







Map-Reduce模型回顾:
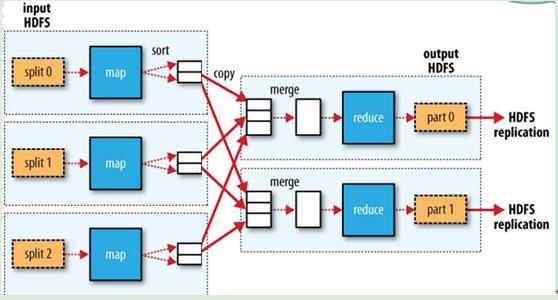
Hdfs文件读写、lucene索引读写特点:
Hdfs是hadoop的分布式文件存储系统。Hdfs为提高集群存储的效率,目前只支持顺序写,不支持随机写,即:只能从文件末尾追加写入,不支持随机修改文件内容。但lucene默认创建索引过程中,必然会有大量的合并、删除、更新操作,要求文件系统支持随机写。如果利用lucene的一些特性,采用顺序写的方式创建、更新索引文件,必然导致lucene搜索时做较多处理,影响搜索性能。因此,为保证lucene搜索的效率,需要一个支持随机写的文件系统创建索引,但Hdfs显然不符合要求。这里我们采用“迂回战术”:先在本地磁盘创建索引文件,然后再上传到Hdfs。
下面设计一种最简单的Map-reduce编程模型,来创建lucene索引。已知有10亿行日志文件作为输入,要求输出32个索引文件。
实现步骤:
1.指定作业的reduce个数为32。
2.map进程对输入文件进行简单处理,例如检测输入格式、对key进行计算等等,然后输出。
3.指定分区函数,对记录进行分区,即根据各自项目的需求,按照一定的规则使这些记录分发到32个reduce进程去。没有特殊需要,也可直接按hash取模的方式进行分发。
4.每个reduce接收一定数量的数据,基于本地磁盘创建lucene索引。即:每个reduce进程创建一个lucene的writer,不断执行writer.addDocument()操作添加文档,这个过程中会触发一些commit()操作,对应生成很多个segment(索引片段)。在关闭索引之前,调用lucene的forceMerge()方法把索引合成一整块,以提高搜索效率。然后把索引文件上传到hdfs,结束reduce进程。
以上思路实现起来比较容易,也便于理解。如果要求的索引块数有改变,只需更改reduce的数量即可。且用hadoop来进行分布式计算,管理起来比较方便,hadoop自己有很好的重试机制、错误处理机制,可以保证程序运行的稳定性。
仔细分析,不难发现该程序的本质:创建索引的工作几乎全落在reduce端,相当于把日志分成了32份,启动32个进程各自创建一块索引文件。相信不用hadoop,简单的写个程序,开启32个实例,每个实例对1/32的数据建索引也可实现。
看到这个本质,自然也就看到了该思路的缺陷:reduce是该程序的瓶颈。程序运行时间主要受输入数据大小、reduce个数的影响,也受制于reduce所在机器的磁盘读写速度,和集群规模大小没多大关系。几乎没有办法通过调整集群配置来改变程序的运行时间,创建索引过程也没有多大可优化空间,完全依赖于lucene在磁盘上创建索引、合并索引的速度。
在实践中,该模型带来了很多问题,最明显的是:当输入数据量足够大时,创建索引过程会相当慢,且数据量和索引速度不是一个线性关系,索引创建速度难以满足需求。其原因主要是lucene基于磁盘创建索引、合并索引过程的开销比较大。Lucene合并segment时,通常会生成大量的临时文件,磁盘消耗膨胀约2倍甚至更多。此外,如果多个reduce进程在同一块磁盘上进行索引创建、合并操作,必然会导致热点问题,激烈的IO读写竞争会使本来就不快的程序雪上加霜,甚至失败。
如何更快的对大量数据建索引呢?为发挥hadoop并行计算的优势,规避基于磁盘创建、合并索引速度慢的问题,我们探索实践了另一种方案,敬请关注下篇。















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









