







直观理解Neural Tangent Kernel
本文是文章Some Intuition on the Neural Tangent Kernel的翻译整理.
一句话总结:NTK衡量的是,在使用SGD优化参数下,其对应的随机到样本 x ′ \displaystyle x' x′,在参数更新非常一小步 η \displaystyle \eta η后, f ( x ) \displaystyle f( x) f(x)的变化。也就是:
k ( x , x ′ ) = lim η → 0 f ( x , θ + η d f θ ( x ′ ) d θ ) − f ( x , θ ) η k(x,x')=\lim _{\eta \rightarrow 0}\frac{f\left( x,\theta +\eta \frac{df_{\theta } (x')}{d\theta }\right) -f(x,\theta )}{\eta } k(x,x′)=η→0limηf(x,θ+ηdθdfθ(x′))−f(x,θ)
热身
考虑最简单的函数 f ( i ) \displaystyle f( i) f(i),在每个点i都有一个不同的取值,这些取值可以用一个参数 θ i = f ( i ) \displaystyle \theta _{i} =f( i) θi=f(i)来表示,如果我们初始化 θ i = 3 i + 2 \displaystyle \theta _{i} =3i+2 θi=3i+2,那么这个函数大概长这样:
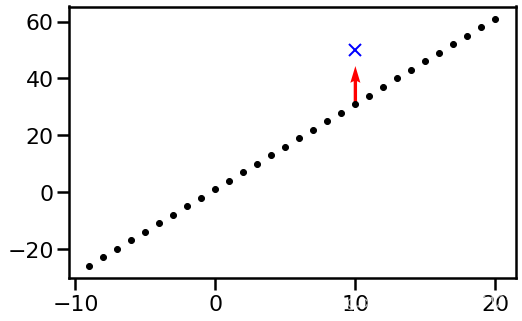
假设现在有一个样本是 ( x , y ) = ( 10 , 50 ) \displaystyle ( x,y) =( 10,50) (x,y)=(10,50),那么根据这个样本,我们需要对这个函数进行梯度更新,显然,这个样本只会影响 f ( 10 ) \displaystyle f( 10) f(10)这个点的参数 θ 10 \displaystyle \theta _{10} θ10,所以其他参数并不会发现变化,只会在10这个点变化,而这个变化如图上红色箭头所示。
显然,假设我们使用squared error loss, L = ( f ( 10 ; θ ) − 50 ) 2 \displaystyle L=( f( 10;\theta ) -50)^{2} L=(f(10;θ)−50)2,并且设更新步长 η = 0.1 \displaystyle \eta =0.1 η=0.1,那么 ∂ L ∂ θ 10 = ∂ ∂ θ 10 ( θ 10 − 50 ) 2 = 2 ( 32 − 50 ) = − 36 \displaystyle \frac{\partial L}{\partial \theta _{10}} =\frac{\partial }{\partial \theta _{10}}( \theta _{10} -50)^{2} =2( 32-50) =-36 ∂θ10∂L=∂θ10∂(θ10−50)2=2(32−50)=−36,显然为了让loss减少,于是 θ 10 = θ 10 − η ∂ L ∂ θ 10 = 32 + 0.1 ∗ 36 = 35.6 \displaystyle \theta _{10} =\theta _{10} -\eta \frac{\partial L}{\partial \theta _{10}} =32+0.1*36=35.6 θ10=θ10−η∂θ10∂L=32+0.1∗36=35.6,我们发现 f ( 10 ) \displaystyle f( 10) f(10)这个点增加3.6
线性函数
刚才的例子只有一个参数发生变化,过于特殊,现在给一个线性函数的例子,设 f ( x , θ ) = θ 1 x + θ 2 \displaystyle f( x,\theta ) =\theta _{1} x+\theta _{2} f(x,θ)=θ1x+θ2. 我们初始化参数为 θ 1 = 3 , θ 1 = 1 \displaystyle \theta _{1} =3,\theta _{1} =1 θ1=3,θ1=1,这样,跟上面的例子差不多,不过这是一条直线,同样考虑样本点 ( x , y ) = ( 10 , 50 ) \displaystyle ( x,y) =( 10,50) (x,y)=(10,50),在该样本下,作一次梯度下降更新参数,
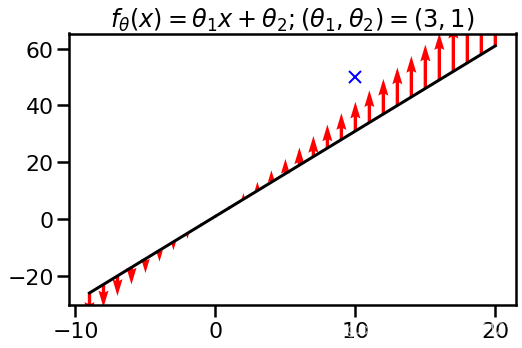
我们发现,所有x的取值都会发现变化,而我们关注的点 f ( x ) \displaystyle f( x) f(x)也会离目标值更近了点。
