






说来惭愧,学习前端有一段时间了,但是对浏览器一直是一知半解。今天刚好看到一篇文章,解决了我对浏览器的许多疑惑,就赶紧写一篇文章记下来,免得自己忘记了。
目前有五大主流浏览器:IE , chrome, firefox, opera,Safari
浏览器的功能主要是:展现网页资源,即向服务器发出请求,然后把请求的资源展现在浏览器窗口中。这里的浏览器资源一般是HTML文件,也可以是其他累类型,pdf等
说到这,弱弱问一句,有听过浏览器上层结构这几个名词吗?如果没有,恭喜你,找到组织了。
浏览器上层结构
● 用户接口– 包括地址栏,前进后退,书签菜单等。总之就是窗口上除了网页显示区域以外的部分。
● 浏览器引擎 – 查询与操作渲染引擎的接口。
● 渲染引擎 – 负责显示请求的内容。比如请求到HTML, 它会负责解析HTML 与 CSS 并将结果显示到窗口
● 网络 – 用于网络请求, 如HTTP请求。它包括平台无关的接口和各平台独立的实现。
● UI后端 – 绘制基础元件,如组合框与窗口。它提供平台无关的接口,内部使用操作系统的
● JavaScript解释器。用于解析执行JavaScript代码。
● 数据存储。这是一个持久层。浏览器需要把所有数据存到硬盘上,如cookies。新的HTML规范 (HTML5) 规定了一个完整(虽然轻量级)的浏览器中的数据库:’web database’。

注意:渲染是个大的概念,它的实现要依靠网络,UI后端和JavaScript解释器三者的协调合作
渲染引擎的目的是把请求到的网页资源展示出来。
首先明确渲染引擎有两种:一种是Mozilla公司自家的Gecko,一种是Safari和chrome使用的webkit。
渲染引擎的流程:
渲染引擎开始于从网络层获取请求内容,一般是不超过8K的数据块。接下来就是渲染引擎的基本工作流程

● 渲染引擎会解析HTML文档并把标签转换成内容树中的DOM节点。同时,它会解析style元素和外部文件中的样式数据。样式数据和HTML中 的显示属性将共同用来创建另一棵树——渲染树。
● 渲染树包含带有颜色,尺寸等显示属性的矩形。这些矩形的顺序与显示顺序一致。
● 渲染树构建完成后就是布局处理,也就是确定每个节点在屏幕上的确切显示位置。
● 接着是绘制—— 遍历渲染树并用UI后端层将每一个节点绘制出来。
一定要理解这是一个缓慢的过程,为了更好的用户体验,渲染引擎会尝试尽快的把内容显示出来。它不会等到所有HTML都被解析完才创建并布局渲染树。它会 在处理后续内容的同时把处理过的局部内容先展示出来。
主要流程示例

