






先说机器配置:
CPU:Intel Xeon E3-1230 v5 skylake平台(此CPU无核显)
主板:ASUS E3 Pro Gaming v5
RAM:8G
GPU:ASUS STRIX-GTX1070 O8GB
存储:1个128G SSD + 1个 1T 机械硬盘 都是GPT分区
为什么先说机器配置呢?因为在安装Ubuntu过程中这个相当重要,在网上找到的教程中,大多数是在笔记本电脑或者比较旧的电脑上安装。如果你的机器是这一两年内的新配置(一般都是UEFI+GPT),本教程应该会相对实用。不过,还是要先了解自己的机器是传统的BIOS+MBR还是新的UEFI+GPT,相关内容可以看这里(关键是看看BIOS和UEFI长什么样子)。而自己机器分区表是MBR还是GPT,在Win10下也可通过Win+X进入“磁盘管理”查看。我的机器是UEFI+GPT的,环境搭建也是以此为基础。
1 Ubuntu安装
1.1 Win10下的磁盘分区
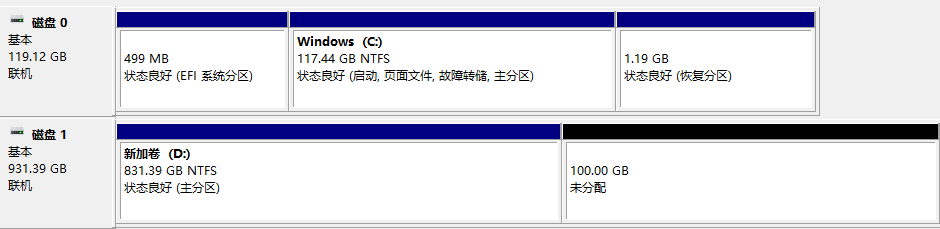
1.2 Win10下的设置
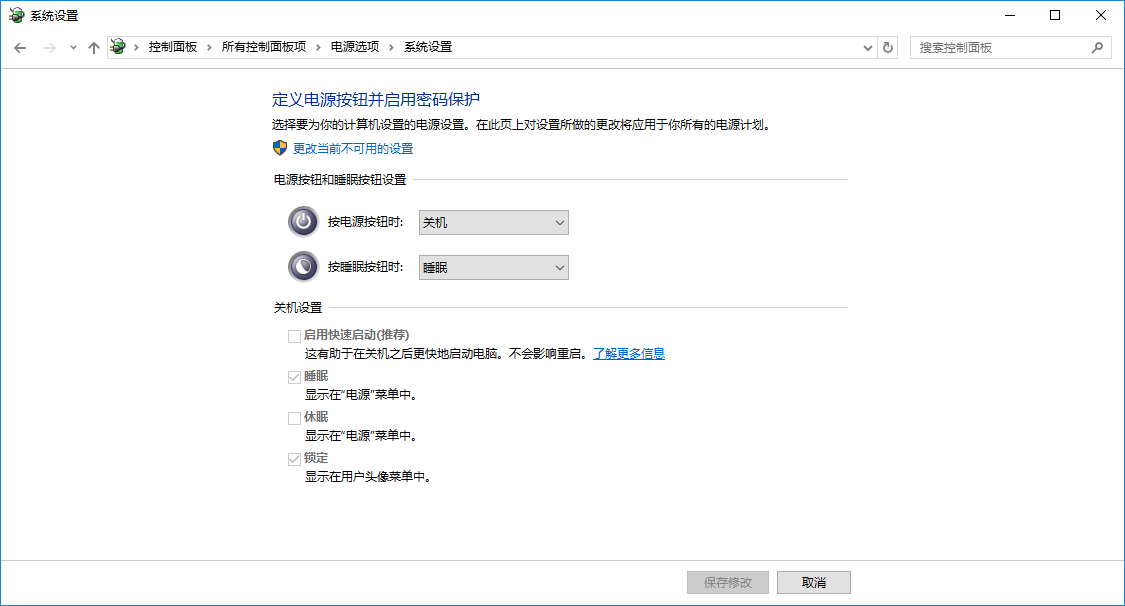
这里主要是要禁用快速启动,因为快速启动会阻碍Ubuntu系统的挂载。
Win+X进入电源选项->选择电源按钮的功能->更改当前不可用的设置->将“启用快速启动”的选项去掉->保存修改。
1.3 UEFI下的设置
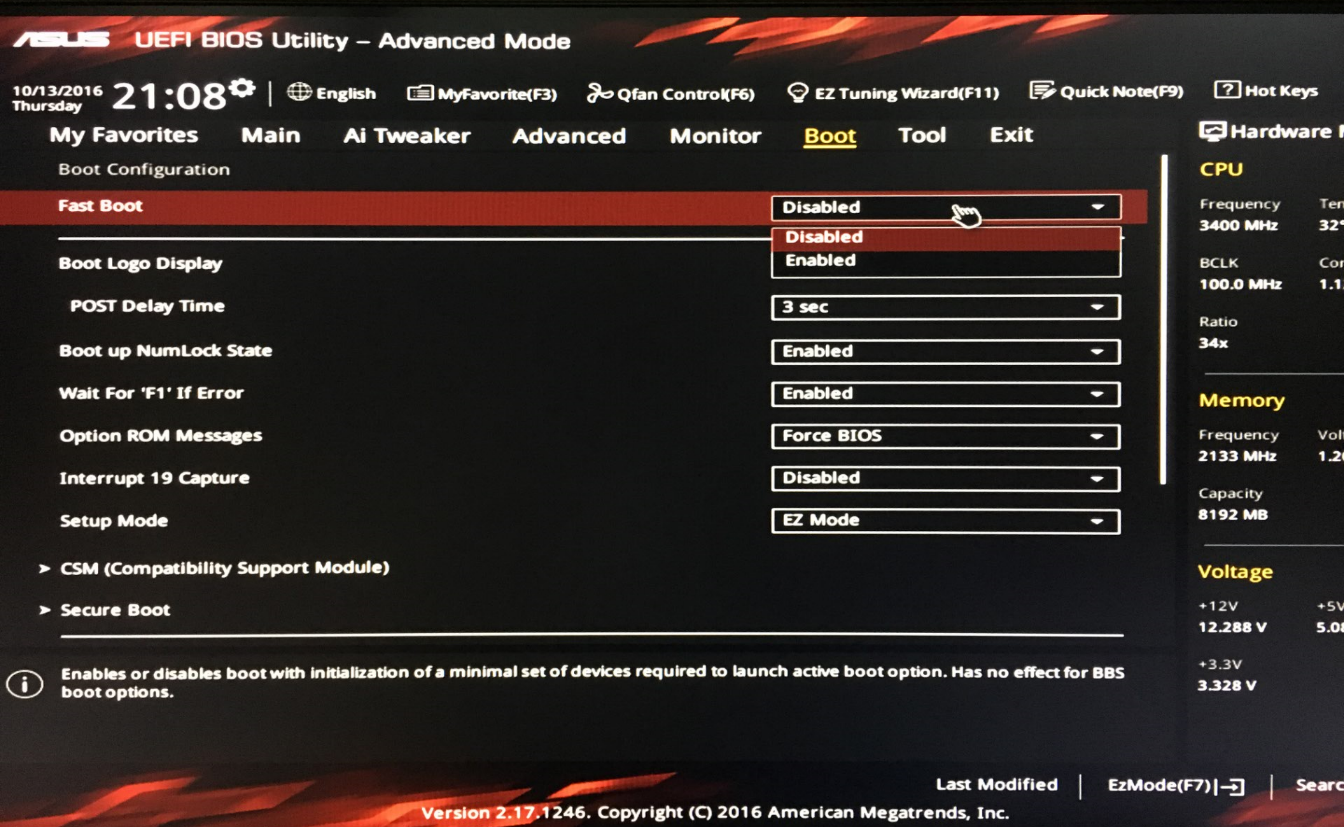
1.3.1 UEFI禁用Fast Boot
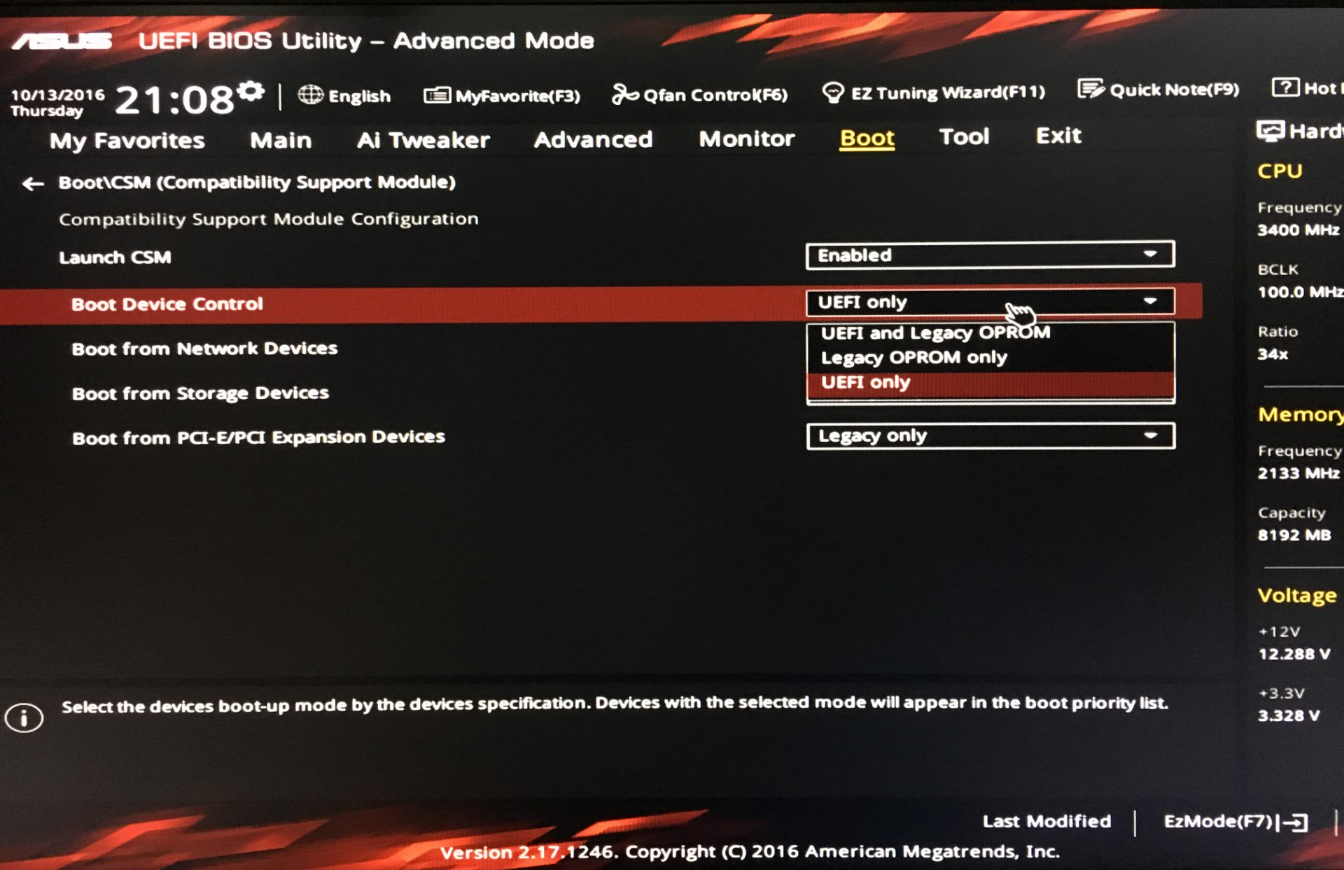
1.3.2 UEFI更改CSM(重中之重)
在Fast Boot下面,可以看到CSM(Compatibility Support Module),这是主板可以兼容传统BIOS和新UEFI引导的模块,点入去将Boot Device Control 更改为UEFI only。
这里Legacy OPROM就是传统BIOS引导,有人可能会问,为什么不保留初始的UEFI and Legacy OPROM,就可以兼容两种模式了?经过我的试验,即多次安装Ubuntu过程中,发现使用纯UEFI引导的安装更容易成功,特别在Ubuntu系统内的分区中(后面会提到)会更妥当。
1.3.3 UEFI禁用Secure Boot(自行选择)
CSM下方的Secure Boot,点进去会看到Secure Boot的选项是灰色无法更改的。关于Secure Boot的问题,可以参考这里和这里。
