







分层数据
- 分层数据的每项(除根项)只有一个父项和零个或多个子项的数据集合。
- 分层数据存在于许多基于数据库的应用程序中,包括论文和邮件列表中的分类、组织层级关系、内容管理系统的分类、产品分类。
邻接表模型
数据库中结构:
+--------+----------------------+--------------+
| id | name | parent_id |
+-------------+-----------------+--------------+
| 1 | 智慧学校 | NULL |
| 2 | 广东省教育厅 | 1 |
| 3 | 广州市教育厅 | 2 |
| 4 | 东莞市教育厅 | 2 |
| 5 | 佛山市教育厅 | 2 |
| 6 | 荔湾区华侨小学 | 3 |
| 7 | 湖南省教育厅 | 1 |
| 8 | 长沙市教育厅 | 7 |
| 9 | 湘潭市教育厅 | 7 |
| 10 | 张家界市教育厅 | 7 |
+-------------+----------------------+--------+优点:
实现简单,能直观看到直接父子关系。
缺点:
当要检索某节点下所有子孙节点时,只能一层一层递归查询。
orcal中实现子孙节点查找:
SELECT * FROM unit t CONNECT BY prior t.parent_id=t.id start with t.parent_id = 1
mysql使用函数实现(使用函数形式):
CREATE FUNCTION getChildLst(id INT)
RETURNS varchar(1000) CHARSET utf8
BEGIN
DECLARE sTemp VARCHAR(1000);
DECLARE sTempChd VARCHAR(1000);
SET sTemp = '$';
SET sTempChd =cast(rootId as CHAR);
WHILE sTempChd is not null DO
SET sTemp = concat(sTemp,',',sTempChd);
SELECT group_concat(id) INTO sTempChd FROM emp where FIND_IN_SET(parentId,sTempChd)>0;
END WHILE;
RETURN substr(sTemp,3);
END看上面的语句是全表扫描,没有走索引。一些数据量比较大的表,查询就很慢。
前缀编码模型
数据库结构
+-------------+-----------------+--------+
| id | name | code |
+--------+----------------------+--------+
| 1 | Seewo智慧学校 | 001 |
| 2 | 广东省教育厅 | 001001 |
| 3 | 广州市教育厅 | 001001001 |
| 4 | 东莞市教育厅 | 001001002 |
