







文章向导
从单链表到循环链表
引入多态的特性简化实现
创建一个循环链表
合并两个任意长度循环链表
完整实例,验证成果。
一、从单链表到循环链表
对于一般的单链表,假设我们正处于表中的某一个节点,并想以此为起点来遍历整个链表。但显然这是无法做到的,我们只能从头节点再次重新开始遍历。
于是,循环链表也就应运而生,从而填补这种从单链表中任一节点开始遍历整个链表的需求。下图就是一个实际的循环链表结构:

从图中我们可以明确的发现,此时用指向终端节点的尾指针来表示整个循环链表,而终端节点的指针则指向头节点(其实头节点对于循环链表也不是必需的,但通常我们都会设定一个头节点。)
二、引入多态特性简化实现
在这一部分我们主要设计循环链表所要用到抽象数据类型,那么是否所有的数据组织和接口都要重头开始设计呢? 答案是否定的,因为我们可以利用之前单链表就已经实现好接口和数据组织来进一步定义循环链表,从而简化实际的开发工作。
而这种做法也被称之为多态(面向对象语言中的一种特性),它允许某种类型的对象(变量)在使用时可用其他类型的对象(变量)代替。这就意味着我们除了可以使用循环链表本身的操作外,还可以使用单链表中的操作。
点此查看list.h
/*循环链表抽象数据类型*/
#ifndef CLIST_H
#define CLIST_H
#include <stdlib.h>
#include "list.h"
typedef ListNode ClistNode; //多态
typedef ListMsg ClistMsg; //多态
/*Public Interface*/
int clist_init(ClistMsg *list_msg, ClistNode **list);
ClistNode* two_clist_merge(ClistMsg *clist_msg_a, ClistMsg *clist_msg_b, ClistMsg *merge);
void clist_destory(ClistMsg *list_msg, ClistNode **list);
#define clist_get_node list_get_node
#define clist_ins_node list_ins_node
#define clist_del_node list_del_node
#define clist_head(list_msg) list_head(list_msg)
#define clist_tail(list_msg) list_tail(list_msg)
#define clist_is_head(list_msg, list) list_is_head(list_msg, list)
#define clist_is_tail(list) list_is_tail(list)
#define clist_size(list_msg) list_size(list_msg)
#endif三、创建一个循环链表
/* 函数名:clist_init
*
* 功能:创建一个带头结点的指定结点数目的循环链表
*
* 入口参数:
* > clist_msg: 存放链表信息(大小、头尾结点)
* > clist: 描述链表结点的内容(数据域、指针域)
*
* 返回值:-1: fail, 0: success
*/
int clist_init(ClistMsg *clist_msg, ClistNode **clist)
{
ClistNode *p, *r;
int i, size;
memset(clist_msg, 0, sizeof(ClistMsg)); //clean up
printf("Please Enter the size of clist: ");
scanf("%d", &(clist_msg->size));
size = list_size(clist_msg);
srand(time(0)); //初始化随机数种子, time(0)为系统时间
*clist = (ListNode*)malloc(sizeof(ListNode)); //*clist为整个链表,但形参clist为栈变量,注意!!!
