







四 HDFS 的数据流
4.1 HDFS 写数据流程
4.1.1 剖析文件写入
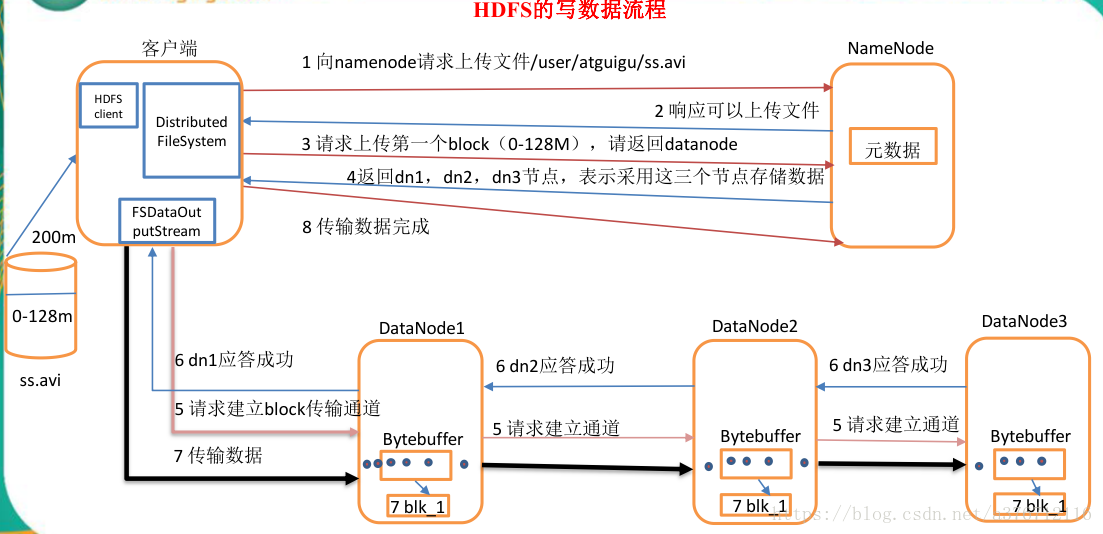
1)客户端通过 Distributed FileSystem 模块向 namenode 请求上传文件,namenode 检查目标
文件是否已存在,父目录是否存在。
2)namenode 返回是否可以上传。
3)客户端请求第一个 block 上传到哪几个 datanode 服务器上。
4)namenode 返回 3 个 datanode 节点,分别为 dn1、dn2、dn3。
5)客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用 dn2,
然后 dn2 调用 dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3 逐级应答客户端。
7)客户端开始往 dn1 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以
packet 为单位,dn1 收到一个 packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet 会放
入一个应答队列等待应答。
8)当一个 block 传输完成之后,客户端再次请求 namenode 上传第二个 block 的服务器。(重
复执行 3-7 步)。
4.1.2 网络拓扑概念
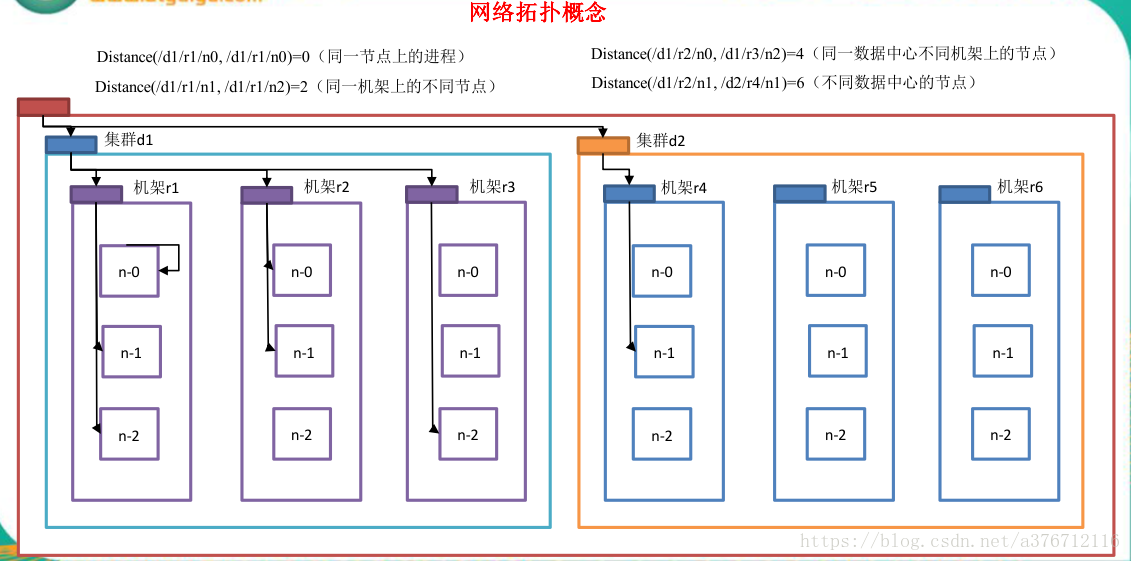
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限
制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为
距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。利用这种
标记,这里给出四种距离描述。
4.1.3 机架感知(副本节点选择)
1)官方 ip 地址:
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/RackAwareness.ht
ml
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Dat a_Replication
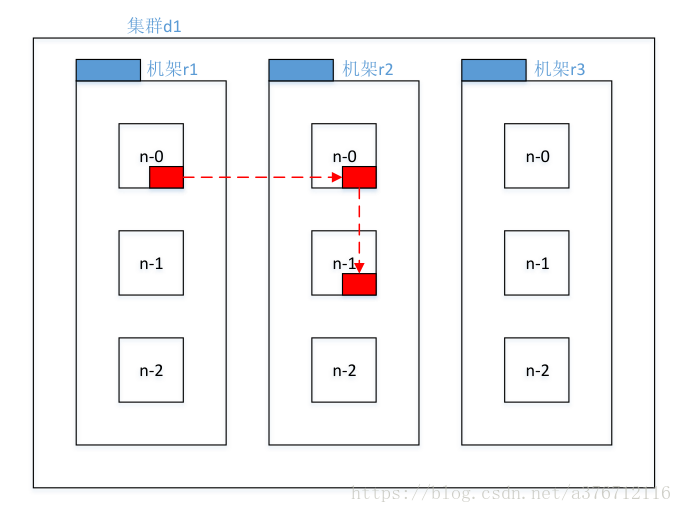
2)低版本 Hadoop 副本节点选择
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于不相同机架的随机节点上。
第三个副本和第二个副本位于相同机架,节点随机。
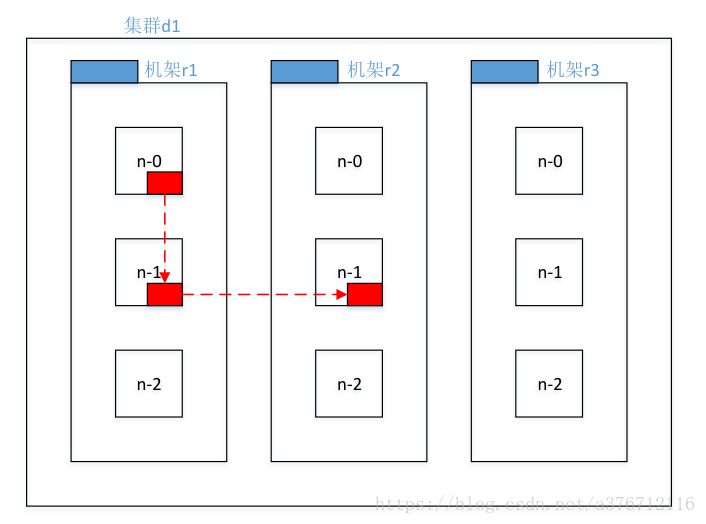
3)Hadoop2.7.2 副本节点选择
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
4)HDFS 如何控制客户端读取哪个副本节点数据
HDFS 满足客户端访问副本数据的最近原则。即客户端距离哪个副本数据最近,HDFS
就让哪个节点把数据给客户端。
4.2 HDFS 读数据流程
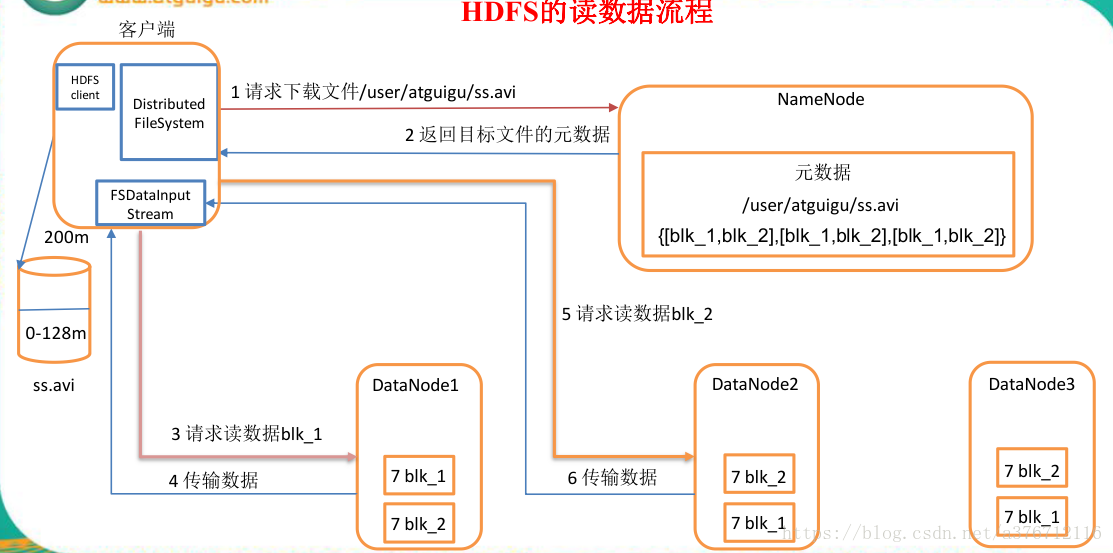
1)客户端通过 Distributed FileSystem 向 namenode 请求下载文件,namenode 通过查询元数
据,找到文件块所在的 datanode 地址。
2)挑选一台 datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 packet 为单位来做校
验)。
4)客户端以 packet 为单位接收,先在本地缓存,然后写入目标文件。
4.3 一致性模型
1)debug 调试如下代码
// 向 HDFS 上写数据
@Test
publicvoidwriteFile()throwsIOException,InterruptedException,
URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");
// 2 获取输出流
