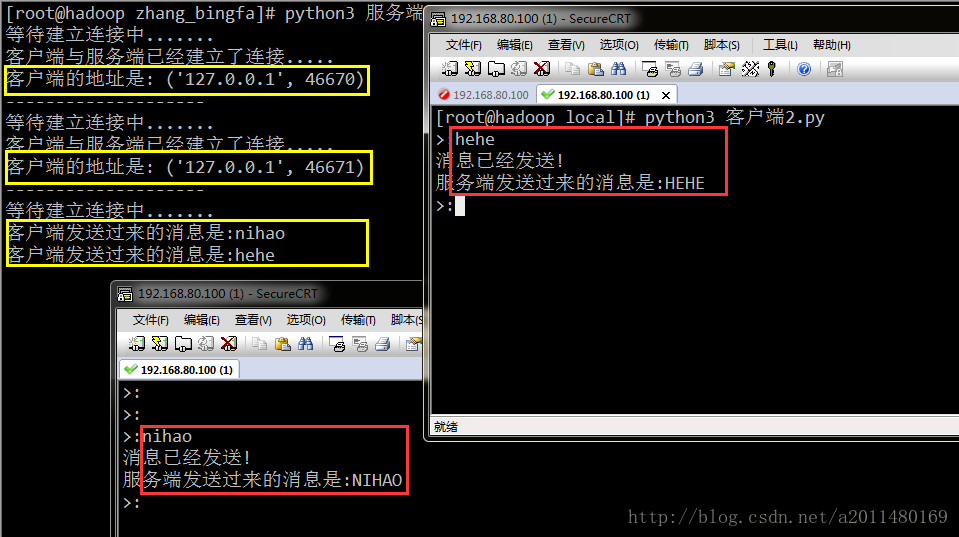
上面程序的问题:客户端的数量并没有得到有效的限制。
思考:在实际的工作当中,有几个cpu就应该开启几个进程,而不应该在我们的机器上面无限的开启多个进程,无限的启动多个进程实际上没有什么用,因为启动多个进程实际上是为了使用多核的优势,让任务的并行的进程处理,所有进程的数量应该得到合理的控制。
| 3、进程之间的相互通信(IPC) |
①进程与进程之间的关系:进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或者同一个打印终端,是没有问题的。
②进程之间数据隔离,但是共享同一套文件系统,因而可以通过文件来实现进程之间的相互的通信,但问题是必须自己加锁处理。
③进程彼此之间互相隔离,要实现进程间通信(IPC),multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的。
④创建队列的类Queue底层就是以管道和加锁的方式实现的。
⑤进程间通信的方式3,共享数据:
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的;
虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此;
进程间通信应该尽量避免使用本节所讲的共享数据的方式。
实例程序1:进程与进程之间可以共享同一套文件系统
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
程序1:多进程共享同一套文件系统
"""
from multiprocessing import Process
def talk(filename,msg):
with open(filename,'a',encoding='utf-8') as fr:
fr.write(msg)
if __name__ == '__main__':
for i in range(100):
p = Process(target=talk,args=('word.txt','进程%s\n'%str(i)))
p.start()运行效果展示:
进程0
进程2
进程3
进程4
进程1
进程6
进程5
进程7
进程8
进程10
进程11
进程9
进程12
进程13
进程14
进程15
进程16
进程18
进程17
进程19
进程20
进程22
进程21
进程24
进程23
进程26
进程28
进程27
进程25
进程30
进程29
进程31
进程32
进程33
进程34
进程35
进程36
进程37
进程38
进程39
进程40
进程41
进程42
进程43
进程44
进程46
进程48
进程47
进程45
进程49
进程50
进程52
进程51
进程55
进程56
进程54
进程53
进程59
进程58
进程57
进程60
进程61
进程63
进程62
进程64
进程65
进程66
进程67
进程69
进程68
进程70
进程71
进程72
进程74
进程73
进程76
进程75
进程78
进程79
进程80
进程77
进程81
进程83
进程82
进程84
进程85
进程86
进程87
进程88
进程90
进程89
进程91
进程92
进程94
进程96
进程93
进程95
进程98
进程97
进程99从打印效果上面我们可以看出,多个进程共享同一套文件系统,多个进程彼此之间并发执行(打印并没有具体的顺序)
实例程序2:程序之前,先介绍一下队列Queue的常用方法:
队列Queue常用的方法:
class Queue(object):
def __init__(self, maxsize=-1):
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递,maxsize是队列中允许最大项数,省略则无大小限制
def qsize(self):
查看队列中以存放的有效元素的个数
def empty(self):
判断一个队列是否已经满了或者是否为空
def full(self):
判断一个队列是否已经满了或者是否为空
def put(self, obj, block=True, timeout=None):
将数据插入到队列中,在默认情况下,如果队列中的元素已经满了,此时队列将处于阻塞状态.