clist_msg->head = r = *clist; //r为指向头结点
/*将新结点插入表尾:尾插法*/
for (i = 0; i < size; i++) {
p = (ListNode*)malloc(sizeof(ListNode)); //生成新结点,总计size个,故在外使用时list->next才是整个链表的第一个节点
if (p == NULL) {
printf("fail to creat a new node!\n");
return -1;
}
p->data = rand()%100 + 1; //生成[1,100]范围内的随机数
r->next = p; //表尾结点指向新结点
r = p; //将新生成的结点p赋值给r, 让r始终保持为名义上的尾结点
}
clist_msg->tail = r; //记录尾节点
r->next = clist_msg->head; //当前循环链表结束
return 0;
} 这个部分的代码基本沿用了单链表的框架(点此查看单链表博文),其中有几处做了调整:
- clist_msg->head = r = *clist; //记录整个链表的头节点
- clist_msg->tail = r; //记录链表的尾节点
r->next = clist_msg->head; //当前循环链表结束(在单链表中设置为:r->next = NULL)
第三项加粗的部分其实也是循环链表与单链表的主要差异之处,我们可以此来作为判断条件,仅当循环遍历到头尾相接时才退出循环。
四、合并两个任意长度的循环链表
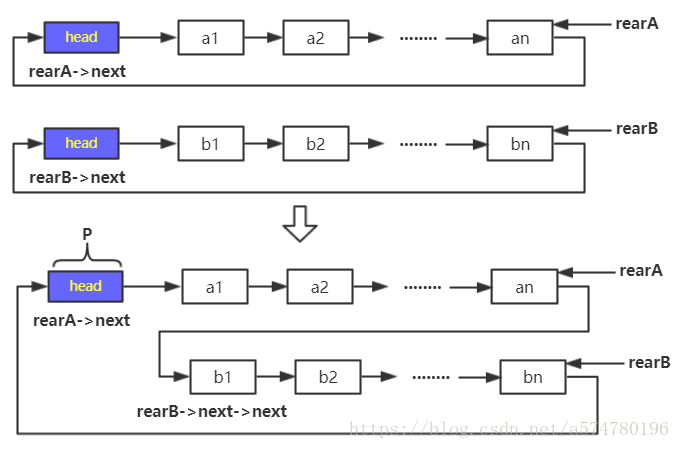
假定我们已经创建好了两个循环链表(分别用指向终端节点的尾指针rearA和rearB来表示),现进行一定的操作后,将两者合并为一个循环链表。
下图完整的描述了这种变化过程,可以看到的是合并后删除了其中一份链表的头节点同时,节点的连接关系也发生了相应变化。
/* 函数名:two_clist_merge
*
* 功能:将两个循环链表合并为一个循环链表, 并更新链表长度
*
* 入口参数:
* > clist_msg_a(b): 存放链表信息(大小、头尾结点)
* > merge_msg:存放合并后的链表信息
*
* 返回值:p(合并后的链表头节点)
*/
ClistNode* two_clist_merge(ClistMsg *clist_msg_a, ClistMsg *clist_msg_b, ClistMsg *merge_msg)
{
ClistNode *p, *q, *rearA, *rearB;
/*合并操作*/
rearA = clist_tail(clist_msg_a); //获得A表的尾节点
rearB = clist_tail(clist_msg_b); //获得B表的尾节点
p = rearA->next; //保存A表的头节点
rearA->next = rearB->next->next; //A表的终端节点指向B表的第一个节点
q = rearB->next; //保存B表头节点,用于释放
rearB->next = p; //B表的终端节点指向A表头节点
free(q);
/*记录合并后的链表状态*/
merge_msg->size = clist_msg_a->size + clist_msg_b->size;
merge_msg->head = p; //合并后整表的头节点
merge_msg->tail = rearB; //合并后整表的尾节点
return p;
}【合并步骤】
step1. 保存A表的头节点(p = rearA->next);
step2. A表的终端节点指向B表的第一个节点(rearA->next = rearB->next->next);
step3. 保存B表的头节点(用于释放);
step4. B表的终端节点指向A表的头节点。
五、完整实例,验证成果。
#include <stdio.h>
#include <string.h>
#include <time.h>
#include "clist.h"
/* 函数名:clist_init
*
* 功能:创建一个带头结点的指定结点数目的循环链表
*
* 入口参数:
* > clist_msg: 存放链表信息(大小、头尾结点)
* > clist: 描述链表结点的内容(数据域、指针域)
*
* 返回值:-1: fail, 0: success
*/
int clist_init(ClistMsg *clist_msg, ClistNode **clist)
{
ClistNode *p, *r;
int i, size;
memset(clist_msg, 0, sizeof(ClistMsg)); //clean up
printf("Please Enter the size of clist: ");
scanf("%d", &(clist_msg->size));
size = list_size(clist_msg);
srand(time(0)); //初始化随机数种子, time(0)为系统时间
*clist = (ListNode*)malloc(sizeof(ListNode)); //*clist为整个链表,但形参clist为栈变量,注意!!!