FSDataOutputStream fos = fs.create(new Path("/hello.txt"));
// 3 写数据 fos.write("hello".getBytes());
// 4 一致性刷新 fos.hflush();
// 5 关闭资源
fos.close();
fs.close();
}
2)总结
写入数据时,如果希望数据被其他 client 立即可见,调用如下方法
FsDataOutputStream. hflush (); //清理客户端缓冲区数据,被其他 client 立即可见
五 NameNode 工作机制
5.1 NameNode&Secondary NameNode 工作机制
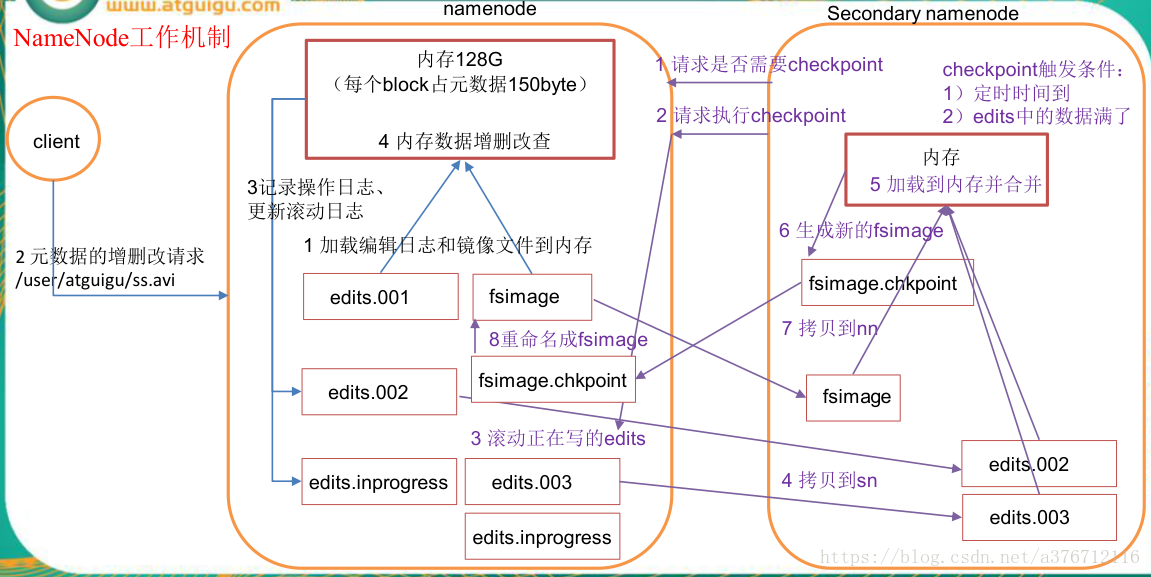
1)第一阶段:namenode 启动
(1)第一次启动 namenode 格式化后,创建 fsimage 和 edits 文件。如果不是第一次启
动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)namenode 记录操作日志,更新滚动日志。
(4)namenode 在内存中对数据进行增删改查。
2)第二阶段:Secondary NameNode 工作
(1)Secondary NameNode 询问 namenode 是否需要 checkpoint。直接带回 namenode 是
否检查结果。
(2)Secondary NameNode 请求执行 checkpoint。
(3)namenode 滚动正在写的 edits 日志。
(4)将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
(5)Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件 fsimage.chkpoint。
(7)拷贝 fsimage.chkpoint 到 namenode。
(8)namenode 将 fsimage.chkpoint 重新命名成 fsimage。
5.2 镜像文件和编辑日志文件
1)概念
namenode 被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current 目录中
产生如下文件
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
(1)Fsimage 文件:HDFS 文件系统元数据的一个永久性的检查点,其中包含 HDFS
文件系统的所有目录和文件 idnode 的序列化信息。
(2)Edits 文件:存放 HDFS 文件系统的所有更新操作的路径,文件系统客户端执行
的所有写操作首先会被记录到 edits 文件中。
(3)seen_txid 文件保存的是一个数字,就是最后一个 edits_的数字
(4)每次 Namenode 启动的时候都会将 fsimage 文件读入内存,并从 00001 开始到 seen_txid 中记录的数字依次执行每个 edits 里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成 Namenode 启动的时候就将 fsimage 和 edits 文件进行了合并。
2)oiv 查看 fsimage 文件
(1)查看 oiv 和 oev 命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file(2)基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径(3)案例实操
[atguigu@hadoop102 current]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current
[atguigu@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/fsimage.xml将显示的 xml 文件内容拷贝到 eclipse 中创建的 xml 文件中,并格式化。部分显示
结果如下。
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id>
