







【DB笔试面试1】下列不属于Oracle的逻辑结构的是()
A、区 B、段 C、数据文件 D、表空间
答案:C。
Oracle中逻辑结构包括表空间、段、区和块。其中,数据库由表空间构成,而表空间又是由段构成,而段又是由区构成,而区又是由Oracle块构成。使用这种“块 → 区 → 段 → 表空间 → 数据库”的结构为了提高数据库的效率。逻辑结构图如下图所示:
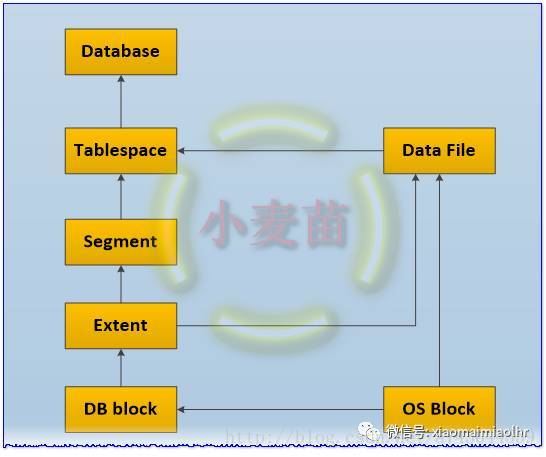
本题中,对于选项A、B、D都属于数据库的逻辑结构,对于C选项的数据文件是属于数据库的物理结构,是实实在在可以看得见的。
所以,本题的答案为C。
【DB笔试面试2】下面哪个用户不是Oracle缺省安装后就存在的用户()
A、SYSDBA B、SYSTEM
C、SCOTT D、SYS
SYSDBA和SYSOPER属于系统权限,也称为管理权限,拥有例如数据库开启、关闭等一些系统管理级别的权限。SYSDBA拥有最高的系统权限,SYS用户必须以SYSDBA的权限来登录,而普通用户以SYSOPER登陆后用户是PUBLIC。
[oracle@orcltest ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.3.0 Production on Tue Dec 6 14:39:19 2016
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Data Mining
and Real Application Testing options
SYS@lhrdb> show user
USER is “SYS”
SYS@lhrdb> grant sysoper to lhr;
Grant succeeded.
SYS@lhrdb> conn lhr/lhr as sysoper
Connected.
PUBLIC@lhrdb> show user
USER is “PUBLIC”
PUBLIC@lhrdb> conn lhr/lhr
Connected.
LHR@lhrdb> show user
USER is “LHR”
SYSDBA和SYSOPER具体的权限如下表所示:
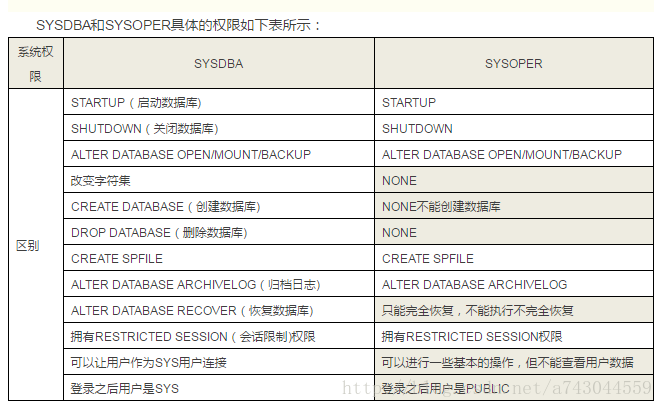
本题中,对于选项A,SYSDBA属于系统特殊权限,不属于用户,选项A的描述错误。所以,选项A正确。
对于选项B,SYSTEM是系统默认用户,拥有DBA角色。所以,选项B错误。
对于选项C,SCOTT用户属于测试用户。所以,选项C错误。
对于选项D,SYS用户具有管理系统的最高权限,必须以SYSDBA来登录。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试3】下面哪种情况会让普通用户连接到Oracle数据库,但不能创建表()
A、授予了CONNECT的角色,但没有授予RESOURCE的角色
B、没有授予用户系统管理员的角色
C、数据库实例没有启动
D、数据库监听没有启动
CONNECT角色只具有最简单的登录权限,登录后不能做任何操作,只有赋予了CREATE TABLE权限后才能创建表。
本题中,对于选项A,只有CONNECT角色只能登录,登录后不能做其它操作。所以,选项A正确。
对于选项B,没有系统管理员权限,但是有CREATE TABLE权限也可以创建表。所以,选项B错误。
对于选项C,数据库实例如果没有启动,普通用户不能连接数据库。所以,选项C错误。
对于选项D,数据库监听如果没有启动,普通用户也不能连接到数据库。所以,选项D错误。
所以,本题的答案为A
【DB笔试面试4】在Oracle中,关于PL/SQL下列描述正确的是()
A、PL/SQL代表Power Language/SQL
B、PL/SQL不支持面向对象编程
C、PL/SQL块包括声明部分、可执行部分和异常处理部分
D、PL/SQL提供的四种内置数据类型是CHARACTER、INTEGER、FLOAT、BOOLEAN
PL/SQL(Procedure Language & Structured Query Language)是Oracle在标准的SQL语言上的扩展。PL/SQL不仅允许嵌入SQL语言,还可以定义变量和常量,允许使用条件语句和循环语句,允许使用异常处理各种错误,这样使得它的功能变得更加强大。
一个基本的PL/SQL块由三部分组成:定义部分,可执行部分以及异常部分。
定义部分:定义将在可执行部分中用到的所有变量、常量、游标和用户自定义的异常处理,这部分是可选的。
可执行部分:包括对数据进行操作的SQL语句。这部分必须存在。
异常处理部分:对可执行部分中的语句,在执行过程中出错或出现非正常现象时所做出的处理。这部分也是可选的。
本题中,对于选项A,PL/SQL代表Procedure Language & Structured Query Language。所以,选项A错误。
对于选项B,PL/SQL支持面向对象编程。所以,选项B错误。
对于选项C,PL/SQL块包括声明部分、可执行部分和异常处理部分。所以,选项C正确。
对于选项D,PL/SQL提供的内置数据类型不包括CHARACTER。所以,选项D错误。
所以,本题的答案为C。
【DB笔试面试5】在Oracle数据库中,下面关于函数的描述正确的是()
A、SYSDATE函数返回Oracle服务器的日期和时间
B、ROUND数字函数按四舍五入原则返回与指定十进制数最靠近的整数
C、ADD_MONTHS日期函数返回指定两个月份天数的和
D、SUBSTR函数从字符串指定的位置返回剩余的子串
Oracle有很多系统函数,像SYSDATE,TRUNCATE,ROUND,NVL等都是常用的也是必须掌握的函数。
本题中,对于选项A,SYSDATE返回系统的时间。所以,选项A正确。
对于选项B,ROUND函数按照四舍五入的原则进行取舍,并非取整。所以,选项B错误。
对于选项C,ADD_MONTHS函数是加上指定的月份数。所以,选项C错误。
对于选项D,SUBSTR为字符截取函数,表示从字符串指定的位置返回指定长度的子串。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试6】适合建立索引的字段是()(多选题)
A、在SELECT子句中的字段 B、外键字段
C、主键字段 D、在WHERE子句中的字段
以下列上适合建立索引:
(1) 表的主键、外键必须有索引。
(2) 经常与其它表进行连接的表,在连接字段上应该建立索引。
(3) 经常出现在WHERE子句中的字段,特别是大表的字段,应该建立索引。
(4) 索引应该建在选择性高的字段上。
(5) 索引应该建在小字段上,对于大的文本字段甚至超长字段,不适合建索引。
(6) 复合索引的建立需要进行仔细分析。
(7) 正确选择复合索引中的主列字段,一般是选择性较好的字段。
(8) 如果单字段查询很少甚至没有,那么可以建立复合索引;否则考虑单字段索引。
(9) 如果复合索引中包含的字段经常单独出现在WHERE子句中,那么分解为多个单字段索引。
(10) 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段。
(11) 如果既有单字段索引,又有这几个字段上的复合索引,那么一般可以删除复合索引。
(12) 频繁进行DML操作的表,不要建立太多的索引。
(13) 删除无用的索引,避免对执行计划造成负面影响。
本题中,对于选项A,SELECT子句中的字段若作为连接条件,则可以建立索引。所以,选项A错误。
对于选项B,外键字段应该建立索引。所以,选项B正确。
对于选项C,主键字段应该建立索引。所以,选项C正确。
对于选项D,在WHERE子句中的字段常作为连接条件或过滤条件,可以建立索引。所以,选项D正确。
所以,本题的答案为B、C、D。
【DB笔试面试7】运行上面的程序,下面选项中哪几个更改永久保存到数据库()
BEGIN
INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(35000,’WANG’,’FRED’);
SAVEPOINT SAVE_A;
INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(40000,’WOO’,’DAVID’);
SAVEPOINT SAVE_B;
INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(50000,’LDD’,’FRIK’);
SAVEPOINT SAVE_C;
INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(45000,’LHR’,’DAVID’);
INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(25000,’LEE’,’BERT’);
ROLLBACK TO SAVEPOINT SAVE_C;
INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(32000,’CHUNG’,’MIKE’);
ROLLBACK TO SAVEPOINT SAVE_B;
COMMIT;
END;
运行上面的程序,下面选项中哪几个更改永久保存到数据库()(多选题)
A、INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(50000,’LDD’,’FRIK’);
B、INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(32000,’CHUNG’,’MIKE’);
C、INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(35000,’WANG’,’FRED’);
D、INSERT INTO EMPLOYEE(SALARY,LAST_NAME,FIRST_NAME) VALUES(40000,’WOO’,’DAVID’);
保存点(SAVEPOINT)是事务处理过程中的一个标志,与回滚命令(ROLLBACK)结合使用。其主要用途是允许用户将某一段处理进行回滚而不必回滚整个事务。
1)执行SAVEPOINT SAVE_A的时候创建了一个保存点SAVE_A;
2)执行SAVEPOINT SAVE_B的时候创建了一个保存点SAVE_B;
3)执行SAVEPOINT SAVE_C的时候创建了一个保存点SAVE_C;
4)在执行ROLLBACK TO SAVEPOINT SAVE_C后,SAVEPOINT SAVE_C到当前语句之间所有的操作都被回滚;也就是说回滚到了3)的状态;
5)在执行ROLLBACK TO SAVEPOINT SAVE_B后,SAVEPOINT SAVE_B到当前语句之间所有的操作都被回滚;也就是说回滚到了2)的状态;
6)在执行COMMIT后,只有SAVEPOINT SAVE_B之前的操作会被提交从而永久保存到数据库。
综上分析,题目中的程序块在执行完毕后,只有SAVEPOINT SAVE_B之前的操作会被提交从而永久保存到数据库,显然,C和D选项正确。
所以,本题的答案为C、D。
【DB笔试面试8】小明设计了如下的学籍管理系统,已知关系:
学籍(学号,学生姓名) PK=学号
成绩(科目号,成绩,学号) PK=科目代码,FK=学号
已有表记录如下,能够插入成绩记录的是()

A、(1,99,5) B、(5,68,1) C、(3,70,7) D、(7,45,NULL)
主键用来唯一地标识一条记录,不能有重复的记录,不允许为空,主键只能有一个,用来保证数据完整;表的外键是另一表的主键,外键可以有重复的,可以是空值,一个表可以有多个外键,用来和其它表建立联系用的。
对于本题主要看外键列是否在主表中存在,若不存在,则报错:ORA-02291: integrity constraint (SYS.FK_XX) violated - parent key not found
本题中,对于选项A,学号5在学籍表中不存在。所以,选项A错误。
对于选项B,学号1在学籍表中存在。所以,选项B正确。
对于选项C,学号7在学籍表中不存在。所以,选项C错误。
对于选项D,外键列可以为空。所以,选项D正确。
所以,本题的答案为B、D。
【DB笔试面试9】对数据库第二范式的理解,正确的是()
对数据库第二范式的理解,正确的是()
A、数据库表的每一列都是不可分割的原子数据项
B、在1NF基础上,任何非主属性不依赖于其它非主属性
C、在1NF基础上,非码属性必须完全依赖于码
D、以上说法都不正确
1NF:原子性,字段不可再分,否则就不是关系型数据库。
2NF:唯一性,一个表只说明一个事物。
3NF:每列都与主键有直接关系,不存在传递依赖。
本题中,对于选项A,属于第一范式。所以,选项A错误。
对于选项B,在1NF基础上消除非主属性对主键的部分函数依赖才是2NF。所以,选项B错误。
对于选项C,在1NF基础上,非码属性必须完全依赖于码。所以,选项C正确。
对于选项D,自然错误。
所以,本题的答案为C。
【DB笔试面试10】下列选项中,不属于SQL约束的是()
下列选项中,不属于SQL约束的是()
A、UNIQUE
B、PRIMARY KEY
C、FOREIGN KEY
D、BETWEEN
约束主要有以下几种:
NOT NULL:用于控制字段的内容一定不能为空(NULL)。
UNIQUE:控制字段内容不能重复,一个表允许有多个UNIQUE约束。
PRIMARY KEY:也是用于控制字段内容不能重复,但它在一个表只允许出现一个。
FOREIGN KEY:FOREIGN KEY约束用于防止非法数据插入外键列,因为外键列的值必须在主表中存在。
CHECK:用于控制字段的值范围。
DEFAULT:用于设置新记录的默认值。
本题中,对于选项A,UNIQUE属于唯一约束。所以,选项A错误。
对于选项B,PRIMARY KEY属于主键约束。所以,选项B错误。
对于选项C,FOREIGN KEY属于外键约束。所以,选项C错误。
对于选项D,BETWEEN属于连接操作符,不属于约束,所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试11】根据题目要求写出以下50道SQL语句(1)
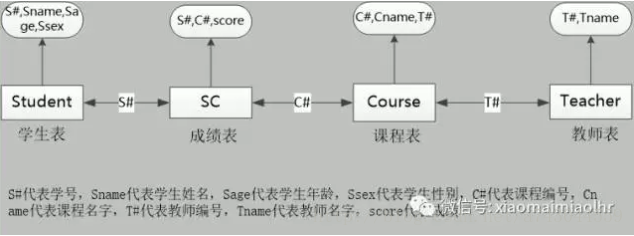
已知有如下4张表:
学生表:STUDENT(S#,SNAME,SAGE,SSEX)
课程表:COURSE(C#,CNAME,T#)
成绩表:SC(S#,C#,SCORE)
教师表:TEACHER(T#,TNAME)
其中,S#代表学号,SNAME代表学生姓名,SAGE代表学生年龄,SSEX代表学生性别,C#代表课程编号,CNAME代表课程名字,T#代表教师编号,TNAME代表教师名字,SCORE代表成绩。
根据以上信息按照下面要求写出对应的SQL语句。
本题考察SQL的编写能力,对于这类型的题目,只要把4张表之间的关联关系搞清楚了,编写对应的SQL语句就比较容易了,本题给出的四张表之间的关系如下图所示:
1、查询课程编号为“001”的课程比“002”的课程成绩高的所有学生的学号
答案:首先查询课程编号分别为001和002的所有学生的学号及其分数作为内嵌视图A和B,然后将A和B通过学号关联,过滤条件就是A的分数大于B的分数,最终SQL如下:
SELECT A.S#
FROM (SELECT S#, SCORE FROM SC WHERE C# = ‘001’) A,
(SELECT S#, SCORE FROM SC WHERE C# = ‘002’) B
WHERE A.SCORE > B.SCORE
AND A.S# = B.S#;
2、查询平均成绩大于60分的学生的学号和平均成绩
答案:该内容通过SC表即可获取,按照SC表的S#分组后即可求出平均成绩,最后通过HAVING子句来过滤平均分大于60的学生,最终SQL如下:
SELECT S#, AVG(SCORE)
FROM SC
GROUP BY S#
HAVING AVG(SCORE) > 60;
3、查询所有学生的学号、姓名、选课数、总成绩
答案:学生姓名通过STUDENT表获取,成绩通过SC表获取,考察的是COUNT和GROUP BY函数,最终SQL如下:
SELECT STUDENT.S#, STUDENT.SNAME, COUNT(SC.C#), SUM(SCORE)
FROM STUDENT
LEFT OUTER JOIN SC
ON STUDENT.S# = SC.S#
GROUP BY STUDENT.S#, SNAME;
4、查询姓“李”的老师的个数
答案:老师通过TEACHER表即可查询,考察模糊查询,最终SQL如下:
SELECT COUNT(DISTINCT(TNAME))
FROM TEACHER
WHERE TNAME LIKE ‘李%’;
5、查询没学过“李美玲”老师课的学生的学号、姓名
答案:首先查询学习过“李美玲”老师课的学生的学号作为子查询,而“李美玲”老师涉及到TEACHER表,TEACHER表要和学生有关联必须通过课程和成绩表,最终SQL如下:
SELECT STUDENT.S#, STUDENT.SNAME
FROM STUDENT
WHERE S# NOT IN (SELECT DISTINCT (SC.S#)
FROM SC, COURSE, TEACHER
WHERE SC.C# = COURSE.C#
AND TEACHER.T# = COURSE.T#
AND TEACHER.TNAME = ‘李美玲’);
6、查询学过编号为“001”的课程并且也学过编号为“002”的课程的学生的学号、姓名