def put_nowait(self, obj):
该效果等同于:def put(self, obj, block=False, timeout=None):即若队列中的元素已经满了,如果用户继续
插入数据,此时直接报错,有点类似于C语言中队列的效果。
def get(self, block=True, timeout=None):
q.get方法可以从队列读取并且删除一个元素,在默认情况下,如果队列中的元素已经空了,
此时队列将处于阻塞状态.
def get_nowait(self):
该效果等同于:def get(self, block=False, timeout=None):即若队列中的元素已经空了,如果用户继续
读取数据,此时直接报错,有点类似于C语言中队列的效果。示例程序21:put方法的使用
#!/usr/bin/python
# -*- coding:utf-8 -*-
from multiprocessing import Queue
if __name__ == '__main__':
q = Queue(3)
q.put('a')
q.put('b')
print('进程之间有效元素的个数是:%d'%q.qsize())
q.put('c')
q.put('d')
print('模拟队列中put方法的效果!')运行效果:

示例程序22:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from multiprocessing import Queue
if __name__ == '__main__':
q = Queue(3)
q.put('a')
q.put('b')
print('进程之间有效元素的个数是:%d'%q.qsize())
q.put('c')
try:
q.put('d',block=False)
except Exception:
print('队列中的元素已经满了,在放的话直接报错!')
print('模拟队列中put方法的效果!')运行结果:
进程之间有效元素的个数是:2
队列中的元素已经满了,在放的话直接报错!
模拟队列中put方法的效果!
Process finished with exit code 0示例程序4:程序之前,先来知识:
生产者消费者模型的作用:在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
什么是生产者和消费者模式:生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
基于队列实现生产者消费者模型:(重要)
41:
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
开启两个进程:一个进程负责生产,一个进程负责消费
模拟生产者消费者模型
"""
from multiprocessing import Queue,Process
import time
import random
def consumer(q,name):
while True:
time.sleep(random.randint(1,3))
res = q.get()
print('\033[41m消费者%s拿到了%s\033[0m'%(name,res))
def producer(q,name):
for i in range(10):
time.sleep(random.randint(1,3))
print('\033[42m生产者%s生产了%s\033[0m' % (name, i))
q.put(i)
if __name__ == '__main__':
q = Queue()
#整个程序当中一共开启了两个进程:主进程与子进程
p1 = Process(target=consumer,args=(q,'alex'))
p1.start()
#在这里面主进程作为生产者
producer(q,'egon')
print('生产者执行完毕!')运行结果:
生产者egon生产了0
消费者alex拿到了0
生产者egon生产了1
消费者alex拿到了1
生产者egon生产了2
消费者alex拿到了2
生产者egon生产了3
生产者egon生产了4
消费者alex拿到了3
生产者egon生产了5
消费者alex拿到了4
生产者egon生产了6
消费者alex拿到了5
生产者egon生产了7
生产者egon生产了8
消费者alex拿到了6
生产者egon生产了9
生产者执行完毕!
消费者alex拿到了7
消费者alex拿到了8
消费者alex拿到了9从上面的结果中我们可以看出,生产者和消费者并发执行。
42:基于上一个程序的更改(一个主进程,两个子进程)
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
本程序中一个主进程,2个子进程
"""
from multiprocessing import Queue,Process
import time
import random
def consumer(q,name):
while True:
time.sleep(random.randint(1,3))
res = q.get()
print('\033[41m消费者%s拿到了%s\033[0m'%(name,res))
def producer(q,name):
for i in range(10):
time.sleep(random.randint(1,3))
print('\033[42m生产者%s生产了%s\033[0m' % (name, i))
q.put(i)
if __name__ == '__main__':
q = Queue()
#在整个过程当中,3个进程同时执行
p1 = Process(target=consumer,args=(q,'alex'))
p1.start()
p2 = Process(target=producer,args=(q,'egon'))
p2.start()
print('主进程执行完毕!')43:解决消费者进程卡住的方法1:(通过发送一个标志信号来解决)
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
本程序中一个主进程,2个子进程
"""
from multiprocessing import Queue,Process
import time
import random
def consumer(q,name):
while True:
time.sleep(random.randint(1,3))
res = q.get()
#一旦消费者获得了信号,则子进程执行完毕
if res is None:
print('消费者消费完包子了!')
