







Causal effect可识别的一般条件
结论:干预后分布
p
(
v
′
∣
d
o
(
x
)
)
p(v'|do(x))
p(v′∣do(x)),可识别的充要条件是,不存在confounder(隐的共同原因),连接了X与X的孩子。举个例子,
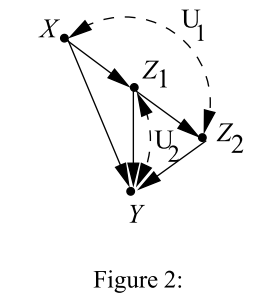
上图的
U
1
,
U
2
U_1,U_2
U1,U2是隐变量,该图
p
(
y
,
z
1
,
z
2
∣
d
o
(
x
)
)
p(y,z_1,z_2|do(x))
p(y,z1,z2∣do(x))是可识别的,因为不存在隐变量
U
U
U同时指向X与X的孩子,但是如果我们加一个
U
3
→
X
,
U
3
→
Z
1
U_3\to X,U_3\to Z_1
U3→X,U3→Z1那就变成不可识别的了。
但这是为什么呢?干预后的分布又是什么意思?我们从干预这个操作开始讲起。
干预后的分布是什么?
先说下因果图的分布是什么?给定一个因果网络,以及变量 v = { v 1 , . . . , v n , x } \displaystyle v=\{v_{1} ,...,v_{n} ,x\} v={v1,...,vn,x},假设没有隐变量,对于分布 p ( v ) \displaystyle p( v) p(v),可以进行概率分解:
P ( v ) = ∏ i P ( v i ∣ p a i ) P( v) =\prod _{i} P( v_{i} |pa_{i}) P(v)=i∏P(vi∣pai)
那如果有隐变量 u \displaystyle u u,但是所有隐变量都没有父亲(这种模型也被称为Semi-Markovian model),那么有隐变量的分布就是:
P ( v ) = ∑ u ∏ i P ( v i ∣ p a i , u i ) p ( u ) P( v) =\sum _{u}\prod _{i} P\left( v_{i} |pa_{i} ,u^{i}\right) p( u) P(v)=u∑i∏P(vi∣pai,ui)p(u)
那个干预后的分布,我们可以定义为,强制改变
x的状态,但是其他的状态保持不变,记为
p
x
(
v
)
:
=
p
(
v
′
∣
d
o
(
x
)
)
\displaystyle p_{x}( v) :=p( v'|do( x))
px(v):=p(v′∣do(x)),其中
v
′
v'
v′表示不包括x的所有结点。那么对x干预的后果,会使得
P
(
v
)
\displaystyle P( v)
P(v)出现两种情况:
P x ( v ) = { ∏ { i ∣ V i ∉ x } P ( v i ∣ p a i ) d o ( x ) 的 取 值 在 v 中 有 概 率 0 d o ( x ) 的 取 值 在 v 中 没 有 概 率 P_{x}( v) =\begin{cases} \prod _{\left\{i|V_{i}\not{\in } x\right\}} P( v_{i} |pa_{i}) & do( x) 的取值在v中有概率\\ 0 & do( x) 的取值在v中没有概率 \end{cases} Px(v)={∏{i∣Vi∈x}P(vi∣pai)0do(x)的取值在v中有概率do(x)的取值在v中没有概率
这是因为干预相当于让一个变量强制100%发生,那么其发生概率只会等于0或1(0的情况就表示这种干预不能发生). 注意,虽然 p ( d o ( x ) ∣ p a x ) = 1 \displaystyle p( do( x) |pa_{x}) =1 p(do(x)∣pax)=1,但是 p ( y ∣ d o ( x ) ) \displaystyle p( y|do( x)) p(y∣do(x))不一定等于1的.