答案:这道题需要注意的是“且”这个关键词,说明查询出来的学生即学习过001也学习过002的课程,最终SQL如下:
SELECT STUDENT.S#, STUDENT.SNAME
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
ANDSC.C# = ‘001’
AND EXISTS (SELECT *
FROM SC AS SC_2
WHERE SC_2.S# = SC.S#
AND SC_2.C# = ‘002’);
错误答案:
SELECT STUDENT.S#, STUDENT.SNAME
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
AND SC.C# IN (‘001’ ,’002’);
7、查询学过“李多多”老师所教的所有课的学生的学号、姓名
答案:这道题和第6题比较相似,需要理解题意,题目说的是查询学过“李多多”老师所教的所有课的同学的学号、姓名,举个例子,比如“李多多”老师教过语文和数学,那么就得找出哪些同学同时学习了语文和数学这2门课程,最终SQL如下:
SELECT S#, SNAME
FROM STUDENT
WHERE S# IN (SELECT S#
FROM SC, COURSE, TEACHER
WHERE SC.C# = COURSE.C#
AND TEACHER.T# = COURSE.T#
AND TEACHER.TNAME = ‘李多多’
GROUP BY S#
HAVING COUNT(SC.C#) = (SELECT COUNT(C#)
FROM COURSE, TEACHER
WHERE TEACHER.T# = COURSE.T#
AND TNAME = ‘李多多’));
错误答案:
SELECT S#, SNAME
FROM STUDENT
WHERE S# IN (SELECT S# FROM SC, COURSE, TEACHER
WHERESC.C# = COURSE.C#
AND TEACHER.T# = COURSE.T#
AND TEACHER.TNAME = ‘李多多’);
8、查询课程编号为“002”的总成绩
答案:本题考查SUM函数,最终SQL如下所示:
SELECT SUM(SCORE) FROM SC SC_2 WHERE SC_2.C# = ‘002’;
9、查询所有课程成绩小于60分的学生的学号、姓名
答案:涉及到学生表和成绩表,比较简单,最终SQL如下:
SELECT S#, SNAME
FROM STUDENT
WHERE S# NOT IN (SELECT STUDENT.S#
FROM SC
WHERE SCORE >= 60);
10、查询没有学全所有课的学生的学号、姓名
答案:没有学全所有课,翻译一下就是学生学习的课程数小于总的课程数,最终SQL如下:
SELECT STUDENT.S#, STUDENT.SNAME
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
GROUP BY STUDENT.S#, STUDENT.SNAME
HAVING COUNT(C#) < (SELECT COUNT(C#) FROM COURSE);
11、查询至少有一门课与学号为“1001”的学生所学课程相同的学生的学号和姓名
答案:首先找出学号为1001的学生学习过的课程,然后根据这些课程号就可以找到有哪些学生学习过部分1001学生学习过的课程,最终SQL如下:
SELECT S#, SNAME
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
AND C# IN (SELECT C# FROM SC WHERE S# = ‘1001’);
SELECT SC.S#, SNAME;
12、查询所学课程和学号为“001”的学生所有课程一样的其他学生的学号和姓名
答案:首先找出学号为1001的学生学习过的课程,然后根据这些课程号和所学课程总数就可以找到有哪些同学学习过和他一样的课程,最终SQL如下:
SELECT STUDENT.S#, STUDENT.SNAME
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
AND C# IN (SELECT C# FROM SC WHERE S# = ‘001’)
GROUP BY STUDENT.S#, STUDENT.SNAME
HAVING COUNT(C#) = (SELECT COUNT(C#) FROM SC WHERE S# = ‘001’);
13、把“SC”表中“李多多”老师教的课的成绩都更改为此课程的平均成绩
答案:首先找到李多多老师教过哪些课程及其课程的平均成绩,然后根据课程号关联成绩表进行更新,最终SQL如下:
UPDATE SC
SET SCORE =
(SELECT AVG(SC_2.SCORE)
FROM COURSE, TEACHER, SC SC_2
WHERE COURSE.T# = TEACHER.T#
AND COURSE.C# = SC_2.C#
AND SC_2.C# =SC.C#
AND TEACHER.TNAME = ‘李多多’
GROUP BY COURSE.C#)
WHERE EXISTS(SELEC 1 FROM COURSE,
TEACHER,
SC SC_2 WHERE COURSE.T# = TEACHER.T#
AND COURSE.C# = SC_2.C#
AND SC_2.C# =SC.C#
AND TEACHER.TNAME = ‘李多多’
GROUP BY COURSE.C#
);
14、查询没有学习过“1002”号课程的的学生的学号和姓名
答案:本题比较简答,最终SQL如下:
SELECT STUDENT.S#, STUDENT.SNAME
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
AND C# NOT IN (SELECT C# FROM SC WHERE S# = ‘1002’);
15、删除学习“李多多”老师课的SC表记录
答案:本题比较简答,最终SQL如下:
DELETE FROM SC
WHERE SC.C# IN
(SELECT COURSE.C# FROM COURSE C, TEACHER T WHERE C.T# = T.T# AND T.TNAME=’李多多’);
16、向SC表中插入一些记录这些记录要求符合以下条件:没有上过编号为“003”课程的学生的学号、编号为002的课程的平均成绩
答案:2个点,002课程的平均成绩和没有学习过003课程的学生,最终SQL如下:
INSERT INTO SC(S#,C#,SCORE)
SELECT S#, ‘002’, (SELECT AVG(SCORE) FROM SC WHERE C# = ‘002’)
FROM STUDENT
WHERE S# NOT IN (SELECT S# FROM SC WHERE C# = ‘003’);
17、按平均成绩从高到低显示所有学生的“数据库”、“企业管理”、“英语”三门的课程成绩,其中数据库的c#为004,企业管理的c#为001,英语的c#为006,按如下形式显示:
学生ID 数据库 企业管理 英语 有效课程数 有效平均成绩
答案:查看标量子查询,最终SQL如下:
SELECT S# AS 学生ID,
(SELECT SCORE FROM SC WHERE SC.S# = T.S# AND C# = ‘004’) AS 数据库,
(SELECT SCORE FROM SC WHERE SC.S# = T.S# AND C# = ‘001’) AS 企业管理,
(SELECT SCORE FROM SC WHERE SC.S# = T.S# AND C# = ‘006’) AS 英语,
COUNT(*) AS 有效课程数,
AVG(T.SCORE) AS 平均成绩
FROM SC AS T
GROUP BY S#
ORDER BY AVG(T.SCORE) DESC;
18、查询各科成绩最高和最低的分,以如下形式显示课程ID最高分最低分
答案:最终SQL如下:
SELECT C# AS 课程ID, MAX(SCORE) AS 最高分, MIN(SCORE) AS 最低分
FROM SC
GROUP BY C#;
19、按各科平均成绩从低到高和及格率的百分数从高到低排列,以如下形式显示:
课程号 课程名 平均成绩 及格百分数
答案:最终SQL如下:
SELECT T.C# AS 课程号,
MAX(COURSE.CNAME) AS 课程名,
NVL(AVG(SCORE), 0) AS 平均成绩,
((100 * SUM(CASE
WHEN NVL(SCORE, 0) >= 60 THEN
1
ELSE
0
END)) / COUNT(*)) AS 及格百分数
FROM SC T, COURSE C
WHERE T.C# = C.C#
GROUP BY T.C#
ORDER BY 平均成绩,
((100 * SUM(CASE
WHEN NVL(SCORE, 0) >= 60 THEN
1
ELSE
0
END)) / COUNT(*));
20、查询如下课程平均成绩和及格率的百分数(用1行显示),其中企业管理为001,马克思为002,UML为003,数据库为004
答案:最终SQL如下:
SELECT SUM(CASE WHEN C#=’001’ THEN SCORE ELSE 0 END)/SUM(CASE C# WHEN ‘001’ THEN 1 ELSE 0 END) AS 企业管理平均分,
100*SUM(CASE WHEN C#=’001’ AND SCORE>=60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C#=’001’ THEN 1 ELSE 0 END) AS 企业管理及格百分数,
SUM(CASE WHEN C#=’002’ THEN SCORE ELSE 0 END)/SUM(CASE C# WHEN’002’ THEN 1 ELSE 0 END) AS 马克思平均分,
100*SUM(CASE WHEN C#=’002’ AND SCORE>=60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C#=’002’ THEN 1 ELSE 0 END) AS 马克思及格百分数,
SUM(CASE WHEN C#=’003’ THEN SCORE ELSE 0 END)/SUM(CASE C# WHEN’003’ THEN 1 ELSE 0 END) AS UML平均分 ,
100*SUM(CASE WHEN C#=’003’ AND SCORE>=60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C#=’003’ THEN 1 ELSE 0 END) AS UML及格百分数,
SUM(CASE WHEN C#=’004’ THEN SCORE ELSE 0 END)/SUM(CASE C# WHEN ‘004’ THEN 1 ELSE 0 END) AS数据库平均分,
100*SUM(CASE WHEN C#=’004’AND SCORE>=60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C#=’004’THEN 1 ELSE 0 END) AS 数据库及格百分数
FROM SC;
21、查询不同老师所教不同课程平均分从高到低显示
答案:最终SQL如下:
SELECT Z.T# AS 教师ID,
Z.TNAME AS 教师姓名,
C.C# AS 课程,
C.CNAME AS 课程名称,
AVG(SCORE) AS 平均成绩
FROM SC AS T, COURSE AS C, TEACHER AS Z
WHERE T.C# = C.C#
AND C.T# = Z.T#
GROUP BY C.C#,Z.T#,Z.TNAME,C.CNAME
ORDER BY AVG(SCORE) DESC;
22、查询如下课程成绩第3名到第6名的学生成绩单,其中企业管理为001,马克思为002,UML为003,数据库为004,以如下形式显示:
学生ID 学生姓名 企业管理 马克思 UML 数据库 平均成绩
答案:最终SQL如下:
SELECT SC.S# AS 学生学号,
STUDENT.SNAME AS 学生姓名,
T1.SCORE AS 企业管理,
T2.SCORE AS 马克思,
T3.SCORE AS UML,
T4.SCORE AS 数据库,
NVL(T1.SCORE, 0) + NVL(T2.SCORE, 0) + NVL(T3.SCORE, 0) +
NVL(T4.SCORE, 0) AS 总分
FROM STUDENT, SC
LEFT JOIN (SELECT *
FROM (SELECT NB.S#,
NB.SCORE,
(RANK() OVER(PARTITION BY NB.S# ORDER BY NB.SCORE)) RK
FROM SC NB
WHERE NB.C# = ‘001’)
WHERE RK <= 6
AND RK >= 3) AS T1
ON SC.S# = T1.S#
LEFT JOIN (SELECT *
FROM (SELECT NB.S#,
NB.SCORE,
(RANK() OVER(PARTITION BY NB.S# ORDER BY NB.SCORE)) RK
FROM SC NB
WHERE NB.C# = ‘002’)
WHERE RK <= 6
AND RK >= 3) AS T2
ON SC.S# = T2.S#
LEFT JOIN (SELECT *
FROM (SELECT NB.S#,
NB.SCORE,
(RANK() OVER(PARTITION BY NB.S# ORDER BY NB.SCORE)) RK
FROM SC NB
WHERE NB.C# = ‘003’)
WHERE RK <= 6
AND RK >= 3) AS T3
ON SC.S# = T3.S#
LEFT JOIN (SELECT *
FROM (SELECT NB.S#,
NB.SCORE,
(RANK() OVER(PARTITION BY NB.S# ORDER BY NB.SCORE)) RK
FROM SC NB
WHERE NB.C# = ‘004’)
WHERE RK <= 6
AND RK >= 3) AS T4
ON SC.S# = T4.S#
WHERE STUDENT.S# = SC.S#;
23、使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计各分数段人数:课程ID和课程名称
答案:最终SQL如下:
SELECTSC.C# AS 课程ID,
CNAME AS 课程名称,
SUM(CASE WHEN SCORE BETWEEN 85 AND 100 THEN 1 ELSE 0 END) AS “[100-85]” ,
SUM(CASE WHEN SCORE BETWEEN 70 AND 85 THEN 1 ELSE 0 END) AS “[85-70]” ,
SUM(CASE WHEN SCORE BETWEEN 60 AND 70 THEN 1 ELSE 0 END) AS “[70-60]” ,
SUM(CASE WHEN SCORE<60 THEN 1 ELSE 0 END) AS “[60-]”
FROM SC,COURSE
WHERE SC.C#=COURSE.C#
GROUP BY SC.C#,CNAME;
24、查询学生平均成绩及其名次
答案:最终SQL如下:
SELECT S# AS 学生学号, RK AS 名次, 平均成绩
FROM (SELECT S#,
AVG(SCORE) 平均成绩,
SUM(SCORE) 总成绩,
(RANK() OVER(PARTITION BY S# ORDER BY SUM(SCORE) DESC)) RK
FROM SC
GROUP BY S#) AS T2
ORDER BY 名次 DESC;
25、查询各科成绩前三名的记录(不考虑成绩并列情况)
答案:最终SQL如下:
SELECT T1.S# AS 学生ID, T1.C# AS 课程ID, SCORE AS 分数
FROM SC T1
WHERE SCORE IN
(SELECT TOP 3 SCORE FROM SC WHERE T1.C# = C# ORDER BY SCORE DESC)
ORDER BY T1.C#;
【DB笔试面试12】根据题目要求写出以下50道SQL语句(26-50)
26、查询每门课程被选修的学生数
答案:最终SQL如下:
SELECT C#, COUNT(S#) FROM SC GROUP BY C#;
27、查询出只选修了一门课程的全部学生的学号和姓名
答案:最终SQL如下:
SELECT SC.S#, STUDENT.SNAME
FROM SC, STUDENT
WHERE SC.S# = STUDENT.S#
GROUP BY SC.S#, STUDENT.SNAME
HAVING COUNT(C#) = 1;
28、查询男生、女生人数
答案:最终SQL如下:
SELECT SUM(CASE WHEN SSEX = ‘男’ THEN 1 ELSE 0) AS 男生人数,
SUM(CASE WHEN SSEX = ‘女’ THEN 1 ELSE 0) AS 女生人数