<type>DIRECTORY</type>
<name>atguigu</name>
<mtime>1512790549080</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16389</id>
<type>FILE</type>
<name>wc.input</name>
<replication>3</replication>
<mtime>1512722322219</mtime>
<atime>1512722321610</atime>
<perferredBlockSize>134217728</perferredBlockSize>
<permission>atguigu:supergroup:rw-r--r--</permission>
<blocks>
<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>59</numBytes>
</block>
</blocks>
</inode>3)oev 查看 edits 文件
(1)基本语法
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径(2)案例实操
[atguigu@hadoop102 current]$ hdfs oev -p XML -i
edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-2.7.2/edits.xml将显示的 xml 文件内容拷贝到 eclipse 中创建的 xml 文件中,并格式化。显示结果
如下。
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA>
<TXID>129</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD</OPCODE>
<DATA>
<TXID>130</TXID>
<LENGTH>0</LENGTH>
<INODEID>16407</INODEID>
<PATH>/hello7.txt</PATH>
<REPLICATION>2</REPLICATION>
<MTIME>1512943607866</MTIME>
<ATIME>1512943607866</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-1544295051_1</CLIENT_ NAME>
<CLIENT_MACHINE>192.168.1.5</CLIENT_MACHINE> <OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS> <USERNAME>atguigu</USERNAME> <GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
<RPC_CLIENTID>908eafd4-9aec-4288-96f1-e8011d181561</RPC_CLIENTID> <RPC_CALLID>0</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>131</TXID>
<BLOCK_ID>1073741839</BLOCK_ID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>132</TXID>
<GENSTAMPV2>1016</GENSTAMPV2>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
<DATA>
<TXID>133</TXID>
<PATH>/hello7.txt</PATH>
<BLOCK>
<BLOCK_ID>1073741839</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1016</GENSTAMP>
</BLOCK>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
<DATA>