类似的,在有隐变量的时候,同样也有干预后的分布为
P x ( v ) = { ∑ u ∏ { i ∣ V i ∉ x } P ( v i ∣ p a i , u i ) p ( u ) d o ( x ) 的 取 值 在 v 中 有 概 率 0 d o ( x ) 的 取 值 在 v 中 没 有 概 率 P_{x}( v) =\begin{cases} \sum _{u}\prod _{\left\{i|V_{i}\not{\in } x\right\}} P\left( v_{i} |pa_{i} ,u^{i}\right) p( u) & do( x) 的取值在v中有概率\\ 0 & do( x) 的取值在v中没有概率 \end{cases} Px(v)={∑u∏{i∣Vi∈x}P(vi∣pai,ui)p(u)0do(x)的取值在v中有概率do(x)的取值在v中没有概率
可识别性是什么?–以back door和front door为例
所谓可识别,就是回答以下问题:能不能仅用观测数据就算出 P x ( v ) \displaystyle P_{x}( v) Px(v),这个问题在没有隐变量的时候是显然的,因为 P x ( v ) = ∏ { i ∣ V i ∉ x } P ( v i ∣ p a i ) \displaystyle P_{x}( v) =\prod _{\left\{i|V_{i}\not{\in } x\right\}} P( v_{i} |pa_{i}) Px(v)={i∣Vi∈x}∏P(vi∣pai),全部分布都是可观测的,所以一定可以算的。
练习1: 推导大名鼎鼎的back-door准则,设有因果关系 X ← Z → Y \displaystyle X\leftarrow Z\rightarrow Y X←Z→Y且 X → Y \displaystyle X\rightarrow Y X→Y,于是
p ( d o ( x ) , y , z ) = p ( z ) p ( d o ( x ) ∣ z ) ⏟ = 1 p ( y ∣ z , d o ( x ) ) ⟹ ∑ z p ( d o ( x ) , y , z ) = ∑ z p ( z ) p ( y ∣ z , d o ( x ) ) ⟹ p ( y ∣ d o ( x ) ) p ( d o ( x ) ) ⏟ = 1 = ∑ z p ( z ) p ( y ∣ z , d o ( x ) ) ⟹ p ( y ∣ d o ( x ) ) = ∑ z p ( z ) p ( y ∣ z , d o ( x ) ) \begin{array}{ c c l } & p( do( x) ,y,z) & =p( z)\underbrace{p( do( x) |z)}_{=1} p( y|z,do( x))\\ \Longrightarrow & \sum _{z} p( do( x) ,y,z) & =\sum _{z} p( z) p( y|z,do( x))\\ \Longrightarrow & p( y|do( x))\underbrace{p( do( x))}_{=1} & =\sum _{z} p( z) p( y|z,do( x))\\ \Longrightarrow & p( y|do( x)) & =\sum _{z} p( z) p( y|z,do( x)) \end{array} ⟹⟹⟹p(do(x),y,z)∑zp(do(x),y,z)p(y∣do(x))=1 p(do(x))p(y∣do(x))=p(z)=1 p(do(x)∣z)p(y∣z,do(x))=∑zp(z)p(y∣z,do(x))=∑zp(z)p(y∣z,do(x))=∑zp(z)p(y∣z,do(x))
显然这个只适用于没有隐变量的情况。但是有隐变量的时候怎么办?
练习2: 推导大名鼎鼎的fount-door准则
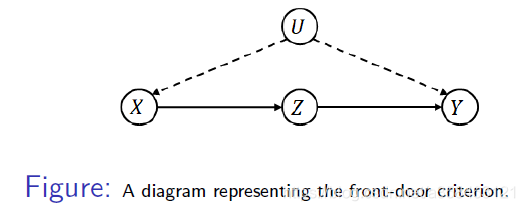
比如上图的结构,也有一个著名的准则交fount door准则:
p ( y ∣ d o ( x ) ) = ∑ z p ( z ∣ x ) ∑ x p ( y ∣ x , z ) p ( x ) p( y|do( x)) =\sum _{z} p( z|x)\sum _{x} p( y|x,z) p( x) p(y∣do(x))=z∑p(z∣x)x∑p(y∣x,z)p(x)
这个又是怎么来的呢?我们可以看看,首先
p ( x , y , z ) = p ( z ∣ x ) ∑ u p ( x ∣ u ) p ( y ∣ z , u ) p ( u ) p( x,y,z) =p( z|x)\sum _{u} p( x|u) p( y|z,u) p( u) p(x,y,z)=p(z∣x)u∑p(x∣u)p(y∣z,u)p(u)
全概率这一步很简单但却是及其关键的,因为我们发现 p ( z ∣ x ) \displaystyle p( z|x) p(z∣x)可以提出来,于是 ∑ u p ( x ∣ u ) p ( y ∣ z , u ) p ( u ) = p ( x , y , z ) p ( z ∣ x ) \displaystyle \sum _{u} p( x|u) p( y|z,u) p( u) =\frac{p( x,y,z)}{p( z|x)} u∑p(x∣u)p(y∣z,u)p(u)=p(z∣x)p(x,y,z),这个的作用我们后面说,接来下 d o ( x ) \displaystyle do( x) do(x),于是有:
p ( d o ( x ) , y , z ) = p ( z ∣ d o ( x ) ) ∑ u p ( y ∣ z , u ) p ( u ) p( do( x) ,y,z) =p( z|do( x))\sum _{u} p( y|z,u) p( u) p(do(x),y,z)=p(z∣do(x))u∑p(y∣z,u)p(u)
两边同时对z求和:
p ( d o ( x ) , y ) = ∑ z ∑ u p ( z ∣ d o ( x ) ) p ( y ∣ z , u ) p ( u ) = ∑ z p ( z ∣ d o ( x ) ) ∑ u p ( y ∣ z , u ) p ( u ) p( do( x) ,y) =\sum _{z}\sum _{u} p( z|do( x)) p( y|z,u) p( u) =\sum _{z} p( z|do( x))\sum _{u} p( y|z,u) p( u) p(do(x),y)=z∑u∑p(z∣do(x))p(y∣z,u)p(u)=z∑p(z∣do(x))u∑p(y∣z,u)p(u)
接下来是关键了,我们发现它大概可以分解成两项,首先第一项是 p ( z ∣ d o ( x ) ) = p ( z ∣ x ) \displaystyle p( z|do( x)) =p( z|x) p(z∣do(x))=p(z∣x),因为这个分布概率并不会收到do的影响而变化。那么剩下第二项则是 ∑ u p ( y ∣ z , u ) p ( u ) \displaystyle \sum _{u} p( y|z,u) p( u) u∑p(y∣z,u)p(u),关键的地方来了,我们发现 ∑ u p ( x ∣ u ) p ( y ∣ z , u ) p ( u ) = p ( x , y , z ) p ( z ∣ x ) \displaystyle \sum _{u} p( x|u) p( y|z,u) p( u) =\frac{p( x,y,z)}{p( z|x)} u∑p(x∣u)p(y∣z,u)p(u)=p(z∣x)p(x,y,z),用这个表达式是可以消去隐变量的!对比下第二项 ∑ z ∑ u p ( y ∣ z , u ) p ( u ) \displaystyle \sum _{z}\sum _{u} p( y|z,u) p( u) z∑u∑p(y∣z,u)p(u),很接近!但还差个 p ( x ∣ u ) \displaystyle p( x|u) p(x∣u),那么我们能不能凑这一项出来?然后把隐变量干掉?答案是可以!只需要加一个 ∑ x p ( x ∣ u ) \displaystyle \sum _{x} p( x|u) x∑p(x∣u),于是
∑ u p ( y ∣ z , u ) p ( u ) = ∑ x ∑ z ∑ u p ( x ∣ u ) p ( y ∣ z , u ) p ( u ) = ∑ x ∑ z ∑ u p ( x ∣ u ) p ( y ∣ z , u ) p ( u ) = ∑ x ∑ z p ( x , y , z ) p ( z ∣ x ) = ∑ x ∑ z p ( y ∣ z , x ) p ( z ∣ x ) p ( x ) p ( z ∣ x ) = ∑ x ∑ z p ( y ∣ z , x ) p ( x ) \begin{aligned} \sum _{u} p( y|z,u) p( u) & =\sum _{x}\sum _{z}\sum _{u} p( x|u) p( y|z,u) p( u)\\ & =\sum _{x}\sum _{z}\sum _{u} p( x|u) p( y|z,u) p( u)\\ & =\sum _{x}\sum _{z}\frac{p( x,y,z)}{p( z|x)}\\ & =\sum _{x}\sum _{z}\frac{p( y|z,x) p( z|x) p( x)}{p( z|x)}\\ & =\sum _{x}\sum _{z} p( y|z,x) p( x) \end{aligned} u∑p(y∣z,u)p(u)=x∑z∑u∑p(x∣u)p(y∣z,u)p(u)=x∑z∑u∑p(x∣u)p(y∣z,u)p(u)=x∑z∑p(z∣x)p(x,y,z)=x∑z∑p(z∣x)p(y∣z,x)p(z∣x)p(x)=x∑z∑p(y∣z,x)p(x)
最后总体来看:
p ( d o ( x ) , y ) = ∑ z p ( z ∣ x ) ∑ x ∑ z p ( y ∣ z , x ) p ( x ) \begin{aligned} p( do( x) ,y) & =\sum _{z} p( z|x)\sum _{x}\sum _{z} p( y|z,x) p( x) \end{aligned} p(do(x),y)=z∑p(z∣x)x∑z∑p(y∣z,x)p(x)
因为 p ( d o ( x ) , y ) = p ( y ∣ d o ( x ) ) p ( d o ( x ) ) = p ( y ∣ d o ( x ) ) \displaystyle p( do( x) ,y) =p( y|do( x)) p( do( x)) =p( y|do( x)) p(do(x),y)=p(y∣do(x))p(do(x))=p(y∣do(x)),所以我们就得到了front door准则!
p ( y ∣ d o ( x ) ) = ∑ z p ( z ∣ x ) ∑ x p ( y ∣ x , z ) p ( x ) p( y|do( x)) =\sum _{z} p( z|x)\sum _{x} p( y|x,z) p( x) p(y∣do(x))=z∑p(z∣x)x∑p(y∣x,z)p(x)
其实这里面最关键的一步是用 p ( x , y , z ) p ( z ∣ x ) \displaystyle \frac{p( x,y,z)}{p( z|x)} p(z∣x)p(x,y,z)进行替换。
可识别的一般条件
从back door和front door的推导,我们可以找出一些规律,首先,我们发现全概率是可以替换掉隐变量的分布的,基于此,我们可以给出一个最简单的情况,设 V ′ = V \ { X } \displaystyle V'=V\backslash \{X\} V′=V\{X},考虑 p x ( v ′ ) \displaystyle p_{x}( v') px(v′)的可识别性,这里 v ; \displaystyle v; v;是除了x的所有贝叶斯网络下的变量.
