







传统的 Apache Hadoop架构存储和计算是耦合在一起的, HDFS作为其分布式文件系统也存在诸多不足。那么,如何实现Hadoop的存算分离,以规避HDFS的问题、降低成本、提升性能?
01、Hadoop分布式文件系统
在探讨如何实现存算分离来优化数据存储之前,我们先通过一张图来回顾Hadoop分布式文件系统的架构。从图中我们可以发现3个角色,分别是Namenode,Client,以及Datanodes。
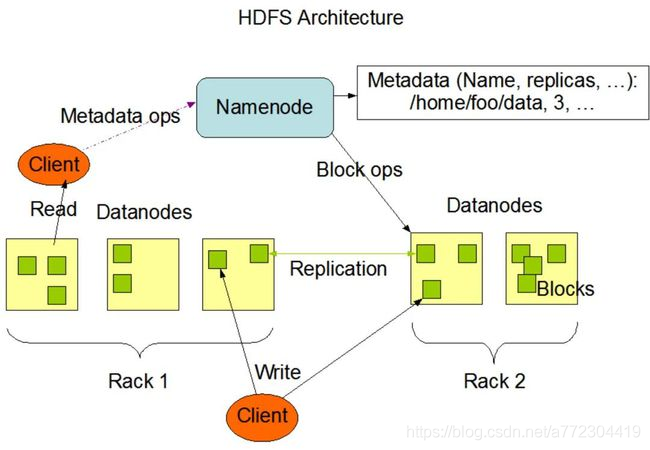
其中,Client是用户操作HDFS文件系统进行创建、删除、移动或重命名操作的客户端。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)和客户端对文件的访问。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件或目录。同时,Namenode也负责确定数据块到具体Datanode节点的映射。Datanode在集群中分布在各个节点,每个节点分布1个,管理所在节点的数据存储。
从内部看,HDFS暴露了文件系统的namespace,使用户能够以文件的形式在上面存储数据。一个文件被拆分为多个数据块,这些数据块存储在一组Datanode上,如图中绿色的方块,即代表被切分后的数据块。在Namenode的统一调度下,进行数据块的创建、删除和复制。Datanode也负责处理文件系统客户端的读写请求。
首先,我们来回顾Hadoop分布式文件系统HDFS写入数据的流程。我们以具体的需求引入,把本地文件上传到HDFS中,会经过哪些步骤?
Step 1: HDFS client将要上传的本地文件向Namenode提交请求,触发请求上传文件的前置校验,主要检查权限,并判断目录是否存在。如果校验失败,则本次上传失败。如果成功,即进入第二步。
Step 2: 请求上传,获取Datanode列表。Namenode会将本次上传的需要的Datanode节点列表反馈给HDFS的客户端。
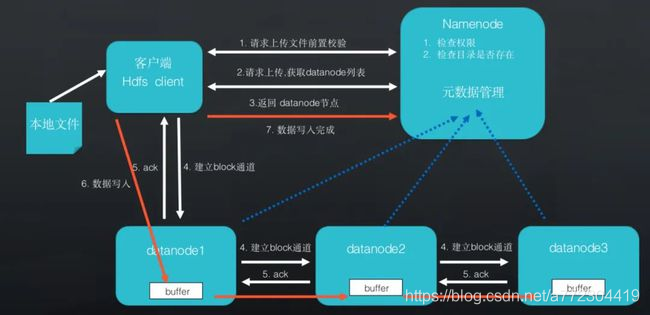
Step 3: 完成上述步骤后,客户端开始上传文件。客户端在上传文件的时候并不会将文件逐一上传到对应的Datanode上,而是建立block通道。如下图所示,Datanode1与Datanode2之间、Datanode2与Datanode3之间分别建立block通道。只需对Datanode1上传文件即可,无需再上传到其他Datanode上。
Step 4: block通道建立后,会触发Datanode的ack操作,当Datanode把ack返回给HDFS client,才开始真正准备文件上传操作。HDFS客户端将本地文件进行切块,写入到对应的Datanode上,写入对应的buffer中,后续将buffer中的内容转入磁盘中,并通过block通道把上传文件的文件流转发给后方的Datanode,以保障文件的上传。
Step 5: 数据写入完成后,HDFS client会将写入结果汇报给Namenode。
接着,我们来回顾Hadoop分布式文件系统(HDFS)读取数据的流程,也就是如何把上传的文件下载到本地。
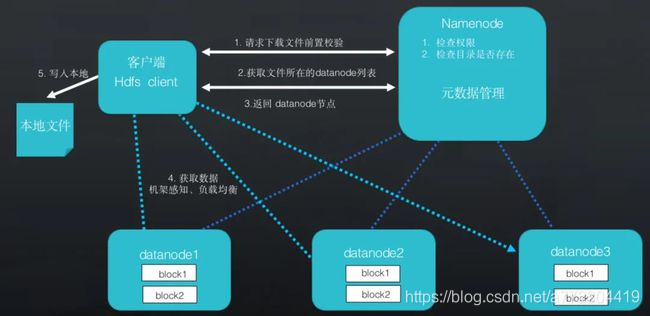
Step 1: HDFS client向Namenode提交下载文件前置校验的请求。与写入流程一致,Namenode开始检查权限。
Step 2: HDFS client获取文件所在的Datanode列表。因为Namenode是整个HDFS 的元数据管理,把文件所在的Datanode列表返回给HDFS client,进行依次的下载操作,将数据块下载到本地并拼接成完整的文件。
Step 3: 如下图所示,如果每次下载都通过Datanode1,则Datanode1负载的压力会过大。因此,获取数据的时候通过机架感知、负载均衡的算法,减轻Datanode1的压力,实现就近节点获取数据。
在Hadoop yarn的工作机制中,主要具有几大节点:Mapreduce客户端、Resouce Manager、Node Manager和Datanode。
02、Hadoop分布式文件系统的问题
回顾了Hadoop分布式文件系统的写入数据和读取数据流程,我们不难发现存在于Hadoop分布式文件系统中的问题。具体总结为以下几点:
1、计算存储耦合
在传统的Hadoop集群系统中,计算和存储资源是紧密耦合的。当存储空间或计算资源不足时,只能同时对两者进行扩容。如果用户的计算需求远远大于存储需求,此时扩容集群会造成存储的浪费,相反则计算资源被浪费。
2、扩容受限
主要体现为集群节点增多,导致扩容成本增加,风险增加。
3、HDFS性能问题
HDFS Namenode的全局锁虽然简化了锁模型降低了复杂度,但是全局锁最大的缺点就是容易产生性能瓶颈。HDFS管理者主要负责文件系统的运维空间,集群的配置信息和数据块的复制。Namenode在运行中保存的每个文件和每个数据块之间的关系,统称为元数据。在运行的时候,HDFS中每个文件、目录和数据块的元数据信息必须存储在Namenode的内存中。默认情况下,为每100万个数据块分配最大的空间,这就限制了实际HDFS中的对象数量,也意味着对于拥有大量文件的超大集群来说,内存会成为限制系统扩展的瓶颈。同时,作为一个可扩展的文件系统,单个集群中支持数千个节点,在单个命名空间的Datanode中可以实现很好的扩展。但Namenode不能在单个空间进行横向扩展,因此,通常情况下,HDFS的性能瓶颈存在于单个的Namenode之上。
4、HDFS成本问题
在HDFS文件系统中典型文件大小一般都在G字节至T字节,由于HDFS的副本特性一份文件至少会存储3份,这些额外的空间会带来存储成本额外的提高。
针对上述问题,现在Hadoop采用存算分离的架构的方案趋势越来越明显。
03、Hadoop实现存算分离的方案
对于Hadoop分布式文件系统存在的计算资源及存储成本等问题,我们目前有两种实现存算分离的解决方案。
方案一:Hadoop 兼容的文件系统

