







awk
awk特殊变量
Awk特殊变量 | 描述 |
$number | 表示记录的字段。比如,$1表示第1个字段,$2表示第2个字段,如此类推。而$0比较特殊,表示整个当前行 |
FS | 表示字段分隔符 Filed Separator |
NF | 表示当前记录中的字段数量 Number Filed |
NR | 表示当前记录的编号(awk将第一个记录算作记录号1) Number Record |
Awk特殊变量 | 描述 |
RS | 表示记录分隔符 Record Separator |
OFS | 表示输出字段分隔符,在两个单独的字段间插入定义的字符串 Output Filed Separator |
ORS | 表示输出记录分隔符,在两个单独的记录间插入定义的字符串 Output Record Separator |
-v :定义变量 awk -v i=0
-F :定义字段分割符,同FS
测试文件,通讯录文件address,其内容如下:
zhangsan 13712345678 zhs@hotmail.com
lisi 13012345678 ls@21cn.com |
要处理这个文件,可以将每三行看作是一个独立的记录,一个记录包含三个字段。如下脚本将原记录由三行转换成一行输出:
BEGIN { FS="\n" RS="" }
{ print $1 ", " $2 ", " $3 } |
此代码将产生以下输出:
zhangsan, 13712345678, zhs@hotmail.com lisi, 13012345678, ls@21cn.com |
在上面例子中,为了在三个字段之间插入一个逗号和空格,使用了", "。这个方法虽然有用,但比较难看。其实我们还有更好的方法,那就是设置变量OFS(输出字段分隔符)。OFS缺省情况下被设置成" "(单个空格)。使用如下脚本可以达到上面例子同样的效果:
BEGIN { FS="\n" RS="" OFS=", " }
{ print $1, $2, $3 } |
awk还有一个特殊变量ORS(输出记录分隔符)。ORS缺省情况下被设置成"\n",如果我们将其设为"\n\n",就可以使输出记录的间隔翻倍。
需要注意的是,使用上面的方法,最多只能处理一个记录占用三行的文本,象下面一个记录占据四行的通讯录,就处理不了了(大家可以试试看):
wangwu 13512345678 ww@163.com wuhan, hubei |
要处理这种情况,代码最好考虑每个记录的字段数量,并依次打印每个记录。以下就是修正的代码:
BEGIN { FS="\n" RS="" ORS="" }
{ x=1 while ( x<NF ) { print $x "\t" x++ } print $NF "\n" } |
条件控制语句
awk的if语句类似于C语言的if语句,没什么好说的,举一个例子吧:
{ if ( $1 == "foo" ) { if ( $2 == "foo" ) { print "uno" } else { print "one" } } else if ($1 == "bar" ) { print "two" } else { print "three" } } |
其时在第1节的最后,我们已经看到了awk的while循环结构,它等同于相应的C语言while循环。awk还有"do...while"循环,它在代码块结尾处对条件求值,还是直接举例吧:
do...while 示例
{ count=1 do { print "I get printed at least once no matter what" } while ( count != 1 ) } |
for 循环
也等同于C语言的for循环:
for ( x = 1; x <= 4; x++ ) { print "iteration",x } |
break和 continue
此外,如同C语言一样,awk提供了break、continue来控制awk的循环结构。break语句用于跳出最深层的循环,使循环立即终止,并继续执行循环代码块后面的语句。continue语句使awk立即开始执行下一个循环迭代,而不执行代码块的其余部分。
在awk中,数组下标通常从1开始,而不是0:
myarray[1]="jim" myarray[2]=456 |
awk遇到第一个赋值语句时,它将创建myarray,并将元素myarray[1]设置成"jim"。执行了第二个赋值语句后,数组就有两个元素了。Awk数组不需要连续的数字序列下标(例如,可以定义myarr[1]和myarr[1000],但不定义其它所有元素)
awk可以使用"in"操作来遍历数组中的所有元素,如下所示:
for ( x in myarray ) { print myarray[x] } |
但是这个方法有一个缺点——当awk在数组下标之间轮转时,它不会依照任何特定的顺序。那就意味着我们不能知道以上代码的输出是:
jim 456 |
还是
456 jim |
awk数组中还可以使用字符串下标,其实,不管你使用的下标是字符串还是数字,awk在幕后还将其认为是字符串下标。举例如下:
代码一:
myarr["1"]="China" print myarr["1"] |
代码二:
myarr["1"]="Mr. Whipple" print myarr[1] |
代码三:
myarr["name"]="Mr. Whipple" print myarr["name"] |
它们都将打印 "China"!