<TXID>134</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/hello7.txt</PATH>
<REPLICATION>2</REPLICATION>
<MTIME>1512943608761</MTIME>
<ATIME>1512943607866</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME></CLIENT_NAME>
<CLIENT_MACHINE></CLIENT_MACHINE>
<OVERWRITE>false</OVERWRITE>
<BLOCK>
<BLOCK_ID>1073741839</BLOCK_ID>
<NUM_BYTES>25</NUM_BYTES>
<GENSTAMP>1016</GENSTAMP>
</BLOCK>
<PERMISSION_STATUS> <USERNAME>atguigu</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS>5.3 滚动编辑日志
正常情况 HDFS 文件系统有更新操作时,就会滚动编辑日志。也可以用命令强制滚动
编辑日志。
1)滚动编辑日志(前提必须启动集群)
[atguigu@hadoop102 current]$ hdfs dfsadmin -rollEdits2)镜像文件什么时候产生
Namenode 启动时加载镜像文件和编辑日志
5.4 Namenode 版本号
1)查看 namenode 版本号
在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current 这个目录下查看 VERSION
namespaceID=1933630176
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
storageType=NAME_NODE
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-63
2)namenode 版本号具体解释
(1) namespaceID 在 HDFS 上,会有多个 Namenode,所以不同 Namenode 的
namespaceID 是不同的,分别管理一组 blockpoolID。
(2)clusterID 集群 id,全局唯一
(3)cTime 属性标记了 namenode 存储系统的创建时间,对于刚刚格式化的存储系统,
这个属性为 0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)storageType 属性说明该存储目录包含的是 namenode 的数据结构。
(5)blockpoolID:一个 block pool id 标识一个 block pool,并且是跨集群的全局
唯一。当一个新的 Namespace 被创建的时候(format 过程的一部分)会创建并持久化一个
唯一 ID。在创建过程构建全局唯一的 BlockPoolID 比人为的配置更可靠一些。NN 将
BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次 load 并使用。
(6)layoutVersion 是一个负整数。通常只有 HDFS 增加新特性时才会更新这个版本
号。
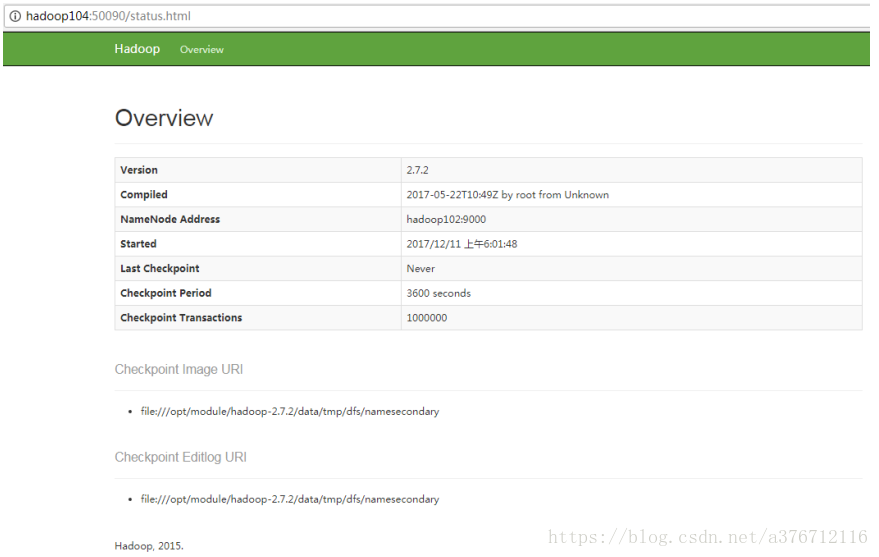
5.5 web 端访问 SecondaryNameNode 端口号
(1)启动集群。
(2)浏览器中输入:http://hadoop104:50090/status.html
(3)查看 SecondaryNameNode 信息。
5.6 chkpoint 检查时间参数设置
(1)通常情况下,SecondaryNameNode 每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>(2)一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode 执行
一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1 分钟检查一次操作次数</description> </property>5.7 SecondaryNameNode 目录结构