break
print('\033[41m消费者%s拿到了%s\033[0m'%(name,res))
def producer(q,name):
for i in range(10):
time.sleep(random.randint(1,3))
print('\033[42m生产者%s生产了%s\033[0m' % (name, i))
q.put(i)
q.put(None)
if __name__ == '__main__':
q = Queue()
#在整个过程当中,3个进程同时执行
p1 = Process(target=consumer,args=(q,'alex'))
p1.start()
p2 = Process(target=producer,args=(q,'egon'))
p2.start()
print('主进程执行完毕!')在上面的程序当中:生产者发送了一个None信号,一旦消费者获取到了这个None信号,则直接结束,从而避免了阻塞的问题。
44:通过join的设置,主进程等待完两个子进程执行完毕之后,才向下继续执行。
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
本程序中一个主进程,2个子进程
"""
from multiprocessing import Queue,Process
import time
import random
def consumer(q,name):
while True:
time.sleep(random.randint(1,3))
res = q.get()
#一旦消费者获得了信号,则子进程执行完毕
if res is None:
print('消费者消费完包子了!')
break
print('\033[41m消费者%s拿到了%s\033[0m'%(name,res))
def producer(q,name):
for i in range(10):
time.sleep(random.randint(1,3))
print('\033[42m生产者%s生产了%s\033[0m' % (name, i))
q.put(i)
q.put(None)
if __name__ == '__main__':
q = Queue()
#在整个过程当中,3个进程同时执行
p1 = Process(target=consumer,args=(q,'alex'))
p1.start()
p2 = Process(target=producer,args=(q,'egon'))
p2.start()
#p1和p2写的时候和顺序无关
p1.join()
p2.join()
print('主进程执行完毕!')运行结果:
生产者egon生产了0
消费者alex拿到了0
生产者egon生产了1
生产者egon生产了2
消费者alex拿到了1
消费者alex拿到了2
生产者egon生产了3
消费者alex拿到了3
生产者egon生产了4
生产者egon生产了5
消费者alex拿到了4
生产者egon生产了6
生产者egon生产了7
消费者alex拿到了5
生产者egon生产了8
消费者alex拿到了6
生产者egon生产了9
消费者alex拿到了7
消费者alex拿到了8
消费者alex拿到了9
消费者消费完包子了!
主进程执行完毕!创建队列的另外一个类:JoinableQueue:JoinableQueue([maxsize]):这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
class JoinableQueue(multiprocessing.Queue):
def task_done(self):
使用者使用此方法发出信号,表示q.get()
的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
def join(self):
生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止45:功能需求:生产者确认消费者已经将自己的数据给拿走了,并且已经正确处理了.
代码示例:
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
功能需求:生产者确认消费者已经将自己的数据给拿走了,并且已经正确处理了.
注意:此时Queue提供的功能不能够实现,需要使用JoinableQueue
两者的关系:父与子
进程.join的含义:等待进程执行完毕
同时这也是解决消费者进程等待的另外一种方案:利用守护进程
"""
from multiprocessing import Queue,JoinableQueue,Process
import time
import random
def consumer(q,name):
while True:
time.sleep(random.randint(1,3))
res = q.get()
#一旦消费者获得了信号,则子进程执行完毕
print('\033[41m消费者%s拿到了%s\033[0m'%(name,res))
#从队列中取一个,喊一声
q.task_done()
def producer(q,name):
for i in range(10):
time.sleep(random.randint(1,3))
print('\033[42m生产者%s生产了%s\033[0m' % (name, i))
q.put(i)
#q.join()的含义:等待队列结束(错误:里面的元素取空了,而是task_done完毕,喊够指定次数的声音)
q.join() #一旦缩进,就变成了生产一个消费一个
print('消费者已经将全部的包子吃完了!')
if __name__ == '__main__':
q = JoinableQueue()
#在整个过程当中,3个进程同时执行
p1 = Process(target=consumer,args=(q,'alex'))
p1.daemon = True
p1.start()
p2 = Process(target=producer,args=(q,'egon'))
p2.start()
#p1和p2写的时候和顺序无关
p2.join()
#生产者执行完的话,消费者肯定已经执行完毕!
print('主进程执行完毕!')
#消费者进程====>生产者进程====>主进程,所有主进程执行完毕之后,消费者进程肯定已经执行完毕!因此自然可以杀死!
#主进程等待p进程结束,而p进程等待c进程将数据都取完,c进程一旦取完数据,p.join就是不在阻塞的了,进而主进程结束,
#主进程结束会回收守护进程c,而c进程此时已经没有存在的必要了.