删除数组元素使用delete,举例如下:
delete fooarray[1] |
另外,如果想要查看是否存在某个特定数组元素,可以使用特殊的"in"布尔运算符,如下所示:
if ( 1 in fooarray ) { print "It's there." } else { print "Can't find it." } |
虽然大多数情况下awk的print语句可以完成任务,但有时我们还需要更多。使用两个函数printf()、sprintf(),将能让输出锦上添花。printf()会将格式化字符串打印到stdout,而sprintf()则返回可以赋值给变量的格式化字符串。
从下面例子可以看到,它们几乎与C语言完全相同。
x=1 b="foo" printf("%s got a %d on the last test\n","Jim",83) myout=("%s-%d",b,x) print myout |
此代码将打印:
Jim got a 83 on the last test foo-1 |
既然awk把所有变量都当作字符串处理,那么字符串处理对awk就显得尤为重要。但要说明一点,awk不能象在其它语言(如 C、C++)中那样将字符串看作是字符数组。例如,如果执行以下代码:
mystring="How are you doing today?" print mystring[3] |
将会接收到一个错误,如下所示:
awk: string.gawk:59: fatal: attempt to use scalar as array |
不用担心,awk有许多字符串函数,弥补了这个缺陷。现将常用的字符串函数列举如下:
字符串函数 | 描述 |
length() | 返回字符串的长度 |
index() | 返回子字符串在另一个字符串中出现的位置 |
tolower() | 返回字符串并且将所有字符转换成小写 |
toupper() | 返回字符串并且将所有字符转换成大写 |
substr() | 返回从字符串中选择的子串 |
match() | 返回子字符串在另一个字符串中出现的位置。它与index()的区别在于它并不搜索子串,它搜索的是正则表达式。 |
sub() | 替换匹配的第一个字符序列,并返回整个字符串 |
gsub() | 替换匹配的全部字符序列,并返回整个字符串 |
split() | 分割字符串,并将各部分放到使用整数下标的数组中 |
length()返回字符串的长度,例子如下:
print length(mystring) |
index()返回子字符串在另一个字符串中出现的位置,如果没有找到该字符串则返回0,例子如下:
print index(mystring,"you") |
tolower()和toupper()返回字符串并且将所有字符分别转换成小写或大写。注意,tolower()和toupper()返回新的字符串,不会修改原来的字符串。例子如下:
print tolower(mystring) print toupper(mystring) |
使用substr()可以从字符串中选择子串。以下是substr()的调用方法:
mysub=substr(mystring,startpos,maxlen) |
以下是一个示例:
print substr(mystring,9,3) |
match()与index()非常相似,它与index()的区别在于它并不搜索子串,它搜索的是正则表达式。match()函数将返回匹配的起始位置,如果没有找到匹配,则返回0。此外,match()还将设置两个变量,叫作RSTART和RLENGTH。RSTART包含返回值(第一个匹配的位置),RLENGTH指定它占据的字符跨度(如果没有找到匹配,则返回-1)。通过使用RSTART、RLENGTH、substr()和一个小循环,可以轻松地遍历字符串中的每个匹配。以下是一个match()调用示例:
print match(mystring,/you/), RSTART, RLENGTH |
sub()和gsub()是两个字符串替换函数。sub()的调用方法如下:
sub(regexp,replstring,mystring) |
调用sub()时,它将在mystring中匹配regexp的第一个字符序列,并且用replstring替换该序列。gsub()与sub()的唯一的区别是sub()替换第一个regexp匹配(如果有的话),gsub()则执行全局替换,换出字符串中的所有匹配。举例如下:
sub(/o/,"O",mystring) print mystring mystring="How are you doing today?" gsub(/o/,"O",mystring) print mystring |
其输出结果如下:
HOw are you doing today? HOw are yOu dOing tOday? |
split()的功能是分割字符串,并将分割后的各部分放到使用整数下标的数组中。此函数有三个变量,第一个自变量为要分割的原始字符串,第二个自变量为分割后填入的数组名称,第三个变素为用于指示分割的分隔符。split()返回时,它将返回分割的字符串元素的数量。split()将分割的每一个部分赋值给下标从1开始的数组。举例如下:
numelements=split("Jan,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,Dec",mymonths,",") print mymonths[1],mymonths[numelements] |
其输出如下:
Jan Dec |
最后需要说明一点的是,调用length()、sub()或gsub()时,可以去掉最后一个变量,这样awk将对$0(整个当前行)应用函数调用。例如要打印文件中每一行的长度,使用以下awk脚本:
{ print length() } |
head
head [参数]... [文件]...