P
(
v
)
=
∑
u
∏
i
P
(
v
i
∣
p
a
i
,
u
i
)
p
(
u
)
P( v) =\sum _{u}\prod _{i} P\left( v_{i} |pa_{i} ,u^{i}\right) p( u)
P(v)=u∑i∏P(vi∣pai,ui)p(u)
定理1: 如果没有双向边指向X的时候(X这个变量不存在latent confounder),
P
x
(
v
)
\displaystyle P_{x}( v)
Px(v)可识别
P x ( v ′ ) = P ( v ′ ∣ x , p a x ) P ( p a x ) P_{x}( v') =P( v'|x,pa_{x}) P( pa_{x}) Px(v′)=P(v′∣x,pax)P(pax)
证明:
因为X没有latent confounder,因此
p
(
x
∣
p
a
x
,
u
x
)
=
p
(
x
∣
p
a
x
)
\displaystyle p\left( x|pa_{x} ,u^{x}\right) =p( x|pa_{x})
p(x∣pax,ux)=p(x∣pax)(x没有隐变量),于是
P ( v ) = p ( v ′ ∣ x ) p ( x ) = P ( x ∣ p a x ) ∑ u ∏ { i ∣ V i ≠ X } P ( v i ∣ p a i , u i ) P ( u ) = P ( x ∣ p a x ) P ( v ′ , d o ( x ) ) = P ( x ∣ p a x ) P ( v ′ ∣ d o ( x ) ) \left. \begin{array}{ l } P(v)=p( v'|x) p( x)\\ =P(x|pa_{x} )\sum _{u}\prod _{\{i|V_{i} \neq X\}} P(v_{i} |pa_{i} ,u^{i} )P(u)\\ =P(x|pa_{x} )P (v',do( x) )\\ =P(x|pa_{x} )P(v'|do( x) ) \end{array}\right. P(v)=p(v′∣x)p(x)=P(x∣pax)∑u∏{i∣Vi=X}P(vi∣pai,ui)P(u)=P(x∣pax)P(v′,do(x))=P(x∣pax)P(v′∣do(x))
因此
P x ( v ′ ) = P ( v ) P ( x ∣ p a x ) = P ( v ′ ∣ x , p a x ) P ( x ∣ p a x ) p ( p a x ) P ( x ∣ p a x ) = P ( v ′ ∣ x , p a x ) P ( p a x ) P_{x}( v') =\frac{P(v)}{P(x|pa_{x} )} =\frac{P(v'|x,pa_{x}) P( x|pa_{x}) p( pa_{x})}{P(x|pa_{x} )} =P( v'|x,pa_{x}) P( pa_{x}) Px(v′)=P(x∣pax)P(v)=P(x∣pax)P(v′∣x,pax)P(x∣pax)p(pax)=P(v′∣x,pax)P(pax)
证毕。
如果X有隐变量怎么办?另一个有趣的情况则是,如果没有双向边指向所有X直接孩子的话(意味着X和X的子孙(非直接孩子)都是允许存在双向边),我们也能推出一个可识别的公式。
定理2 如果所有X的直接孩子都没有双向边,则 P x ( v ′ ) \displaystyle P_{x}( v') Px(v′)可识别,
P x ( v ′ ) = ( ∏ { i ∣ V i ∈ C h x } P ( v i ∣ p a i ) ) ∑ x P ( v ) ∏ { i ∣ V i ∈ C h x } P ( v i ∣ p a i ) P_{x} (v')=\left(\prod _{\{i|V_{i} \in Ch_{x} \}} P(v_{i} |pa_{i} )\right)\sum _{x}\frac{P(v)}{\prod _{\{i|V_{i} \in Ch_{x} \}} P(v_{i} |pa_{i} )} Px(v′)=⎝⎛{i∣Vi∈Chx}∏P(vi∣pai)⎠⎞x∑∏{i∣Vi∈Chx}P(vi∣pai)P(v)
证明:
令
S
=
V
\
(
c
h
x
∪
{
X
}
)
,
A
=
∏
{
i
∣
V
i
∈
S
}
P
(
v
i
∣
p
a
i
,
u
i
)
\displaystyle S=V\backslash ( ch_{x} \cup \{X\}) ,A=\prod _{\{i|V_{i} \in S\}} P(v_{i} |pa_{i} ,u^{i} )