| 5 | 佛山市教育厅 | 001001003 |
| 6 | 荔湾区华侨小学 | 001001001001 |
| 7 | 湖南省教育厅 | 001002 |
| 8 | 长沙市教育厅 | 001002001 |
| 9 | 湘潭市教育厅 | 001002002 |
| 10 | 张家界市教育厅 | 001002003 |
+-------------+----------------------+--------+节点编码:为当前记录行的编码(内部编码),它的所有直接下级记录行的编码都是以它为依据进行扩展。
优点:
使用like语句即可查出其所有子孙节点的记录集。
缺点:
固定长度编码限制了子节点的个数,层级不明显,查询直系亲属节点麻烦。
每层的节点个数受编码长度限制
改进的前缀编码模型
数据库结构
+--------+------------------+----------------+--------------+--------------+
| id | name | parent_id | code | childMaxNum |
+--------+------------------+----------------+--------------+--------------+
| 1 | Seewo智慧学校 | NULL | 1. | 2 |
| 2 | 广东省教育厅 | 1 | 1.1. | 3 |
| 3 | 广州市教育厅 | 2 | 1.1.1. | 1 |
| 4 | 东莞市教育厅 | 2 | 1.1.2. | 0 |
| 5 | 佛山市教育厅 | 2 | 1.1.3. | 0 |
| 6 | 荔湾区华侨小学 | 3 | 1.1.1.1. | 0 |
| 7 | 湖南省教育厅 | 1 | 1.2. | 3 |
| 8 | 长沙市教育厅 | 7 | 1.2.1. | 0 |
| 9 | 湘潭市教育厅 | 7 | 1.2.2. | 0 |
| 10 | 张家界市教育厅 | 7 | 1.2.3. | 0 |
+--------+-------------------+---------------+--------------+--------------+改进的前缀编码模型中添加了直系父节点id的parent_id,和当前子节点分配最大数childMaxNum(记录了当前已分配的数字),前缀编码code使用特殊符号区分节点的层次。
查找子孙节点sql:
select * from unit where code like ‘1.1.%’
嵌套集合模型
模型图:
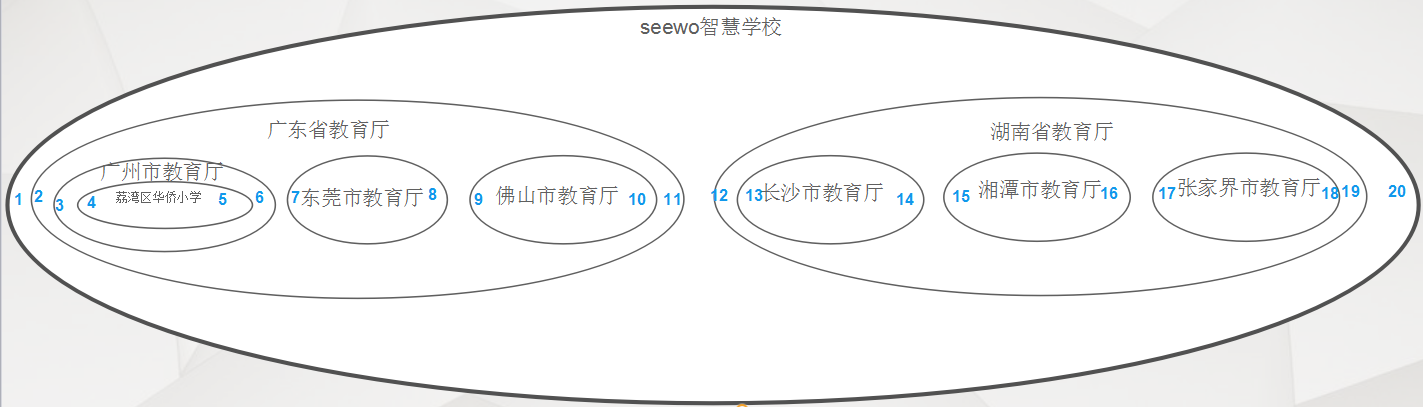
使用左值和右值来表现嵌套集合模型中数据的分层特性。
优点:
所有子孙节点的左右值都在父节点的左右值范围内,能快速查找出一棵子树,且能快速判断是否含有子节点。
缺点:
1、当增加删除一个节点时,需要更新其他节点的左右值。
2、层级不明显。
二叉树模型
