







背景
有个好久好久没怎么维护的Hadoop集群,一直在提供服务,也做了HA,由于某些原因要对HDFS做重启,重启前检查了遍服务,发现另一个NameNode已经挂了有一段时间了。
重启过程倒是没啥问题,但NameNode的Startup Progress特别久,持续Loading edits,将近3个小时。
分析
到NameNode的数据目录看了下,发现有大量的edits_*文件,加起来得有60G,这些文件也存在很久了,最早的文件貌似和StandBy NameNode挂掉的时间比较接近。edits文件很久没有做合并了,怀疑是跟另一个NameNode挂掉有关。
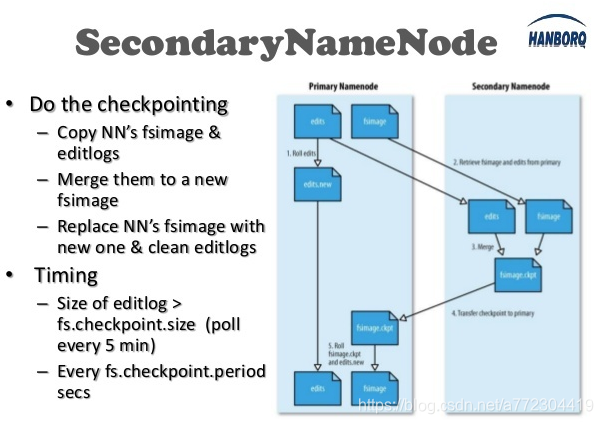
在网上也查了下NameNode合并的机制,果不其然,StandBy的NameNode平时并不是闲着的,虽然不对外提供服务,但是它会在后台默默的做edits的合并和JournalNode的同步等工作,合并edits文件后,也会同步给Active的NameNode,让它清理无用的edits文件。
SecondaryNamenode(也是StandBy NameNode)最重要作用,是定期合并FsImage和EditLog文件,并替换NameNode上的旧的FsImage文件,生成新的EditLog文件,替换原来的旧的EditLog文件。这样可以保证SecondaryNameNode上的文件为最近的信息。当发生宕机时候,可以快速恢复。
强制刷新edits文件
执行
hdfs dfsadmin -safemode enter
然后再执行
hdfs dfsadmin -saveNamespace
















 1831
1831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











