







相关博客:
一、堆:
1、什么是堆:
堆是一种特殊的树,它满足需要满足两个条件:
(1)堆是一种完全二叉树,也就是除了最后一层,其他层的节点个数都是满的,最后一个节点都靠左排列。
(2)堆中每一个节点的值都必须大于等于(或小于等于)其左右子节点的值。
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作“小顶堆”。
2、堆的实现:
用数组来存储完全二叉树是非常节省内存空间的,因为我们不需要存储左右子节点的指针,单纯通过数组的下标,就可以找到一个节点的子节点和父节点。
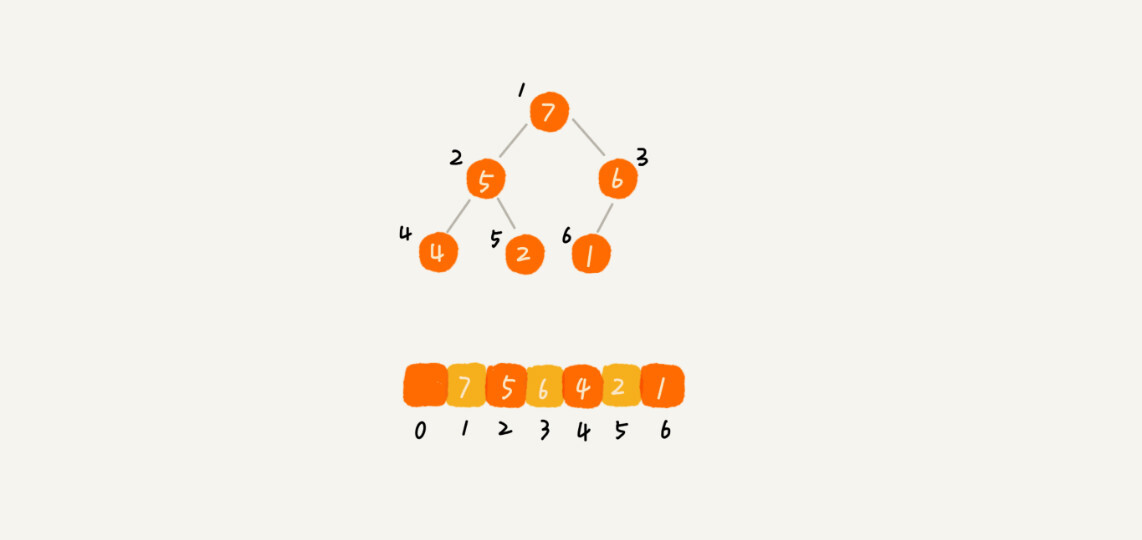
从图中我们可以看到,数组中下标为 i 的节点的左子节点,就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1的节点,父节点就是下标为i/2的节点。
3、堆的核心操作:
(1)往堆中插入一个元素:
我们新插入一个元素之后,堆可能就不满足堆的特性了,就需要进行调整,让其重新满足堆的特性,即堆化(heapify),堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。所以分为两种,从下往上 和 从上往下。
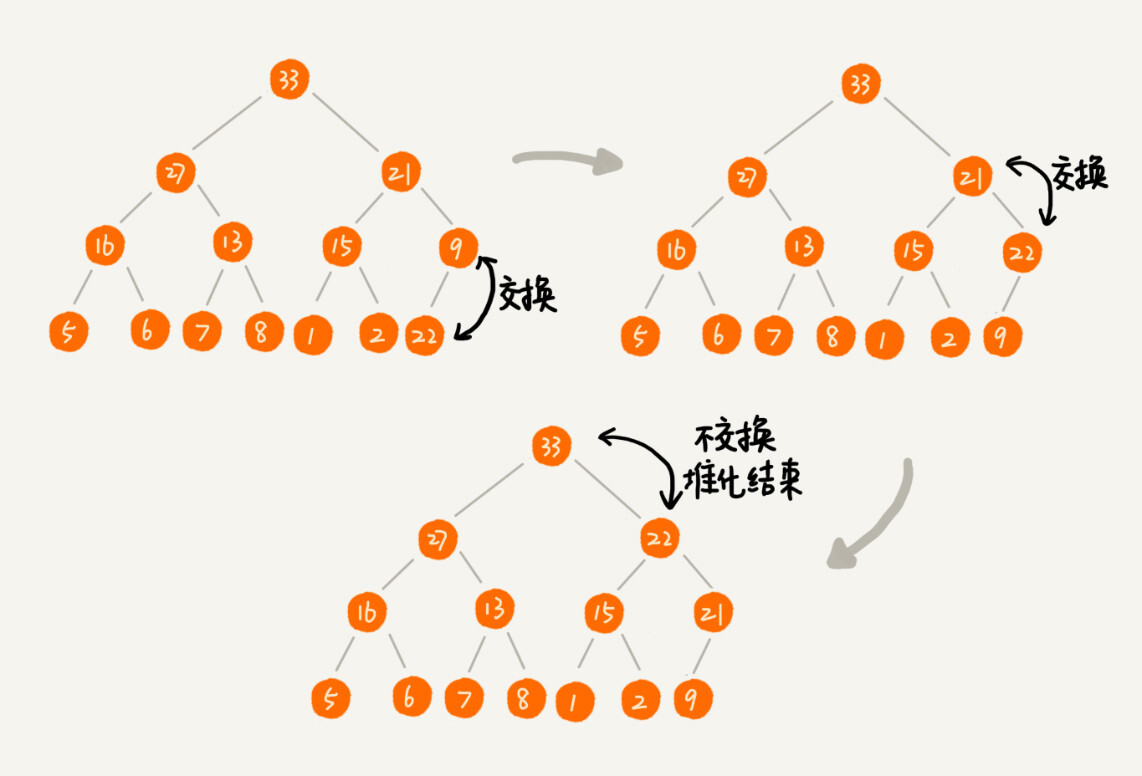
