







如何进行图像数据的预处理?
目录
1、TFRecord输入数据格式
来自实际问题中的数据往往很多格式和属性,而TFRecord能统一格式,有效的管理不同的属性。
TFRecord格式是TensorFlow所专属的。
1.1、TFRecord格式是什么?
TFRecord 文件中的数据都是通过 tf.train.Example协议内存块(Protocol Buffer)的格式存储的。
(这个是数据格式文件,不是python!)
message Example {
Features features = 1;
};
message Features {
map<string, Feature> feature = 1;
};
message Feature {
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
1.2、样例程序
(1)生成TFRecord文件
原理:将数据填入到 Example 协议内存块(protocol buffer),将协议内存块序列化为一个字符串, 并且通过tf.python_io.TFRecordWriter 写入到 TFRecords 文件。
以下代码将MNIST输入数据转换为TFRecord的格式(MNIST是一个数字识别数据集,深度学习入门案例)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 生成整数型的属性。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 生成字符串型的属性。
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
#输入路径
DATASET_PATH = 'datasets/MNIST_DATA'
mnist = input_data.read_data_sets(DATASET_PATH, dtype=tf.uint8, one_hot=True)
images = mnist.train.images
# 训练数据所对应的正确答案,可以作为一个属性保存在 TFRecord 中
labels = mnist.train.labels
# 训练数据的图像分辨率,这可以作为 Example 中的一个属性。
pixels = images.shape[1]
num_example = mnist.train.num_example
# 输出 TFRecord 文件的地址。
filename = '/home/jie/Jie/codes/tf/datasets/MNIST_DATA/output.tfrecords'
# 创建一个 writer 来写 TFRecord 文件。
writer = tf.python_io.TFRecordWriter(filename)
for index in range(num_example):
# 将图像矩阵转化成一个字符串。
image_raw = images[index].tostring()
# 将一个样例转化为 Example Protocol Buffer ,并将所有的信息写入这个数据结构。
example = tf.train.Example(features=tf.train.Features(features={
'pixels':_int64_feature(pixels),
'label':_int64_feature(np.argmax(labels[index])),
'image_raw':_bytes_features(images_raw)}))
# 将一个 Example 写入 TFRecord 文件。
writer.write(example.SerializeToString())
writer.close()
(2)读取TERecord文件
原理:使用tf.TFRecordReader的tf.parse_single_example解析器。这个操作可以将Example协议内存块(protocol buffer)解析为张量。
import tensorflow as tf
# TFRecord 文件的地址。
filename = 'datasets/MNIST_DATA/output.tfrecords'
# 创建一个 reader 来读取 TFRecord 文件中的样例。
reader = tf.TFRecordReader()
# tf.train.string_input_producer 创建一个队列来维护输入文件列表
filename_queue = tf.train.string_input_producer([filename])
# 从文件中读取一个样例。也可以使用 read_up_to 函数-次性读取多个样例。
_, serialized_example = reader.read(filename_queue)
# 解析读入的一个样例。若需要解析多个样例,可用parse_example函数
features = tf.parse_single_example(
serialized_example,
features={
# TensorFlow 提供两种不同的属性解析方法。
# 1. tf.FixedLenFeature,所解析的结果为一个 Tensor。
# 2. tf.VarLenFeature,所得到的解析结果为SparseTensor,用于处理稀疏数据。
# 这里解析数据的格式需要和上面程序可入数据的格式一致。
'image_raw':tf.FixedLenFeature([], tf.string),
'pixels':tf.FixedLenFeature([], tf.int64),
'label':tf.FixedLenFeature([], tf.int64),
})
# tf.decode_raw 可以将字符串解析成图像对应的像索数组。
image = tf.decode_raw(features['image_raw'], tf.uint8)
label = tf.cast(features['label'], tf.int32)
pixels = tf.cast(features['pixels'], tf.int32)
sess = tf.Session()
# 启动多线程处理输入数据
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 每次运行可以读取 TFRecord 文件中的一个样例。
# 当所有样例都读取完之后,在此样例中程序会再重头读取
for i in range(10):
print(sess.run([image, label, pixels]))
2、图像数据预处理
预处理的目的:弱化与图像识别无关的因素。
2.1、图像预处理函数
(1)图像编码/解码处理
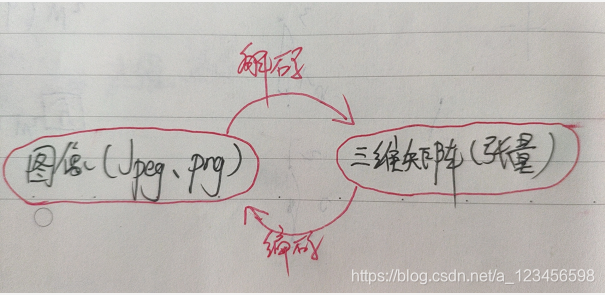
什么是编码/解码处理?
