






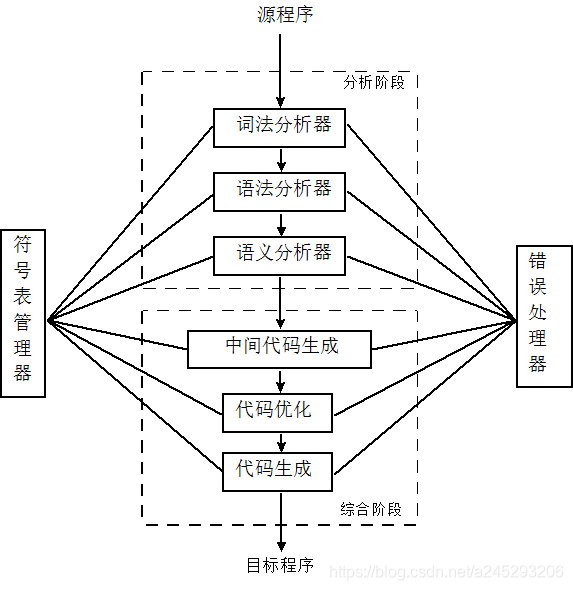
编译概述
源程序----翻译程序---->目标程序—解释程序—>结果
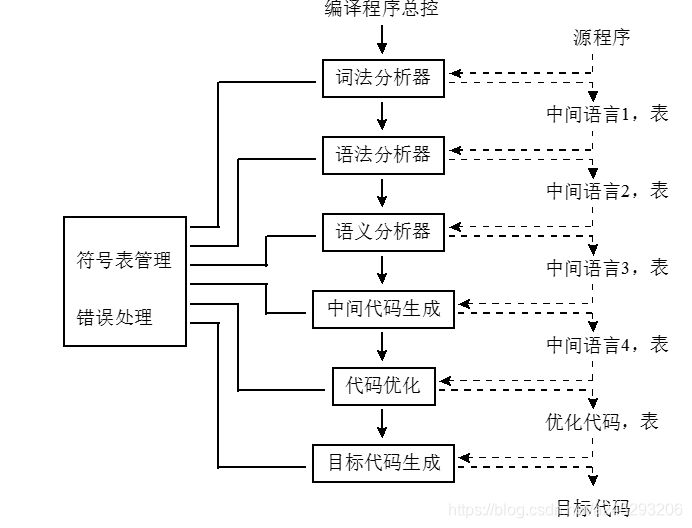
- 编译的阶段和任务
- 分析阶段
- 词法分析
- 语法分析
- 语义分析
- 综合阶段
- 中间代码生成
- 代码优化
- 目标代码生产
- 符号表的管理
- 错误诊断与处理
- 分析阶段
分析阶段
- 词法分析
- 扫描,线性分析
- 词法分析器
- 依次读入源程序中的每个字符,对构成源程序的字符串进行分解,识别出每个具有独立意义的字符串作为记号(token)并组织成记号流
- 把需要存放的单词放到符号表中,如变量名,标号,常量等。
- 工作依据
- 源程序的构词规则,也称为模式
eg:
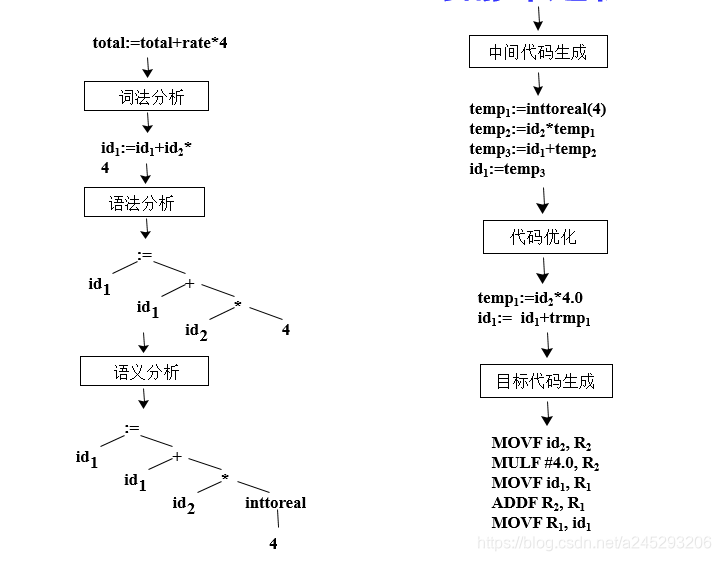
对 total:=total+rate*4 的词法分析:
(1) 标识符 total
(2) 赋值号 :=
(3) 标识符 total
(4) 加号 +
(5) 标识符 rate
(6) 乘号 *
(7) 整常数 4
空格, 注释的处理其他
分割记号的空格:删除
源程序中的注释:跳过
识别出来的标识符要放入符号表
对这些记号还要增加一个属性值
如发现标识符total时,词法分析器不仅产生一个记号如id,还把它的单词total填入符号表(如果total在表中不存在的话),记号id的属性值就是指向符号表中R条目的指针。
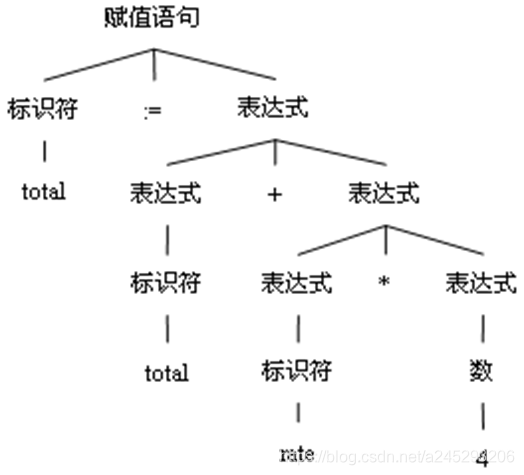
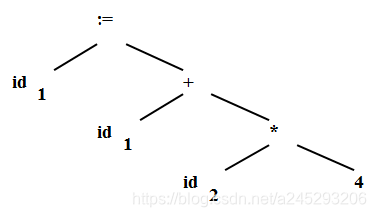
- 语法分析
- 层次结构的分析
- 把记号流按语言的语法结构层次地分组,以形成语法短语
- 源程序的语法短语常用分析树表示
- 工作依据
- 源程序的语法规则
- 程序的层次结构通常由递归的形式表示,如表达式的定义如下:
- 任何一个标识符都是一个表达式
- 任何一个数是一个表达式
- 如果expr1和expr2是表达式,expr1+expr2、expr1*expr2、(expr1)也都是表达式。
- 语句的递归定义
- 如果id是一个标识符,expr是一个表达式,则
id:=expr 是一个语句。 - 如果expr是表达式,stmt是语句,则
while (expr) do stmt 和 if (expr) then stmt 都是语句。