命令功能:
head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
命令参数:
-q 隐藏文件名
-v 显示文件名
-c<字节> 显示字节数
-n<行数> 显示的行数
使用实例:
实例1:显示文件的前n行
命令:head -n 5 log2014.log
grep
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep --help 匹配模式选择: -E, --extended-regexp 扩展正则表达式egrep -F, --fixed-strings 一个换行符分隔的字符串的集合fgrep -G, --basic-regexp 基本正则 -P, --perl-regexp 调用的perl正则 -e, --regexp=PATTERN 后面根正则模式,默认无 -f, --file=FILE 从文件中获得匹配模式 -i, --ignore-case 不区分大小写 -w, --word-regexp 匹配整个单词 -x, --line-regexp 匹配整行 -z, --null-data 一个 0 字节的数据行,但不是空行 杂项: -s, --no-messages 不显示错误信息 -v, --invert-match 显示不匹配的行 -V, --version 显示版本号 --help 显示帮助信息
输入控制: -m, --max-count=NUM 匹配的最大数 -b, --byte-offset 打印匹配行前面打印该行所在的块号码。 -n, --line-number 显示的加上匹配所在的行号 --line-buffered 刷新输出每一行 -H, --with-filename 当搜索多个文件时,显示匹配文件名前缀 -h, --no-filename 当搜索多个文件时,不显示匹配文件名前缀 --label=LABEL print LABEL as filename for standard input -o, --only-matching 只显示一行中匹配PATTERN 的部分 -q, --quiet, --silent 不显示任何东西 --binary-files=TYPE 假定二进制文件的TYPE 类型; TYPE 可以是`binary', `text', 或`without-match' -a, --text 匹配二进制的东西 -I 不匹配二进制的东西 -d, --directories=ACTION 目录操作,读取,递归,跳过 -D, --devices=ACTION 设置对设备,FIFO,管道的操作,读取,跳过 -R, -r, --recursive 递归调用 --include=PATTERN 只查找匹配FILE_PATTERN 的文件 --exclude=PATTERN 跳过匹配FILE_PATTERN 的文件和目录 --exclude-from=FILE 跳过所有除FILE 以外的文件 -L, --files-without-match 匹配多个文件时,显示不匹配的文件名 -l, --files-with-matches 匹配多个文件时,显示匹配的文件名 -c, --count 显示匹配了多少次 -Z, --null 在FILE 文件最后打印空字符 文件控制: -B, --before-context=NUM 打印匹配本身以及前面的几个行由NUM控制 -A, --after-context=NUM 打印匹配本身以及随后的几个行由NUM控制 -C, --context=NUM 打印匹配本身以及随后,前面的几个行由NUM控制 -NUM 根-C的用法一样的 --color[=WHEN], --colour[=WHEN] 使用标志高亮匹配字串; -U, --binary 使用标志高亮匹配字串; -u, --unix-byte-offsets 当CR 字符不存在,报告字节偏移(MSDOS 模式)
监控网络客户连接数:netstat -n | grep tcp | grep 侦听端口 | wc -l
显示匹配的个数,不显示内容:
[root@krlcgcms01 test]# cat test|grep -c zhang 3
匹配system,-i:不区分大小写,-n:显示行号。
[root@krlcgcms01 test]# grep system test [root@krlcgcms01 test]# grep -ni system test 9:dbus:x:81:81:System message bus:/:/bin/false
匹配单词:匹配zhan没有匹配到东西,匹配zhangy能匹配到,因为在test文件中,有zhangy这个单词
[root@krlcgcms01 test]# cat test|grep -w zhan [root@krlcgcms01 test]# cat test|grep -w zhangy zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash ba:x:1002:1002::/home/zhangy:/bin/bash
不匹配以bin开头的行,并显示行号