但是当我将各种Key备份好,准备Delete Platform Key (PK)时,我发现这样会导致Win10系统重置,所以我并未执行此步,在后面步骤也正常,读者可自行选择是否执行此步。

1.4 制作Ubuntu的U盘启动盘
从官网下载好ubuntu-14.04.5-desktop-amd64.iso后,利用Rufus刻录。注意,一定要在“分区方案和目标系统类型”中选择->“用于UEFI计算机的GPT分区方案”。
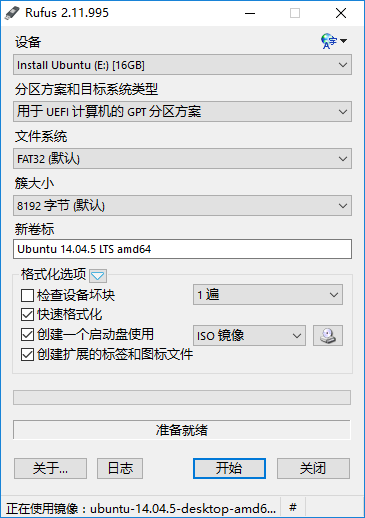
1.5 开始安装
重启,华硕主板按Delete或者F2进入UEFI界面,选择带UEFI字样的U盘启动。进入GNU GRUB后,选择Install Ubuntu。
后面的安装有图形界面引导,需要说明的是安装方式及分区。由于要安装双系统,在安装方式里一定要选择“其它选项(Something else)”。
进入分区后,根据刚才在Win10下划分的未分配100GB,可以在当前安装界面中的分区表找到一个107876MB左右的空闲区域,选中,点击左侧“+”进行分区,共分三个区如下:
1. 300MB->逻辑分区->空间起始位置->EFI引导分区(EFI boot partition) ;
2. 8192MB->主分区->空间起始位置->交换空间(swap area);
3. 剩余所有空间->主分区->空间起始位置->Ext4日志文件系统(Ext4 journaling file system)->挂载点为“/”。
分区完成后,下面要选择“安装启动引导器的设备”,这里选择分区表中EFI引导分区(300MB)所在的设备,这个设备是分区表中的第一列,你可以在那里看到刚刚分的各个区所在的“设备”(实际上都在同一个硬盘上,但由于虚拟磁盘管理,不同的分区在不同“设备”上)。我的EFI引导分区在“dev/sdb3”上,那么“安装启动引导器的设备”就相应选择“dev/sdb3”。分区过程图可以看这里。
注意:
1. 交换空间的大小是根据机器本身的内存RAM大小决定的,可以根据实际情况分配。
2. “安装启动引导器的设备”这里的“dev/”后面接的无论是“sda”还是“sdb”,选择EFI引导分区对应的设备即可。顺带解释一下“dev/sda”、“dev/sdb”的问题,这是在有两块不同的物理硬盘才会显示,如果只有一块硬盘的话,当然只能看见“dev/sda”了。
接下来的地区选择、键盘布局、用户名及密码相对常规,可以自行设置。
1.6 安装过程中可能出现的情况
这里可能出现的情况可以看我在这里的描述。最初在UEFI的CSM中一直选择UEFI and Legacy OPROM的兼容模式,经常在分区的安装步骤前后,不是无法扫描分区表(进入分区表时一片空白)导致无法分区,就是分区完成后安装程序突然崩溃。最后选择UEFI only后,安装才正常进行。
