







【例】给定4个叶子结点a,b,c和d,分别带权7,5,2和4。构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:
(a)WPL=7*2+5*2+2*2+4*2=36
(b)WPL=7*3+5*3+2*1+4*2=46
(c)WPL=7*1+5*2+2*3+4*3=35
其中(c)树的WPL最小,可以验证,它就是哈夫曼树。

构造哈夫曼树的算法如下:
1)对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F={T1,T2,T3,...,Ti,..., Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。
2)在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
3)从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
4)重复2)和3),直到集合F中只有一棵二叉树为止。
例如,对于4个权值为1、3、5、7的节点构造一棵哈夫曼树,其构造过程如下图所示:
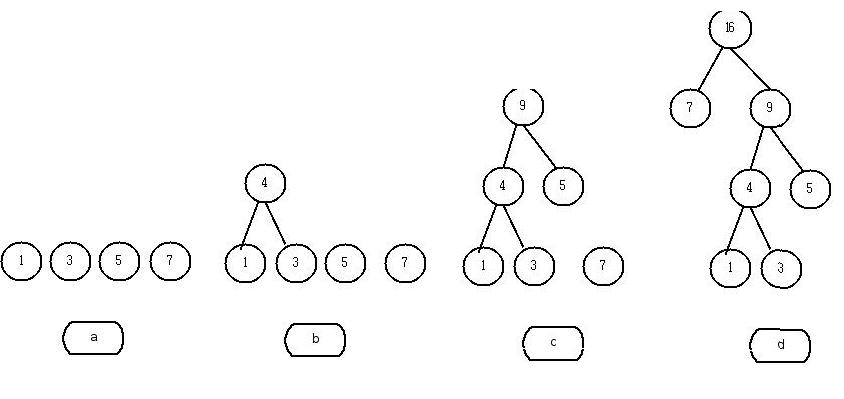
可以计算得到该哈夫曼树的路径长度WPL=(1+3)*3+2*5+1*7=26。
哈夫曼编码应用
大数据量的图像信息会给存储器的存储容量,通信干线信道的带宽,以及计算机的处理速度增加极大的压力。单纯靠增加存储器容量,提高信道带宽以及计算机的处理速度等方法来解决这个问题是不现实的,这时就要考虑压缩。压缩的关键在于编码,如果在对数据进行编码时,对于常见的数据,编码器输出较短的码字;而对于少见的数据则用较长的码字表示,就能够实现压缩。
【例】:假设一个文件中出现了8种符号S0,SQ,S2,S3,S4,S5,S6,S7,那么每种符号要编码,至少需要3bit。假设编码成 000,001, 010,011,100,101,110,111。那么符号序列S0S1S7S0S1S6S2S2S3S4S5S0S0S1编码后变成 000001111000001110010010011100101000000001,共用了42bit。我们发现S0,S1,S2这3个符号出现的频率比较大,其它符号出现的频率比较小,我们采用这样的编码方案:S0到S7的码辽分别01,11,101,0000,0001,0010,0011, 100,那么上述符号序列变成011110001110011101101000000010010010111,共用了39bit。尽管有些码字如 S3,S4,S5,S6变长了(由3位变成4位),但使用频繁的几个码字如S0,S1变短了,所以实现了压缩。对于上述的编码可能导致解码出现非单值性:比如说,如果S0的码字为01,S2的码字为011,那么当序列中出现011时,你不知道是S0的码字后面跟了个1,还是完整的一个S2的码字。因此,编码必须保证较短的编码决不能是较长编码的前缀。符合这种要求的编码称之为前缀编码。要构造符合这样的二进制编码体系,可以通过二叉树来实现。
以下是哈夫曼树的java实现:
package demo1.client;
import java.util.*;
/**
* 二叉树节点
*/
class Node implements Comparable {
private int value;
private Node leftChild;
private Node rightChild;
public Node(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public Node getLeftChild() {
return leftChild;
}
public void setLeftChild(Node leftChild) {
this.leftChild = leftChild;
}
public Node getRightChild() {
return rightChild;
}
public void setRightChild(Node rightChild) {
this.rightChild = rightChild;
}
public int compareTo(Object o) {
Node that = (Node) o;
double result = this.value - that.value;
return result > 0 ? 1 : result == 0 ? 0 : -1;
}
}
/**
* 哈夫曼树构造类:
*/
public class HuffmanTreeBuilder {
public static void main(String[] args) {
List<Node> nodes = Arrays.asList(
new Node(1),
new Node(3),
new Node(5),
new Node(7)
);
Node node = HuffmanTreeBuilder.build(nodes);
PrintTree(node);
}
/**
* 构造哈夫曼树
* @param nodes 结点集合
* @return 构造出来的树的根结点
*/
private static Node build(List<Node> nodes) {
nodes = new ArrayList<Node>(nodes);
sortList(nodes);
while (nodes.size() > 1) {
createAndReplace(nodes);
}
return nodes.get(0);
}
/**
* 组合两个权值最小结点,并在结点列表中用它们的父结点替换它们
* @param nodes 结点集合
*/
private static void createAndReplace(List<Node> nodes) {
Node left = nodes.get(0);
Node right = nodes.get(1);
Node parent = new Node(left.getValue() + right.getValue());
parent.setLeftChild(left);
parent.setRightChild(right);
nodes.remove(0);
nodes.remove(0);
nodes.add(parent);
sortList(nodes);
}
/**
* 将结点集合由大到小排序
*/
private static void sortList(List<Node> nodes) {
Collections.sort(nodes);
}
/**
* 打印树结构,显示的格式是node(left,right)
* @param node
*/
public static void PrintTree(Node node)
{
Node left = null;
Node right = null;
if(node!=null)
{
System.out.print(node.getValue());
left = node.getLeftChild();
right = node.getRightChild();
System.out.println("("+(left!=null?left.getValue():" ") +","+ (right!= null?right.getValue():" ")+")");
}
if(left!=null)
PrintTree(left);
if(right!=null)
PrintTree(right);
}
}















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