FROM STUDENT
GROUP BY SSEX;
29、查询姓“张”的学生名单
答案:最终SQL如下:
SELECT SNAME FROM STUDENT WHERE SNAME LIKE ‘张%’;
30、查询同名同性学生名单并统计同名人数
答案:最终SQL如下:
SELECT SNAME, COUNT() FROM STUDENT GROUP BY SNAME HAVING COUNT() > 1;
31、1981年出生的学生名单(注:STUDENT表中SAGE列的类型是DATE)
答案:最终SQL如下:
SELECT SNAME
FROM STUDENT
WHERE TO_CHAR(STUDENT.SAGE,’YYYY’)=’1981’;
32、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时按课程号降序排列
答案:最终SQL如下:
SELECT C#, AVG(SCORE) FROM SC GROUP BY C# ORDER BY AVG(SCORE), C# DESC;
33、查询平均成绩大于85的所有学生的学号、姓名和平均成绩
答案:最终SQL如下:
SELECT SNAME, SC.S#, AVG(SCORE)
FROM STUDENT, SC
WHERE STUDENT.S# = SC.S#
GROUP BY SC.S#, SNAME
HAVING AVG(SCORE) > 85;
34、查询课程名称为“数据库”且分数低于60的学生姓名和分数
答案:最终SQL如下:
SELECT SNAME, NVL(SCORE, 0)
FROM STUDENT, SC, COURSE
WHERE SC.S# = STUDENT.S#
ANDSC.C# = COURSE.C#
AND COURSE.CNAME = ‘数据库’
AND SCORE < 60;
35、查询所有学生的选课情况
答案:最终SQL如下:
SELECT SC.S#,SC.C#, SNAME, CNAME
FROM SC, STUDENT, COURSE
WHERE SC.S# = STUDENT.S#
ANDSC.C# = COURSE.C#;
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
答案:最终SQL如下:
SELECT DISTINCT STUDENT.S#, STUDENT.SNAME,SC.C#, SC.SCORE
FROM STUDENT, SC
WHERE SC.SCORE >= 70
AND SC.S# = STUDENT.S#;
37、查询不及格的课程并按课程号从大到小排列
答案:最终SQL如下:
SELECT C# FROM SC WHERE SCORE < 60 ORDER BY C#;
38、查询课程编号为003且课程成绩在80分以上的学生的学号和姓名
答案:最终SQL如下:
SELECT SC.S#, STUDENT.SNAME
FROM SC, STUDENT
WHERE SC.S# = STUDENT.S#
AND SCORE > 80
AND C# = ‘003’;
39、查询选了课程的学生人数
答案:最终SQL如下:
SELECT COUNT(DISTINCT S#) FROM SC GROUP BY S#;
40、查询选修“李多多”老师所授课程的学生中成绩最高的学生姓名及其成绩
答案:最终SQL如下:
SELECT STUDENT.SNAME, SCORE
FROM STUDENT, SC, COURSE C, TEACHER
WHERE STUDENT.S# = SC.S#
AND SC.C# = C.C#
AND C.T# = TEACHER.T#
AND TEACHER.TNAME = ‘李多多’
AND SC.SCORE = (SELECT MAX(SCORE) FROM SC WHERE C# = C.C#);
41、查询各个课程及相应的选修人数
答案:最终SQL如下:
SELECT C#, COUNT(*) FROM SC GROUP BY C#;
42、查询有2门不同课程成绩相同的学生的学号、课程号、学生成绩
答案:最终SQL如下:
SELECT DISTINCT A.S#, A.C#, B.SCORE
FROM SC A, SC B
WHERE A.SCORE = B.SCORE
AND A.S# = B.S#
AND A.C# <> B.C#;
43、查询每门课程成绩最好的前两名
答案:最终SQL如下:
SELECT T1.S# AS 学生ID, T1.C# AS 课程ID, SCORE AS 分数
FROM (SELECT S#, C#, (RANK() OVER(PARTITION BY C# ORDER BY SCORE DESC)) RK
FROM SC) T1
WHERE RK <= 2;
44、查询每门课程的学生选修人数,超过10人的课程才统计。要求输出课程
号和选修人数,查询结果按人数降序排列,若人数相同按课程号升序排列
答案:最终SQL如下:
SELECT C# AS 课程号, COUNT(*) AS 人数
FROM SC
GROUP BY C#
HAVING COUNT(*)>10
ORDER BY COUNT(*) DESC, C#;
45、查询至少选修两门课程的学生学号
答案:最终SQL如下:
SELECT S# FROM SC GROUP BY S# HAVING COUNT(*) >= 2;
46、查询全部学生都选修的课程的课程号和课程名
答案:最终SQL如下:
SELECT C#, CNAME
FROM COURSE
WHERE C# IN (SELECT C#
FROM (SELECT C#, COUNT(DISTINCT S#) CS# FROM SC GROUP BY C#)
WHERE CS# = (SELECT COUNT(*) FROM STUDENT));
47、查询没学过“李多多”老师讲授的任一门课程的学生姓名
答案:最终SQL如下:
SELECT SNAME
FROM STUDENT
WHERE S# NOT IN (SELECT S#
FROM COURSE, TEACHER, SC
WHERE COURSE.T# = TEACHER.T#
AND SC.C# = COURSE.C#
AND TNAME = ‘李多多’);
48、查询两门以上不及格课程的同学的学号及其平均成绩
答案:最终SQL如下:
SELECT S#, AVG(NVL(SCORE, 0))
FROM SC
WHERE S# IN
(SELECT S# FROM SC WHERE SCORE < 60 GROUP BY S# HAVING COUNT(*) > 2)
GROUP BY S#;
49、检索课程编号为“004”且分数小于60的学生学号,结果按按分数降序排列
答案:最终SQL如下:
SELECT S#
FROM SC
WHERE C# = ‘004’
AND SCORE < 60
ORDER BY SCORE DESC;
50、删除学生编号为“002”的课程编号为“001”的课程的成绩
答案:最终SQL如下:
DELETE FROM SC
WHERE S# = ‘002’
AND C# = ‘001’;
【DB笔试面试13】下列关于NULL的描述中,不正确的是()
下列关于NULL的描述中,不正确的是()
A、当实际值是未知或没有任何意义时,可以使用NULL来表示它
B、不要使用NULL来代表0,两者是不同的
C、不要使用NULL来代替空格,两个是不同的
D、算术表达式2000 + null结果等于2000
NULL代表未知的,无意义,参与运算的结果为NULL。
本题中,对于选项A,NULL表示未知,无意义。所以,选项A错误。
对于选项B,NULL不代表0。所以,选项B错误。
对于选项C,NULL不代表空格。所以,选项C错误。
对于选项D,2000+NULL的结果为NULL。所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试14】PL/SQL中的注释符有()(两个选项)
PL/SQL中的注释符有()(两个选项)
A、–
B、 % %
C、/* */
D、 <– –>
E、#
PL/SQL的注释有2种,分别为–和/* */。
本题中,对于选项B,%%不能表示注释。所以,选项B错误。
对于选项D,<– –>是Java语言中的注释。所以,选项D错误。
所以,本题的答案为A、C。
【DB笔试面试15】下列语句中使用了列别名,会导致错误的有()(两个选项)
下列语句中使用了列别名,会导致错误的有()(两个选项)
A、SELECT EMPNO, ENAME, SAL*12 “Annual Salary” FROM EMP;
B、SELECT EMPNO, ENAME, SAL*12 “AnnualSalary” FROM EMP;
C、SELECT EMPNO, ENAME, SAL*12 ‘Annual Salary’ FROM EMP;
D、SELECT EMPNO, ENAME, SAL*12 ‘AnnualSalary’ FROM EMP;
E、SELECT EMPNO, ENAME, SAL*12 AnnualSalary FROM EMP;
若列的别名中含有空格,则用双引号括起来,不能使用单引号。
本题中,对于选项A,别名中有空格,可以使用双引号。
对于选项B,别名中没有有空格,也可以使用双引号。
对于选项C和选项D,别名不能使用单引号括起来。所以,选项C、选项D错误。
对于选项E,别名可以不加双引号。
所以,本题的答案为C、D。
【DB笔试面试16】下列情况中,会导致Oracle事务结束的有()(两个选项)
A、PL/SQL块结束
B、发出savepoint语句
C、用户强行退出SQL*Plus
D、发出SELECT语句
E、发出commit或rollback语句
事务结束可以采用COMMIT或ROLLBACK,若强行退出SQL*Plus,事务将自动回滚。
本题中,对于选项A,PL/SQL块结束和事务是否结束没有关系。所以,选项A错误。
对于选项B,SAVEPOINT不能结束事务。所以,选项B错误。
对于选项C,用户强行退出SQL*Plus未提交的事务自动回滚。所以,选项C正确。
对于选项D,SELECT语句不能结束事务。所以,选项D错误。
对于选项E,COMMIT或ROLLBACK属于正常提交或回滚事务。所以,选项E正确。
所以,本题的答案为C、E。
【DB笔试面试17】下列对于视图的描述中,错误的是()
下列对于视图的描述中,错误的是()
A、视图可以限制对数据库的访问,因为视图可以选择性的显示数据库的一部分数据
B、视图可以简化用户的查询,允许用户从多个表中检索数据而不需要知道基表是如何连接的
C、可以通过视图实现对基表的DML操作
D、在对视图执行DML操作时,可以不受基表的约束的限制
本题中,对于选项A,视图可以有访问权限,但可以对基表没有访问权限,从而限制了数据库的访问。所以,选项A错误。
对于选项B,由于视图可以是基于多个表的链接查询,所以,视图可以简化用户的查询,允许用户从多个表中检索数据而不需要知道基表是如何连接的。所以,选项B错误。
对于选项C,简单的视图可以实现对基表的DML操作。所以,选项C错误。
对于选项D,当视图执行DML操作时,同样受基于表上的约束的限制。所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试18】约束可以防止无效数据进入表中,维护数据一致性,Oracle提供了若干种约束,下列描述正确的是()
A、主键约束、唯一约束、外键约束、条件约束、非空约束
B、唯一性索引、非唯一性索引、位图索引、位图连接索引、HASH索引
C、列级约束、表级约束、单项约束、组合约束、连接约束
D、主键约束、唯一约束、外键约束、缺省值约束、非空约束
Oracle中的约束包含主键约束、唯一约束、外键约束、条件约束、非空约束。
本题中,对于选项B,非唯一性索引、位图索引、位图连接索引、HASH索引都不属于约束。所以,选项B错误。
对于选项C,列级约束、表级约束、单项约束、组合约束、连接约束多不属于约束。所以,选项C错误。
对于选项D,缺省值约束不属于约束。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试19】下列关于TO_CHAR()、TO_DATE()函数使用过程中不会出错的有()(两个选项)
下列关于TO_CHAR()、TO_DATE()函数使用过程中不会出错的有()(两个选项)
A、SELECT TO_CHAR(SYSDATE,’YYYYMMDDHH24MISS’) FROM DUAL;
B、SELECT TO_CHAR(SYSDATE,’YYYY年MM月DD日 HH24:MI:SS’) FROM DUAL;
C、SELECT TO_CHAR(SYSDATE,’YYYY’年’MM’月’DD’日’ HH24:MI:SS’) FROM DUAL;
D、SELECT TO_DATE(‘20070605113430’,’YYYY###MM###DD##HH24##MISS’) FROM DUAL;
TO_CHAR将日期转换为字符,TO_DATE将字符转换为日期格式。
本题中,对于选项A,可以正常转换。所以,选项A正确。
对于选项B,不能转换,因为会报ORA-01821: date format not recognized错误,有中文的时候需要用双引号括起来。所以,选项B错误。
对于选项C,报错,ORA-00907: 缺失右括号,有中文的时候需要用双引号括起来,正确的写法应该为:“SELECT TO_CHAR(SYSDATE, ‘YYYY”年”MM”月”DD”日”HH24:MI:SS’) FROM DUAL;”。所以,选项C错误。
对于选项D,可以转换,结果为2007-6-5 11:34:30。所以,选项D正确。
所以,本题的答案为A、D。
【DB笔试面试20】下列比较为真的有()
下列比较为真的有()
A、TRUNC(123.56) = 123
B、TRUNC(123.56,1) = 123.6
C、ROUND(123.56) = 123
D、ROUND(123.56,1) = 123.5
本题考察的是TRUNC函数和ROUND函数的知识。其中,TRUNC函数的作用是舍去,不存在四舍五入的情况,ROUND函数截取的时候四舍五入。
本题中,对于选项A,计算结果为123。所以,选项A正确。
对于选项B,保留一位小数,计算结果为123.5。所以,选项B错误。
对于选项C,计算结果为124。所以,选项C错误。
对于选项D,保留一位小数,计算结果为123.6。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试21】一般数据库若出现日志满了,会出现()
一般数据库若出现日志满了,会出现()
A、不能执行任何操作
B、只能执行查询等读操作,不能执行更改,备份等写操作
C、查询,更新等读写操作正常运行
D、只能执行更改,备份等写操作,不能进行查询等读操作
若数据库日志满了的话,则只能执行查询等读操作,不能执行更改、备份等写操作,原因是任何写操作都要记录日志。也就是说,基本上处于不能使用的状态。
本题中,对于选项A,可以查询。所以,选项A错误。
对于选项B,只能执行查询等读操作,不能执行更改、备份等写操作。所以,选项B正确。
对于选项C,更新不能执行。所以,选项C错误。
对于选项D,更改不能执行。所以,选项D错误。
所以,本题的答案为B。
–个人觉得此题出的不严谨,要分为归档模式和非归档模式。
【DB笔试面试22】 SQL语言集数据查询、数据操纵、数据定义和数据控制功能于一体,其中,CREATE、DROP、ALTER
SQL语言集数据查询、数据操纵、数据定义和数据控制功能于一体,其中,CREATE、DROP、ALTER语句实现的是()功能
A、数据查询 DQL
B、数据操纵 DML
C、数据定义 DDL
D、数据控制 DCL
数据操纵语言(DML,Data Manipulation Language):包括INSERT、UPDATE和DELETE,它们分别用于添加、修改和删除表中的行。
事务处理语言(TCL,Transaction Control Language):其语句能确保被DML语句影响的表的所有行及时得以更新,包括BEGIN TRANSACTION、COMMIT和ROLLBACK。
数据控制语言(DCL,Data Control Language):其语句通过GRANT或REVOKE获得许可,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。CREATE、DROP、ALTER属于数据定义语言。
本题中,对于选项A,数据查询是SELECT语句。所以,选项A错误。
对于选项B,数据操纵是DML语句。所以,选项B错误。
对于选项C,数据定义包括CREATE、DROP和ALTER。所以,选项C正确。
对于选项D,数据控制包括GRANT和REVOKE。所以,选项D错误。
所以,本题的答案为C。
【DB笔试面试23】 SQL语言集数据定义功能、数据操纵功能和数据控制功能于一体。如下所列语句中,属于数据控制功能的是()
SQL语言集数据定义功能、数据操纵功能和数据控制功能于一体。如下所列语句中,属于数据控制功能的是()
A、GRANT
B、CREATE
C、INSERT
D、SELECT
本题中,对于选项A,GRANT是数据控制语句。所以,选项A正确。
对于选项B,CREATE是数据定义语句。所以,选项B错误。
对于选项C,INSERT是数据操纵语句。所以,选项C错误。