回顾一下。
这里有个印象十分深刻,就是当时也尝试过Legacy OPROM only的模式进行安装,在分区选项中是没有EFI引导分区这一选项的,只有“保留的 BIOS 启动区域”选项(在UEFI only的模式下EFI引导分区和保留的 BIOS 启动区域都有),分区完成后也正常,但在最后安装复制文件时报错,原因应该BIOS安装往磁盘写文件时默认磁盘分区表是MBR,而我的磁盘分区表是GPT,会导致读写出现问题。
另外,在UEFI and Legacy OPROM的兼容模式下安装,假如分区步骤未给“保留的 BIOS 启动区域”分配空间,安装程序提醒你要给“保留的 BIOS 启动区域”分配至少1MB,实际上这是不需要的,采用UEFI引导的安装,给EFI引导分区分配空间就足够了。
所以,再次要提醒,在UEFI的CSM中一定要选择UEFI only,避免兼容问题。
One more thing. 有时安装在分区完成后,安装程序也可能崩溃,这时你先重启退出安装回到Win10下的磁盘管理,可以看到分区的确是完成了,你可以选择将这些分区右键->删除卷,使其变回未分配状态。但是,EFI系统分区是无法以此方式删除的,可以选择DiskGenius进行。然后尝试安装Ubuntu。
2 显卡驱动安装
安装完成后,重启进入Ubuntu系统,Ctrl+Alt+T打开终端。执行顺序如下:
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
sudo apt-get install nvidia-367
sudo apt-get install mesa-common-dev
sudo apt-get install freeglut3-dev
sudo reboot显卡驱动安装完成重启进入Ubuntu系统,屏幕分辨率应该显示正常。
3 CUDA&cuDNN安装
3.1 CUDA

下载完成后,打开终端,先进入CUDA安装程序所在的目录(cd命令可以跳转目录),然后执行:
sudo sh cuda_8.0.44_linux.run首先会出现安装协议,按Space向下翻,输入accpet接受协议,需要注意的是:
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 367.**?
(y)es/(n)o/(q)uit: n这里一定要选择no,否则会导致之前的显卡驱动被覆盖。
安装完成后注意看提示,有问题可以参考这里。(我没遇到)
在终端配置环境变量:
nano ~/.bashrc