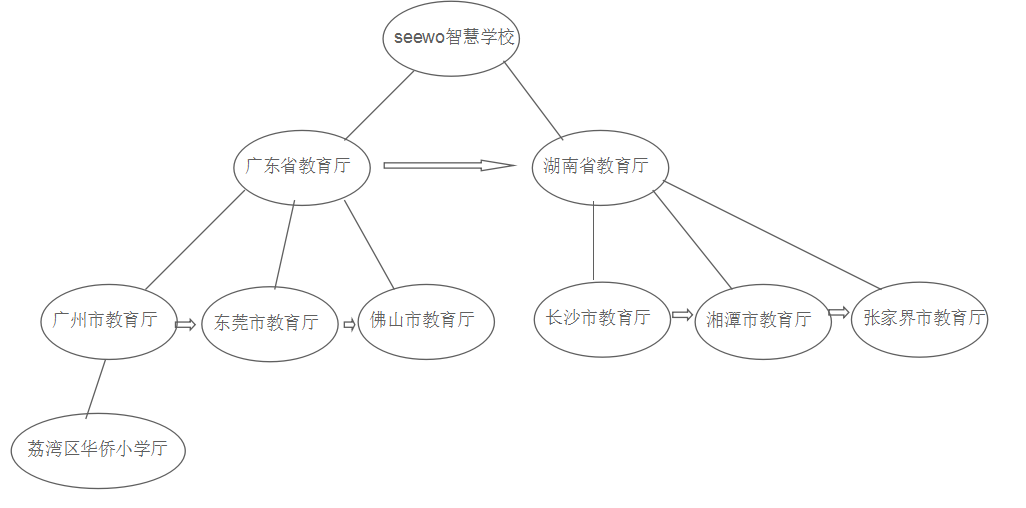
把这种层级结构变换为二叉树模型,变换规则,某节点A的左边第一个子节点B作为A左子节点,B右边第一个兄弟节点C作为B的右子节点,如果C右边还有兄弟节点D,则把D作为C的右子节点,如此类推。最后变换为下图:
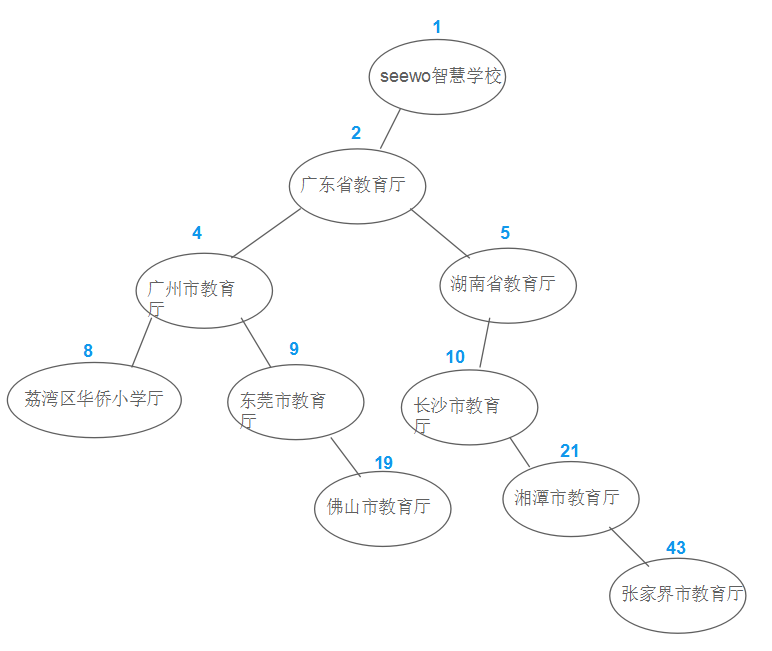
每个节点的编码以一维数组存放二叉树的方式进行编码
+-------------+-----------------+----------+
| id | name | location |
+--------+----------------------+----------+
| 1 | Seewo智慧学校 | 1 |
| 2 | 广东省教育厅 | 2 |
| 3 | 广州市教育厅 | 4 |
| 4 | 东莞市教育厅 | 9 |
| 5 | 佛山市教育厅 | 19 |
| 6 | 荔湾区华侨小学 | 8 |
| 7 | 湖南省教育厅 | 5 |
| 8 | 长沙市教育厅 | 10 |
| 9 | 湘潭市教育厅 | 21 |
| 10 | 张家界市教育厅 | 43 |
+-------------+-----------------+---------+MongoDB实现
使用非关系型数据库优点可以快速的查找
{ id:"1", name:"Seewo智慧学校", ancestors:[], parent:null }
{ id:"2", name:"广东省教育厅", ancestors:["1"], parent:"1" }
{ id:"3", name:"广州市教育厅 ", ancestors:["1","2"], parent:"2" }
{ id:"4", name:"东莞市教育厅", ancestors:["1","2"], parent:"2" }
{ id:"5", name:"佛山市教育厅", ancestors:["1","2"], parent:"2" }
{ id:"6", name:"荔湾区华侨小学", ancestors:["1","2","3"], parent:"3" }
{ id:"7", name:"湖南省教育厅", ancestors:["1"], parent:"1" }
{ id:"8", name:"长沙市教育厅", ancestors:["1","8"], parent:"7" }
{ id:"9", name:"湘潭市教育厅", ancestors:["1","8"], parent:"7" }
{ id:"10", name:"张家界市教育厅", ancestors:["1","8"], parent:"7" }查找id=1的所有子孙节点:find({ancestors:”1”})














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