看手绘图:
样例代码:
# -*-coding:utf-8-*-
import tensorflow as tf
import matplotlib.pyplot as plt
IMAGES_PATH = 'xzx/6987985.jpeg'
SAVE_PATH = 'xzx/output.jpeg'
# 读取图像的原始数据。
image_raw_data = tf.gfile.FastGFile(IMAGES_PATH, 'rb').read()
with tf.Session() as sess:
# 对图像进行 jpeg 的格式解码从而得到图像对应的三维矩阵。
# tf.image.decode_png 函数对 png 格式的图像进行解码。
# 解码之后的结果为一个张量,在使用它的取值之前需要明确调用运行的过程。
img_data = tf.image.decode_jpeg(image_raw_data)
print(img_data.eval())
# 输出解码之后的三维矩阵,上面这一行代码将输出以下内容。
# 使用 pyplot 工具可视化得到的图像。
plt.imshow(img_data.eval())
plt.show()
# 将表示一张图像的三维矩阵重新按照jpeg格式编码并存入文件中。
# 打开该图像,与原始图像一样
encoded_image = tf.image.encode_jpeg(img_data)
with tf.gfile.GFile(SAVE_PATH, "wb") as f:
f.write(encoded_image.eval())
(2)图像大小调整
resized = tf.image.resize_images(img_data, [300, 300], method=0)
method0,1,2,3代表不同的调整大小方法,不做详解。
# 略去加载原始图像,定义会话等过程,假设:img_data是已经解码的图像。
# 1. 首先将图片数据转换为实数类型,即将0-255转化为0.0-1.0范围内的实数。
# 大多数图像处理 API 支持整数和实数类型的输入。
# 如果输入是整数类型,这些 API 会在内部将输入转化为实数后处理,再将输出转化为整数。
# 如果有多个处理步骤,在格数和实数之间的反复转化将导致精度损失,
# 因此推荐在图像处理前将其转化为实数类型。
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
# 通过 tf.image.resize_images 函数调整图像的大小。
# 第一个参数: 原始图像
# 第二个和第三个参数为调整后图像的大小
# method 参数给出了调整图像大小的算法
resized = tf.image.resize_images(img_data, [300, 300], method=0)
plt.imshow(resized.eval())
plt.show()
(3)图像翻转
翻转的意义?
必须采取随机的翻转,让相片的角度对识别不产生影响。(比如不管猫头向左还是向右,都得识别出来)
随机翻转代码:
# 以 50% 概率上下翻转图像
flipped1 = tf.image.random_flip_up_down(img_data)
# 以 50% 概率左右翻转图像
flipped2 = tf.image.random_flip_left_right(img_data)
(4)图像色彩调整
目的:
与图像翻转一样,图片的亮度、对比度、饱和度和色相都不应该对识别产生影响,所以也应该随机改变这些属性。
a、调整亮度
# 将图像的亮度 -0.5
adjusted1 = tf.image.adjust_brightness(img_data, -0.5)
# 截断在 0.0-1.0 范围区间
adjusted1 = tf.clip_by_value(adjusted1, 0.0, 1.0)
# 将图像的亮度 +0.5
adjusted2 = tf.image.adjust_brightness(img_data, 0.5)
# 在[-max_delta, max_delta)的范围随机调整图像的亮度。
max_delta = 0.9
adjusted3 = tf.image.random_brightness(img_data, max_delta)
b、调整对比度
# 将图像的饱和度-5
adjusted1 = tf.image.adjust_saturation(img_data, -5)
# 将图像的饱和度+5
adjusted2 = tf.image.adjust_saturation(img_data, 5)
# 在[lower, upper] 的范围随机调整图像的饱和度
lower = 10
upper = 100
adjusted3 = tf.image.random_saturation(img_data, lower, upper)
c、调整色相
# 分别将色相加 0.1、0.3、0.6 和 0.9
adjusted1 = tf.image.adjust_hue(img_data, 0.1)
adjusted2 = tf.image.adjust_hue(img_data, 0.3)
adjusted3 = tf.image.adjust_hue(img_data, 0.6)
adjusted4 = tf.image.adjust_hue(img_data, 0.9)
# 在 [-max_delta, max_delta] 的范围随机调整图像的色相。
max_delta = 0.5
adjusted5 = tf.image.random_hue(img_data, max_delta)
d、调整饱和度
# 将图像的饱和度-5
adjusted1 = tf.image.adjust_saturation(img_data, -5)
# 将图像的饱和度+5
adjusted2 = tf.image.adjust_saturation(img_data, 5)
# 在[lower, upper] 的范围随机调整图像的饱和度
lower = 10
upper = 100
adjusted3 = tf.image.random_saturation(img_data, lower, upper)
e、图像标准化
adjusted = tf.image.per_image_standardization(img_data)
(5)处理标注框
加入标注框:
tf.image.draw_bounding_boxes()函数在图像中添加标注框。输入图像矩阵的数字为实数,且是一个 batch 的数据(四维张量)。所以,绘制图时,需要tf.reduce_sum()函数进行降维。
# 将图像缩小一些,这样可视化能让标注框更加清楚。
img_data = tf.image.resize_images(img_data, [180, 267], method=1)