[root@krlcgcms01 test]# cat test|grep -nv '^bin' root:x:0:0:root:/root:/bin/bash DADddd:x:2:2:daemon:/sbin:/bin/false mail:x:8:12:mail:/var/spool/mail:/bin/false ftp:x:14:11:ftp:/home/ftp:/bin/false &nobody:$:99:99:nobody:/:/bin/false zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash http:x:33:33::/srv/http:/bin/false dbus:x:81:81:System message bus:/:/bin/false hal:x:82:82:HAL daemon:/:/bin/false mysql:x:89:89::/var/lib/mysql:/bin/false aaa:x:1001:1001::/home/aaa:/bin/bash ba:x:1002:1002::/home/zhangy:/bin/bash test:x:1003:1003::/home/test:/bin/bash @zhangying:*:1004:1004::/home/test:/bin/bash policykit:x:102:1005:Po
多文件匹配时,显示匹配文件的文件名
[apacheuser@krlcgcms01 test]$ grep -l 'root' test test2 testbak DAta test test2 testbak
多文件匹配时,在匹配的行前面加上文件名
[apacheuser@krlcgcms01 test]$ grep -H 'root' test test2 testbak test:root:x:0:0:root:/root:/bin/bash test2:root testbak:root:x:0:0:root:/root:/bin/bash
匹配以root开头或者以zhang开头的行,注意反斜杠
[root@krlcgcms01 test]# cat test |grep '^\(root\|zhang\)' root:x:0:0:root:/root:/bin/bash zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash
find
找出文件名为2015-11-11.txt且小于2k的文件并删除nohup find . -type f -size -2k -name 2015-11-11.txt | xargs rm -rf &
nohup find . -mtime +6 -name *.txt -print | xargs rm -rf &
find可谓是aix/linux上使用较多的维护用命令,但很多时候需要用到针对时间的搜索。本文主要对find中搭配atime、ctime和mtime的各种参数进行介绍。
atime:访问时间(access time),指的是文件最后被读取的时间,可以使用touch命令更改为当前时间;
ctime:变更时间(change time),指的是文件本身最后被变更的时间,变更动作可以使chmod、chgrp、mv等等;
mtime:修改时间(modify time),指的是文件内容最后被修改的时间,修改动作可以使echo重定向、vi等等;
以下例子应该很容易理解上述三个时间:某用户在2013年1月5日00:00:00时,
在/home下输入ping www.baidu.com > ping.log;5秒钟后,该用户使ctrl+C强制关闭该命令;5秒钟后,使用cat ping.log查看。则ping.log的ctime为2013-01-05 00:00:00;mtime为2013-01-05 00:00:05;atime为2013-01-05 00:00:10。
这三个参数理解后,我们就可以使用find找到某个时刻进行过某类操作的文件集合。
find . {-atime/-ctime/-mtime/-amin/-cmin/-mmin} [-/+]num
第一个参数,.,代表当前目录,如果是其他目录,可以输入绝对目录和相对目录位置;
第二个参数分两部分,前面字母a、c、m分别代表访问、变更、修改,后面time为日期,min为分钟,注意只能以这两个作为单位;
第三个参数为量,其中不带符号表示符合该数量的,带-表示符合该数量以后的,带+表示符合该数量以前的。
注意:find中对于时间的推算均为:
1、到......为止用+号,从......开始用-号,一个时间单位内的不带符号;
2、数字代表往前偏移量;
3、当前到往后的一个时间单位为基准0;-0就是下限单位;+0就是上限单位。
sort
sort 命令对 File 参数指定的文件中的行排序,并将结果写到标准输出。如果 File 参数指定多个文件,那么 sort 命令将这些文件连接起来,并当作一个文件进行排序。
sort语法
[root@www ~]# sort [-fbMnrtuk] [file or stdin]选项与参数:-f :忽略大小写的差异,例如 A 与 a 视为编码相同;-b :忽略最前面的空格符部分;-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;-n :使用『纯数字』进行排序(默认是以文字型态来排序的);-r :反向排序;-u :就是 uniq ,相同的数据中,仅出现一行代表;-t :分隔符,默认是用 [tab] 键来分隔;-k :以那个区间 (field) 来进行排序的意思
对/etc/passwd 的账号进行排序