在最后增加以下两行:
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}Ctrl+X 保存并离开,回到终端,让环境变量马上生效:
source ~/.bashrc3.2 cuDNN
先到官网下载cuDNN v5.1,需要先注册并做问卷调查,下载中选择cuDNN v5.1 Library for Linux。

下载完成后,打开终端,先进入cuDNN文件所在的目录(cd命令可以跳转目录),然后执行:
tar xvf cudnn-8.0-linux-x64-v5.1.tgz
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*终端回到根目录,输入命令检查显卡配置是否正常:
nvidia-smi
4 Tensorflow源码安装
4.1 Bazel安装配置
由于Tensorflow采取源码安装的方式,所以需要Bazel进行编译,官方教程可以看这里。执行顺序如下:
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer
echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list
curl https://bazel.io/bazel-release.pub.gpg | sudo apt-key add -sudo apt-get update && sudo apt-get install bazel在“curl https://bazel.io/bazel-release.pub.gpg | sudo apt-key add -”步骤中,可能会由于网络原因下载较慢,可以直接用浏览器打开“https://bazel.io/bazel-release.pub.gpg”进行下载,随后进入该文件目录执行“sudo apt-key add bazel-release.pub.gpg”。
4.2 Tensorflow源码配置及编译
在python2.7下,先要安装环境依赖包:
sudo apt-get install python-numpy swig python-dev python-wheel python-pip git从github上克隆Tensorflow源码到本地:
git clone https://github.com/tensorflow/tensorflow切换到最新的r0.11版本(需要先进入保存Tensorflow源码的目录):
git checkout r0.11开始配置(同样需要先进入保存Tensorflow源码的目录):
