







推荐系统的描述
对于电影推荐系统,记nn为用户的数量,mm为电影的数量,r(i,j) = 1表示用户 j 对电影 i 进行过了评价,y(i,j)就是它的分数。r(i,j) = 0 表示用户还没观看过这个电影,也没评分过。我们假设用户看过电影后,一定会给电影一个评分,如果没有给,默认评分为零。电影推荐系统的任务,就是根据用户的评分,预测出那些用户还未观看的电影的评分,从而把那些用户可能会给出较高评分的电影推荐给用户。
基于内容的推荐算法
以电影推荐系统为例,假设theta(j)表示用户 j 的参数,x(i)为电影i的特征向量 (比如爱情电影,动作电影。这样,用户j对电影i的预测评分为theta{(j).T * x(i)。
接下来就是要获得用户j的参数theta(j)。这个实际上是个线性回归问题,即利用用户对现有电影的所有的评分学习出其参数 theta(j)。根据线性回归算法的损失公式,就是要求解线性回归算法的成本函数的最小值时,theta(j)的值。假设m(j)是用户j评价过的电影的总数。n为电影的特征数。
用户 j 的成本函数: 
求解用户 j 的参数theta(j)
求下面这个成本函数的最小值,就得到了用户j的参数theta(j)

求解所有用户的参数theta(1), theta(2), ... , theta(n)
叠加所有的用户,求下面成本函数的最小值,就得到了所有用户的参数

参数迭代公式为(alpha是学习率):

协同过滤算法
基于内容的推荐算法需要对推荐对象提取特征,构成特征向量。对电影推荐系统来说,需要对电影进行特征提取,如爱情片,动作片,然后对所有的电影进行特征采集,即针对每个电影写出其爱情成分是多少分,动作成分是多少分。这在工程上工作量非常大。
换一个方法,可以在用户注册的时候,让用户告诉我们他的偏好,比如用户喜欢哪些类型的电影。即通过调查问卷,事先知道了用户j的参数theta(j)。再根据用户的对看过的电影的评分数据,去推断出电影属于哪种类型,即电影的特征向量x(i)。针对用户 j 没有看过的电影i,根据theta(j).T * x(i)预测出用户可能的评分,根据预测出来的评分高低,去决定是否向用户推荐这部电影。
计算电影i的特征向量x(i)
选取合适的x(i),以便让下面的公式值最小。这是求解电影i的特征向量x(i)的过程

求解所有电影的特征x(1), x(2), ... , x(mm)
选取合适的x(1), x(2), ... , x(n_m),以便让下面的公式值最小

实际工程应用上,事先知道用户j的参数theta(j)也是件很难的事。其实有了所有的用户参数theta(j),就可以估算出电影的特征向量x(i)。或者如果有了电影的特征向量x(i),就可以算出用户的偏好参数theta(j)。这看起来象是个鸡生蛋和蛋生鸡的问题。
实际上,协同过滤算法就是为了解决这个问题的。
- 先随机估算出用户参数theta(j)
- 利用估算出来的theta(j)和用户看过的电影的评分数据,估算出特征向量x(i)
- 利用估算出来的特征向量x(i),反向估算出用户偏好参数theta(j)
- 重复步骤 2 ,直到用户参数theta(j)和特征向量x(i)收敛到一个合适的值
这就是协同过滤算法的核心步骤。协同过滤的一个重要的效应是,当用户对某个电影进行评分时,会帮助算法学习电影的特征,这有利于系统向所有用户推荐合适的电影,同时也让算法更好地学习到用户的偏好。这样所有用户不停地使用系统的过程中,无形中在协同过滤,帮助系统学习出更好的参数,从而更准确地推荐出用户喜欢的电影。
协同过滤算法的实现
协同过滤算法需要不停地计算theta(j)和x(i),这样算法的效率实际上是比较低的。一个更高效的算法是把计算theta(j)和x(i)的两个成本函数合并起来,得到以theta(j)和x(i)为参数的总成本函数,最小化这个成本函数,就可以同时求出theta(j)和x(i)的值。
总成本函数为:

协同过滤算法的实现步骤:
1.用较小的随机数来初始化x(1), x(2), ... ,x(mm), theta(1), theta(2), ... , theta(nn)。用较小的随机数来初始化不会让两个变量变成同一个特征。
2.最小化成本函数J(x(1), x(2), ... ,x(mm), theta(1), theta(2), ... , theta(nn)),可以使用梯度下降或其他的优化过的高级算法。其参数迭代公式为:

3.学习出参数后,针对一个用户j的参数为theta(j),针对这个用户没有看过的电影,学习到的特征为x(i),那么可以预测到这个用户对这个电影的评分将是theta(j).T * x(i)
推荐相似的电影
若已经通过协同过滤算法学习到了所有的电影特征x(i)。假设这个时候用户在浏览电影i,遍历所有的电影,通过公式|x(i)-x(k)|找出和正在浏览的电影“距离最小”,即相似度最高的几部电影。
均值归一化
若现在有个新用户j没有对任何电影进行打分。那么根据协同过滤算法的成本函数:

第一部分将为0,因为对用户j,没有r(i,j)=1的项。第二部分将为一个固定值,因为已经学习好了电影的特征,所以计算结果将使 theta(j)为全 0 。这样的话,这个用户对所有电影的评分将预测为 0 ,我们也就没有什么他喜欢的电影推荐给他了。
简单地讲,如果一个新用户没有评分过任何电影,我们可以预测这个用户对新电影的评分为这个电影的评分的平均值。所以需要先对电影评分数据进行均值归一处理。
假设有所有的电影评分矩阵Y,对其按行求平均值,得到mu。然后我们计算Y-mu作为我们协同过滤算法的训练数据集。这样训练出来theta(j)和x(i)之后,针对新用户j对电影i的预测评分公式将变成theta(j).T * x(i) + mu(i)。
代码实现
import numpy as np
from scipy.optimize import minimize
import pandas as pd
def getRecommender(Y, R, params=None, n=10, theLambda=10, maxIter=100):
"""
Args:
Y - 用户对影片的评分矩阵
R - 用户j是否对影片i评分的矩阵 (0/1)
params - 若有初始化参数,可在此传入(Theta, X)
n - 电影的特征数
theLambda - 正则化参数
maxIter - 最大迭代次数
Returns:
train - 训练函数
predict - 预测函数
getTopRecommends - 获取特定影片的最相似推荐
"""
# 影片数,用户数
nm, nu = Y.shape
# 标准化影片的评分
mu = np.zeros((Y.shape[0], 1), dtype=np.float)
for i in range(nm):
totalRates = np.sum(Y[i])
validCount = len(np.nonzero(R[i])[0])
mu[i] = totalRates / validCount
Y = Y - mu
def roll(Theta, X):
"""
对于模型而言,Theta和X都是待学习的参数,需要放在一起直接优化
Args:
Theta - 用户偏好矩阵
X - 电影特征矩阵
Returns:
vector - 折叠后的参数
"""
#return np.hstack((X.A.T.flatten(), Theta.A.T.flatten()))
return np.hstack((X.A.T.flatten(), Theta.A.T.flatten()))
def unroll(vector):
"""
Args:
vector 参数向量
Returns:
Theta - 用户偏好矩阵
X - 电影特征矩阵
"""
X = np.mat(vector[:nm * n].reshape(n, nm).T)
Theta = np.mat(vector[nm * n:].reshape(n, nu).T)
return Theta, X
def initParams():
"""初始化参数
Returns:
Theta - 用户偏好矩阵
X - 电影特征矩阵
"""
Theta = np.mat(np.random.rand(nu, n))
X = np.mat(np.random.rand(nm, n))
return Theta, X
def regularize(param):
"""对参数进行正则化
Args:
param - 参数
Return:
regParam - 正规化后的参数
"""
return theLambda * 0.5 * np.sum(np.power(param, 2))
def J(params):
"""代价函数
Args:
params - 参数向量
nu - 用户数
nm - 电影数
n - 特征数
Return:
J - 预测代价
"""
# 参数展开
Theta, X = unroll(params)
# 计算误差
rows, cols = np.nonzero(R)
# 预测
h = predict(Theta, X)
diff = h - Y
diff[R != 1] = 0
error = 0.5 * np.sum(np.power(diff, 2))
# 正则化 Theta
regTheta = regularize(Theta)
# 正规化 x
regX = regularize(X)
return error + regTheta + regX