S=V\(chx∪{X}),A={i∣Vi∈S}∏P(vi∣pai,ui). 因为所有X的孩子都没有隐变量,所以全概率可以分解为两部分:
p ( v ) = ∏ { i ∣ V i ∈ c h x } P ( v i ∣ p a i , u i ) ∑ u p ( x ∣ p a x , u x ) ⋅ ∏ V \ ( c h x ∪ { X } ) P ( v i ∣ p a i , u i ) ⏟ A ⋅ p ( u ) p( v) =\prod _{\{i|V_{i} \in ch_{x} \}} P(v_{i} |pa_{i} ,u^{i} )\sum _{u} p\left( x|pa_{x} ,u^{x}\right) \cdotp \underbrace{\prod _{V\backslash ( ch_{x} \cup \{X\})} P(v_{i} |pa_{i} ,u^{i} )}_{A} \cdotp p( u) p(v)={i∣Vi∈chx}∏P(vi∣pai,ui)u∑p(x∣pax,ux)⋅A V\(chx∪{X})∏P(vi∣pai,ui)⋅p(u)
一部分是X的孩子(没有隐变量,所以可以提出来),另一部分是其余的变量。又因为 p ( d o ( x ) ∣ p a x ) = 1 \displaystyle p( do( x) |pa_{x}) =1 p(do(x)∣pax)=1,所以
p ( d o ( x ) , v ′ ) = ∏ { i ∣ V i ∈ c h x } P ( v i ∣ p a i , u i ) ∑ u A ⋅ p ( u ) p( do( x) ,v') =\prod _{\{i|V_{i} \in ch_{x} \}} P(v_{i} |pa_{i} ,u^{i} )\sum _{u} A\cdotp p( u) p(do(x),v′)={i∣Vi∈chx}∏P(vi∣pai,ui)u∑A⋅p(u)
好了,关键一步来了,跟之前类似,我们发现干预分布跟全概率分布长得很像,大家都有一个 A p ( u ) \displaystyle Ap( u) Ap(u),就是缺了 p ( x ∣ p a x , u x ) \displaystyle p\left( x|pa_{x} ,u^{x}\right) p(x∣pax,ux),所以自然的,我们可以在干预分布里强行加进去,利用 ∑ x p ( x ∣ p a x , u x ) = 1 \displaystyle \sum _{x} p\left( x|pa_{x} ,u^{x}\right) =1 x∑p(x∣pax,ux)=1,这样我们就能借助全概率来消掉干预分布的隐变量。而且,因为A是排除了所有X与X的子代的变量,因此A不包含x,于是,
p ( d o ( x ) , v ′ ) = ∏ { i ∣ V i ∈ c h x } P ( v i ∣ p a i , u i ) ∑ x ∑ u p ( x ∣ p a x , u x ) A ⋅ p ( u ) = ∏ { i ∣ V i ∈ c h x } P ( v i ∣ p a i , u i ) ∑ x p ( v ) ∏ { i ∣ V i ∈ c h x } P ( v i ∣ p a i , u i ) \begin{aligned} p( do( x) ,v') & =\prod _{\{i|V_{i} \in ch_{x} \}} P(v_{i} |pa_{i} ,u^{i} )\sum _{x}\sum _{u} p\left( x|pa_{x} ,u^{x}\right) A\cdotp p( u)\\ & =\prod _{\{i|V_{i} \in ch_{x} \}} P(v_{i} |pa_{i} ,u^{i} )\sum _{x}\frac{p( v)}{\prod _{\{i|V_{i} \in ch_{x} \}} P(v_{i} |pa_{i} ,u^{i} )} \end{aligned} p(do(x),v′)={i∣Vi∈chx}∏P(vi∣pai,ui)x∑u∑p(x∣pax,ux)A⋅p(u)={i∣Vi∈chx}∏P(vi∣pai,ui)x∑∏{i∣Vi∈chx}P(vi∣pai,ui)p(v)
证毕。
总结下,最重要的一步仍然是想办法用全概率将隐变量干掉,我们发现,当X的孩子没有隐变量的时候是可以干掉的,如果X的孩子有隐变量,那么A中就会包含X,这时候就不一定了。所以接来下的问题是什么时候可行,什么时候不可行?