clist_msg->head = r = *clist; //r为指向头结点
/*将新结点插入表尾:尾插法*/
for (i = 0; i < size; i++) {
p = (ListNode*)malloc(sizeof(ListNode)); //生成新结点,总计size个,故在外使用时list->next才是整个链表的第一个节点
if (p == NULL) {
printf("fail to creat a new node!\n");
return -1;
}
p->data = rand()%100 + 1; //生成[1,100]范围内的随机数
r->next = p; //表尾结点指向新结点
r = p; //将新生成的结点p赋值给r, 让r始终保持为名义上的尾结点
}
clist_msg->tail = r; //记录尾节点
r->next = clist_msg->head; //当前循环链表结束
return 0;
}
/* 函数名:two_clist_merge
*
* 功能:将两个循环链表合并为一个循环链表, 并更新链表长度
*
* 入口参数:
* > clist_msg_a(b): 存放链表信息(大小、头尾结点)
* > merge_msg:存放合并后的链表信息
*
* 返回值:p(合并后的链表头节点)
*/
ClistNode* two_clist_merge(ClistMsg *clist_msg_a, ClistMsg *clist_msg_b, ClistMsg *merge_msg)
{
ClistNode *p, *q, *rearA, *rearB;
/*合并操作*/
rearA = clist_tail(clist_msg_a); //获得A表的尾节点
rearB = clist_tail(clist_msg_b); //获得B表的尾节点
p = rearA->next; //保存A表的头节点
rearA->next = rearB->next->next; //A表的终端节点指向B表的第一个节点
q = rearB->next; //保存B表头节点,用于释放
rearB->next = p; //B表的终端节点指向A表头节点
free(q);
/*记录合并后的链表状态*/
merge_msg->size = clist_msg_a->size + clist_msg_b->size;
merge_msg->head = p; //合并后整表的头节点
merge_msg->tail = rearB; //合并后整表的尾节点
return p;
}
/* 函数名:clist_destory
*
* 功能:将一个带头结点的循环链表置为空表
*
* 入口参数:
* > list_msg: 存放链表信息(大小、头尾结点)
* > list: 描述链表结点的内容(数据域、指针域)
*
* 返回值:none
*/
void clist_destory(ClistMsg *list_msg, ClistNode **list)
{
ListNode *p, *q;
p = (*list)->next; //第一个结点赋值给p
do {
q = p->next; //下一个结点赋值给q
free(p); //释放上一个结点
p = q;
} while(p != list_msg->head);
free(*list); //释放头节点
*list = NULL;
memset(list_msg, 0, sizeof(ListMsg)); //clean up
printf("ClearList: *list = %p\n", *list);
}
int main(int argc, char *argv[])
{
ClistMsg clist_msg_a, clist_msg_b, merge_msg;
ClistNode *clist_a, *clist_b, *merge;
clist_init(&clist_msg_a, &clist_a);
clist_get_node(&clist_msg_a, clist_a);
clist_init(&clist_msg_b, &clist_b);
clist_get_node(&clist_msg_b, clist_b);
merge = two_clist_merge(&clist_msg_a, &clist_msg_b, &merge_msg);
printf("merged: size = %d, head = %p, tail = %p\n", merge_msg.size, merge_msg.head, merge_msg.tail);
clist_get_node(&merge_msg, merge);
clist_destory(&merge_msg, &merge);
return 0;
} 如果你是小白,看到这儿我还想多一句嘴。关于这份实例代码如何编译运行的问题:
首先保证以下四份文件都在同一个目录下,其中list.c和list.h请参照单链表部分的博客内容。
然后注释掉list.c中的main.c函数
最后用gcc编译器将clist.c和list.c源文件进行编译,若没有注释掉list.c中的main.c函数,则会提示重复定义等错误信息。
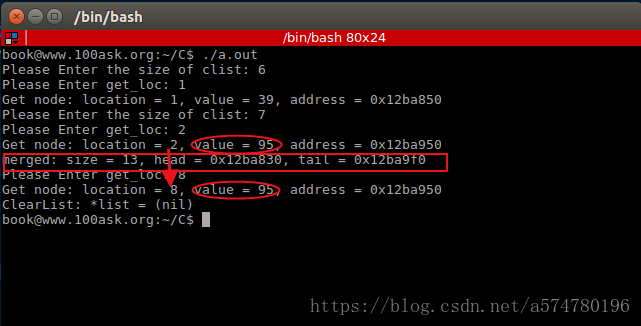
【实验结果】
A表长度初始化为6,B表长度初始化为7。最后合并后长度为13,同时合并前获取B表的第二个位置的元素值为95,合并后再获取第八个位置的元素值(原B表的第二个位置)也为95。
参阅资料
大话数据结构
算法精解—C语言描述














 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