- 如果id是一个标识符,expr是一个表达式,则
- 语义分析
- 对语句的意义进行检查
- 收集类型等必要信息
- 用语法分析确定的层次结构表示各语法成分
- 工作依据
- 源程序的语义规则
- 一个重要任务
- 类型检查
- 数组的下标是否合理
- 根据规则检查每个运算符及其运算对象是否符合要求
- 过程调用中,形参与实参个数,类型是否匹配
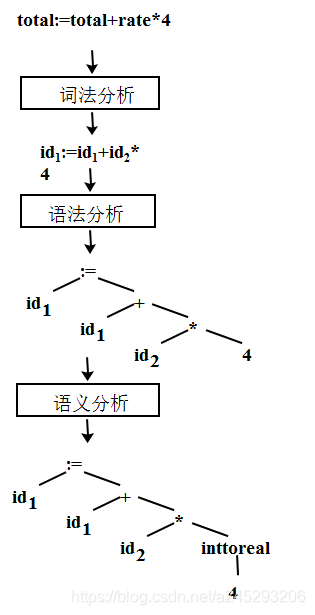
- 类型检查
综合阶段
- 任务
- 根据所制定的源程序到目标程序的对应关系,对分析阶段所产生的中间形式进行综合加工,从而得到与源程序等价的目标程序
- 任务划分
- 中间代码生成
- 代码优化
- 目标代码生成
- 中间代码生成
- 三地址代码
- 编译程序必须生成临时变量名,以便保留每条指令的计算结果
- 有些三地址指令少于三个操作数
- 三地址代码
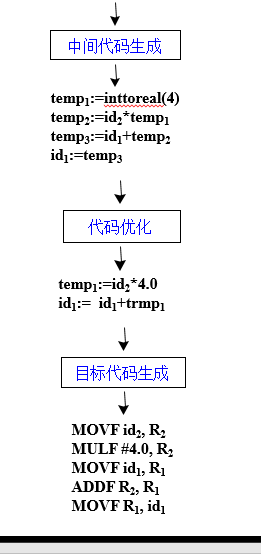
total:=total+rate*4 的三地址代码:
temp1:=inttoreal(4)
temp2:=id2*temp1
temp3:=id1+temp2
id1:=temp3
- 代码优化
- 对代码进行优化,使之占用的空间少,运行速度快
- 在中间代码的基础上进行
temp1:=inttoreal(4)
temp2:=id2*temp1
temp3:=id1+temp2
id1:=temp3
|
\ /
temp1:=id2*4.0
temp2:=id1+temp1
id1:=temp2
|
\ /
temp1:=id2*4.0
id1:=id1+temp1
- 目标代码生成
- 生成目标代码一般是可以重定位的机器代码或汇编语言代码
- 涉及到的两个问题
- 对程序中使用的每个变量要指定存储单元
- 对变量进行寄存器分配
total:=total+rate*4 的目标代码
MOVF id2, R2
MULF #4.0, R2
MOVF id1, R1
ADDF R2, R1
MOVF R1, id1
赋值语句total:=total+rate*4的各综合步骤及结果
翻译过程
符号表管理
- 重要工作
- 记录源程序中所使用的标识符
- 收集各个标识符的各种属性信息
- 符号表:
- 若干个记录组成的数据结构
- 每个标识符在表中有一条记录
- 记录的域是标识符的属性
- 应允许快速找到标识符的记录
- 可在其中存取数据
语句示例:
声明语句:float total, rate;