如下图
显然,这个图里面X的孩子是由双向边 U 2 \displaystyle U_{2} U2的,但他却是可以识别的。为什么?我们可以来推导下:
P ( v ) = ∑ u 1 P ( x ∣ u 1 ) P ( z 2 ∣ z 1 , u 1 ) P ( u 1 ) ⏟ Q 1 ⋅ ∑ u 2 P ( z 1 ∣ x , u 2 ) P ( y ∣ x , z 1 , z 2 , u 2 ) P ( u 2 ) ⏟ Q 2 P(v)=\underbrace{\sum _{u_{1}} P(x|u_{1} )P(z_{2} |z_{1} ,u_{1} )P(u_{1} )}_{Q_{1}} \cdot \underbrace{\sum _{u_{2}} P(z_{1} |x,u_{2} )P(y|x,z_{1} ,z_{2} ,u_{2} )P(u_{2} )}_{Q_{2}} P(v)=Q1 u1∑P(x∣u1)P(z2∣z1,u1)P(u1)⋅Q2 u2∑P(z1∣x,u2)P(y∣x,z1,z2,u2)P(u2)
我们发现 p ( v ) \displaystyle p( v) p(v)分解成两部分,分别由 u 1 , u 2 \displaystyle u_{1} ,u_{2} u1,u2两个求和组成,并且,这两部分对应的恰好是隐变量confounder导致的,这两部分,分别被confounder形成的分布,在后文会被称为c-factor. 于是,考虑干预后分布,因为 p ( d o ( x ) ∣ u 1 ) = 1 \displaystyle p( do( x) |u_{1}) =1 p(do(x)∣u1)=1, 我们有
P x ( v ′ ) = ∑ u 1 P ( z 2 ∣ z 1 , u 1 ) P ( u 1 ) ⋅ ∑ u 2 P ( z 1 ∣ x , u 2 ) P ( y ∣ x , z 1 , z 2 , u 2 ) P ( u 2 ) ⏟ Q 2 P_{x} (v')=\sum _{u_{1}} P(z_{2} |z_{1} ,u_{1} )P(u_{1} )\cdot \underbrace{\sum _{u_{2}} P(z_{1} |x,u_{2} )P(y|x,z_{1} ,z_{2} ,u_{2} )P(u_{2} )}_{Q_{2}} Px(v′)=u1∑P(z2∣z1,u1)P(u1)⋅Q2 u2∑P(z1∣x,u2)P(y∣x,z1,z2,u2)P(u2)
对比全概率公式,我们发现只缺了一项 P ( x ∣ u 1 ) \displaystyle P(x|u_{1} ) P(x∣u1)所以我们补回去,就有
P x ( v ′ ) = ∑ u 2 P ( z 1 ∣ x , u 2 ) P ( y ∣ x , z 1 , z 2 , u 2 ) P ( u 2 ) ⏟ Q 2 ⋅ ∑ x ∑ u 1 P ( x ∣ u 1 ) P ( z 2 ∣ z 1 , u 1 ) P ( u 1 ) ⏟ Q 1 = Q 2 ∑ x Q 1 \begin{aligned} P_{x} (v') & =\underbrace{\sum _{u_{2}} P(z_{1} |x,u_{2} )P(y|x,z_{1} ,z_{2} ,u_{2} )P(u_{2} )}_{Q_{2}} \cdot \sum _{x}\underbrace{\sum _{u_{1}} P(x|u_{1} )P(z_{2} |z_{1} ,u_{1} )P(u_{1} )}_{Q_{1}}\\ & =Q_{2}\sum _{x} Q_{1} \end{aligned} Px(v′)=Q2 u2∑P(z1∣x,u2)P(y∣x,z1,z2,u2)P(u2)⋅x∑Q1 u1∑P(x∣u1)P(z2∣z1,u1)P(u1)=Q2x∑Q1
这意味着,如果 Q 1 \displaystyle Q_{1} Q1和 Q 2 \displaystyle Q_{2} Q2这两部分都是可识别的(可从观测数据恢复),他们的整体就是可识别的!实际上,因为 p ( v ) = Q 1 Q 2 \displaystyle p( v) =Q_{1} Q_{2} p(v)=Q1Q2,所以只要其中一个,比如 Q 1 \displaystyle Q_{1} Q1可识别,另一个就可以识别 Q 2 = p ( v ) Q 1 \displaystyle Q_{2} =\frac{p( v)}{Q_{1}} Q2=Q1p(v). 那 Q 1 \displaystyle Q_{1} Q1要怎么识别呢?我们要想办法把 u 2 \displaystyle u_{2} u2的部分干掉,但是又不能像之前一样用全概率(否则 Q 2 \displaystyle Q_{2} Q2就没法恢复了),怎么办?虽然不能用所有变量的全概率,但是我们可以用部分结点的全概率啊!仔细观察全概率的分解, y \displaystyle y y只出现在 Q 2 \displaystyle Q_{2} Q2中,所以可以通过求和(积分)把y干掉,得到只有3个变量的全概率!:
∑ y P ( v ) = P ( x , z 1 , z 2 ) = ∑ u 1 P ( x ∣ u 1 ) P ( z 2 ∣ z 1 , u 1 ) P ( u 1 ) ⏟ Q 1 ⋅ ∑ u 2 P ( z 1 ∣ x , u 2 ) P ( u 2 ) \sum _{y} P(v)=P( x,z_{1} ,z_{2}) =\underbrace{\sum _{u_{1}} P(x|u_{1} )P(z_{2} |z_{1} ,u_{1} )P(u_{1} )}_{Q_{1}} \cdot \sum _{u_{2}} P(z_{1} |x,u_{2} )P(u_{2} ) y∑P(v)=P(x,z1,z2)=Q1 u1∑P(x∣u1)P(z2∣z1,u1)P(u1)⋅u2∑P(z1∣x,u2)P(u2)
而且把y干掉之后,我们又发现, z 2 \displaystyle z_{2} z2只出现在 Q 1 \displaystyle Q_{1} Q1中,所以也可以把他干掉:
∑ y ∑ z 2 P ( v ) = P ( x , z 1 ) = P ( x ) ⋅ ∑ u 2 P ( z 1 ∣ x , u 2 ) P ( u 2 ) \sum _{y}\sum _{z_{2}} P(v)=P( x,z_{1}) =P(x) \cdot \sum _{u_{2}} P(z_{1} |x,u_{2} )P(u_{2} ) y∑z2∑P(v)=P(x,z1)=P(x)⋅u2∑P(z1∣x,u2)P(u2)
这样我们就得到两个部分变量的全概率分解。显然,用这两个全概率分解相除, u 2 \displaystyle u_{2} u2被消干掉了!