①从下往上堆化:
例如:在已经建好的堆中插入值为“22”的结点,这时候就需要重新调整堆结构,过程如下:
Java代码实现:
public class Heap {
private int[] a;//数组,从下标1开始存储数据
private int n;//堆可以存储的最大数据个数
private int count;//堆中已经存储的数据个数
public Heap(int capacity){
a = new int[capacity+1];
n=capacity;
count = 0;
}
//1、插入数据,并从下往上堆化
public void insert(int data){
if(count>=n) return;//堆满了
++count;
a[count]=data;
int i = count;
while(i/2>0 && a[i]>a[i/2]){
swap(a,i,i/2);
i=i/2;
}
}
private void swap(int[] array, int i, int j) {
int temp=array[j];
array[j]=array[i];
array[i]=temp;
}
}(2)从堆中删除堆顶元素:
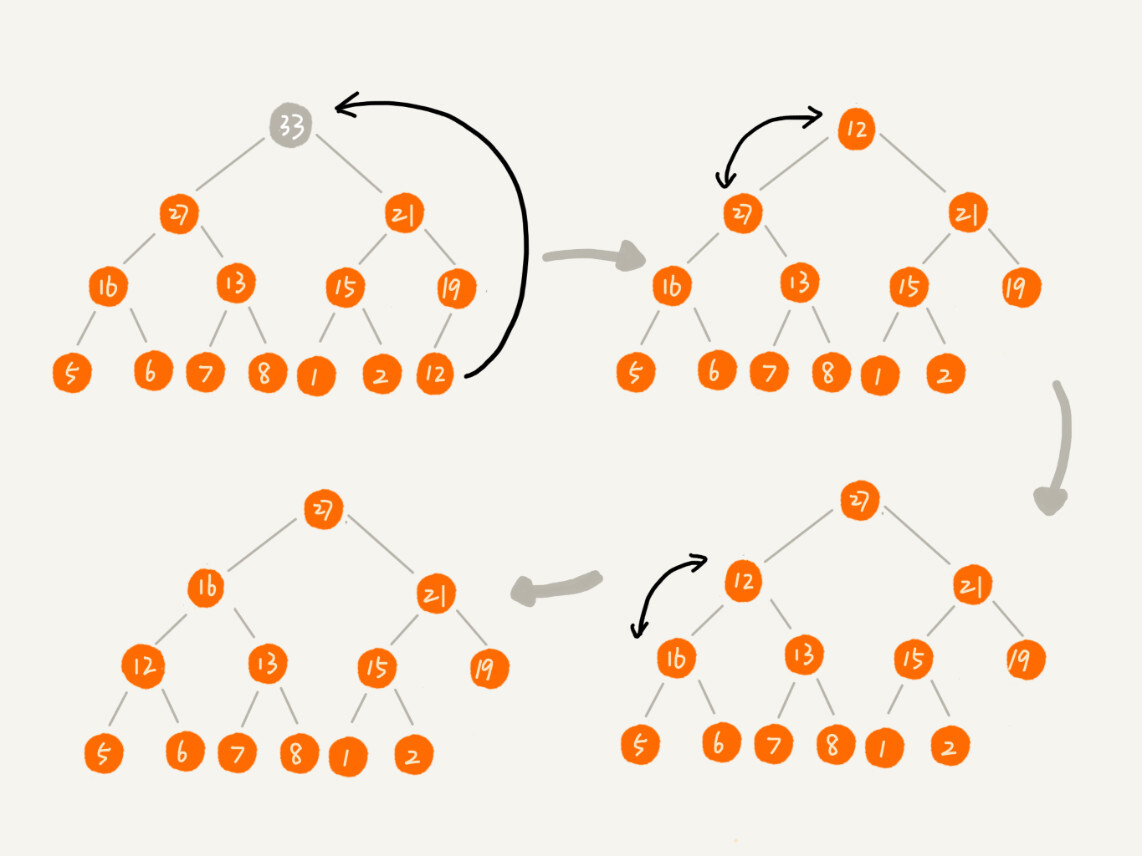