图3 webkit流程

图4 Mozilla的Gecko渲染引擎主要流程
以下将详细讲述每一步:解析+布局+绘制
解析器——词法分析器组合
解析器有两个处理过程——词法分析与句法分析。
词法分析负责把输入切分成符号序列,符号是语言的词汇——由该语言所有合法的单词组成。
句法分析是对该语言句法法则的应用。
解析器通常把工作分给两个组件——分词程序负责把输入切分成合法符号序列,解析程序负责按照句法规则分析文档结构和构建句法树。词法分析器知道如何过滤像空格,换行之类的无关字符。
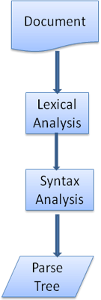
图 6:从源文档到解析树(文档,词法分析,句法分析,解析树)。
解析过程是交互式的。解析器通常会从词法分析器获取新符号并尝试匹配句法规则。如果匹配成功,就在句法树上创建相应的节点,并继续从词法分析器获取下一个符号。如果没有匹配的规则,解析器会内部保存这个符号,并继续从词法分析器获取符号,直到内部保存的所有符号能够成功匹配一个规则。如果最终无法匹配,解析器会抛出异常。这意味着文档无效,含有句法错误。
(好好理解对立即html的解析有帮助)
HTML解析器
HTML解析器的工作是解析HTML标记到解析树。
HTML DTD
HTML的定义使用DTD文件。这种格式用来定义SGML族语言,它包含对所有允许的元素的定义,包括它们的属性和层级关系。如我们前面所说,HTML DTD构不成上下文无关语法。
DTD有几种不同类型。严格模式完全尊守规范,但其它模式为了向前兼容可能包含对早期浏览器所用标签的支持。当前的严格模式DTD:http://www.w3.org/TR/html4/strict.dtd
DOM
解析器输出的树是由DOM元素和属性节点组成的。DOM的全称为:Document Object Model。它是HTML文档的对象化描述,也是HTML元素与外界(如Javascript)的接口。
DOM与标签几乎有着一一对应的关系,如下面的标签
<html> <body> <p> Hello World </p> <div> <img src="example.png"/></div> </body> </html>
会被转换成如的DOM树:
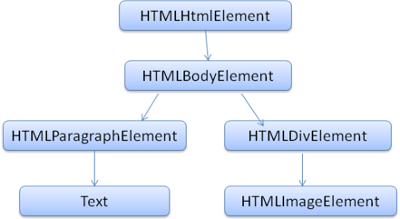
图5: DOM树生成例子
当我们说树中包含DOM节点时,意思就是这个树是由实现了DOM接口的元素组成。这些实现包含了其它一些浏览器内部所需的属性。
解析算法
如我们前面看到的,HTML无法使用自上而下或自下而上的解析器来解析。
理由如下:
- 语言的宽容特点
- 浏览器需要对无效HTML提供容错性的事实。
- 解析过程的反复。通常解析过程中源码不会变化。但在HTML中,script标签包含”document.write”时可以添加内容,即解析过程实际上还会改变源码。
浏览器创建了自己的解析器来解析HTML文档。
HTML5规范里对解析算法有具体的说明,解析由两部分组成:分词与构建树。
分词属于词法分析部分,它把输入解析成符号序列。在HTML中符号就是开始标签,结束标签,属性名称和属生值。
分词器识别这些符号并将其送入树构建者,然后继续分析处理下一个符号,直到输入结束。
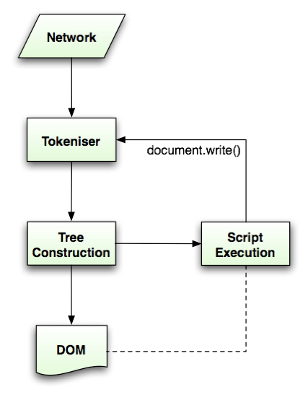
图 6: HTML解析流程 (源自HTML5规范)
分词算法
算法的输出是HTML符号。算法可以用状态机来描述。 每一个状态从输入流中消费一个或多个字符,并根据它们更新下一状态。决策受当前符号状态和树的构建状态影响。这意味着同样的字符可能会产生不同的结果,取决于当前的状态。算法太复杂,我们用一个例子来看看它的原理。