Nerual tangent kernel
考虑某个点x,我们关心该函数在该点下的取值为 f θ ( x ) \displaystyle f_{\theta }( x) fθ(x),在SGD算法中,往往随机抽一个样本 x ′ \displaystyle x' x′,我们想要知道,在这个新样本下,更新一次参数 θ \displaystyle \theta θ, f ( x ) \displaystyle f( x) f(x)会发生什么变化,而nerual tangent kernel k ( x , x ′ ) \displaystyle k( x,x') k(x,x′)正是衡量这种变化的函数:
η k ~ θ ( x , x ′ ) = f ( x , θ + η f θ ( x ′ ) d θ ) − f ( x , θ ) \eta \tilde{k}_{\theta } (x,x')=f\left( x,\theta +\eta \frac{f_{\theta } (x')}{d\theta }\right) -f(x,\theta ) ηk~θ(x,x′)=f(x,θ+ηdθfθ(x′))−f(x,θ)
换句话说,
k ( x , x ′ ) = lim η → 0 f ( x , θ + η d f θ ( x ′ ) d θ ) − f ( x , θ ) η k(x,x')=\lim _{\eta \rightarrow 0}\frac{f\left( x,\theta +\eta \frac{df_{\theta } (x')}{d\theta }\right) -f(x,\theta )}{\eta } k(x,x′)=η→0limηf(x,θ+ηdθdfθ(x′))−f(x,θ)
我们对 f \displaystyle f f进行泰勒近似,根据泰勒公式 f ( x + Δ x ) ≈ f ( x ) + f ′ ( x ) Δ x \displaystyle f( x+\Delta x) \approx f( x) +f'( x) \Delta x f(x+Δx)≈f(x)+f′(x)Δx
f ( x , θ + η d f θ ( x ′ ) d θ ) ≈ f ( x , θ ) + f ′ ( x , θ ) η d f θ ( x ′ ) d θ f\left( x,\theta +\eta \frac{df_{\theta } (x')}{d\theta }\right) \approx f( x,\theta ) +f'( x,\theta ) \eta \frac{df_{\theta } (x')}{d\theta } f(x,θ+ηdθdfθ(x′))≈f(x,θ)+f′(x,θ)ηdθdfθ(x′)
于是
f ( x , θ + η d f θ ( x ′ ) d θ ) − f ( x , θ ) η ≈ f ′ ( x , θ ) d f θ ( x ′ ) d θ = < d f θ ( x ) d θ , d f θ ( x ′ ) d θ > \frac{f\left( x,\theta +\eta \frac{df_{\theta } (x')}{d\theta }\right) -f(x,\theta )}{\eta } \approx f'( x,\theta )\frac{df_{\theta } (x')}{d\theta } =\left< \frac{df_{\theta } (x)}{d\theta } ,\frac{df_{\theta } (x')}{d\theta }\right> ηf(x,θ+ηdθdfθ(x′))−f(x,θ)≈f′(x,θ)dθdfθ(x′)=⟨dθdfθ(x),dθdfθ(x′)⟩
我们发现,NTK给予了我们一种“预测” f ( x ) \displaystyle f( x) f(x)在SGD下变化的能力。那它有一些什么性质呢?
NTK对参数的取值敏感
显然,神经网络可以改变参数,但是保持输出的值不变,那么参数的变化对NTK会有影响吗?答案是有,比如说,上面线性函数的例子将函数改为
f θ ( x ) = θ 1 x + 10 θ 2 f_{\theta }( x) =\theta _{1} x+10\theta _{2} fθ(x)=θ1x+10θ2
但是设 θ 1 = 3 , θ 2 = 0.1 \displaystyle \theta _{1} =3,\theta _{2} =0.1 θ1=3,θ2=0.1,你会发现这个函数跟上面是一致的,只是截距项从1变成10*0.1,然而,使用同样的样本 ( x , y ) = ( 10 , 50 ) \displaystyle ( x,y) =( 10,50) (x,y)=(10,50)更新这么一个函数,你会发现它的函数变化是不同的:
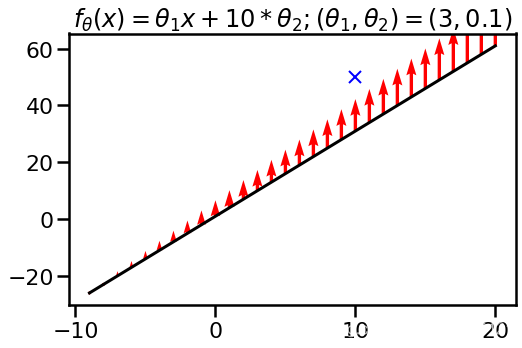
也就是说,NTK对参数是敏感的。
tiny radial basis function network
最后,再来一个小型的神经网络举个例子,考虑函数
f θ ( x ) = θ 1 exp ( − ( x − θ 2 ) 2 30 ) + θ 3 exp ( − ( x − θ 4 ) 2 30 ) + θ 5 , f_{\theta } (x)=\theta _{1}\exp\left( -\frac{(x-\theta _{2} )^{2}}{30}\right) +\theta _{3}\exp\left( -\frac{(x-\theta _{4} )^{2}}{30}\right) +\theta _{5} , fθ(x)=θ1exp(−30(x−θ2)2)+θ3exp(−30(x−θ4)2)+θ5,
初始化为 ( θ 1 , θ 2 , θ 3 , θ 4 , θ 5 ) = ( 4.0 , − 10.0 , 25.0 , 10.0 , 50.0 ) \displaystyle (\theta _{1} ,\theta _{2} ,\theta _{3} ,\theta _{4} ,\theta _{5} )=(4.0,-10.0,25.0,10.0,50.0) (θ1,θ2,θ3,θ4,θ5)=(4.0,−10.0,25.0,10.0,50.0),同样的,在样本点 ( x , y ) = ( 10 , 50 ) \displaystyle ( x,y) =( 10,50) (x,y)=(10,50)更新这么一个函数,我们得到函数的变化为:
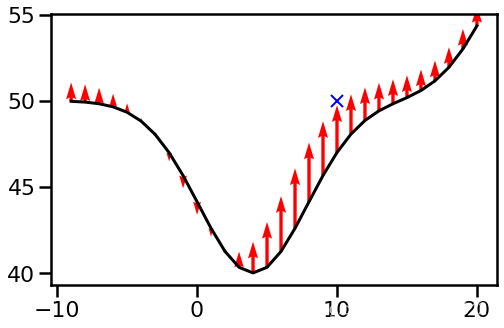
显然,我们发现,在靠近0附近它的变化是很小的,而在10附近它的变化是很大的,之前说过,NTK就是刻画这种变化的,因此,我们可以把NTK画出来:
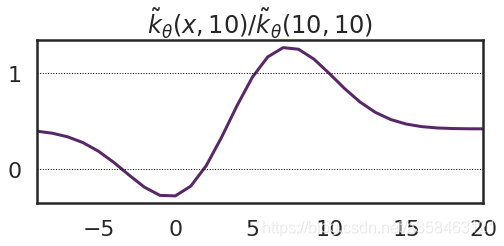
这里除以了在10,10处标准化了一下(只是个除了个常数可以无视),可以发现,确实在0附近的值很小,而在10附近的值很大,符合我们的观察。值得一提的是,虽然样本是 x = 10 \displaystyle x=10 x=10的点,但是变化最大的地方其实是在 x = 7 \displaystyle x=7 x=7的地方。
那如果我们不停的更新参数会怎样?以下是更新15次的图
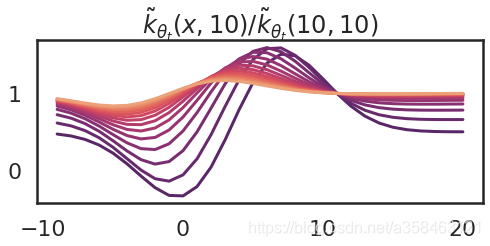
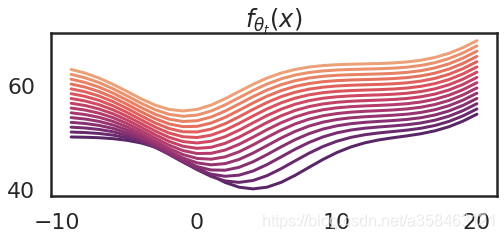
显然,随着参数的变化,kernel大小也在变化,而且越来越平滑,这意味着函数在每个取值下的变化越来越一致。
NTK有什么用?
NTK在无限宽神经网络下有几个非常重要,有用的性质:
- 在无限宽的网络中,如果参数 θ 0 \displaystyle \theta _{0} θ0在以某种合适的分布下初始化,那么在该初始值下的NTK k θ 0 \displaystyle k_{\theta _{0}} kθ0是一个确定的函数,这意味着,不管我的初始值是多少,最终总会收敛到一个确定的核函数上,它与初始化无关!
- 而且在无限宽网络中, k θ t \displaystyle k_{\theta _{t}} kθt并不会随着训练的变化而变化,也就是说,在训练中参数的改变并不会改变该核函数。
以上两个事实告诉我们,在无限宽网络中,训练可以理解成一个简单的交kernel gradient descent的算法,而且kernel还是固定的,只取决于网络的结构还有激活函数之类的。这些性质,加上,Neal,(1994)的结论,使得我们可以将这个用梯度下降收敛的极值的概率分布看做是一个随机过程。
最后要注意的就是,这里的NTK,其实是针对梯度下降法提出来的,以往的无限宽网络与高斯过程的联系其实只是在初始化阶段的时候收敛到高斯过程,它并没有说训练过程也是一个高斯过程。它是没有考虑随机梯度下降这一过程的。
而在NTK这里,我们发现,训练的时候与kernel无关,而且初始化决定了它的取值,也就是说,在训练过程中,我们仍然可以认为它还是一个高斯过程而不仅仅是初始化的时候。














 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