删除步骤:把最后一个节点放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止。这就是从上往下的堆化方法。
例如:删除堆顶的“33”结点,删除步骤如下:
Java代码实现:
public void removeMax(){
if(count ==0) return;
a[1]=a[count];
--count;
heapity(a,count,1);
}
//2、自上往下堆化
private void heapity(int[] a2, int n, int i) {
while(true){
int MaxPos=i;
if(i*2<=n && a[i]<a[i*2]) MaxPos=i*2;
if(i*2+1<=n && a[MaxPos]<a[i*2+1]) MaxPos=i*2+1;
if(MaxPos==i) break;
swap(a, i, MaxPos);
i=MaxPos;
}
}一个包含 n个节点的完全二叉树,树的高度不会超过 log2n。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就O(logn)。插入数据和删除堆顶元素的主要逻辑就是堆化,所以在堆中插入一个元素和删除堆顶元素的时间复杂度都是O(logn)。
二、堆排序:
1、算法原理:
堆排序是指利用堆这种数据结构进行排序的一种算法。
(1)排序过程中,只需要个别临时存储空间,所以堆排序是原地排序算法,空间复杂度为O(1)。
(2)堆排序的过程分为建堆和排序两大步骤。建堆过程的时间复杂度为O(n),排序过程的时间复杂度为O(nlogn),所以,堆排序整体的时间复杂度为O(nlogn)。
(3)堆排序不是稳定的算法,因为在排序的过程中,存在将堆的最后一个节点跟堆顶节点互换的操作,所以可能改变值相同数据的原始相对顺序。
2、建堆:
(1)第一种是实现思路:借助前面的,在堆中插入元素的思路。将要排序的数组从前往后处理,依次到插入堆中,并且每次都从下往上进行堆化。
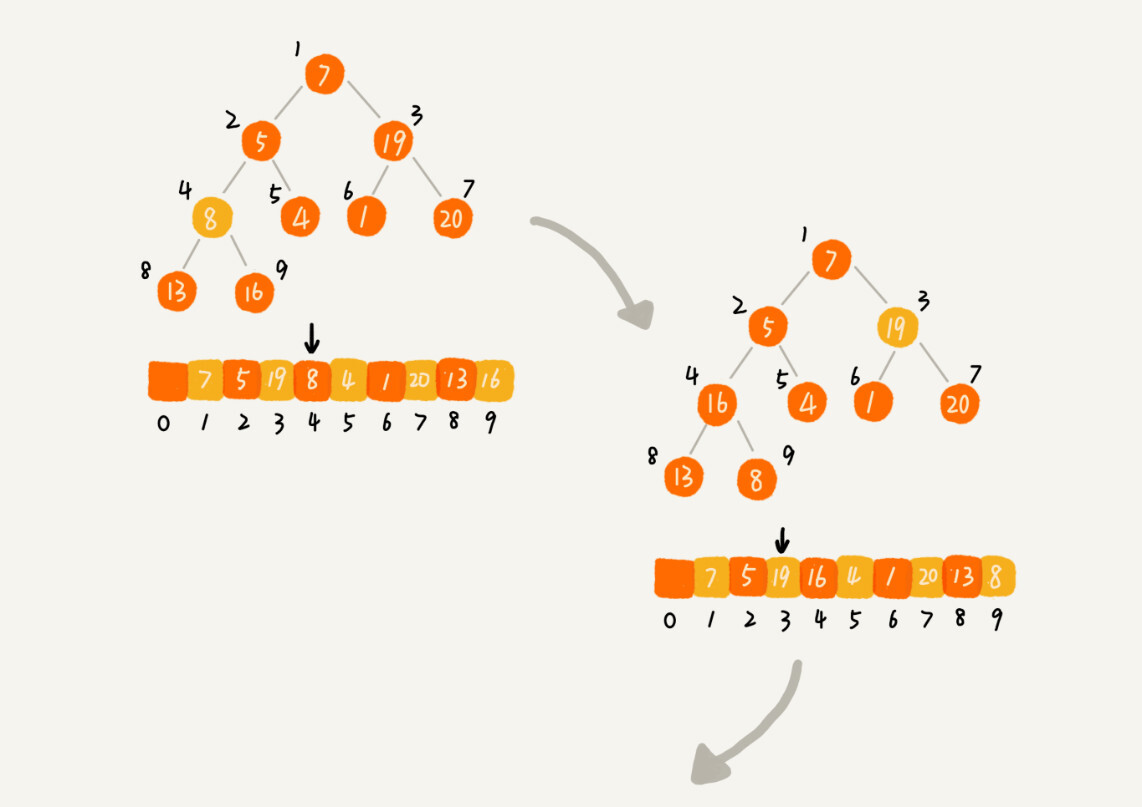
(2)第二种实现实现思路:从后往前处理数组,并且每个数据都是从上往下堆化。也就是从二叉树中第一个非叶子节点开始开始堆化,因为叶子节点往下堆化只能自己跟自己比较。如下图:
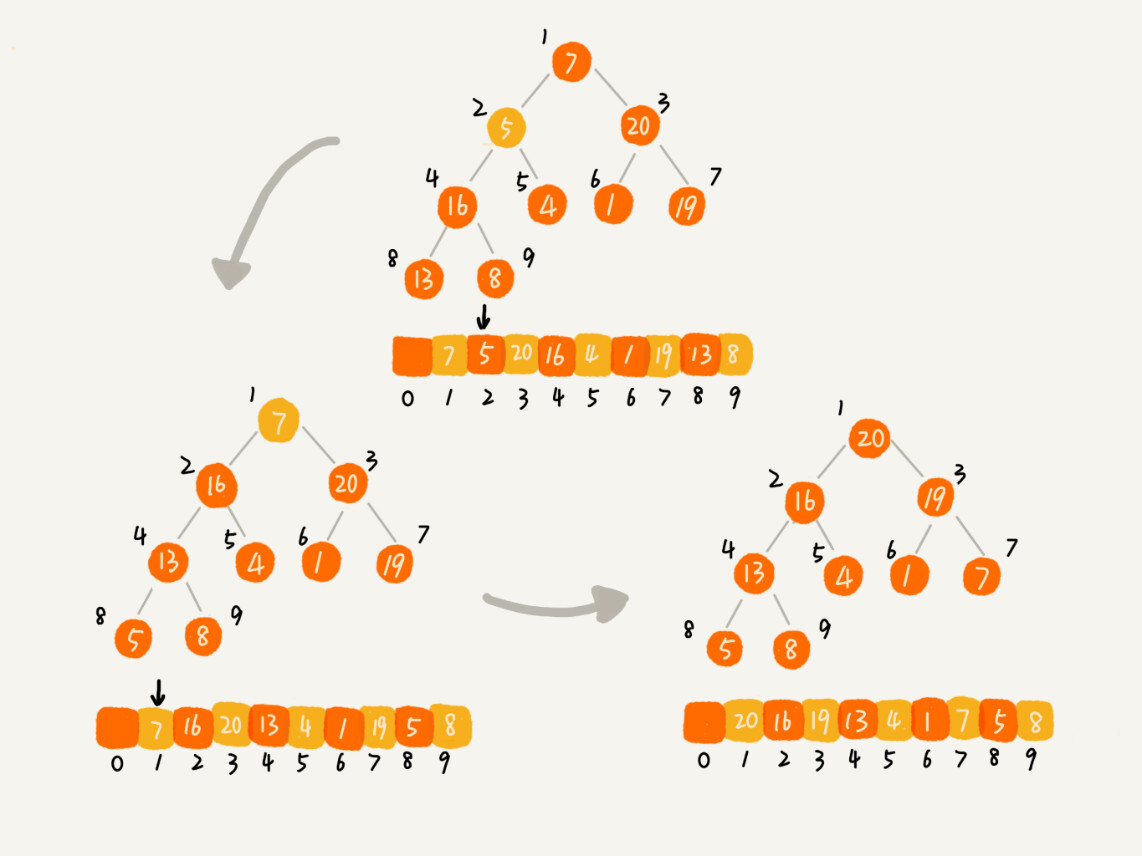
Java代码实现:
//3、第二种堆化的方法:
public void buildHeap(int[] a,int n){
for(int i=n/2;i>=1;--i){
heapity(a,n,i);
}
}
//2、自上往下堆化
private void heapity(int[] a, int n, int i) {
while(true){
int MaxPos=i;
if(i*2<=n && a[i]<a[i*2]) MaxPos=i*2;
if(i*2+1<=n && a[MaxPos]<a[i*2+1]) MaxPos=i*2+1;
if(MaxPos==i) break;
swap(a, i, MaxPos);
i=MaxPos;
}
}3、排序:
(1)建堆:建堆结束后,数组中的数据已经是按照大顶堆的特性组织的。数组中的第一个元素就是堆顶。
(2)取出最大值(类似删除操作):将堆顶元素a[1]与最后一个元素a[n]交换,这时,最大元素就放到了下标为n的位置。
(3)重新堆化:交换后新的堆顶可能违反堆的性质,需要重新进行堆化。
(4)重复(2)(3)操作,直到最后堆中只剩下下标为1的元素,排序就完成了。

Java代码实现:
//4、排序,n表示数据的个数。
public void sort(int[] a,int n) {
buildHeap(a,n);
int k=n;
while(k>1){
swap(a, 1, k);
--k;
heapity(a,k,1);
}
}
本篇博客主要参考《极客时间》王争的《数据结构与算法之美》专栏第28节。















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