#大家同时向队列中放数据,但是谁先放,不用考虑这个问题,因为队列内部就是=管道+锁的机制,保证了多个进程放数据的时候
#不会乱,多个进程取数据的时候也不会乱运行结果:
生产者egon生产了0
消费者alex拿到了0
生产者egon生产了1
生产者egon生产了2
消费者alex拿到了1
消费者alex拿到了2
生产者egon生产了3
消费者alex拿到了3
生产者egon生产了4
生产者egon生产了5
消费者alex拿到了4
生产者egon生产了6
生产者egon生产了7
消费者alex拿到了5
生产者egon生产了8
消费者alex拿到了6
生产者egon生产了9
消费者alex拿到了7
消费者alex拿到了8
消费者alex拿到了9
消费者消费完包子了!
主进程执行完毕!
Process finished with exit code 0示例程序:进程之间通信的方式3:共享数据
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
进程间通过Manager实现数据的共享:进程间相互通信的第三种方式
"""
from multiprocessing import Manager,Process
import os
def work(d,l):
print('当前执行的进程是:\033[41m%s\033[0m'%os.getpid())
l.append(os.getpid())
d[os.getpid()] = os.getpid()
if __name__ == '__main__':
m = Manager()
#创建一个进程之间可以共享的列表
l = m.list(['init'])
#创建一个进程之间可以共享的字典
d = m.dict({'name':'egon'})
p_list = []
for i in range(5):
p = Process(target=work,args=(d,l))
#每建立一个进程对象先放到列表当中去
p_list.append(p)
p.start()
for p in p_list:
p.join()
#在打印之前必须要join,不然根本就看不出xi效果
print(l)
print(d)
运行结果:
当前执行的进程是:5528
当前执行的进程是:7324
当前执行的进程是:10812
当前执行的进程是:6480
当前执行的进程是:10808
['init', 5528, 7324, 10812, 6480, 10808]
{6480: 6480, 10808: 10808, 'name': 'egon', 5528: 5528, 7324: 7324, 10812: 10812}| 4、进程同步(加锁的机制) |
①什么是进程同步?
所谓进程同步就是当多个进程在处理相同资源的时候,保证共享数据的数据一致性和变化一致性
②进程同步问题的由来?
导致进程同步的原因共有两个:
⑴多个进程彼此之间处理的是相同的资源(比如3个窗口共同售出1000张票)
⑵多个进程彼此之间在处理相同关键步骤的时候,在这些关键的步骤没有执行完毕的时候,CPU会切换到另外一个进程去执行这些关键的步骤,导致共享数据的一致性出现问题
③在Python当中,如何解决进程同步的问题?
在Python当中是通过Lock语法机制来解决进程同步的问题的,通过Lock()语法机制,保证这些关键的步骤在被某一个进程访问或者执行的时候,其余进程不能在执行这些关键的步骤(尽管CPU仍在多个线程之间来回切换),直到这个进程将这些关键的步骤执行完毕,其余进程才能执行这些关键的步骤;
Python当中的Lock()语法机制类似于数据库中的事务性处理机制,类似于Java当中的synchronized语法机制语法机制。
示例程序1:共享数据的问题:共享数据的一致性和数据的同步性出现了问题
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
通过加锁的机制,可以保证多个进程共享数据之间数据的一致性
场景:抢票的场景
json不能识别单引号
"""
from multiprocessing import Process
import time
import random
import json
def work(dbfile,name):
with open(dbfile,encoding='utf-8') as fr:
dic = json.loads(fr.read())
print('该用户读取到的数据是:%s'%dic)
if dic['count'] > 0:
dic['count'] -= 1
#模拟网络延迟
time.sleep(random.randint(1,3))
with open(dbfile,'w',encoding='utf-8') as fw:
fw.write(json.dumps(dic))
#fw.write(dic.__str__)
print('\033[41m;%s抢票成功!\033[0m'%name)
else:
print('\033[45m;%s抢票失败!\033[0m'%name)
if __name__ == '__main__':
p_l = []
for i in range(100):
p = Process(target=work,args=('word.txt','进程%s'%i))
p_l.append(p)
p.start()
for p in p_l:
p.join()
print('执行完毕!')运行结果:
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
该用户读取到的数据是:{'count': 1}
;进程0抢票成功!
该用户读取到的数据是:{'count': 0}
;进程13抢票失败!
;进程1抢票成功!
;进程3抢票成功!
该用户读取到的数据是:{'count': 0}
;进程14抢票失败!
;进程4抢票成功!
该用户读取到的数据是:{'count': 0}
;进程15抢票失败!
