








原理图(摘自网络):
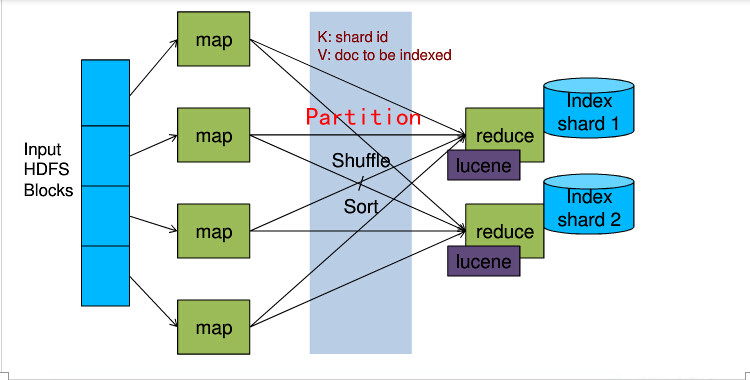
1、datasource
hdfs或者
TableMapReduceUtil来scan数据(不建议HFileInputFomat方式,易丢失数据)
2、map
setup()方法中通过zkHost创建CloudSolrServer,目的是通过docId,来计算这个docId应该router到哪个shardId,关键代码为:
// copy from org.apache.solr.common.cloud.HashBasedRouter
private int sliceHash(String id) {
return Hash.murmurhash3_x86_32(id, 0, id.length(), 0);
}
// copy from org.apache.solr.common.cloud.HashBasedRouter
private Slice hashToSlice(int hash, DocCollection collection) {
for (Slice slice : collection.getSlices()) {
Range range = slice.getRange();
if (range != null && range.includes(hash))
return slice;
}
throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, "No slice servicing hash code " + Integer.toHexString(hash) + " in " + collection);
}
map()方法,输入(ImmutableBytesWritable , Result )输出(Text, Result)即将
ImmutableBytesWritable计算shardId(比如:shard1,shard2...)
关键代码:
@Override
protected void map(ImmutableBytesWritable key, Result columns, Context context) throws IOException, InterruptedException {
String id = Bytes.toString(columns.getRow());
int sliceHash = sliceHash(id);
Slice slice = hashToSlice(sliceHash, cstate.getCollection(defau_collection));
String shardid = slice.getName();// shard1,shard2 ...
context.write(new Text(shardid), columns);
}
3、
Partitioner
通过shardId,随机发散到多个reduce,即一个shard数据,多个reduce来建索引,更高效
关键代码:
/**
*
numPartitions为配置一个shard对应多少个reduce
*/
@Override
public int getPartition(Text key, Result result, int numPartitions) {
initReducerTimes();
int shardId = Integer.valueOf(key.toString().substring(5))-1;// 十位
int part2 = (int) Math.round(Math.random() * (reducerTimes-1));// 个位
return reducerTimes * shardId + part2;
}
4、reduce
setup()方法中获取partition,计算shardid,
通过zkHost获取cloudServer,最后ConcurrentUpdateSolrServer,这个solrServer就是针对某个shard建索引的server。
关键代码:
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
zk_host = conf.get(IndexingConfig.ZK_HOST, zk_host);
defau_collection = conf.get(IndexingConfig.DEFAULT_COLLECTION, defau_collection);
// max_segments = conf.getInt(IndexingConfig.MAX_SEGMENTS, max_segments);
document_buffer_size = conf.getInt(IndexingConfig.DOCUMENT_BUFFER_SIZE, document_buffer_size);
solr_thread_count = conf.getInt(IndexingConfig.SOLR_THREAD_COUNT, solr_thread_count);
id_field = conf.get(IndexingConfig.ID_FIELD, id_field);
logger.info("初始化server...");
try {
cloudServer = new CloudSolrServer(zk_host);
cloudServer.setDefaultCollection(defau_collection);
SolrPingResponse response = cloudServer.ping();
logger.info("status:" + response.getStatus());
if (response.getStatus() != 0) {
logger.error("服务有问题");
throw new RuntimeException("服务响应不正常");
}
logger.info(cloudServer.ping().toString());
} catch (Exception e) {
logger.error("", e);
throw new RuntimeException("配置好solr服务");
}
logger.info("初始化结束");
// 取得partition
partition = conf.get("mapred.task.partition");// 0~79
// 根据partition来启动不同的solrServer
shardid = getShardId(partition);
ZkStateReader reader = cloudServer.getZkStateReader();
try {
String url = reader.getLeaderUrl(defau_collection, "shard" + shardid, 3000);
//solrServer = new ConcurrentUpdateSolrServer(url, document_buffer_size, solr_thread_count);
solrServer = new HttpSolrServer(url);
System.out.println("###url: " + url);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
initTransformers();
initFieldBoost();
// transformers init();
for (TransformerMR t :transformers) {
t.init(conf);
}
}
总结:重点在于直接将doc router到正确的shard,而不经过solrCloud的内部router(实际上是copy其router源码);并且每个shard对应多个reduce,随机发散,增加一层并发。
注意:
ConcurrentUpdateSolrServer使用了 final BlockingQueue<UpdateRequest> queue;
在高并发过程中(mapreduce建索引),会造成阻塞问题,丢失数据。
原因可能有2个
1、
queue满了,写不进去,请求连接中断
2、
queue还有数据未写入硬盘,直接执行optimize()操作
换成HttpSolrServer就没有问题了,solrServer = new HttpSolrServer(url);















 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