上图是Hadoop3.X目前兼容的文件系统,支持AWS s3、腾讯云COS、阿里云OSS存储,从图中可以看出,用户在上传数据时候,需要调用对应云服务厂商的sdk进行数据的写入。下载文件也是同样原理。
为什么可以使用这种方式实现Hadoop的计算存储分离呢?
我们以日常生活事件为例:家里带宽升级到100Mbps后,我们在线看电影的时候不会出现卡顿,下载一部电影只需几分钟。而在几年前带宽很低的时候,下载一部电影可能需要数个小时。带宽的速度,尤其是机房内带宽的速度,当前已经变为1000Mbps、2000Mbps、10000Mbps,甚至100000Mbps。但是磁盘的速度基本没有太大的变化。带宽速度的提高带来了软件架构的变化。
方案二:云原生的Hadoop文件系统
虽然方案一可以实现计算存储分离,但是基本架构上还是存在问题:虽然带宽增加,但是如果Hadoop集群机房和对应的对象存储机房距离较远,网络抖动等因素加大了传输失败的几率。假如判断一个目录需要多次的RESTful请求才能完成操作,多次请求会对性能造成影响。因此,我们提出了方案二:DataSimba文件缓存层。
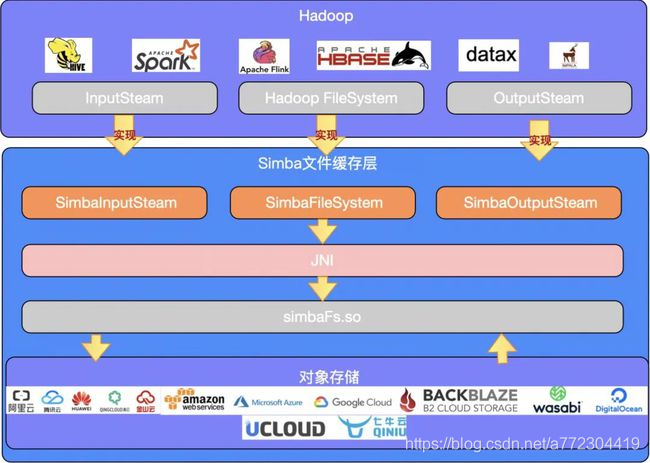
上图是目前DataSimba的存算分离架构,SimbaFsClient是一个java开发的jar包,兼容Hadoop文件系统,按照Hadoop FileSystem API规范来实现。DataSimba文件缓存层主要实现了Hadoop FileSystem的list、delete、rename、mkdir等接口,其中InputStream和OutputStream主要实现了对文件的读写优化等相关功能(预读、缓存读、异步写、批量写、文件压缩)。
DataSimba文件缓冲层通过JNI (Java Native Interface) 技术转换为本地simbafs.so的调用实现相关方法,完成文件的上传/下载操作,作为中间缓存层实现计算存储分离。
由此,DataSimba文件缓存层有效规避了计算存储紧密耦合、扩容空间及存储成本等问题。
















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