./configure
Please specify the location of python. [Default is /usr/bin/python]:
Do you wish to build TensorFlow with Google Cloud Platform support? [y/N] N
No Google Cloud Platform support will be enabled for TensorFlow
Do you wish to build TensorFlow with Hadoop File System support? [y/N] N
No Hadoop File System support will be enabled for TensorFlow
Found possible Python library paths:
/usr/local/lib/python2.7/dist-packages
/usr/lib/python2.7/dist-packages
Please input the desired Python library path to use. Default is [/usr/local/lib/python2.7/dist-packages]
/usr/local/lib/python2.7/dist-packages
Do you wish to build TensorFlow with GPU support? [y/N] y
GPU support will be enabled for TensorFlow
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]:
Please specify the Cuda SDK version you want to use, e.g. 7.0. [Leave empty to use system default]: 8.0
Please specify the location where CUDA 8.0 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify the Cudnn version you want to use. [Leave empty to use system default]: 5
Please specify the location where cuDNN 5 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify a list of comma-separated Cuda compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size.
[Default is: "3.5,5.2"]: 6.1注意:最后的“6.1”计算能力是根据自身显卡决定的,可以到这里查看。
开始配置后,首先会自动下载一些环境依赖的包,然后开始配置。
另外,在配置这个步骤,很多教程都说“一定要显示成功,不能出现error”。我的机器在Tensorflow配置时一些环境依赖的包无法下载,导致后面Bazel编译出现问题,所以我决定使用别人编译好的whl安装Tensorflow。这里有人可能会有疑惑,解释一下这个Bazel编译Tensorflow源码的意义,编译源码成功后,是会生成一个“tensorflow-0.11.0rc0-py2-none-any.whl”的文件,然后通过“sudo pip install tensorflow-0.11.0rc0-py2-none-any.whl”安装才算完成。
这里有人可能又会问,为什么要这么麻烦编译源码生成一个whl去安装呢?的确,在Tensorflow官方安装教程里的Pip Installation方式,下载支持GPU的whl然后通过pip安装就行了,步骤如下:
# Ubuntu/Linux 64-bit
sudo apt-get install python-pip python-dev# Ubuntu/Linux 64-bit, GPU enabled, Python 2.7
# <strong>Requires CUDA toolkit 7.5 and CuDNN v5. For other versions, see "Install from sources" below.</strong>
export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.11.0rc0-cp27-none-linux_x86_64.whl# Python 2
sudo pip install --upgrade $TF_BINARY_URL可以看到,官方解释说,这个whl支持的CUDA是7.5版本,而当前CUDA最新版本是8.0才支持10系GPU(也有说法CUDA 7.5也可以支持10系GPU不过需要调整,这个大家自行搜索),因此,通过Bazel编译Tensorflow源码生成的whl才可以在安装后支持10系GPU。
那么回过头来,别人编译好的whl安装Tensorflow,在哪里可以找到呢?可以看这里。在这里要感谢这位博主的分享!