[root@www ~]# cat /etc/passwd | sortadm:x:3:4:adm:/var/adm:/sbin/nologinapache:x:48:48:Apache:/var/www:/sbin/nologinbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin
/etc/passwd 内容是以 : 来分隔的,我想以第三栏来排序,该如何
[root@www ~]# cat /etc/passwd | sort -t ':' -k 3root:x:0:0:root:/root:/bin/bashuucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologinbin:x:1:1:bin:/bin:/sbin/nologingames:x:12:100:games:/usr/games:/sbin/nologin
默认是以字符串来排序的,如果想要使用数字排序:
cat /etc/passwd | sort -t ':' -k 3nroot:x:0:0:root:/root:/bin/bashdaemon:x:1:1:daemon:/usr/sbin:/bin/shbin:x:2:2:bin:/bin:/bin/sh
默认是升序排序,如果要倒序排序,如下
cat /etc/passwd | sort -t ':' -k 3nrnobody:x:65534:65534:nobody:/nonexistent:/bin/shntp:x:106:113::/home/ntp:/bin/falsemessagebus:x:105:109::/var/run/dbus:/bin/falsesshd:x:104:65534::/var/run/sshd:/usr/sbin/nologin
如果要对/etc/passwd,先以第六个域的第2个字符到第4个字符进行正向排序,再基于第一个域进行反向排序。
cat /etc/passwd | sort -t':' -k 6.2,6.4 -k 1r sync:x:4:65534:sync:/bin:/bin/syncproxy:x:13:13:proxy:/bin:/bin/shbin:x:2:2:bin:/bin:/bin/shsys:x:3:3:sys:/dev:/bin/sh
查看/etc/passwd有多少个shell:对/etc/passwd的第七个域进行排序,然后去重:
cat /etc/passwd | sort -t':' -k 7 -uroot:x:0:0:root:/root:/bin/bashsyslog:x:101:102::/home/syslog:/bin/falsedaemon:x:1:1:daemon:/usr/sbin:/bin/shsync:x:4:65534:sync:/bin:/bin/syncsshd:x:104:65534::/var/run/sshd:/usr/sbin/nologin
uniq
用途
报告或删除文件中重复的行。
语法
uniq [ -c | -d | -u ] [ -f Fields ] [ -s Characters ] [ -Fields ] [ +Characters ] [ InFile [ OutFile ] ]
描述
uniq 命令删除文件中的重复行。
uniq 命令读取由 InFile 参数指定的标准输入或文件。该命令首先比较相邻的行,然后除去第二行和该行的后续副本。重复的行一定相邻。(在发出 uniq 命令之前,请使用 sort 命令使所有重复行相邻。)最后,uniq 命令将最终单独的行写入标准输出或由 OutFile 参数指定的文件。InFile 和 OutFile 参数必须指定不同的文件。如果输入文件用“- ”表示,则从标准输入读取;输入文件必须是文本文件。文本文件是包含组织在一行或多行中的字符的文件。这些行的长度不能超出 2048 个字节(包含所有换行字符),并且其中不能包含空字符。
缺省情况下,uniq 命令比较所有行。如果指定了-f Fields 或 -Fields 标志, uniq 命令忽略由 Fields 变量指定的字段数目。 field 是一个字符串,用一个或多个 <空格 > 字符将它与其它字符串分隔开。
如果指定了 -s Characters 或 -Characters 标志, uniq 命令忽略由 Characters 变量指定的字段数目。为 Fields 和 Characters 变量指定的值必须是正的十进制整数。
当前本地语言环境决定了 -f 标志使用的 <空白> 字符以及 -s 标志如何将字节解释成字符。
如果执行成功,uniq 命令退出,返回值 0。否则,命令退出返回值大于 0。
标志
-c 在输出行前面加上每行在输入文件中出现的次数。
-d 仅显示重复行。
-u 仅显示不重复的行。
-f Fields 忽略由 Fields 变量指定的字段数目。如果 Fields 变量的值超过输入行中的字段数目, uniq 命令用空字符串进行比较。这个标志和 -Fields 标志是等价的。
-s Characters 忽略由 Characters 变量指定的字符的数目。如果 Characters 变量的值超过输入行中的字符的数目, uniq 用空字符串进行比较。如果同时指定 -f 和 -s 标志, uniq 命令忽略由 -s Characters 标志指定的字符的数目,而从由 -f Fields 标志指定的字段后开始。 这个标志和 +Characters 标志是等价的。