P ( x , z 1 , z 2 ) P ( x , z 1 ) = Q 1 P ( x ) ⟹ Q 1 = P ( x , z 1 , z 2 ) P ( x , z 1 ) P ( x ) = P ( z 2 ∣ z 1 , x ) P ( z 1 ∣ x ) p ( x ) P ( z 1 ∣ x ) = P ( z 2 ∣ z 1 , x ) p ( x ) ⟹ Q 2 = P ( v ) Q 1 = P ( y ∣ z 1 , z 2 , x ) P ( z 2 ∣ z 1 , x ) P ( z 1 ∣ x ) P ( x ) P ( z 2 ∣ z 1 , x ) p ( x ) = P ( y ∣ z 1 , z 2 , x ) P ( z 1 ∣ x ) \frac{P( x,z_{1} ,z_{2})}{P( x,z_{1})} =\frac{Q_{1}}{P(x)}\\ \Longrightarrow Q_{1} =\frac{P( x,z_{1} ,z_{2})}{P( x,z_{1})} P(x) =\frac{P( z_{2} |z_{1} ,x) P( z_{1} |x) p( x)}{P( z_{1} |x)} =P( z_{2} |z_{1} ,x) p( x)\\ \Longrightarrow Q_{2} =\frac{P( v)}{Q_{1}} =\frac{P( y|z_{1} ,z_{2} ,x) P( z_{2} |z_{1} ,x) P( z_{1} |x) P( x)}{P( z_{2} |z_{1} ,x) p( x)} =P( y|z_{1} ,z_{2} ,x) P( z_{1} |x) P(x,z1)P(x,z1,z2)=P(x)Q1⟹Q1=P(x,z1)P(x,z1,z2)P(x)=P(z1∣x)P(z2∣z1,x)P(z1∣x)p(x)=P(z2∣z1,x)p(x)⟹Q2=Q1P(v)=P(z2∣z1,x)p(x)P(y∣z1,z2,x)P(z2∣z1,x)P(z1∣x)P(x)=P(y∣z1,z2,x)P(z1∣x)
于是,我们终于得到干预后的分布:
P x ( v ′ ) = Q 2 ∑ x Q 1 = P ( y ∣ z 1 , z 2 , x ) P ( z 1 ∣ x ) ∑ x ′ P ( z 2 ∣ z 1 , x ′ ) p ( x ′ ) \begin{aligned} P_{x} (v') & =Q_{2}\sum _{x} Q_{1}\\ & =P( y|z_{1} ,z_{2} ,x) P( z_{1} |x)\sum _{x'} P( z_{2} |z_{1} ,x') p( x') \end{aligned} Px(v′)=Q2x∑Q1=P(y∣z1,z2,x)P(z1∣x)x′∑P(z2∣z1,x′)p(x′)
C-components
从上面可以看出,最关键的地方就是分解成 Q 1 , Q 2 \displaystyle Q_{1} ,Q_{2} Q1,Q2的两部分,而这两部分从图上就是不重叠的两个confounder组成的,所以v可以分解为多个component的乘积
p ( v ) = ∏ j = 1 k Q j p( v) =\prod ^{k}_{j=1} Q_{j} p(v)=j=1∏kQj
其中每个Q都对应一组隐变量的confounder的集合 n j \displaystyle n_{j} nj,他们有着重合的孩子 S j \displaystyle S_{j} Sj,于是:
Q j = ∑ n j ∏ { i ∣ V i ∈ S } p ( v I ∣ p a i , u i ) P ( n j ) Q_{j} =\sum _{n_{j}}\prod _{\{i|V_{i} \in S\}} p\left( v_{I} |pa_{i} ,u^{i}\right) P( n_{j}) Qj=nj∑{i∣Vi∈S}∏p(vI∣pai,ui)P(nj)
我们称 S J \displaystyle S_{J} SJ为c-component (confounded component), Q j \displaystyle Q_{j} Qj为c-factor. 最重要的是,我们可以证明,所有的 Q j \displaystyle Q_{j} Qj都是可识别的!,换句话说,如果我们能将干预后的分布变成 Q \displaystyle Q Q的组合,那么干预后的分布就是可识别的了!并且每个 Q \displaystyle Q Q长这样:
Q j = ∏ { i ∣ V i ∈ S } p ( v i ∣ v ( i − 1 ) ) Q_{j} =\prod _{\{i|V_{i} \in S\}} p\left( v_{i} |v^{( i-1)}\right) Qj={i∣Vi∈S}∏p(vi∣v(i−1))
这里 v ( i − 1 ) \displaystyle v^{( i-1)} v(i−1)表示的是在causal order排列下,所有排在 v i \displaystyle v_{i} vi后的变量。显然,如果整个图只有一个 Q \displaystyle Q Q,那么 Q = p ( v 1 ∣ v 2 , . . . v n ) p ( v 2 ∣ v 3 , . . . , v n ) . . . p ( v n ) \displaystyle Q=p( v_{1} |v_{2} ,...v_{n}) p( v_{2} |v_{3} ,...,v_{n}) ...p( v_{n}) Q=p(v1∣v2,...vn)p(v2∣v3,...,vn)...p(vn)就是全概率分解.