对于选项D,SELECT是数据查询语句。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试24】 Oracle实例启动和关闭的信息记载到()中
Oracle实例启动和关闭的信息记载到()中
A、告警文件
B、后台进程跟踪文件
C、服务器进程跟踪文件
D、参数文件
数据库启动和关闭的信息记录在告警日志里。
本题中,对于选项A,告警日志是正确的。所以,选项A正确。
对于选项B,后台跟踪文件记录的是数据库后台进程信息。所以,选项B错误。
对于选项C,服务器进程跟踪的是用户的进程信息。所以,选项C错误。
对于选项D,参数文件记录的是数据库的参数。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试25】下列有关InnoDB和MyISAM的说法中,正确的是()(多选题)
下列有关InnoDB和MyISAM的说法中,正确的是()(多选题)
A、InnoDB不支持FULLTEXT类型的索引
B、InnoDB执行DELETE FROM TABLE 命令时,不会重新建表
C、MyISAM的索引和数据是分开保存的
D、MyISAM支持主外键,索引及事务的存储
MySQL有多种存储引擎,每种存储引擎有各自的优缺点。MySQL存储引擎包括处理事务安全表的引擎和处理非事务安全表的引擎。MyISAM引擎管理非事务表。它提供高速存储和检索,以及全文搜索能力。InnoDB引擎支持行锁,支持事务,CRASH后具有RECOVE机制,有较好的读写并发能力。物理文件主要包括日志文件、数据文件和索引文件,索引文件和数据文件是放在一个目录下,可以设置共享文件与独享文件两种格式。
本题中,对于选项A,InnoDB不支持FULLTEXT类型的索引。所以,选项A正确。
对于选项B,当InnoDB执行DELETE FROM TABLE命令时,不会重新建表。所以,选项B正确。
对于选项C,MyISAM的索引和数据是分开保存的。所以,选项C正确。
对于选项D,MyISAM不支持事务。所以,选项D错误。
所以,本题的答案为A、B、C。
【DB笔试面试26】从客户端通过SQL*Plus登陆Oracle某个特定用户,必须要提供的信息有()
从客户端通过SQL*Plus登陆Oracle某个特定用户,必须要提供的信息有()
A、用户名、口令、监听
B、用户名、监听、端口号
C、用户名、口令、本地服务名
D、用户名、口令、目录方法名配置
SQL*Plus连接Oracle服务器的命令形如sqlplus user/password@tns_name。
本题中,对于选项A,监听不需要。所以,选项A错误。
对于选项B,监听不需要。所以,选项B错误。
对于选项C,用户名、口令和本地服务名都是需要的。所以,选项C正确。
对于选项D,目录方法名配置不需要。所以,选项D错误。
所以,本题的答案为C。
【DB笔试面试27】下列选项中,不属于SQL语句的是()
下列选项中,不属于SQL语句的是()
A、DESC
B、SELECT
C、ALTER TABLE
D、TRUNCATE
常用的SQL语句有SELECT、DELETE、UPDATE、ALTER、TRUNCATE等。
本题中,对于选项A,DESC是SQL*Plus命令,不属于SQL语句。所以,选项A正确。
对于选项B,SELECT是SQL语句。所以,选项B错误。
对于选项C,ALTER是SQL语句。所以,选项C错误。
对于选项D,TRUNCATE是SQL语句。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试28】下列关于SQL语句书写规则的描述中,正确的是()
下列关于SQL语句书写规则的描述中,正确的是()
A、SQL语句区分大小写,要求关键字必须大写,对象名小写
B、SQL语句必须在一行书写完毕,并且用分号结尾
C、SQL语句的缩进可以提高语句的可读性,并且可以提高语句的执行性能
D、SQL语句中为了提高可读性,通常会把一些复杂的语句中每个子句写在单独的行上
SQL语句大小写不敏感,最后以分号结尾,可以书写多行。
本题中,对于选项A,SQL语句不区分大小写。所以,选项A错误。
对于选项B,SQL语句可以书写多行。所以,选项B错误。
对于选项C,SQL语句缩进可以提高可读性,但不能提高其执行效率。所以,选项C错误。
对于选项D,为了提高SQL的可读性,会把一些复杂语句中每个子句写在单独的行上。所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试29】在客户端配置本地服务名时,下列信息中,不需要提供的是()
在客户端配置本地服务名时,下列信息中,不需要提供的是()
A、服务器地址
B、服务器监听的端口号
C、网络协议
D、服务器端目录配置
E、ORACLE_SID或数据库服务名
配置TNS的时候需要提供服务器地址,监听的端口号,网络协议一般是TCP/IP,还有数据库的SERVICE_NAME,其一般形式如下所示:
**orclasm =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.59.130)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orclasm.lhr.com)
)
)**
本题中,对于选项A,服务器地址是需要的。所以,选项A错误。
对于选项B,监听端口号是需要的。所以,选项B错误。
对于选项C,网络协议是需要的。所以,选项C错误。
对于选项D,目录配置不需要。所以,选项D正确。
对于选项E,ORACLE_SID或数据库服务名是需要的。所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试30】下列SQL命令中,能够在SQL*PLUS环境下执行特定的脚本文件的是()(两个选项)
下列SQL命令中,能够在SQL*PLUS环境下执行特定的脚本文件的是()(两个选项)
A、@
B、START
C、RUN
D、/
E、EXECUTE
SQL命令行中能执行特定脚本的命令只有@和start。
本题中,对于选项A,@是可以执行脚本的。所以,选项A正确。
对于选项B,START是可以执行脚本的。所以,选项B正确。
对于选项C,RUN只能执行SQL命令。所以,选项C错误。
对于选项D,/不能执行脚本。所以,选项D错误。
对于选项E,EXECUTE只能执行存储过程。所以,选项D正确。
所以,本题的答案为A、B。
【DB笔试面试31】下面是EMP雇员表的信息,依靠这些信息完成下面的试题:
下面是EMP雇员表的信息,依靠这些信息完成下面的试题:
EMP雇员表的结构如下所示:
EMPNO 数值型 – 雇员ID
ENAME 字符型 – 雇员姓名
JOB 字符型 – 工作岗位
MGR 数值型 – 上级领导ID
HIREDATE 日期型 – 雇用日期
SAL 数值型 – 薪水
COMM 数值型 – 奖金
DEPTNO 数值型 – 部门编号
EMP雇员表的数据如下所示:
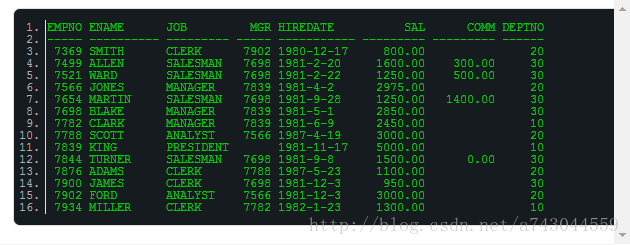
1、下面的语句能执行成功吗?
SELECT ENAME, JOB, SAL SALARY FROM EMP;
2、下面语句选取雇员编号、雇员姓名、年薪水总合,其中有3处错误,请找出并纠正它们:
SELECT EMPNO,ENAME
SAL X 12 ANNUAL SALARY
FROM EMP;
3、用一个查询语句显示EMP 表中总共有哪些工作?
4、用一个查询语句显示工作岗位为CLERK或者ANALYST并且工资不等于1000、3000、5000的雇员的姓名、工作岗位、工资?
5、用一个查询语句显示工资最高的前3位雇员的姓名、工作岗位、工资?
1、答案:可以执行。
2、答案:列的别名若含有空格应该用双引号括起来,乘号应该为*,所以,正确的语句如下所示:
SELECT EMPNO,ENAME,SAL *12 “Annual Salary” FROM EMP;
3、答案:SELECT DISTINCT A.JOB FROM EMP A;。
4、答案: SELECT A.ENAME,A.JOB,A.SAL FROM EMP A WHERE A.JOB IN (‘CLERK’,’ANALYST’) AND A.SAL NOT IN (1000,3000,5000);。
5、答案:SELECT * FROM (
SELECT A.ENAME,A.JOB,A.SAL FROM SCOTT.EMP A ORDER BY A.SAL DESC ) WHERE ROWNUM<=3;。
【DB笔试面试32】Which of the following are valid program types for a lightweight job?
Which of the following are valid program types for a lightweight job? (Choose all that apply)
A、PLSQL_BLOCK
B、EXECUTABLE
C、JAVA_STORED_PROCEDURE
D、STORED_PROCEDURE
E、EXTERNAL
题目问的是JOB中的程序类型可以有哪些,只能包含PLSQL_BLOCK和STORED_PROCEDURE这2类。
本题中,对于选项A,PLSQL_BLOCK是JOB中可以使用的程序类型。所以,选项A正确。
对于选项B,EXECUTABLE不能用于JOB的程序。所以,选项B错误。
对于选项C,JAVA_STORED_PROCEDURE不能用于JOB的程序。所以,选项C错误。
对于选项D,STORED_PROCEDURE 存储过程是JOB中可以使用的程序类型。所以,选项D正确。
对于选项E,EXTERNAL不能用于JOB的程序。所以,选项E错误。
所以,本题的答案为A、D。
【DB笔试面试33】Which three components does the Scheduler use for managing tasks within the Oracle environment? (Choose three)
A、a job
B、a program
C、a schedule
D、a PL/SQL procedure
本题翻译为中文如下:在Oracle环境调度程序为管理任务使用哪三个组件()
A、A JOB作业B、A PROGRAM程序C、A SCHEDULE调度D、A PL/SQL程序
核心组件和主要步骤:
一个作业包含两个必需组件:需要执行的操作,操作的发生时间或调度。“操作”是由命令区域和作业属性中的JOB_TYPE和JOB_ACTION参数表示的。“时间”是在调度中表示的,调度可以基于时间或事件,或者从属于其它作业的结果。
调度程序使用以下基本组件:
(1)“作业”指定要执行的操作。它可以是PL/SQL过程、纯二进制可执行文件、Java应用程序或SHELL脚本。可以将程序(内容)和调度(时间)指定为作业定义的一部分,也可以改用现有的程序或调度。
(2)“调度”指定作业的执行时间和次数。调度可以基于时间或事件,可以为作业定义调度,方法是使用一系列日期、一个事件,或两者相结合,以及表示重复间隔的附加说明。可以单独存储作业的调度,然后对多个作业使用同一个调度。
(3)“程序”是有关特定可执行文件、脚本或过程的元数据集合。自动作业将执行某个任务。使用程序,无需修改作业本身即可修改作业任务或者“内容”。
本题中,对于选项A,A JOB作业是调度程序的组件。所以,选项A正确。
对于选项B,A PROGRAM程序是调度程序的组件。所以,选项B正确。
对于选项C,A SCHEDULE调度是调度程序的组件。所以,选项C正确。
对于选项D,A PL/SQL程序不是调度程序的组件。所以,选项D错误。
所以,本题的答案为A、B、C。
【DB笔试面试34】Oracle系统进程和作用的描述,说法正确的有()(多选题)
Oracle系统进程和作用的描述,说法正确的有()(多选题)
A、数据写进程(dbwr):负责将更改的数据从数据库缓冲区高速缓存写入数据文件
B、进程监控(pmon):负责在一个Oracle进程失败时清理资源
C、归档进程(arcn):在每次日志切换时把已满的日志组进行备份或归档
D、系统监控(smon):检查数据库的一致性如有必要还会在数据库打开时启动数据库的恢复
Oracle的进程比较多,常用的有如下几类:
(1)数据写进程(dbwr):负责将更改的数据从数据库缓冲区高速缓存写入数据文件。
(2)监控进程(pmon):负责在一个Oracle进程失败时清理资源。
(3)归档进程(arcn):在每次日志切换时把已满的日志组进行备份或归档。
(4)系统监控(smon):检查数据库的一致性如有必要还会在数据库打开时启动数据库的恢复。
除此之外,Oracle数据库还有其它一些进程,作用如下所示:
(1)检查点进程(ckpt):负责在每当缓冲区高速缓存中的更改永久地记录在数据库中时,更新控制文件和数据文件中的数据库状态信息。
(2)恢复进程(reco):保证分布式事务的一致性,在分布式事务中,要么同时COMMIT,要么同时ROLLBACK。
(3)作业调度器(cjq):负责将调度与执行系统中已定义好的JOB,完成一些预定义的工作。
(4)日志写进程(lgwr):将REDO日志缓冲区中的更改写入在线REDO日志文件。
本题中,对于选项A,数据写进程负责将更改的数据从数据库缓冲区高速缓存写入数据文件。所以,选项A正确。
对于选项B,监控进程负责在一个Oracle进程失败时清理资源。所以,选项B正确。
对于选项C,归档进程在每次日志切换时把已满的日志组进行备份或归档。所以,选项C正确。
对于选项D,系统监控进程检查数据库的一致性,如有必要,还会在数据库打开时启动数据库的恢复。所以,选项D正确。
所以,本题的答案为A、B、C、D。
【DB笔试面试35】下列关于数据字典的叙述中,哪一条是错误的?()
下列关于数据字典的叙述中,哪一条是错误的?()
A、数据库中的数据可分为用户数据和系统数据
B、用户数据是用户使用的数据
C、系统数据包括数据描述信息、控制信息、存储信息等
D、用户数据和系统数据总称为数据字典
数据库中的数据通常可分为用户数据和系统数据两部分,其中系统数据就可以称为数据字典。数据字典(Data dictionary)是一种用户可以访问的记录数据库和应用程序元数据的目录。数据字典是指对数据的数据项、数据结构、数据流、数据存储、处理逻辑、外部实体等进行定义和描述。其目的是对数据流程图中的各个元素做出详细的说明。数据字典可以分为主动和被动数据字典。主动数据字典是指在对数据库或应用程序结构进行修改时,其内容可以由DBMS自动更新的数据字典。被动数据字典是指修改时必须手工更新其内容的数据字典。数据字典包括对数据库的描述信息、数据库的存储管理信息、数据库的控制信息、用户管理信息和系统事务管理信息等,所以数据字典也可以称为系统目录。
本题中,对于选项D,系统数据才可以称为数据字典,而用户数据不属于数据字典的范畴,选项描述错误。所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试36】下列关于E-R模型和E-R图的叙述中,哪一条是错误的?()
下列关于E-R模型和E-R图的叙述中,哪一条是错误的?()
A、E-R模型是一种图示化模型
B、实体和相应的属性之间用有向边连接起来
C、联系型本身也是一种实体型
D、E-R模型可用以表示概念模型
E-R模型是一种用图形表示数据及其联系的方法,所使用的图形构件包括矩形、菱形、椭圆形和连接线。其中,矩形表示实体,矩形框内写上实体名。菱形表示联系,菱形框内写上联系名。椭圆形表示属性,椭圆形框内写上属性名。连接线表示实体,联系与属性之间的所属关系,或实体与联系之间的相连关系。
本题中,对于选项B,实体和相应的属性之间用无向边连接起来,而不是有向边,选项描述错误。所以,选项B正确。
所以,本题的答案为B。
【DB笔试面试37】下列关于关系模型的参照完整性规则的叙述中,哪一条是错误的?()
下列关于关系模型的参照完整性规则的叙述中,哪一条是错误的?()
A、外键和相应的主键需定义在相同值域上
B、外键和相应的主键可以不同名
C、参照关系模式和被参照关系模式可以是同一个关系模式
D、外键值不可以为空值
外键可以为空,其它选项说法正确。
答案:D。
【DB笔试面试38】 创建表T1,并使得表中EMPLOYID字段值非空且唯一的SQL语句是下列哪一个?
创建表T1,并使得表中EMPLOYID字段值非空且唯一的SQL语句是下列哪一个?()
A、CREATE TABLE T1 (EMPLOYID INTEGER);
B、CREATE TABLE T1 (EMPLOYID UNIQUE INTEGER);
C、CREATE TABLE T1 (EMPLOYID INTEGER NOT NULL);
D、CREATE TABLE T1 (EMPLOYID INTEGER, PRIMARY KEY(EMPLOYID);
非空且唯一就创建主键,其它选项均有误。
答案:D。
【DB笔试面试39】 删除STUDENT表的DEPT列,但是只有在没有视图或约束引用该列时才能执行删除,否则拒绝删除。正确表述上述需求的SQL语句是下列哪一个?()
A、ALTER TABLE STUDENT DROP DEPT RESTRICT;
B、ALTER TABLE STUDENT DELETE DEPT RESTRICT;
C、ALTER TABLE STUDENT DROP DEPT CASCADE;
D、ALTER TABLE STUDENT DELETE DEPT CASCADE;
删除列使用DROP,排除B和D,有约束存在的时候使用RESTRICT,所以答案为A。
答案:A。
【DB笔试面试40】请问正确实现“查询张三同学没有选修的课程的课程号”的SQL语句是下列哪一个?