-Fields 忽略由 Fields 变量指定的字段数目。这个标志和 -f Fields 标志是等价的。
+Characters 忽略由 Characters 变量指定的字符的数目。如果同时指定 - Fields 和 +Characters 标志, uniq 命令忽略由 +Characters 标志指定的字符数目,并从由 -Fields 标志指定的字段后开始。 这个标志和 -s Characters 标志是等价的。
- c 显示输出中,在每行行首加上本行在文件中出现的次数。它可取代- u和- d选项。
- d 只显示重复行 。
- u 只显示文件中不重复的各行 。
- n 前n个字段与每个字段前的空白一起被忽略。一个字段是一个非空格、非制表符的字符串,彼此由制表符和空格隔开(字段从0开始编号)。
+ n 前n个字符被忽略,之前的字符被跳过(字符从0开始编号)。
- f n 与- n相同,这里n是字段数。
- s n 与+n相同,这里n是字符数。
退出状态
该命令返回以下退出值:
0 命令运行成功。
>0 发生错误。
补充
文件经过处理后在它的输出文件中可能会出现重复的行。例如,使用cat命令将两个文件合并后,再使用sort命令进行排序,就可能出现重复行。这时可以使用uniq命令将这些重复行从输出文件中删除,只留下每条记录的唯一样
示例
要删除名为 fruit 文件中的重复行并将其保存到一个名为 newfruit 的文件中,输入:
uniq fruit newfruit
如果 fruit 文件包含下列行:
apples
apples
peaches
pears
bananas
cherries
cherries
则在您运行uniq 命令后 newfruit 文件将包含下列行:
apples
peaches
pears
bananas
cherries
文件/usr/bin/uniq 包含 uniq 命令。
# uniq -c 的用法,例如:
harley
casely
weedly
harley
linda
#cut -c 1-8 | sort | uniq -c > result.txt
1 casely
2 harley
1 linda
1 weekly
1. 显示文件example中不重复的行。
uniq - u example
2. 显示文件example中不重复的行,从第2个字段的第2个字符开始做比较。
uniq - u - 1 +1 example
testfile的内容如下
cat testfilehelloworldfriendhelloworldhello
直接删除未经排序的文件,将会发现没有任何行被删除
#uniq testfile helloworldfriendhelloworldhello
排序文件,默认是去重
#cat words | sort |uniqfriendhelloworld
排序之后删除了重复行,同时在行首位置输出该行重复的次数
#sort testfile | uniq -c1 friend3 hello2 world
仅显示存在重复的行,并在行首显示该行重复的次数
#sort testfile | uniq -dc3 hello2 world
仅显示不重复的行
sort testfile | uniq -ufriend
top
top - 12:38:33 up 50 days, 23:15, 7 users, load average: 60.58, 61.14, 61.22Tasks: 203 total, 60 running, 139 sleeping, 4 stopped, 0 zombie
Cpu(s) : 27.0%us, 73.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1939780k total, 1375280k used, 564500k free, 109680k buffers
Swap: 4401800k total, 497456k used, 3904344k free, 848712k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4338 oracle 25 0 627m 209m 207m R 0 11.0 297:14.76 oracle
4267 oracle 25 0 626m 144m 143m R 6 7.6 89:16.62 oracle
3458 oracle 25 0 672m 133m 124m R 0 7.1 1283:08 oracle
3478 oracle 25 0 672m 124m 115m R 0 6.6 1272:30 oracle
3395 oracle 25 0 672m 122m 113m R 0 6.5 1270:03 oracle
第一行同uptime命令运行结果,第二、三行为进程和CPU的信息,第四五行为内存信息
后面的行为进程信息:
列名 | 含义 |
PID | 进程id |
PPID | 父进程id |
RUSER | Real user name |
UID | 进程所有者的用户id |
USER | 进程所有者的用户名 |
GROUP | 进程所有者的组名 |
TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
PR | 优先级 |
