







1、字面量相加
首先来看两个字面量字符串相加发生了什么情况,Java代码:
|
1
2
3
4
5
6
7
8
|
package
com.jaffa.test.string;
public
class
StringOptTest {
public
static
void
main(String[] args){
//假设下面不符合常理的写法发生了,看聪明的编译器为我们做什么
String str1 =
"abc"
+
"def"
;
}
}
|
编译后常量池列表和指令截图如下:
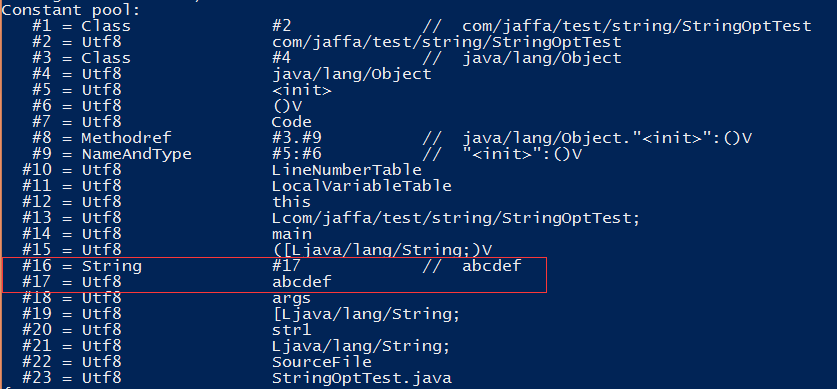
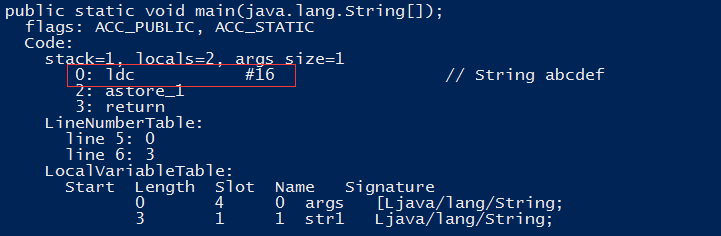
通过编译后常量池列表和指令我们发现”abc”和”def”在编译阶段被自动合成一个字符串常量了,减少运行时的指令运算。对于两个字面量的操作还适用于基本类型,如int、float、long、double等,在编译时都会对两个字面量进行运算。但是如果是一个错误的运算结果,那么编译保留原生的字节码指令,运行时报异常,如下面测试代码:
|
1
|
int
iNum =
1
/
0
;
|
2、声明变量的方式相加
|
1
2
3
|
String str1 =
"abc"
;
String str2 =
"def"
;
String str3 = str1 + str2;
|
常量池列表:
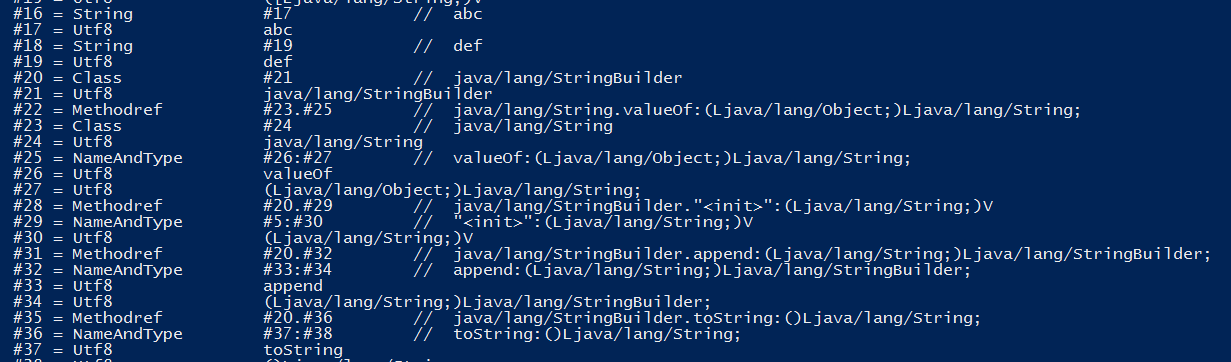
字节码指令:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
0
: ldc #
16
2
: astore_1
3
: ldc #
18
5
: astore_2
6
:
new
#
20
9
: dup
10
: aload_1
11
: invokestatic #
22
14
: invokespecial #
28
17
: aload_2
18
: invokevirtual #
31
21
: invokevirtual #
35
24
: astore_3
25
:
return
|
在字节码指令第6个是先new #20,即声明了一个java.lang.StringBuilder的对象,接着执行aload_1将”abc”从栈帧的局部变量表加载到操作数栈中,执行invokestatic #22调用String.valueOf(Ljava/lang/Object)得字符串,并调用invokespecial #28来完成StringBuilder的初始化工作,即new StringBuilder(“abc”)。第17,18个执行指令完成了append(“def”)的操作,最后执行21、24指令将数据存储第3个局部变量中。所以可以得到被编译优化后的代码应该如下:
|
1
2
3
4
|
String str1 =
"abc"
;