那在什么情况下干预的分布可以写成Q的组合呢?论文[1]指出,当且仅当在没有任何双向边将X与X的孩子连起来就足够了。于是这个干预后的分布可以写成:
P x ( v ′ ) = Q x X ∏ i Q i = Q x X p ( v ) Q X = ( i ) ( ∑ x Q X ) p ( v ) Q X P ( v ) = Q X ∏ i Q i \begin{aligned} P_{x} (v') & =Q^{X}_{x}\prod _{i} Q_{i} =Q^{X}_{x}\frac{p( v)}{Q^{X}}\overset{( i)}{=}\left(\sum _{x} Q^{X}\right)\frac{p( v)}{Q^{X}}\\ P(v) & =Q^{X}\prod _{i} Q_{i} \end{aligned} Px(v′)P(v)=QxXi∏Qi=QxXQXp(v)=(i)(x∑QX)QXp(v)=QXi∏Qi
其中 Q X \displaystyle Q^{X} QX是X对应的c-factor,而 Q x X \displaystyle Q^{X}_{x} QxX是把 Q X \displaystyle Q^{X} QX中的 p ( x ∣ p a x , u x ) \displaystyle p\left( x|pa_{x} ,u^{x}\right) p(x∣pax,ux)删掉:
Q x X = ∑ n X ∏ { i ∣ V i ≠ X , V i ∈ S X } p ( v i ∣ p a i , u i ) p ( n X ) Q X = ∑ n X ∏ { i ∣ V i ∈ S X } p ( v i ∣ p a i , u i ) p ( n X ) Q^{X}_{x} =\sum _{n^{X}}\prod _{\{i|V_{i} \neq X,V_{i} \in S^{X} \}} p\left( v_{i} |pa_{i} ,u^{i}\right) p\left( n^{X}\right)\\ Q^{X} =\sum _{n^{X}}\prod _{\{i|V_{i} \in S^{X} \}} p\left( v_{i} |pa_{i} ,u^{i}\right) p\left( n^{X}\right) QxX=nX∑{i∣Vi=X,Vi∈SX}∏p(vi∣pai,ui)p(nX)QX=nX∑{i∣Vi∈SX}∏p(vi∣pai,ui)p(nX)
注意等式 Q x X p ( v ) Q X = ( i ) ( ∑ x Q X ) p ( v ) Q X \displaystyle Q^{X}_{x}\frac{p( v)}{Q^{X}}\overset{( i)}{=}\left(\sum _{x} Q^{X}\right)\frac{p( v)}{Q^{X}} QxXQXp(v)=(i)(x∑QX)QXp(v),右边是只有在没有任何双向边将X与X的孩子连起来的时候才成立,但是左边是恒成立的。所以证明的关键就是等式 Q x X = ( ∑ x Q X ) \displaystyle Q^{X}_{x} =\left(\sum _{x} Q^{X}\right) QxX=(x∑QX)能否成立。事实上,他们的差别就是一个将 p ( x ∣ p a x , u x ) \displaystyle p\left( x|pa_{x} ,u^{x}\right) p(x∣pax,ux)直接删掉,令一个是对x进行求和/积分,那在什么情况下这两个操作的结果是一致的呢?答案是在 Q X \displaystyle Q^{X} QX中,所有的 p ( v i ∣ p a i , u i ) \displaystyle p\left( v_{i} |pa_{i} ,u^{i}\right) p(vi∣pai,ui)里面的 p a i \displaystyle pa_{i} pai都不包括 x \displaystyle x x的时候,对x求和,跟直接删掉 p ( x ∣ p a x , u x ) \displaystyle p\left( x|pa_{x} ,u^{x}\right) p(x∣pax,ux)是等价的。换句话说,如果存在一个confounder连接了X跟X的孩子,使得他们出现在同一个c-conponent Q X \displaystyle Q^{X} QX中,导致其中的某个结点的父亲 p a i \displaystyle pa_{i} pai,出现了 x \displaystyle x x,这时候求和是没法将 p ( x ∣ p a x , u x ) \displaystyle p\left( x|pa_{x} ,u^{x}\right) p(x∣pax,ux)删掉的,从而导致 Q X \displaystyle Q^{X} QX这一项不可识别。这就是证明的直观过程。具体过程,有兴趣自己看[1].
参考资料
Tian J, Pearl J. A general identification condition for causal effects[C]//Aaai/iaai. 2002: 567-573.














 1895
1895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