设教学数据库中有三个基本表:
学生表S(SNO,SNAME,AGE,SEX),其属性分别表示学号、学生姓名、年龄、性别;
课程表C(CNO,CNAME,TEACHER),其属性分别表示课程号、课程名、上课教师名;
选修表SC(SNO,CNO,GRADE),其属性分别表示学号、课程号、成绩。请问正确实现“查询张三同学没有选修的课程的课程号”的SQL语句是下列哪一个?()
A、SELECT CNO
FROM C, SC, S
WHERE C.CNO!= SC.CNO AND S.SNO=SC.SNO
AND SNAME=’张三’;
B、SELECT CNO
FROM C
WHERE CNO != (SELECT CNO
FROM S, SC
WHERE S.SNO=SC.SNO AND SNAME=’张三’);
C、SELECT CNO
FROM C
WHERE CNO NOT IN (SELECT CNO
FROM S, SC
WHERE S.SNO=SC.SNO AND SNAME=’张三’);
D、SELECT CNO
FROM C, SC, S
WHERE C.CNO NOT IN SC.CNO
AND S.SNO=SC.SNO AND SNAME=’张三’;
本题中,对于选项A,“!=”用在这里逻辑不正确。所以,选项A错误。
对于选项B,子查询返回多行记录,不能用“!=”。所以,选项B错误。
对于选项D,缺少连接条件。所以,选项D错误。
所以,本题的答案为C。
【DB笔试面试41】下列实现“将学生的学号和他的平均成绩定义为一个视图”功能的SQL语句中哪一个是正确的?()
有关系SC(S#,C#,GRADE),其中S#是学号,C#是课程号,GRADE是课程成绩。下列实现“将学生的学号和他的平均成绩定义为一个视图”功能的SQL语句中哪一个是正确的?()
A、CREATE VIEW S_G(S#, AVGGRADE)
AS
SELECT S#, AVG(GRADE) FROM SC
GROUP BY S#;
B、CREATE VIEW S_G(S#, AVGGRADE)
SET
SELECT S#, AVG(GRADE) FROM SC
GROUP BY S#;
C、CREATE VIEW S_G(S#, AVGGRADE)
HAVING
SELECT S#, AVG(GRADE) FROM SC
ORDER BY S#;
D、CREATE VIEW S_G(S#, AVGGRADE)
AS
SELECT S#, AVG(GRADE) FROM SC
ORDER BY S#;
本题中,对于选项B,不能使用SET,应该为AS。所以,选项B错误。
对于选项C,不能使用HAVING,应该为AS,所以,选项C正确。
对于选项D,有分组函数必须使用GROUP BY。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试42】下面哪一个语句是SQL标准中用来调用存储过程的()
因为存储过程由DBMS持久地存储,所以能够使用各种SQL接口和程序设计进行调用。下面哪一个语句是SQL标准中用来调用存储过程的()
A、CALL
B、FETCH
C、OPEN
D、EXEC SQL
SQL标准中用来调用存储过程的命令是CALL。
【DB笔试面试43】事务的持久性是指()
A、事务中包括的所有操作要么都做,要么都不做
B、事务一旦提交,对数据库的修改就是永远的
C、一个事务内部的操作及使用的数据对并发执行的其他事务是隔离的
D、事务必须是使数据库从一个一致性状态变到另一个一致性状态
事务的持久性(也叫永久性)是指一旦事务提交成功,其对数据修改是持久性的。数据更新的结果已经从内存转存到外部存储器上,此后即使发生了系统故障,已提交事务所做的数据更新也不会丢失
【DB笔试面试44】根据数据库应用系统生命周期模型,完成数据库关系模式设计的阶段是()
根据数据库应用系统生命周期模型,完成数据库关系模式设计的阶段是()
A、需求分析
B、概念设计
C、逻辑设计
D、物理设计
数据库应用系统生命周期分成七个阶段:规划、需求分析、概念设计、逻辑设计、物理设计、实现、运行和维护。其中,逻辑设计阶段的主要任务是将现实世界的概念数据模型设计成数据库的一种逻辑模式,即适应于某种特定数据库管理系统所支持的逻辑数据模式。这一步设计的结果就是所谓“逻辑数据库”。根据已经建立的概念数据模型,以及所采用的某个数据库管理系统软件的数据模型特性,按照一定的转换规则,把概念模型转换为这个数据库管理系统所能够接受的逻辑数据模型。不同的数据库管理系统提供了不同的逻辑数据模型,例如层次模型、网状模型、关系模型等。逻辑设计的目的是把概念设计阶段设计好的基本E-R图转换为与选用的具体机器上的DBMS所支持的数据模型相符合的逻辑结构(包括数据库模式和外模式)。所以,本题的答案为C。
【DB笔试面试45】以下关于死锁检测和恢复叙述错误的是()
以下关于死锁检测和恢复叙述错误的是()
A、死锁检测,用于定期检查系统是否发生死锁
B、死锁恢复,用于将系统从死锁中解救出来
C、解开系统死锁有效的方法是从后面向前REDO事务的部分操作
D、为了防止某些事务总是被选做被撤销事务,可以限定每个事务被选为撤销事务的次数
对于每个需要撤销的死锁事务,可以简单地放弃该事务已经完成的全部操作,重新启动该事务,更为有效的方法是从后面UNDO这个事务的部分操作,只要能够解开系统死锁即可。
【DB笔试面试46】存储过程是存储在数据库中的代码,具有很多优点。下列陈述中不属于存储过程优点的是()
存储过程是存储在数据库中的代码,具有很多优点。下列陈述中不属于存储过程优点的是()
A、可通过预编译机制提高数据操作的性能
B、可方便地按用户视图表达数据
C、可减少客户端和服务器端的网络流量
D、可实现一定的安全控制
存储过程的优点如下所示:
① 存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
② 存储过程可保证数据的安全性。
③ 通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。
④ 通过存储过程可以使相关的动作在一起发生,从而可以维护数据库的完整性。
⑤ 在运行存储过程前,数据库已对其进行了语法和句法分析,并给出了优化执行方案。这种已经编译好的过程可极大地改善SQL语句的性能。由于执行SQL语句的大部分工作已经完成,所以,存储过程能以极快的速度执行。
⑥ 可以降低网络的通信量,不需要通过网络来传送很多SQL语句到数据库服务器了。
⑦ 把体现企业规则的运算程序放入数据库服务器中,以便集中控制。
因此本题答案为B。
【DB笔试面试47】事务的一致性是指()
事务的一致性是指()
A、事务中包括的所有操作要么都做,要么都不做
B、事务必须是数据库从一个一致性状态变到另一个一致性状态
C、事务一旦提交,对数据库的改变是永久的
D、一个事务内部的操作及使用的数据对并发的其他事务是隔离的
事务的特征有四个,即原子性,一致性,隔离性,持久性。事务是一种逻辑上的工作单元。一个事务就是一系列在逻辑上相关的操作指令的集合,用于完成一项任务,其本质是将数据库中的数据从一种一致状态转换到另一种一致状态,以体现现实世界中的状况变化。至于数据处于什么样的状态算是一致状态,这取决于现实生活中的业务逻辑以及具体的数据库内部实现。所以,一致性是为了让数据库不会因事务执行而遭到破坏,事务应使数据库从一个一致性状态转到另一个一致性状态。
【DB笔试面试48】下面哪个选项中的内容填入SQL语句中是正确的()
设有图书管理数据库:
图书(总编号C(6),分类号C(8),书名C(16),作者C(6),出版单位C(20),单价N(6,2))
读者(借书证号C(4),单位C(8),姓名C(6),性别C(2),职称C(6),地址C(20))
借阅(借书证号C(4),总编号C(6),借书日期D(8))
有SQL语句如下:SELECT 单位,__ FROM 借阅,读者 WHERE
借阅.借书证号=读者.借书证号 __;
对于图书管理数据库,分别求出各个单位当前借阅图书的读者人次。下面哪个选项中的内容填入SQL语句中是正确的()
A、COUNT(借阅.借书证号) GROUP BY 单位
B、SUM(借阅.借书证号) GROUP BY 单位
C、COUNT(借阅.借书证号) ORDER BY 单位
D、COUNT(借阅.借书证号) HAVING 单位
分组用GROUP BY,计算个数用COUNT函数。
【DB笔试面试49】在Oracle中,你需要创建索引提高薪水审查的性能,该审查要对员工薪水提高12个百分点后进行分析处理
在Oracle中,你需要创建索引提高薪水审查的性能,该审查要对员工薪水提高12个百分点后进行分析处理,下面哪个CREATE INDEX命令能解决此问题()
A、CREATE INDEX MY_IDX_1 ON EMPLOYEE(SALARY*1.12);
B、CREATE UNIQUE INDEX MY_IDX_1 ON EMPLOYEE(SALARY);
C、CREATE BITMAP INDEX MY_IDX_1 ON EMPLOYEE(SALARY);
D、CREATE INDEX MY_IDX_1 ON EMPLOYEE(SALARY) REVERSE;
对员工薪水提高12个百分点后进行分析处理,则只能创建函数索引。
显然,本题的答案为A。
【DB笔试面试50】哪个函数的返回值不等于-97()
在Oracle中,执行下面的语句:
SELECT ceil(-97.342),
floor(-97.342),
round(-97.342),
trunc(-97.342)
FROM dual;
哪个函数的返回值不等于-97()
A、ceil()
B、floor()
C、round()
D、trunc()
考察对基本函数的理解。
本题中,对于选项A,CEIL函数返回大于或等于指定表达式的最小整数,大于-97.342的最小整数为-97。所以,选项A错误。
对于选项B,FLOOR函数返回不大于指定表达式的最大整数,这里不大于-97.342的最大整数为-98。所以,选项B正确。
对于选项C,ROUND函数根据四舍五入原则进行取舍,结果为-97。所以,选项C错误。
对于选项D,TRUNC函数根据直接舍去的原则进行取舍,结果为-97,选项D错误。
所以,本题的答案为B。
【DB笔试面试51】请问序列MY_SEQ的当前值是()
在Oracle中,用以下SQL命令创建了一个序列:
CREATE SEQUENCE MY_SEQ
START WITH 394
INCREMENT BY 12
NOMINVALUE
NOMAXVALUE
NOCYCLE
NOCACHE;
用户执行包含MY_SEQ.NEXTVAL的SQL语句三次,然后执行包含MY_SEQ.CURRVAL的SQL语句四次,请问序列MY_SEQ的当前值是()
A、406 B、418 C、430 D、442
MY_SEQ序列创建后的初始化值是394,第一次执行SELECT MY_SEQ.NEXTVAL FROM DUAL后,MY_SEQ的值其实还是394,从第二次开始增加,而MY_SEQ.CURRVAL并不增加序列的值,所以最终结果为394+12*2=418,所以,本题的答案为B。
实验过程如下所示:
SYS@oralhr> CREATE SEQUENCE MY_SEQ
2 START WITH 394
3 INCREMENT BY 12
4 NOMINVALUE
5 NOMAXVALUE
6 NOCYCLE
7 NOCACHE;
Sequence created.
SYS@oralhr> select MY_SEQ.NEXTVAL from dual;
NEXTVAL
394
SYS@oralhr> select MY_SEQ.NEXTVAL from dual;
NEXTVAL
406
SYS@oralhr> select MY_SEQ.NEXTVAL from dual;
NEXTVAL
418
SYS@oralhr> select MY_SEQ.CURRVAL from dual;
CURRVAL
418
SYS@oralhr> select MY_SEQ.CURRVAL from dual;
CURRVAL
418
SYS@oralhr> select MY_SEQ.CURRVAL from dual;
CURRVAL
418
SYS@oralhr> select MY_SEQ.CURRVAL from dual;
CURRVAL
418
【DB笔试面试52】在Oracle中,下列哪种标量类型不能保存到数据库表中()
在Oracle中,下列哪种标量类型不能保存到数据库表中()
A、CHAR B、RAW C、DATE D、BOOLEAN
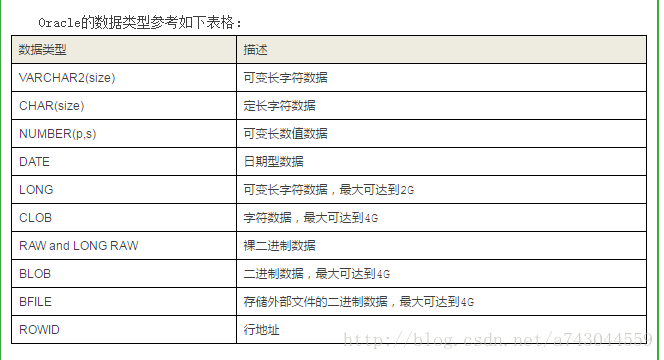
数据类型的作用在于指明存储数值时需要占据的内存空间大小和进行运算的依据。
1) CHAR(n)数据类型用于定义固定长度的字符串,其中,n用于指定字符串的最大长度,n的值必须是正整数且不超过32767。
2) VARCHAR2(n)数据类型用于定义可变长度的字符串,其中,n用于指定字符串的最大长度,n的值必须是正整数且不超过32767。
3) NUMBER(precision,scale)数据类型用于定义固定长度的整数和浮点数,其中,precision表示精度,用于指定数字的总位数;scale表示标度,用于指定小数点后的数字位数,默认值为0,即没有小数位数。
4) DATE该数据类型用于定义日期时间类型的数据,其数据长度为固定7个字节,分别描述年、月、日、时、分、秒。
5) TIMESTAMP该数据类型也用于定义日期时间数据,但与DATE仅显示日期不同,TIMESTAMP类型数据还可以显示时间和上下午标记,如“11-9月-2007 11:09:32.213 AM”。
6) BOOLEAN数据类型用于定义布尔型(逻辑型)变量,其值只能为TRUE(真)、FALSE(假)或NULL(空)。需要注意的是,该数据类型是PL/SQL数据类型,不能应用于表列。
7) LONG数据类型在其它的数据库系统中常被称为备注类型,它主要用于存储大量的可以在稍后返回的文本内容。
8) LONG RAW数据类型在其它数据库系统中常被称为大二进制类型(BLOB),它可以用来存储图形、声音视频数据,尽管关系型数据库管理系统最初不是为它们而设计的,但是多媒体数据可以存储在BLOB或LONG RAW类型的字段内。
9) ROWID数据类型常用在可以将表中的每一条记录都加以唯一标识的场合许多关系型。
对于D选项的BOOLEAN是布尔类型,属于PL/SQL的数据类型,不能保存到数据库表中,所以本题的答案为D。
【DB笔试面试53】在Oracle中,不属于游标属性的是()
在Oracle中,不属于游标属性的是()
A、%NOTFOUND B、%FOUND C、%ISCLOSE D、%ISOPEN
考察对游标属性的理解。
游标是维护查询结果的内存中的一个区域,运行DML时打开,完成时关闭,用SQL%ISOPEN检查是否打开,游标有如下4个属性:
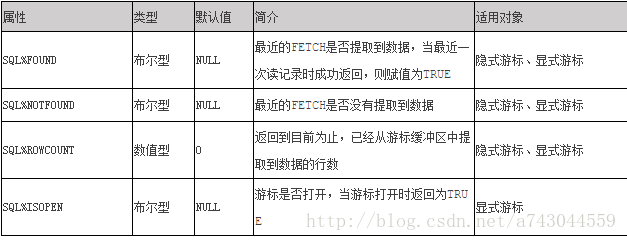
当执行一条DML语句后,DML语句的结果保存在四个游标属性中,这些属性用于控制程序流程或者了解程序的状态。当运行DML语句时,PL/SQL打开一个内建游标并处理结果,游标是维护查询结果的内存中的一个区域,游标在运行DML语句时打开,完成后关闭。隐式游标只使SQL%FOUND,SQL%NOTFOUND,SQL%ROWCOUNT三个属性.SQL%FOUND,SQL%NOTFOUND是布尔值,SQL%ROWCOUNT是整数值。