def gradient(params):
"""计算梯度
Args:
params - 参数向量
Returns:
grad - 梯度向量
"""
Theta, X = unroll(params)
# 当前梯度初始化成0
ThetaGrad = np.mat(np.zeros(Theta.shape))
XGrad = np.mat(np.zeros(X.shape))
error = predict(Theta, X) - Y
error[R != 1] = 0
# 这里只需要计算梯度
ThetaGrad = error.T * X + theLambda * Theta
XGrad = error * Theta + theLambda * X
return roll(ThetaGrad, XGrad)
def train():
"""训练
Returns:
Theta - 用户偏好矩阵
X - 电影特征矩阵
"""
# 初始化参数
if not params:
Theta, X = initParams()
else:
Theta = params['Theta']
X = params['X']
# 最小化目标函数
res = minimize(J, x0=roll(Theta, X), jac=gradient,
method='CG', options={'disp': True, 'maxiter': maxIter})
Theta, X = unroll(res.x)
return Theta, X
def predict(Theta, X):
"""预测
Args:
Theta - 用户偏好矩阵
X - 电影特征矩阵
Return:
h 预测
"""
return X * Theta.T
def getTopRecommends(Theta, X, i, count, rated, items):
"""获得推荐
Args:
Theta - 用户偏好矩阵
X - 影片特征矩阵
i - 用户索引
count - 目标推荐数量
rated - 已经评价的影片id
items - 影片库
Returns:
topRecommends - 推荐项目
"""
predictions = (predict(Theta, X) + mu)[:, i]
# 实用pandas的DataFrame可以将不同类型数据放在一个Frame中,方便排序等操作
# 相较而言,numpy的多维数组要求内部类型完全一致
df = pd.DataFrame(data=predictions, columns=['prediction',])
df['movie'] = items
df.sort_values(by='prediction', ascending=False,inplace=True)
# 不推荐已经评过分的影片
df.drop(rated, inplace=True)
return df[0:count]
return train, predict, getTopRecommends
加载数据
from scipy.io import loadmat
data = loadmat('data/ex8_movies.mat')
Y = data['Y']
R = data['R']
movieParams = loadmat('data/ex8_movieParams.mat')
nm = movieParams['num_movies'][0,0]
n = movieParams['num_features'][0,0]
def getMovie(line):
return ' '.join(line.split()[1:])
movieList = []
with open('data/movie_ids.txt') as f:
for line in f:
movieList.append(getMovie(line.strip()))
myRatings = np.mat(np.zeros((nm,1)))
myRatings[0] = 4
myRatings[97] = 2
myRatings[6] = 3
myRatings[11] = 5
myRatings[53] = 4
myRatings[63] = 5
myRatings[65] = 3
myRatings[68] = 5
myRatings[182] = 4
myRatings[225] = 5
myRatings[354] = 5
# 将我们的新用户数据加入
Y = np.column_stack((myRatings, Y))
R = np.column_stack((myRatings, R)).astype(bool)
train, predict, getTopRecommends = getRecommender(
Y, R, n=n, theLambda=10.0)
训练得出结果:
Theta, X = train()
rated = np.nonzero(myRatings)[0].tolist()
# -1 就是刚才加入的最新用户
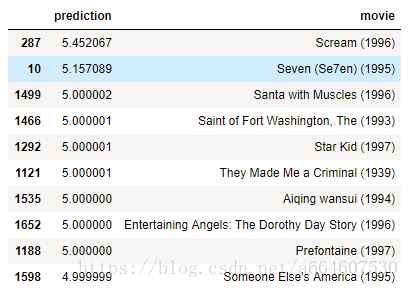
topRecommends = getTopRecommends(Theta, X, -1, 10, rated, movieList)
topRecommends输出:














 2140
2140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