Secondary NameNode 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS
元数据的快照。
在 /opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/current 这 个 目 录 中 查 看
SecondaryNameNode 目录结构。
edits_0000000000000000001-0000000000000000002
fsimage_0000000000000000002
fsimage_0000000000000000002.md5
VERSION
SecondaryNameNode 的 namesecondary/current 目录和主 namenode 的 current 目录的布局
相同。
好处:在主 namenode 发 生 故 障时 (假设没有及时备份数据),可 以 从 SecondaryNameNode 恢复数据。
5.8 Namenode 故障处理方法
Namenode 故障后,可以采用如下两种方法恢复数据。
方法一:将 SecondaryNameNode 中数据拷贝到 namenode 存储数据的目录;
方法二:使 用 -importCheckpoint 选 项 启 动 namenode 守 护 进 程 , 从 而 将
SecondaryNameNode 中数据拷贝到 namenode 目录中。
5.8.1 手动拷贝 SecondaryNameNode 数据:
模拟 namenode 故障,并采用方法一,恢复 namenode 数据
1)kill -9 namenode 进程
2)删除 namenode 存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[atguigu@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* 3)拷贝 SecondaryNameNode 中数据到原 namenode 存储数据目录
[atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/4)重新启动 namenode
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode5.8.2 采用 importCheckpoint 命令拷贝 SecondaryNameNode 数据
模拟 namenode 故障,并采用方法二,恢复 namenode 数据
0)修改 hdfs-site.xml 中的
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>1)kill -9 namenode 进程
2)删除 namenode 存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[atguigu@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*3 )如果SecondaryNameNode不和Namenode在一个主机节点上,需要将SecondaryNameNode 存储数据的目录拷贝到 Namenode 存储数据的平级目录,并删除in_use.lock 文件。
[atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
[atguigu@hadoop102 namesecondary]$ rm -rf in_use.lock
[atguigu@hadoop102 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[atguigu@hadoop102 dfs]$ ls
data name namesecondary4)导入检查点数据(等待一会 ctrl+c 结束掉)
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint5)启动 namenode