显然,本题的答案为C。
【DB笔试面试54】 把对表STUDENT的INSERT权限授予用户user4,并允许其将此权限再授予其他用户。正确表达了这一要求的SQL语句是下列哪一个?()
A、GRANT TABLE STUDENT WITH INSERT TO user4
B、GRANT TABLE STUDENT HAVING INSERT TO user4 WITH GRANT OPTION
C、GRANT INSERT ON TABLE STUDENT TO user4 WITH GRANT OPTION
D、GRANT INSERT ON TABLE STUDENT TO user4
赋权操作为GRANT权限ON TABLE xxx TO USER_XX。若允许其将此权限再授予其他用户则需要带WITH GRANT OPTION子句,所以很显然本题的答案为C。
【DB笔试面试55】在数据库设计的概念结构设计阶段,表示概念结构的常用方法和描述工具是()
在数据库设计的概念结构设计阶段,表示概念结构的常用方法和描述工具是()
A、层次分析法和层次结构图 B、实体-联系方法和E-R图
C、结构分析法和模块结构图 D、数据流程分析法和数据流图
表示概念结构的常用方法是实体-联系方法,即E-R图,所以很显然本题的答案为B。
【DB笔试面试56】 下列关于数据库三级模式结构的叙述中,哪些是正确的?()(多选题)
下列关于数据库三级模式结构的叙述中,哪些是正确的?()(多选题)
A、三级模式指的外模式、模式和内模式
B、外模式是唯一的,但是数据库用户视图可以有多个
C、内模式称为物理模式,一个数据库只有一个内模式
D、模式是数据库的逻辑视图,一个数据库可以有多个模式
E、数据库的三级模式以及模式之间的映像可以保证数据具有较高的数据独立性
数据库系统的三级模式结构是指数据库系统是由外模式、模式和内模式三部分构成。
(1)外模式(External Schema)
外模式也称子模式(Subschema)或用户模式,它是数据库用户(包括应用程序员和最终用户)最终能够看见的和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。外模式面向具体的应用程序,它定义在模式之上,但独立于存储模式和存储设备。设计外模式时应充分考虑到应用的扩充性。外模式通常是模式的子集。一个数据库可以有多个外模式。外模式是保证数据库安全性的一个有力措施。
(2)模式(Schema)
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。它是数据库系统模式结构的中间层,既不涉及数据的物理存储细节和硬件环境,也与具体的应用程序、所使用的应用开发工具以及高级程序设计语言无关。模式是数据库的中心与关键,它独立于数据库的其他层次。设计数据库模式结构时应首先确定数据库的模式。模式实际上是数据库数据在逻辑级上的视图。一个数据库只有一个模式。数据库模式以某一种数据模型为基础,统一综合地考虑了所有用户的需求,并将这些需求有机地结合成一个逻辑整体。模式定义包括数据的逻辑结构定义、数据之间的联系定义以及安全性、完整性要求的定义。
(3)内模式(Internal Schema)
内模式也称存储模式(Storage Schema),一个数据库只有一个内模式,它是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。内模式依赖于它的全局逻辑结构,但独立于数据库的用户视图即外模式,也独立于具体的存储设备。例如,记录的存储方式是顺序存储、按照B树结构存储还是按HASH方法存储;索引按照什么方式组织;数据是否压缩存储,是否加密;数据的存储记录结构有何规定等。
数据库系统的三级模式是对数据的三个抽象级别,它把数据的具体组织留给DBMS管理,使用户能逻辑抽象地处理数据,而不必关心数据在计算机中的表示和存储。为了能够在内部实现这三个抽象层次的联系和转换,数据库系统在这三级模式之间提供了二级映象:外模式/模式映象和模式/内模式映象。正是这两层映象保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。
【DB笔试面试57】下列关于SQL语言特点的描述中,哪些是正确的?()(多选题)
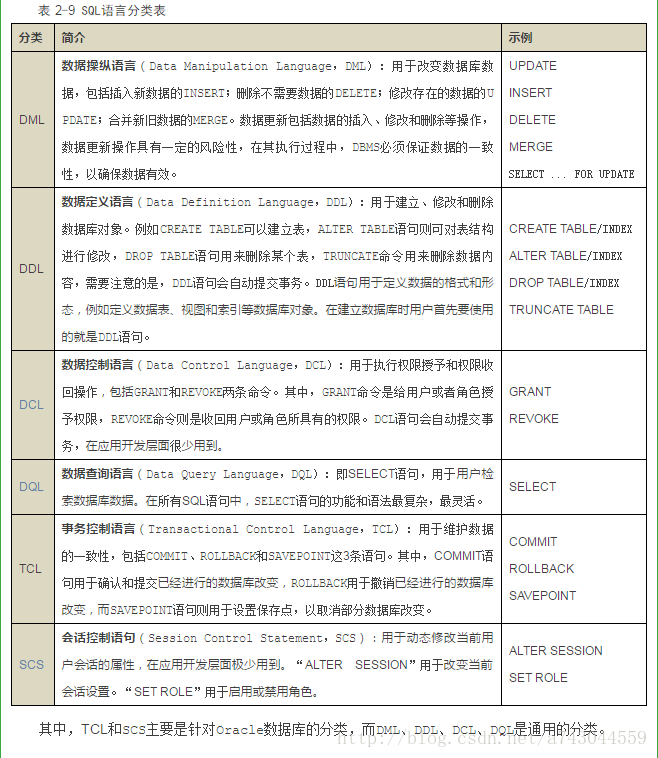
关系数据库标准语言SQL是一个综合的、通用的、功能极强同时又简洁易学的语言。下列关于SQL语言特点的描述中,哪些是正确的?()(多选题)
A、分为模式数据定义语言、外模式数据定义语言、与存储有关的描述语言以及数据操纵语言
B、它可以定义关系模式、录入数据、查询、更新、维护、数据库重构、数据库安全控制等一系列操作要求
C、是一种采用面向记录的操作方式的语言
D、既是自含式语言,又是嵌入式语言
E、具有数据查询、数据定义、数据操纵和数据控制功能
SQL(Structure Query Language,结构化查询语言)是一种在关系型数据库中定义和操纵数据的标准语言。
关系型数据库采用结构化查询语言即SQL作为客户端程序与数据库服务器间沟通的标准接口——客户端发送SQL指令到服务器端,服务器端执行相关的指令并返回其查询的结果。在数据库服务器端执行的SQL指令可以实现各种数据库操作和管理功能,例如:数据的查询和更新(包括添加、修改和删除数据)操作;创建、修改和删除各种数据库对象(如数据表、视图、索引等);数据库用户账户管理、权限管理等。
关系数据语言的共同特点是:语言具有完备的表达能力,是非过程化的集合操作语言,功能强,能够嵌入高级语言中使用。
【DB笔试面试58】SQL Server 2000 提供了完全备份、差异备份和日志备份等几种备份方法,其中差异备份的内容是()


【DB笔试面试59】以下关于视图叙述不正确的是()
以下关于视图叙述不正确的是()
A、视图是由从数据库的基本表中选择出来的数据组成的逻辑窗口
B、视图是一个虚表
C、数据库中不仅存放视图的定义,还存放视图包含的数据
D、基本表中的数据库如果发生了变化,从视图中选取出来的数据也随之变化
视图是由从数据库的基本表中选取出来的数据组成的逻辑窗口,数据库中只存放视图的定义,而不存放视图查询出来的数据。
【DB笔试面试60】 关于E-R图的叙述正确的是()
关于E-R图的叙述正确的是()
A、E-R图是建立在关系数据库的假设上
B、E-R图可将现实世界中的信息抽象地表示为实体以及实体间的联系
C、E-R图使应用过程和数据的关系清晰
D、E-R图能表示数据生命周期
【DB笔试面试61】以下关于数据模型要求错误的是()
以下关于数据模型要求错误的是()
A、能够比较真实的模拟现实世界
B、容易为人们所理解
C、便于在计算机上实现
D、目前大部分数据库模型能很好的同时满足这三方面的要求
目前还没有一种数据库模型能够很好的同时满足能够比较真实的模拟现实世界、容易为人们所了解、便于在计算机上实现这三个方面的要求。
【DB笔试面试62】下列哪个选项是数据库技术与并行处理技术相结合的产 物,是为了处理大型复杂数据库管理应用领域中的海量数据而提出的,该DBS的硬件平台式并行计算机系统,使用多个CPU和多个磁盘进行并行数据处理和磁盘访问操作,以提高数据库系统的素具处理和I/O速度。()
A、集中式数据库系统 B、并行数据库系统
C、分布式数据库系统 D、客户/服务器数据库系统
数据库技术与并行处理技术相结合的产物是并行数据库系统。并行数据库系统通过并行实现各种数据操作,例如数据载入、索引建立、数据查询等,它可以提升系统的性能。
【DB笔试面试63】要以NAME’s address is ADDR格式返回数据,以下SQL语句正确的是
在Oracle中,表EMP包含以下列:
……
NAME VARCHAR2(20)
ADDR VARCHAR2(60)
……
要以NAME’s address is ADDR格式返回数据,以下SQL语句正确的是()
A、SELECT NAME + ”’s address is ’ + ADDR FROM EMP;
B、SELECT NAME || ”’s address is ’ || ADDR FROM EMP;
C、SELECT NAME + ‘\’s address is ’ + ADDR FROM EMP;
D、SELECT NAME || ‘\’s address is ”|| ADDR FROM EMP;
连接字符串用||,排除A和C。若要输出一个单引号,则只需要输入2个连续的单引号即可,所以,本题的答案为B。
【DB笔试面试64】在Oracle中,以下不属于集合操作符的是()
在Oracle中,以下不属于集合操作符的是()
A、UNION B、SUM C、MINUS D、INTERSECT
有时在实际应用中,为了合并多个SELECT语句的结果,可以使用集合操作符UNION、UNION ALL、INTERSECT、MINUS。这些操作符多用于数据量比较大的数据库,运行速度快,称为合并查询,也叫集合查询。
显然,本题的答案为B。
【DB笔试面试65】
在Oracle中,哪一种表分区方式建议的分区数是2的幂(2、4、8等),以获得最平均的数据发布()
A、范围分区 B、列表分区 C、散列分区 D、复合分区
【DB笔试面试66】在Oracle中,关于锁,下列描述不正确的是()
在Oracle中,关于锁,下列描述不正确的是()
A、锁用于在用户之间控制对数据的并发访问
B、DML产生的锁可以将锁归类为行级锁和表级锁
C、INSERT、UPDATE、DELETE语句自动获得行级锁
D、同一时间只能有一个用户锁定一个特定的表
锁(lock)机制用于管理对共享资源的并发访问,用于多用户的环境下,可以保证数据库的完整性和一致性。
根据保护的对象不同,Oracle数据库锁可以分为以下几大类:
(1)DML锁(data locks,数据锁),用于保护数据的完整性;
(2)DDL锁(dictionary locks,字典锁),用于保护数据库对象的结构,如表、索引等的结构定义;
(3)内部锁和闩(internal locks and latches),保护数据库的内部结构。
DML锁的目的在于保证并发情况下的数据完整性。在Oracle数据库中,DML锁主要包括TM锁和TX锁,其中TM锁称为表级锁,TX锁称为事务锁或行级锁。
本题中,对于选项A,锁用于在用户之间控制对数据的并发访问,选项说法正确。所以,选项A错误。
对于选项B,DML语句产生的锁可以分为TM锁和TX锁,说法正确。所以,选项B错误。
对于选项C,INSERT、UPDATE、DELETE语句自动获得行级锁,说法正确。所以,选项C错误。
对于选项D,同一时间可以有多个用户锁定一个特定的表,选项说法错误。所以,选项D正确。
所以,本题的答案为D。
【DB笔试面试67】在Oracle中,关于表分区下列描述不正确的是()
在Oracle中,关于表分区下列描述不正确的是()
A、分区允许对选定的分区执行维护操作,而其他分区对于用户仍然可用
B、不可以对包含LONG或LONG RAW列的表进行分区
C、不可以对包含任何LOB列的表进行分区
D、如果分区键包含DATE数据类型的列,那么必须使用TO_DATE函数完整的指定年份
当表中的数据量不断增大时,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。当对表进行分区后,在逻辑上,表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),当查询数据时,不至于每次都扫描整张表。Oracle可以将大表或索引分成若干个更小更方便管理的部分,每一部分称为一个分区,这样的表称为分区表。SQL语句使用分区表比全表或全表索引能提供更好的访问和处理数据。即使某些分区不可用,其他分区仍然可用,这叫做分区独立性。
分区表的一些限制条件:
① 不能分割是簇一部分的表。
② 不能分割含有LONG或LONG RAW列的表。
③ 索引组织表IOT不能进行范围分区。
本题中,对于选项A的说法体现了分区的独立性,选项说法正确。所以,选项A错误。
对于选项B的说法体现了分区的特殊性,说法正确。所以,选项B错误。
对于选项C,可以对包含有LOB列的表进行分区,选项说法错误。所以,选项C正确。
对于选项D,如果分区键包含DATE数据类型的列,则必须使用TO_DATE函数完整的指定年份,选项说法正确。所以,选项D错误。
所以,本题的答案为C。
【DB笔试面试68】 下列关于数据库数据字典的叙述中,哪一条是错误的?()
下列关于数据库数据字典的叙述中,哪一条是错误的?()
A、数据字典中保存关于数据库的描述信息
B、数据字典与元数据是不同的概念
C、程序访问数据库数据时,由DBMS通过查询数据字典确定被访问的数据
D、数据独立性是指存储在数据库的数据字典中的数据文件结构,与访问它的程序之间是相互分离的
数据字典(Data dictionary)是一种用户可以访问的记录数据库和应用程序元数据的目录。数据字典是指对数据的数据项、数据结构、数据流、数据存储、处理逻辑、外部实体等进行定义和描述,其目的是对数据流程图中的各个元素做出详细的说明,可以分为主动和被动数据字典。主动数据字典是指在对数据库或应用程序结构进行修改时,其内容可以由DBMS自动更新的数据字典。被动数据字典是指修改时必须手工更新其内容的数据字典。数据字典包括对数据库的描述信息、数据库的存储管理信息、数据库的控制信息、用户管理信息和系统事务管理信息等,所以数据字典也可以称为系统目录。
数据独立性是数据库系统的一个最重要的目标之一。它能使数据独立于应用程序。数据独立性表示应用程序与数据库中存储的数据不存在依赖关系,包括数据的物理独立性和数据的逻辑独立性。数据库管理系统的模式结构和二级映像功能保证了数据库中的数据具有很高的物理独立性和逻辑独立性。物理独立性是指用户的应用程序与存储在磁盘上的数据库中数据是相互独立的。即,数据在磁盘上怎样存储由DBMS管理,用户程序不需要了解,应用程序要处理的只是数据的逻辑结构,这样当数据的物理存储改变了,应用程序不用改变。逻辑独立性是指用户的应用程序与数据库的逻辑结构是相互独立的,即,当数据的逻辑结构改变时,用户程序也可以不变。所以,本题的答案为D。
【DB笔试面试69】下列关于数据模型的数据约束的叙述中,哪一条是错误的?()
下列关于数据模型的数据约束的叙述中,哪一条是错误的?()
A、数据约束描述数据结构中数据间的语法和语义关联
B、数据约束用以保证数据的正确性、有效性和相容性
C、数据完整性约束是数据约束的一种
D、数据约束指的是数据的静态特征,不包括数据的动态行为规则
在数据库表的开发中,约束是必不可少的支持,使用约束可以更好的保证数据库中数据的完整性。数据的完整性是指数据的正确性和一致性,可以通过定义表时定义完整性约束,也可以通过规则,索引,触发器等。约束分为两类:行级和表级,处理机制是一样的。行级约束放在列后,表级约束放在表后,多个列共用的约束放在表后。完整性约束是一种规则,不占用任何数据库空间。完整性约束存在数据字典中,在执行SQL或PL/SQL期间使用。用户可以指明约束是启用的还是禁用的,当约束启用时,它增强了数据的完整性,否则,则反之,但约束始终存在于数据字典中。
【DB笔试面试70】要为每一位工资低于1000元的女职工加薪200元,下列哪一个是实现上述要求的正确的SQL语句?