如果你配置成功选择自行编译并安装,可以接下去看4.3;如果想选择利用别人编译好的whl安装Tensorflow,可以跳过4.3从4.4开始。
4.3 编译Tensorflow源码并安装
Tensorflow配置完成后,开始编译源码并安装(注意文件的保存目录):
bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_packagebazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkgsudo pip install /tmp/tensorflow_pkg/tensorflow-0.11.0rc0-py2-none-any.whl至此,整个Tensorflow环境搭建就已经完成,可以跑一下Tensorflow官方的测试代码。
4.4 使用编译好的whl安装Tensorflow
下载whl好后,因为该whl的编译是在Ubuntu16.04下进行,所以先要将Ubuntu系统升级,这里升级是必须的,如果直接安装该whl,会报关于“GLib”的错误,这是由于编译环境造成的。Ubuntu14.04系统升级至Ubuntu16.04命令如下:
sudo update-manager -d一般来说,该命令需要执行两次,因为第一次执行,系统会更新当前14.04版本内的软件,然后重启后仍然是14.04版本,这时再次执行该命令,就会进行Ubuntu16.04升级。
系统升级完成后,终端执行安装(先进入该whl的保存目录):
sudo pip install tensorflow-0.11.0rc0-py2-none-any.whl至此,整个Tensorflow环境搭建就已经完成,可以跑一下Tensorflow官方的测试代码。
4.5 在Pycharm中使用Tensorflow
由于个人习惯在Pycharm中写Python代码,下面说说Tensorflow在Pycharm的配置,终端执行:
sudo cp /usr/local/cuda-8.0/lib64/libcudart.so.8.0 /usr/local/lib/libcudart.so.8.0 && sudo ldconfig
sudo cp /usr/local/cuda-8.0/lib64/libcublas.so.8.0 /usr/local/lib/libcublas.so.8.0 && sudo ldconfig
sudo cp /usr/local/cuda-8.0/lib64/libcurand.so.8.0 /usr/local/lib/libcurand.so.8.0 && sudo ldconfig
sudo cp /usr/local/cuda-8.0/lib64/libcufft.so.8.0 /usr/local/lib/libcufft.so.8.0 && sudo ldconfigsudo cp /usr/local/cuda-8.0/lib64/libcudnn.so.5 /usr/local/lib/libcudnn.so.5 && sudo ldconfig然后以运行/tensorflow/models/image/mnist/convolutional.py为例,显示下图说明Tensorflow以GPU的方式运行代码:
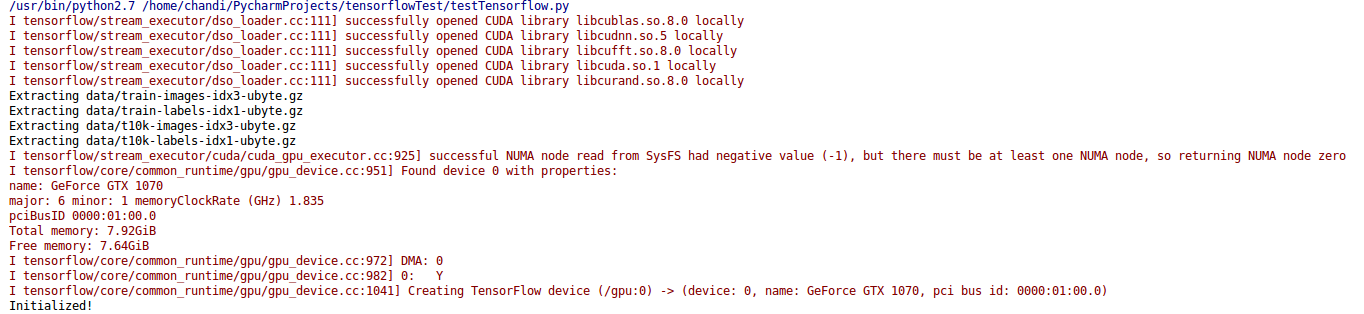
参考教程:
http://jingyan.baidu.com/article/e3c78d6460e6893c4c85f5b1.html
http://www.tensordata.cn/t/ubuntu16-0-4-tensorflow0-11/63














 2125
2125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