String str2 =
"def"
;
//String str3 = str1 + str2;
String str3 =
new
StringBuilder(String.valueOf(str1)).append(str2).toString();
|
通过验证是否可以说明在开发时可以直接使用String来操作字符相加呢,当然不是,如果只是简单的两个短字符串相加在性能上影响不大,但是如果所要操作的是一个大内容的字符串时,在使用上是建议通过new StringBuilder(capacity)来显示声明对象,因为大量的内容相加StringBuilder内部会不断扩展存放空间和复制数据来满足操作,这样会带来额外的消耗,下面这段代码两个情况执行效率上存在差距。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
long
time1 = System.currentTimeMillis();
long
index =
0
;
String str1 =
"abc"
;
String str2 =
"def"
;
while
(index<=
1000000
){
//cost time 3383
StringBuilder str3 =
new
StringBuilder(
200
);
//cost time 9821
//String str3 = null;
for
(
int
i=
0
;i<
100
;i++){
str3.append(str1).append(str2);
//str3 += str1+str2;
}
index ++;
}
System.out.printf(
"cost time %s"
,System.currentTimeMillis()-time1);
|
3、类成员属性
|
1
2
3
4
5
6
7
|
package
com.jaffa.test.string;
public
class
StringOptTest {
private
String str1 =
"abc"
;
private
String str2 =
"def"
;
private
String str3 = str1+str2;
}
|
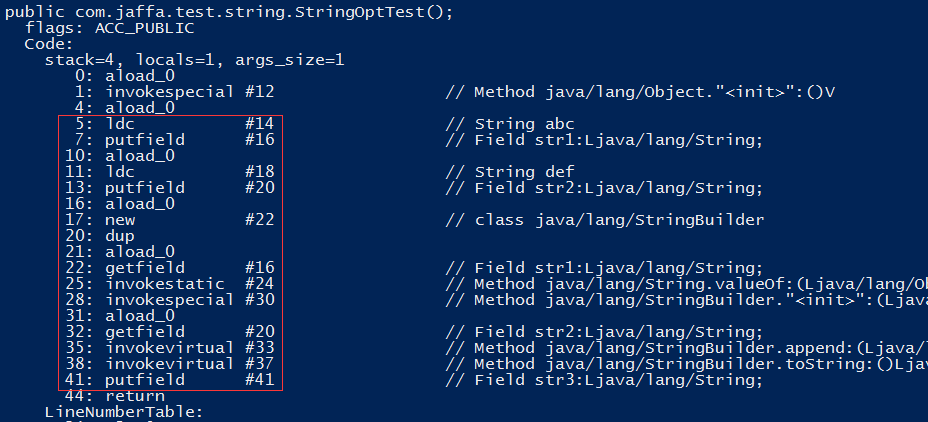
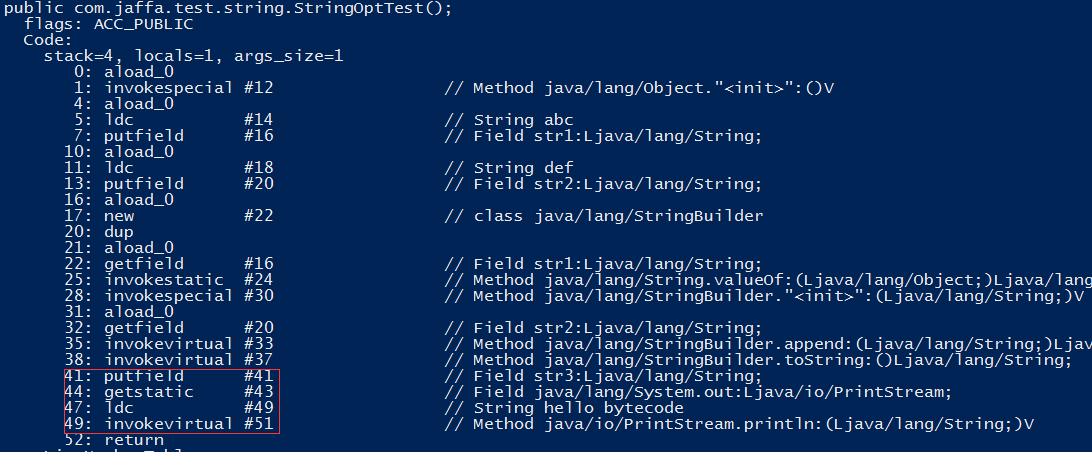
从编译后地字节码我们发现默认生成一个不带参数的构造函数,所有的成员初始化操作在构造函数中完成,注意这里和静态方法不太一样,默认会有aload_0表示实例本身,即this对象是默认参数传入。如果我们显示的编写一个构造函数时,构造函数中的代码会放在初始化成员属性后面执行。如下截图。















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