设有职工基本表:(EMPENO,ENAME,AGE,SEX,SALARY),其属性分别表示职工号、姓名、年龄、性别、工资。要为每一位工资低于1000元的女职工加薪200元,下列哪一个是实现上述要求的正确的SQL语句?()
A、UPDATE EMP
HAVING SALARY=SALARY+200
WHERE SALARY<1000 AND SEX=’女’;
B、UPDATE EMP
SET SALARY=SALARY+200
WHERE SALARY<1000 AND SEX=’女’;
C、UPDATE EMP
WITH SALARY=SALARY+200
WHERE SALARY<1000 AND SEX=’女’;
D、UPDATE EMP
UPDATE SALARY=SALARY+200
WHERE SALARY<1000 AND SEX=’女’;
更新的语法格式为UPDATE 表名 SET 列名=表达式 WHERE 条件。
本题中,对于选项A,不能使用HAVING子句。所以,选项A错误。
对于选项B,语法命令正确。所以,选项B正确。
对于选项C,不能使用WITH。所以,选项C错误。
对于选项D,不能出现2个UPDATE。所以,选项D错误。
所以,本题的答案为B。
【DB笔试面试71】有一个关系:(学生学号,姓名,系别),规定学号的值域是8个数字组成的字符串,这一规则属于下列哪一项约束?()
有一个关系:(学生学号,姓名,系别),规定学号的值域是8个数字组成的字符串,这一规则属于下列哪一项约束?()
A、实体完整性约束 B、参照完整性约束
C、用户自定义完整性约束 D、关键字完整性约束
用户自定义的完整性规则是指某一具体的实际数据库的约束条件,由应用环境所决定,反映某一具体应用所涉及的数据必须满足的要求(比如说一个人的年龄必须要大于零),根据现实生活中的一个实际情况用户定义的一个用户自定义完整性。
所以,本题的答案为C。
【DB笔试面试72】将STUDENT表中的年龄属性的数据类型改为半字节整数,下列SQL语句中哪一个是正确的?()
将STUDENT表中的年龄属性的数据类型改为半字节整数,下列SQL语句中哪一个是正确的?()
A、ALTER TABLE STUDENT ADD age SMALLINT;
B、ALTER TABLE STUDENT MODIFY age SMALLINT;
C、ALTER TABLE STUDENT UPDATE age SMALLINT;
D、ALTER TABLE STUDENT HAVING age SMALLINT;
修改数据类型使用MODIFY关键字。
所以,本题的答案为B。
【DB笔试面试73】
数据库系统中部分或全部事务由于无法获得对需要访问的数据项的控制权而处于等待状态,并且一直等待下去的一种系统状态的情况称为()
A、活锁 B、死锁 C、排它锁 D、共享锁
题目中描述的的情况称为活锁。所谓死锁,是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败。活锁和死锁的区别在于,处于活锁的实体是在不断的改变状态,所谓的“活”,而处于死锁的实体表现为等待;活锁有可能自行解开,死锁则不能。共享锁使一个事务对特定数据库资源进行共享访问,另一事务也可对此资源进行访问或获得相同共享锁。共享锁为事务提供高并发性,但拙劣的事务设计+共享锁容易造成死锁或数据更新丢失。事务设置排它锁后,该事务单独获得此资源,另一事务不能在此事务提交之前获得相同对象的共享锁或排它锁。
【DB笔试面试74】下列关于锁的说法错误的是()
下列关于锁的说法错误的是()
A、锁是一种特殊的二元信号量
B、为了避免活锁现象的发生,DBMS采用资源分配图的方法来处理事务的数据操作请求
C、对于每个需要撤销的死锁事务,可以简单的放弃该事务已经完成的全部操作,重新启动该事务
D、在顺序加锁中,维护数据项的加锁顺序很困难,代价也非常大
为了避免活锁现象的发生,DBMS一般采用先来先服务的策略来处理事务的数据操作请求.
【DB笔试面试75】 关于对SQL对象的操作权限的描述正确的是()
关于对SQL对象的操作权限的描述正确的是()
A、权限的种类分为INSERT,DELETE和UPDATE三种
B、使用REVOKE语句获得权限
C、权限只能用于实表而不能应用于视图
D、使用COMMIT语句赋值权限
REVOKE是对权限的回收,COMMIT是对事务的提交,权限不仅能作用于实表还能作用于虚表。
【DB笔试面试76】在UML机制中,关于包和包图下列说法中错误的是()
在UML机制中,关于包和包图下列说法中错误的是()
A、把模型元素通过内在的语义连在一起的成为一个整体就叫做包
B、包又称为子系统
C、包能够引用来自其他包的模型元素
D、包图必须保证高耦合,低内聚
包图是表明包以及包之间的关系的类图,是对模型中涉及的元素分组所得的结果,是具有特定语义的一个子集,必须保证低耦合,高内聚。
【DB笔试面试77】 有学生表(学号,姓名,所在系,年龄),找出系内学生平均年龄高于全体学生平均年龄的系信息,正确的语句是()
有学生表(学号,姓名,所在系,年龄),找出系内学生平均年龄高于全体学生平均年龄的系信息,正确的语句是()
A、SELECT 所在系,AVG(年龄)FROM 学生表
WHERE AVG(年龄)>(SELECT AVG(年龄)FEOM 学生表);
B、SELECT 所在系,AVG(年龄)FROM 学生表
WHERE AVG(年龄)>(SELECT AVG(年龄)FEOM 学生表)
GROUP BY 所在系;
C、SELECT 所在系,AVG(年龄)FROM 学生表
GROUP BY 所在系
HAVING AVG(年龄)>(SELECT AVG(年龄)FEOM 学生表);
D、SELECT 所在系,(AVG年龄)FROM 学生表
GROUP BY 所在系
WHERE AVG年龄)>(SELECT AVG(年龄)FEOM 学生表);
在分组查询中要用关键字GROUP,AVG()、SUM()等函数作为查询条件时,必须放在HAVING关键字后面,而不能用WHERE关键字。
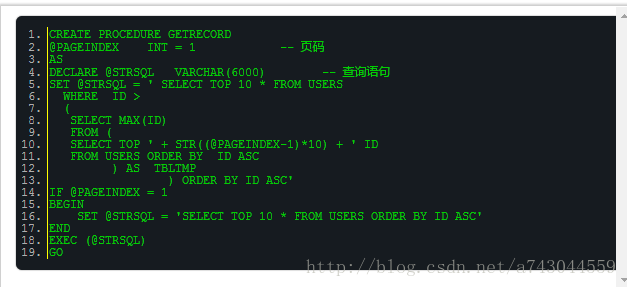
【DB笔试面试78】表USERS中有字段ID,NAME。要求用数据库脚本实现以下功能,以ID为升序排列,并分页,每页10行。
答案如下:
【DB笔试面试79】MySQL如何查询SQL语句的执行计划,从而知道是否使用了索引
1、 MySQL如何查询SQL语句的执行计划,从而知道是否使用了索引。
答案如下:

很明显,能够看到索引:index_name_shouji。
【DB笔试面试80】在MySQL中,创建用户OLDLHR,使之可以管理数据库OLDLHR
在MySQL中,创建用户OLDLHR,使之可以管理数据库OLDLHR。
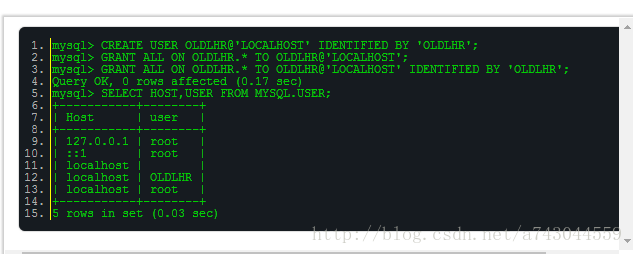
【DB笔试面试81】在MySQL中,如何查看创建的用户OLDLHR拥有哪些权限?
在MySQL中,如何查看创建的用户OLDLHR拥有哪些权限?
mysql> SHOW GRANTS FOR OLDLHR@LOCALHOST;
+—————————————————————————————————————+
| Grants for OLDLHR@localhost |
+—————————————————————————————————————+
| GRANT USAGE ON . TO ‘OLDLHR’@’localhost’ IDENTIFIED BY PASSWORD ‘*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9’ |
| GRANT ALL PRIVILEGES ON OLDLHR.* TO ‘OLDLHR’@’localhost’ |
+—————————————————————————————————————+
2 rows in set (0.02 sec)
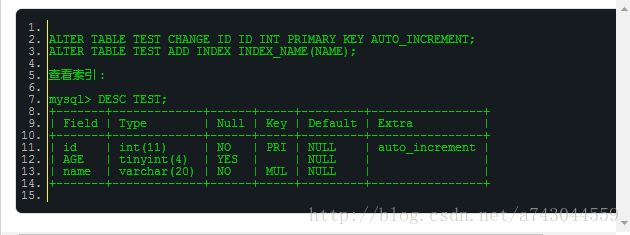
【DB笔试面试82】在MySQL中,把TEST表的ID列设置为主键,并在NAME字段上创建普通索引。
在MySQL中,把TEST表的ID列设置为主键,并在NAME字段上创建普通索引。
ALTER TABLE TEST CHANGE ID ID INT PRIMARY KEY AUTO_INCREMENT;
ALTER TABLE TEST ADD INDEX INDEX_NAME(NAME);
查看索引:
【DB笔试面试83】在SQL Server中,()保存所有的临时表和临时存储过程
在SQL Server中,()保存所有的临时表和临时存储过程
A、master数据库
B、tempdb数据库
C、model数据库
D、msdb数据库
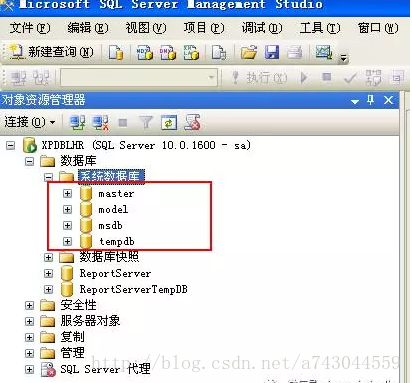
总体而言,SQL Server有如下4个默认的数据库:Master、Model、Tempdb和Msdb。
1、Master
Master数据库(主数据库)保存有放在SQL Server实体上的所有数据库元数据的详细信息,它还是将引擎固定起来的粘合剂。由于如果不使用Master数据库,那么SQL Server就不能启动,所以,必须要小心地管理好这个数据库。因此,对这个数据库进行常规备份是十分必要的。
这个数据库包括了诸如系统登录、配置设置、已连接的Server等信息。主数据库还存有扩展存储过程,它能够访问外部进程,从而允许与磁盘子系统和系统API调用等特性交互。
2、Model
Model数据库(模型数据库)是一个用来在实体上创建新用户数据库的模版数据库,可以把任何存储过程、视图、用户等放在模型数据库里,这样在创建新数据库的时候,新数据库就会包含存放在模型数据库里的所有对象了。
3、Tempdb
Tempdb数据库存有临时对象,例如全局和本地临时表和存储过程。这个数据库在SQL Server每次重启的时候都会被重新创建,而其中包含的对象是依据模型数据库里定义的对象被创建的。除了这些对象,Tempdb还存有其它对象,例如表变量、来自表值函数的结果集,以及临时表变量。由于Tempdb会保留SQL Server实体上所有数据库的对象类型,所以,对数据库进行优化配置是非常重要的。
4、Msdb
Msdb数据库用来保存数据库备份、SQL Agent信息、DTS程序包和SQL Server任务等信息,以及诸如日志转移这样的复制信息。
从SQL Server Studio中可以查看所有的数据库,如下图所示:
【DB笔试面试84】假设有表数据:TABLE 。。。请写出获得此结果的SQL语句。
假设有表数据:TABLE
ID NAME NUM
A a 9
A b 11
B f 7
B g 8
所要结果:
A b 11
B g 8
请写出获得此结果的SQL语句。
答案:本题考察的是聚合函数和子查询,先按照ID列进行分组找出NUM最大的值,然后回表查询即可得最终结果,最终SQL语句如下所示:
SELECT * FROM TABLE
WHERE NUM IN
(SELECT MAX(NUM) FROM TABLE GROUP BY ID);
【DB笔试面试85】设教学数据库中有三个基本表。。。下面的题目都是针对上述三个基本表操作的。
设教学数据库中有三个基本表:
学生表S(S#,SNAME,AGE,SEX),其属性表示学生的学号、姓名、年龄和性别;选课表SC(S#,C#,GRADE),其属性表示学生的学号、所学课程的课程号和成绩;课程表C(C#,CNAME,TEACHER),其属性表示课程号、课程名称和任课教师姓名。
下面的题目都是针对上述三个基本表操作的。
(1)试写出下列插入操作的SQL语句:
把SC表中每门课程的平均成绩插入到另一个已存在的表SC_C(C#,CNAME,AVG_GRADE)中,其中,AVG_GRADE为每门课程的平均成绩。
(2)试写出下列删除操作的SQL语句:
从SC表中把WU老师的女学生选课元组删去。
(1)答案:
INSERT INTO SC_C( C#,CNAME,AVG_GRADE )
SELECT SC.C#, C.CNAME, AVG(GRADE) FROM SC, C WHERE SC.C#=C.C#;
(2)答案:
DELETE FROM SC WHERE S# IN (SELECT S# FROM S WHERE SEX=’女’)
AND C# IN (SELECT C# FROM C WHERE TEACHER=’WU’);
【DB笔试面试86】
设有如下关系表
供应者:SUPPLIER(SNO,SNAME,CITY),其中,SNO供应者编号,SNAME为供应者姓名,CITY所在城市
零件:PART(PNO,PNAME,WEIGHT),其中,PNO零件号,PNAME零件名称,WEIGHT重量
工程:JOB(JNO,JNAME,CITY),其中,JNO工程号,JNAME工程名,CITY所在城市
联系关系:SPJ(SNO,PNO,JNO,QTY),其中,QTY为数量
(1)查找给工程J1提供零件P1的供应者号SNO
(2)查找在北京的供应者给武汉的工程提供零件的零件号
(3)查找由供应者S1提供的零件名PNAME
(4)查找CITY值为上海的工程号和名称
(5)将工程J3的城市改为广州
(6)将所有重20公斤的零件改为重10公斤
(7)将给工程J1提供零件P1的供应者S1改为S2
(8)将值(S3,凌涛,武汉)加到SUPPLIER中
(9)删除所有上海工程的数据
(1)查找给工程J1提供零件P1的供应者号SNO
答案:
SELECT SNO
FROM SPJ,PART,JOB
WHERE SPJ.PNO = PART.PNO
AND SPJ.JNO = JOB.JNO
AND PART.PNAME = ‘P1’
AND JOB.JNAME = ‘J1’;
(2)查找在北京的供应者给武汉的工程提供零件的零件号
答案:
SELECT PNO
FROM SPJ,PART,JOB
WHERE SPJ.PNO = PART.PNO
AND SPJ.JNO = JOB.JNO
AND JOB.CITY = ‘武汉’
AND SUPPLIER.CITY = ‘北京’;
(3)查找由供应者S1提供的零件名PNAME
答案:
SELECT PNAME
FROM PART
WHERE PNO IN
(SELECT PNO FROM SPJ, SUPPLIER
WHERE SPJ.SNO = SUPPLIER.SNO
AND SUPPLIER.SNAME = ‘S1’);
(4)查找CITY值为上海的工程号和名称
答案:
SELECT JNO,JNAME FROM JOB WHERE CITY = ‘上海’;
(5)将工程J3的城市改为广州
答案:
UPDATE JOB SET CITY = ‘广州’ WHERE JNAME = ‘J3’;
(6)将所有重20公斤的零件改为重10公斤
答案:
UPDATE PART SET WEIGHT=’10公斤’ WHERE WEIGHT=’20公斤’;
(7)将给工程J1提供零件P1的供应者S1改为S2
答案:
UPDATE SUPPLIER
SET SNAME = ‘S2’
WHERE SNAME = ‘S1’
AND SNO IN
(SELECT SNO FROM SPJ,JOB,PART
WHERE SPJ.JNO = JOB.JNO
AND JOB.JNAME = ‘J1’
AND SPJ.PNO = PART.PNO
AND PART.PNAME = ‘P1’);
(8)将值(S3,凌涛,武汉)加到SUPPLIER中
答案:
INSERT INTO SUPPLIER VALUES(‘S3’, ‘凌涛’, ‘武汉’);
(9)删除所有上海工程的数据
答案:
DELETE FROM SPJ WHERE JNO IN (SELECT JNO FROM JOB WHERE CITY = ‘上海’);
DELETE FROM JOB WHERE CITY = ‘上海’;
需要注意的是,上述语句的顺序不能弄反。
【DB笔试面试87】COMMIT操作和ROLLBACK操作的作用是什么?