NI | nice值。负值表示高优先级,正值表示低优先级 |
P | 最后使用的CPU,仅在多CPU环境下有意义 |
%CPU | 上次更新到现在的CPU时间占用百分比 |
TIME | 进程使用的CPU时间总计,单位秒 |
TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
%MEM | 进程使用的物理内存百分比 |
VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb。 |
RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
CODE | 可执行代码占用的物理内存大小,单位kb |
DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
SHR | 共享内存大小,单位kb |
nFLT | 页面错误次数 |
nDRT | 最后一次写入到现在,被修改过的页面数。 |
S | 进程状态。 |
COMMAND | 命令名/命令行 |
WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
Flags | 任务标志,参考 sched.h |
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
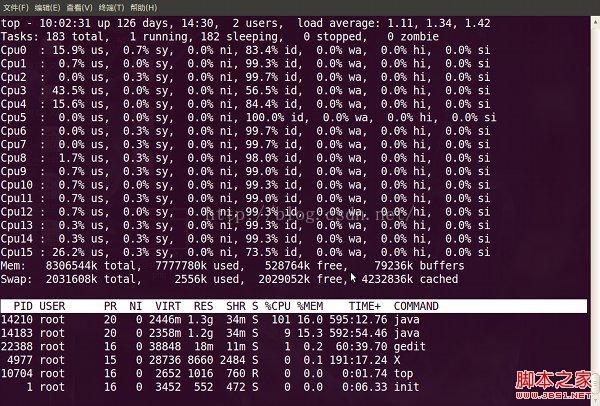
1. 敲击键盘“b”(打开/关闭加亮效果)
2. 敲击键盘“x”(打开/关闭排序列的加亮效果)
敲击“f”键,top进入另一个视图,在这里可以编排基本视图中的显示字段:
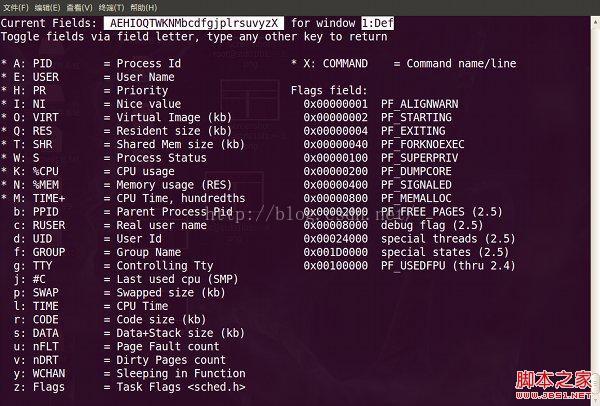
top视图 06
这里列出了所有可在top基本视图中显示的进程字段,有”*”并且标注为大写字母的字段是可显示的,没有”*”并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
查看进程的线程:top -p pid -H
uptime
9:42 up 1 day, 10:40, 2 users, load averages: 2.60 2.60 2.58
| 9:42 | 当前时间 |
| up 1 day | 系统运行时间,格式为时:分 |
| 2 users | 当前登录用户数 |
| load averages | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值 |
export
Linux export命令用于设置或显示环境变量。
export JAVA_HOME=$JAVA_7_HOME
export MYENV //定义环境亦量
export MYENV=7 //定义环境亦量并赋值
alias
功能说明:设置指令的别名。
语 法:alias[别名]=[指令名称]参 数 :若不加任何参数,则列出目前所有的别名设置。alias ll='ls -alF'
tail
同时tail多个文件
tail -f chat_error.log -f chat_biz.log -f chat_info.log
scp
scp是有Security的文件copy,基于ssh登录。操作起来比较方便,比如要把当前一个文件copy到远程另外一台主机上,可以如下命令。scp -rq /home/daisy/full.tar.gz root@172.19.2.75:/home/root然后会提示你输入另外那台172.19.2.75主机的root用户的登录密码,接着就开始copy了。如果想反过来操作,把文件从远程主机copy到当前系统,也很简单。scp -rqroot@/full.tar.gz 172.19.2.75:/home/root/full.tar.gz home/daisy/full.tar.gz
linux 的 scp 命令 可以 在 linux 之间复制 文件 和 目录;
netstat
netstat -tunlp | grep 进程号/端口号 显示进程和开启了哪些端口或端口被哪个进程占用
netstat -anp | grep 进程号 显示进程开启的连接
tcpdump
tcpdump -n -X -c 10 dst host 172.22.4.170 and port 3306 //查看和数据库之间的通信
-c 抓包个数
-e:输出的每行中都将包括数据链路层头部信息,例如源MAC和目标MAC。
-q:快速打印输出。即打印很少的协议相关信息,从而输出行都比较简短。
-X:输出包的头部数据,会以16进制和ASCII两种方式同时输出。
-XX:输出包的头部数据,会以16进制和ASCII两种方式同时输出,更详细。
-v:当分析和打印的时候,产生详细的输出。
-vv:产生比-v更详细的输出。
-vvv:产生比-vv更详细的输出。
pidstat
cpu监控
pidstat -p pid -u 1 3 //-u表示对cpu使用率的监控
pidstat -p pid -u -t 1 3 //-t线程级别的监控
io监控
pidstat -p pid -d -t 1 3 //-d 监控磁盘io
内存监控
pidstat -p pid -r 1 5















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