基础示例,分析下面的标签:
<html> <body> Hello world </body> </html>
初始状态是”Data state”,当遇到”<“时状态改为“Tag open state”。吃掉”a-z”字符组成的符号后产生了”Start tag token”,状态变更为“Tag name state”。我们一直保持此状态,直到遇到”>”。每个字符都被追加到新的符号名上。在我们的例子中,解出的符号就是”html”。
当碰到”>”时,当前符号完成,状态改回“Data state”。”<body>”标签将会以同样的方式处理。现在”html”与”body”标签都完成了,我们回到“Data state”状态。吃掉”H”(”Hello world”第一个字母)时会产生一个字符符号,直到碰到”</body>”的”<“符号,我们就完成了一个字符符号”Hello world”。
现在我们回到“Tag open state”状态。吃掉下一个输入”/”时会产生一个”end tag token”并变更为“Tag name state”状态。同样,此状态保持到我们碰到”>”时。这时新标签符号完成,我们又回到“Data state”。同样”</html>”也会被这样处理。
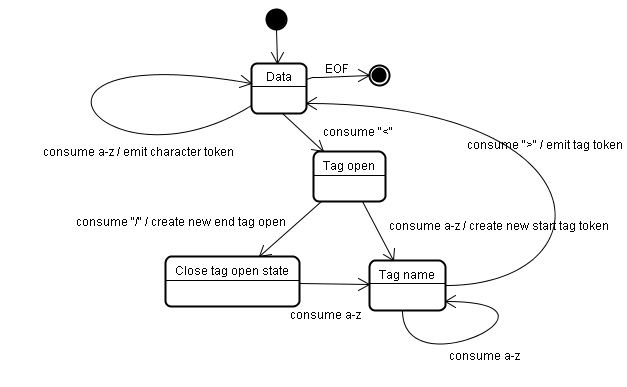
图 9: 示例输入源的分词处理
树的构建算法
当解析器被创建时,文档对象也被创建了。在树的构建过程中DOM树的根节点(Documen)将被修改,元素被添加到上面去。每个分词器完成的节点都会被树构建器处理。规范中定义了每一个符号与哪个DOM对象相关。除了把元素添加到DOM树外,它还会被添加到一个开放元素堆栈。这个堆栈用于纠正嵌套错误和标签未关闭错误。这个算法也用状态机描述,它的状态叫做”insertion modes”。
让我们看看下面输入的树构建过程:
<html> <body> Hello world </body> </html>
树的构建过程中,输入就是分词过程中得到的符号序列。第一个模式叫“initial mode”。接收 html 符号后会变成“before html”模式并重新处理此模式中的符号。这会创建一个HTMLHtmlElement元素并追加到根文档节点。
然后状态改变为“before head”。我们收到”body”时,会隐式创建一个HTMLHeadElement,尽管我们没有这个标签,它也会被创建并添加到树中。
现在我们进入“in head”模式,然后是“after head”,Body会被重新处理,创建HTMLBodyElement元素并插入,然后进入“in body”模式。
字符符号”Hello world”收到后会创建一个”Text”节点,所有字符都被一一追加到上面。
收到body结束标签后进入 “after body” 模式,收到html结束标签后进入“after after body”模式。所有符号处理完后将终止解析。
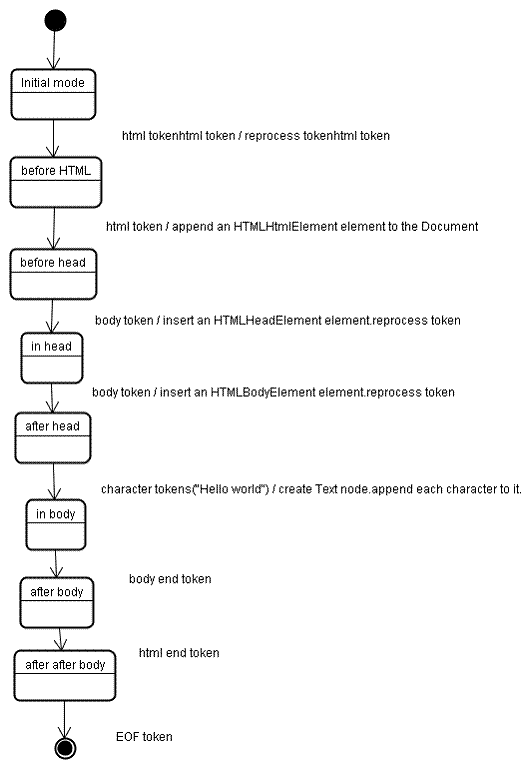
图 10: 示例HTML树的构建
解析结束后的动作
在这一阶段浏览器会把文档标记为交互模式,并开始解析deferred模式的script。”deferred”意味着脚本应该在文档解析完成后执行。脚本处理完成后将进入”complete”状态,”load”事件发生。
未完待续。。。
参考文献:http://taligarsiel.com/Projects/howbrowserswork1.htm
转载自:携程设计委员会















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









