







kafka为什么吞吐量大?
1.数据读取方式
kafka一个topic分成多个分区,每个消费者对应一个或者多个分区,一个分区只对应一个消费者。这样就保证了线程安全性,不用设锁去防止多个消费者同事消费同一个数据源,我们都知道锁是很耗性能的一个东西,这样就省去了这个步骤,性能也有显著的提升。
2.顺序写入
kafka的顺序读写也是一个提高吞吐量的地方,Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得Kafka写入吞吐量得到了显著提升.众所周知Kafka是将消息记录持久化到本地磁盘中的,一般人会认为磁盘读写性能差,可能会对Kafka性能如何保证提出质疑。实际上不管是内存还是磁盘,快或慢关键在于寻址的方式,磁盘分为顺序读写与随机读写,内存也一样分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但磁盘的顺序读写性能却很高,一般而言要高出磁盘随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写。
。
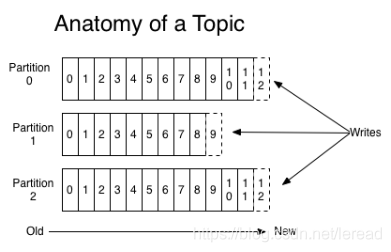
上图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷—— 没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示 读取到了第几条数据 。
3.Page Cache
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做的好处有:
1避免Object消耗:如果是使用 Java 堆,Java对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
2避免GC问题:随着JVM中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在GC问题
相比于使用JVM或in-memory cache等数据结构,利用操作系统的Page Cache更加简单可靠。首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。其次,操作系统本身也对于Page Cache做了大量优化,提供了 write-behind、read-ahead以及flush等多种机制。再者,即使服务进程重启,系统缓存依然不会消失,避免了in-process cache重建缓存的过程。
通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
kafka 单个服务挂了,数据不会丢失
备份高可用性。消息以partition为单位分配到多个server,并以partition为单位进行备份。备份策略为:1个leader和N个followers,leader接受读写请求,followers被动复制leader。leader和followers会在集群中打散,保证partition高可用。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