词法分析器:
错误处理
- 词法分析程序可以检测出非法字符错误。
- 语法分析程序能够发现记号流不符合语法规则的错误。
- 语义分析程序试图检测出具有正确的语法结构,但对所涉及的操作无意义的结构。
- 代码生成程序可能发现目标程序区超出了允许范围的错误。
- 由于计算机容量的限制,编译程序的处理能力受到限制而引起的错误。
前端和后端
- 前端主要由与源语言有关而与目标机器无关的那些部分组成
- 词法分析、语法分析、符号表的建立、语义分析和中间代码生成
- 与机器无关的代码优化工作
- 相应的错误处理工作和符号表操作
- 后端由编译程序中与目标机器有关的部分组成
- 与机器有关的代码优化、目标代码的生成
- 相应的错误处理和符号表操作
遍
- “遍”是指对源程序或其中间形式从头到尾扫描一遍,并作相关的加工处理,生成新的中间形式或目标程序。
- 编译程序的结构受“遍”的影响
- 遍数
- 分遍方式
- 一遍扫描的编译程序
- 多遍编译程序
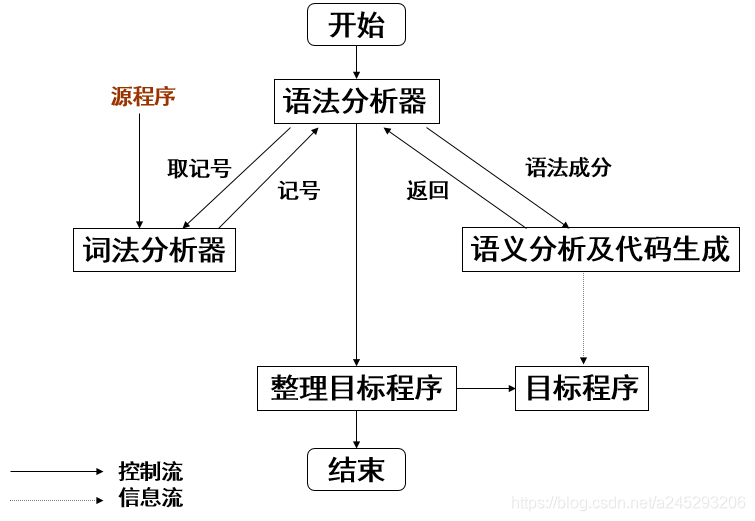
一遍扫描的编译程序:
多遍扫描的编译程序:
编译程序的前后处理器
- 预处理器
- 宏处理
- 宏定义和宏调用(不懂看ppt)
- 文件包含
- 头文件
- 处理到该文件时,就用stdio.h的内容替换该行内容
- 头文件
- 语言扩充
- 宏处理
- 汇编程序
- 汇编语言用助记符表示操作码,用标识符表示存储地址。
- 最简单的汇编程序对输入作两遍扫描
- 第一遍
- 找出标志存贮单元的所有标识符,并将它们存贮到汇编符号表中。
- 在符号表中指定该标识符所对应的存储单元地址,此地址是在首次遇到该标识符时确定的

- 第二遍
- 把每个用助记符表示的操作码翻译为二进制表示的机器代码。
- 把用标识符表示的存储地址翻译为汇编符号表中该标识符所对应的地址。
输出通常是可重定位的机器代码。
起始地址为0,各条指令及其所访问的地址都是相对于0的逻辑地址。
当装入内存时,可以指定任意的地址L作为开始单元。
输出中要对那些需要重定位的指令做出标记
标记供装入程序识别,以便计算相应的物理地址。




- 绝对机器代码

连接装配程序
装入–>连接
- 语法制导的结构化编辑器
- 程序格式化工具
- 软件测试工具
- 程序理解工具
- 高级语言的翻译工具
(以上内容详见ppt)














 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