该用户读取到的数据是:{'count': 0}
;进程16抢票失败!
该用户读取到的数据是:{'count': 0}
.............从上面的运行结果我们会发现,共享数据的一致性出现了问题。
示例程序2:加锁机制
def work(dbfile,name,lock):
with lock:
#lock.acquire()
同步代码块
#lock.release()代码示例:
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
通过加锁的机制,可以保证多个进程共享数据之间数据的一致性
场景:抢票的场景
json不能识别单引号
"""
from multiprocessing import Process,Lock
import time
import random
import json
"""
注意:大家用的是同一把锁,谁先抢到锁,就归谁
"""
def work(dbfile,name,lock):
#哪个用户先到则先加锁,只要不释放,别的用户就执行不了
lock.acquire()
with open(dbfile,encoding='utf-8') as fr:
dic = json.loads(fr.read())
print('该用户读取到的数据是:%s'%dic)
if dic['count'] > 0:
dic['count'] -= 1
#模拟网络延迟
time.sleep(random.randint(1,3))
with open(dbfile,'w',encoding='utf-8') as fw:
fw.write(json.dumps(dic))
#fw.write(dic.__str__)
print('\033[41m%s抢票成功!\033[0m'%name)
else:
print('\033[45m%s抢票失败!\033[0m'%name)
lock.release()
if __name__ == '__main__':
#注意:多个进程之间必须用的是同一把锁
lock = Lock()
p_l = []
for i in range(100):
p = Process(target=work,args=('word.txt','进程%s'%i,lock))
p_l.append(p)
p.start()
for p in p_l:
p.join()
print('执行完毕!')
运行结果:
该用户读取到的数据是:{'count': 1}
进程0抢票成功!
该用户读取到的数据是:{'count': 0}
进程1抢票失败!
该用户读取到的数据是:{'count': 0}
进程2抢票失败!
该用户读取到的数据是:{'count': 0}
进程3抢票失败!
该用户读取到的数据是:{'count': 0}
.............从上面我们可以看出,通过加锁机制,在一定程度上解决了数据同步的问题,当然我们也可以通过上下文lock的方式进行加锁。
我们将Java和Python解决数据同步的代码对比一下,其实都是一样的:
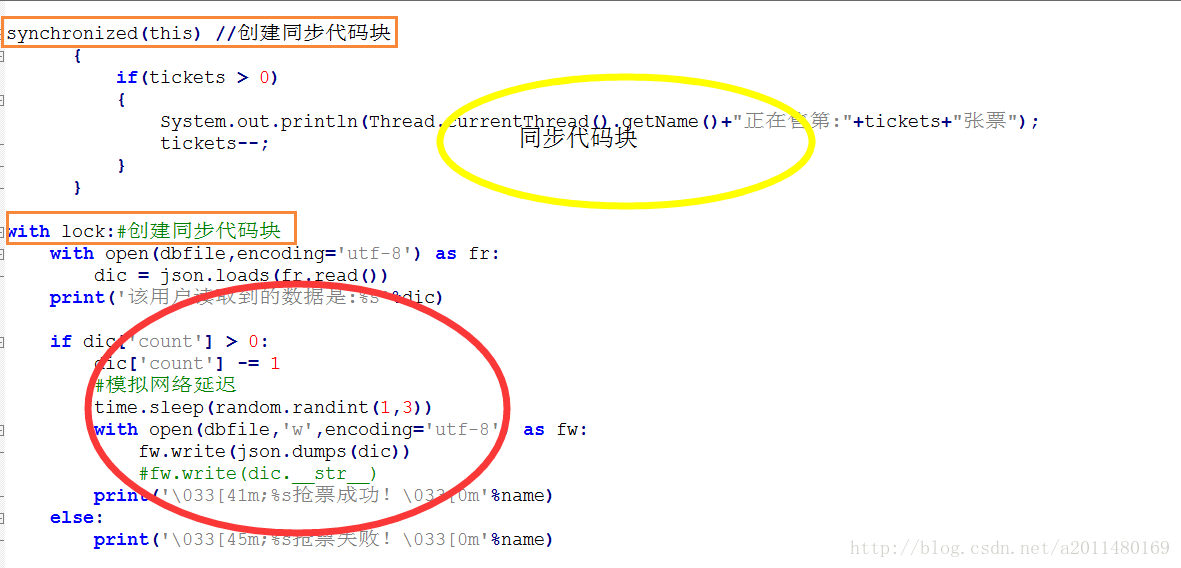















 2983
2983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