COMMIT操作和ROLLBACK操作的作用是什么?
COMMIT语句表示这个事务的所有操作都执行成功(提交),COMMIT告诉系统,数据库要进入一个新的正确状态,该事务对数据库的所有更新都已交付实施(写入磁盘)。
ROLLBACK语句表示事务中有执行失败的操作(应该“回退”),ROLLBACK告诉系统,已发生错误,数据库可能处在不正确的状态,该事务对数据库的所有更新必须被撤销,数据库应恢复该事务到初始状态。
【DB笔试面试88】
学生信息管理系统中有张表STUDENT,其中,有字段ID、NAME、SEX、BIRTH,请回答如下问题:
(1)找出NAME相同的学生(用一句SQL语句)。
(2)用一句SQL语句把学生SEX为男的改为女,女的改为男。
答案:
(1)SELECT * FROM STUDENT WHERE NAME IN (SELECT NAME FROM STUDENT GROUP BY NAME HAVING COUNT(NAME)>1);
(2)UPDATE STUDENT SET SEX = CASE SEX WHEN ‘男’ THEN ‘女’ ELSE ‘男’ END;
【DB笔试面试89】SQL Server、Access、Oracle三种数据库之间的区别是什么?
SQL Server、Access、Oracle三种数据库之间的区别是什么?
Access是一种桌面数据库,只适合于数据量少的应用系统,在处理少量数据和单机访问的数据时是很好的,效率也很高。但是Access数据库有一定的极限,如果数据达到100M左右,那么很容易造成Access假死,或者消耗掉服务器的内存导致服务器崩溃。
SQL Server是基于服务器端的中型的数据库,可以适合大容量数据的应用。在处理海量数据的效率,后台开发的灵活性,可扩展性等方面强大。因为现在数据库都使用标准的SQL语言对数据库进行管理,所以,如果是标准SQL语言,那么两者基本上都可以通用的。SQL Server还有更多的扩展,可以用存储过程、函数等。
Oracle是基于服务器的大型数据库,主要应用于银行、证券类业务等。
【DB笔试面试90】SQL Server的两种存储结构是什么?
SQL Server的两种存储结构是页与区间。
(1)页:用于数据存储的连续的磁盘空间块,大小为8KB,每页的开头是96字节的页头,用于存储有关页的系统信息,包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元ID。
(2)区间:8个连续的物理页面,大小64KB(较小的表(<64KB)与其它数据库对象共享区间)。
表和索引以区间的形式存储,SQL Server中的每个数据库的信息都记录在Master数据库的sysdatabases和sysaltfiles表中。
【DB笔试面试91】
创建一个存储引擎为InnoDB,字符集为GBK的表TEST,字段为ID和NAME VARCHAR(16),并查看表结构完成下列要求:
① 插入一条数据:1,newlhr
② 批量插入数据:2,小麦苗;3,ximaimiao。要求中文不能乱码
③ 首先查询名字为newlhr的记录,然后查询ID大于1的记录
④ 把数据ID等于1的名字newlhr更改为oldlhr
⑤ 在字段NAME前插入AGE字段,类型TINYINT(4)
mysql> CREATE TABLE TEST(ID INT(4) NOT NULL, NAME VARCHAR(20) NOT NULL)ENGINE=InnoDB DEFAULT CHARSET=GBK;
Query OK, 0 rows affected (0.67 sec)
【DB笔试面试92】在MySQL中,有如下表结构,其中,NAME字段代表“姓名”,SCORE字段代表“分数”。
有如下表结构,其中,NAME字段代表“姓名”,SCORE字段代表“分数”。
CREATE TABLE T1 (
ID DOUBLE,
NAME VARCHAR(300),
SCORE DOUBLE
);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘1’,’N1’,’59’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘2’,’N2’,’66’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘3’,’N3’,’78’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘4’,’N1’,’48’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘5’,’N3’,’85’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘6’,’N5’,’51’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘7’,’N4’,’98’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘8’,’N5’,’53’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘9’,’N2’,’67’);
INSERT INTO T1 (ID, NAME, SCORE) VALUES(‘10’,’N4’,’88’);
1、查询单分数最高的人和单分数最低的人。
SELECT * FROM T1 WHERE SCORE IN (SELECT MAX(SCORE) FROM T1 UNION ALL SELECT MIN(SCORE) FROM T1);
2、查询两门分数加起来的第2至5名。
SELECT NAME,SUM(SCORE) FROM T1 GROUP BY NAME ORDER BY SUM(SCORE) DESC LIMIT 1,4;
3、查询两门总分数在150分以下的人。
mysql> SELECT NAME, SUM(SCORE) FROM T1 GROUP BY NAME HAVING SUM(SCORE) < 150;
4、查询两门平均分数介于60和80的人。
mysql> SELECT NAME,AVG(SCORE) FROM T1 GROUP BY NAME HAVING AVG(SCORE) BETWEEN 60 AND 80;
5、查询总分大于150分,平均分小于90分的人数。
mysql> SELECT NAME,SUM(SCORE),AVG(SCORE) FROM T1 GROUP BY NAME HAVING SUM(SCORE)>150 AND AVG(SCORE)<90;
6、查询总分大于150分,平均分小于90分的人数有几个。
mysql> SELECT COUNT(NAME) FROM T1 GROUP BY NAME HAVING SUM(SCORE) > 150 AND AVG(SCORE) < 90;
【DB笔试面试93】在MySQL中,创建GBK字符集的数据库NEWLHR,并查看已建库的完整语句。
在MySQL中,创建GBK字符集的数据库NEWLHR,并查看已建库的完整语句。
mysql> CREATE DATABASE NEWLHR CHARACTER SET GBK ;
Query OK, 1 row affected (0.13 sec)
mysql> SHOW CREATE DATABASE NEWLHR;
+———-+—————————————————————-+
| Database | Create Database |
+———-+—————————————————————-+
| newlhr | CREATE DATABASE newlhr /!40100 DEFAULT CHARACTER SET gbk / |
+———-+—————————————————————-+
1 row in set (0.02 sec)
【DB笔试面试94】在MySQL中,VARCHAR与CHAR的区别是什么?VARCHAR(50)中的50代表的含义是什么?
CHAR是一种固定长度的类型,VARCHAR则是一种可变长度的类型。
CHAR列的长度固定为创建表时声明的长度。长度可以为从0到255的任何值。当保存CHAR值时,在它们的右边填充空格以达到指定的长度。当检索到CHAR值时,尾部的空格被删除掉。在存储或检索过程中不进行大小写转换。
VARCHAR列中的值为可变长字符串。长度可以指定为0到65535之间的值。VARCHAR的最大有效长度由最大行大小和使用的字符集确定。在MySQL 4.1之前的版本,VARCHAR(50)的“50”指的是50字节(bytes),如果存放UTF8汉字时,最多只能存放16个(每个汉字3字节)。从MySQL 4.1版本开始,VARCHAR(50)的“50”指的是50字符(character),无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放50个。CHAR和VARCHAR类型声明的长度表示你想要保存的最大字符数。例如,CHAR(30)可以占用30个字符。
【DB笔试面试95】在MySQL中,MyISAM和InnoDB各有哪些特性?分别适用在怎样的场景下?
答案:MyISAM支持表锁,不支持事务,表损坏率较高。它分为2种类型的文件:以MYD作为后缀名的数据文件和以MYI作为后缀名的索引文件。MyISAM读写并发不如InnoDB,适用于INSERT较多的场景,且支持直接复制文件,用以备份数据,是MySQL公司开发的,物理文件主要有数据文件,日志文件和索引文件,并且这三个文件是单独存在。
InnoDB支持行锁,支持事务,支持行级锁,CRASH后具有RECOVER机制,只有ibd文件,分为数据区和索引区,有较好的读写并发能力,但做COUNT运算时相当消耗CPU,是InnoDB公司开发的。物理文件有日志文件,数据文件和索引文件。其中,索引文件和数据文件是放在一个目录下,可以设置共享文件、独享文件两种格式。
它们之间其它的区别可以参考如下表格:
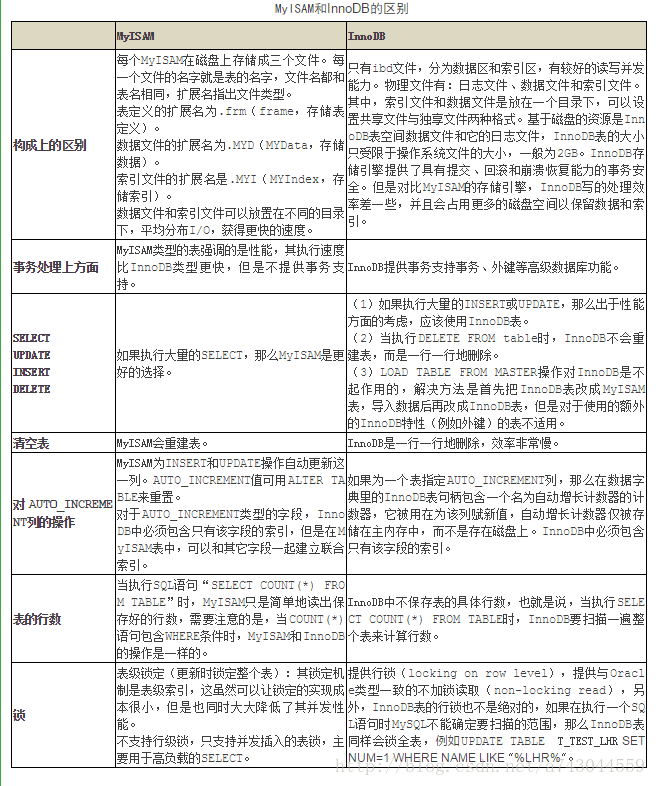
【DB笔试面试96】在MySQL中,下列SQL语句中,可为用户ZHANGSAN分配数据库USERDB表USERINFO的查询()
在MySQL中,下列SQL语句中,可为用户ZHANGSAN分配数据库USERDB表USERINFO的查询和插入数据权限的是()
A、GRANT SELECT,INSERT ON USERDB.USERINFO TO ‘ZHANGSAN’@’LOCALHOST’;
B、GRANT ‘ZHANGSAN’@’LOCALHOST’ TO SELECT,INSERT FOR USERDB.USERINFO;
C、GRANT SELECT,INSERT ON USERDB.USERINFO FOR ‘ZHANGSAN’@’LOCALHOST’;
D、GRANT ‘ZHANGSAN’@’LOCALHOST’TO USERDB.USERINFO ON SELECT,INSERT;
赋予权限的SQL语句:GRANT [权限] ON [TABLE] TO ‘USERNAME’@’LOCALHOST’;。
本题中,对于选项A,语法正确。所以,选项A正确。
对于选项B,权限应该在GRANT之后。所以,选项B错误。
对于选项C,最后的关键词是TO而不是FOR。所以,选项C错误。
对于选项D,最后的关键词是TO而不是ON。所以,选项D错误。
所以,本题的答案为A。
【DB笔试面试97】在MySQL中,如何分析一条SQL语句的执行性能?需要关注哪些信息?
在MySQL中,如何分析一条SQL语句的执行性能?需要关注哪些信息?
答案:使用EXPLAIN命令,观察TYPE列,可以知道是否是全表扫描,可以知道索引的使用形式,观察KEY可以知道使用了哪个索引,观察KEY_LEN可以知道索引是否使用完成,观察ROWS可以知道扫描的行数是否过多,观察EXTRA可以知道是否使用了临时表和进行了额外的排序操作。
【DB笔试面试98】在MySQL中,有两个复合索引(A,B)和(C,D),以下语句会怎样使用索引?可以做怎样的优化?
在MySQL中,有两个复合索引(A,B)和(C,D),以下语句会怎样使用索引?可以做怎样的优化?
SELECT * FROM TAB WHERE (A=? AND B=?) OR (C=? AND D=?)
答案:根据MySQL的机制,只会使用到一个筛选效果好的复合索引,可以做如下优化:
SELECT * FROM TAB WHERE A=? AND B=?
UNION
SELECT * FROM TAB WHERE C=? AND D=?;
【DB笔试面试99】几道MySQL基础题
真题1、 如何连接到MySQL数据库?
答案:连接到MySQL数据库有多种写法,假设MySQL服务器的地址为192.168.59.130,可以通过如下几种方式来连接MySQL数据库:
① mysql -p
② mysql -uroot -p
③ mysql -uroot -h192.168.59.130 -p
真题2、 哪个命令可以查看所有数据库?
答案:运行命令:show databases;
真题3、 如何切换到某个特定的数据库?
答案:运行命令:use database_name;。
真题4、 列出数据库内所有的表?
答案:在当前数据库运行命令:show tables;。
真题5、 如果MySQL密码丢了,那么如何找回密码?
答案:步骤如下:
a、关闭MySQL,/data/3306/mysql stop或pkill mysqld。
b、mysqld_safe –defaults-file=/data/3306/my.cnf –skip-grant-table &。
c、mysql -uroot -p -S /data/3306/mysql.sock ,按ENTER进入。
d、修改密码,UPDATE mysql.user SET password=PASSWORD(“oldlhr123”) WHERE user=’root’ and host=’localhost’;。
真题6、 mysqldump备份mysqllhr库及MySQL库的命令是什么?
答案:mysqldump -uroot -plhr123 -S /data/3306/mysql.sock -B –events -x MySQL mysqllhr > /opt/$(date +%F).sql
真题7、 如何不进入MySQL客户端,执行一条SQL命令,帐号User,密码Passwd,库名DBName,SQL为SELECT sysdate();
答案:采用-e选项,命令为:mysql -uUser -pPasswd -D DBName -e “SELECT sysdate();”。
真题8、 用哪些命令可以查看MySQL数据库中的表结构?
答案:查看MySQL表结构的命令有如下几种:
(1) DESC 表名;
(2) SHOW COLUMNS FROM 表名;
(3) DESCRIBE 表名;
(4) SHOW CREATE TABLE 表名;
(5) USE INFORMATION_SCHEMA。
真题9、 如何创建TABB表,完整拷贝TABA表的结构和索引,而且不要数据?
答案:CREATE TABLE TABB LIKE TABA;。
真题10、 如何查看某一用户的权限?
答案:SHOW GRANTS FOR USERNAME;。
真题11、 如何得知当前BINARY LOG文件和POSITION值?
答案:SHOW MASTER STATUS;。
真题12、 用什么命令切换BINARY LOG?
答案:FLUSH LOGS;。
真题13、 用什么命令整理表数据文件的碎片?
答案:OPTIMIZE TABLE TABLENAME;。
真题14、 如何得到TA_LHR表的建表语句?
答案:SHOW CREATE TABLE TA_LHR;。
【DB笔试面试100】在Oracle中,如下命令:CREATE SEQUENCE seq1()
CREATE SEQUENCE seq1 START WITH 100 INCREMENT BY 10 MAXVALUE 200 CYCLE NOCACHE.
The sequence SEQ1 has generated numbers up to the maximum limit of 200. You issue the following SQL statement:
SELECT seq1.nextval FROM dual.
What is displayed by the SELECT statement?
A、1
B、10
C、100
D、an error
题目“has generated numbers up to the maximum limit of 200”表示序列SEQ1当前已经是最大值200,且创建属性是CYCLE的,所以,NEXTVAL的值从1开始。注意:即便是START WITH 100,使用CYCLE属性的序列还是从1开始的。
所以,本题的答案为A。
–以上内容整理自小麦苗的博客,感谢小麦苗。














 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