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode5.9 集群安全模式操作
1)概述
Namenode 启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中
的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的 fsimage 文件
和一个空的编辑日志。此时,namenode 开始监听 datanode 请求。但是此刻,namenode 运行
在安全模式,即 namenode 的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由 namenode 维护的,而是以块列表的形式存储在
datanode 中。在系统的正常操作期间,namenode 会在内存中保留所有块位置的映射信息。
在安全模式下,各个 datanode 会向 namenode 发送最新的块列表信息,namenode 了解到足
够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,namenode 会在 30 秒钟之后就退出安全模式。所谓的最小副
本 条件指的是在整个文件系统中 99.9% 的块满足最小 副 本 级别 (默 认 值:
dfs.replication.min=1)。在启动一个刚刚格式化的 HDFS 集群时,因为系统中还没有任何块,
所以 namenode 不会进入安全模式。
2)基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模
式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
3)案例
模拟等待安全模式
1)先进入安全模式
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode enter2)执行下面的脚本
编辑一个脚本
#!/bin/bash
bin/hdfs dfsadmin -safemode wait
bin/hdfs dfs -put ~/hello.txt /root/hello.txt3)再打开一个窗口,执行
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode leave5.10 Namenode 多目录配置
1)namenode 的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
2)具体配置如下:
(1)在 hdfs-site.xml 文件中增加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</v alue>
</property>(2)停止集群,删除 data 和 logs 中所有数据。
[atguigu@hadoop102 hadoop-2.7.2]$ rm -rf data/ logs/
[atguigu@hadoop103 hadoop-2.7.2]$ rm -rf data/ logs/
[atguigu@hadoop104 hadoop-2.7.2]$ rm -rf data/ logs/(3)格式化集群并启动。
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode –format
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh (4)查看结果
[atguigu@hadoop102 dfs]$ ll总用量 12
drwx——. 3 atguigu atguigu 4096 12 月 11 08:03 data
drwxrwxr-x. 3 atguigu atguigu 4096 12 月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12 月 11 08:03 name2














 6816
6816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