# tf.image.draw_bounding_boxes 函数要求图像矩阵中的数字为实数.
# -> 先将图像矩阵转化为实数类型。
# 输入是一个 bacth 的数据(多张图像组成的四维矩阵),要将解码之后的图像矩阵添加一维
bacthed = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0)
# 给出每一张图像的所有标注框。一个标注框有 4 个数字,分别代表[Y_min, X_min, Y_max, X_max]
# 注意这里给出的数字都是图像的相对位置。
# 比如在 180 × 267 的图像中,[0.35, 0.47, 0.5, 0.56]代表了从(63,125)到(90, 150)的图像。
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
result = tf.image.draw_bounding_boxes(bacthed, boxes)
result = tf.reduce_sum(result, 0) # 这里显示的时候需要进行降维处理
plt.imshow(result.eval())
plt.show()
随机截取图像:
随机截取图像上有信息含量的部分也是一个提
高模型健壮性( robustness )的一种方式。
==》使得训练模型不受被识别物体大小的影响。
==》tf.image.sample_distorted_bounding_box()函数
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
# min_object_covered=0.4 表示截取部分至少包含某个标注框 40% 的内容。
begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(
tf.shape(img_data), bounding_boxes = boxes,
min_object_covered=0.4)
# 通过标注框可视化随机截取得到的图像。
bacthed = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0)
image_with_box = tf.image.draw_bounding_boxes(bacthed, bbox_for_draw)
# 截取随机出来的图像。每次结果可能不尽相同.
distored_image = tf.slice(img_data, begin, size)
2.2、预处理完整样例代码
输入:原始训练图像
输出:神经网络的输入层
# -*-coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 给定一张图像,随机调整图像的色彩。
# 因为调整亮度、对比度、饱和度和色相的顺序会影响最后的结果,所以定义多种不同的顺序。
# 具体顺序可在预处理时随机选取一种。从而降低无关因素对模型的影响。
# 亮度(brightness) 对比度(contrast)、饱和度(saturation)和色相(hue)
def distort_color(image, color_ordering=0):
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32./255.) #
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
elif color_ordering == 1:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
elif color_ordering == 2:
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
# 截断在 0.0-1.0 范围区间
return tf.clip_by_value(image, 0.0, 1.0)
# 给定一张解码后的图像、目标图像的尺寸以及图像上的标注框,
# 此函数可对给出的图像进行预处理
# 输入:原始训练图像
# 输出:神经网络的输入层
def preprocess_for_train(image, height, width, bbox):
# 如果没有提供标注框,则认为整个图像就是需要关注的部分。
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32,
shape=[1, 1, 4])
# 转换图像张量的类型 。
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 随机截取图像,减小需要关注的物体大小对图像识别算法的影响。
bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box(
tf.shape(image), bounding_boxes=bbox)
distorted_image = tf.slice(image, bbox_begin, bbox_size)
# 将随机截取的图像调整为神经网络输入层的大小。大小调整的算法是随机选摔的 。
distorted_image = tf.image.resize_images(
distorted_image, [height, width], method=np.random.randint(4))
# 随机左右翻转图像。
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 使用一种随机的顺序调整图像色彩。
distorted_image = distort_color(distorted_image, np.random.randint(3))
return distorted_image
IMAGE_PATH = '/home/jie/Desktop/6987985.jpeg'
image_raw_data = tf.gfile.FastGFile(IMAGE_PATH, "rb").read()
with tf.Session() as sess:
img_data = tf.image.decode_jpeg(image_raw_data)
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]])
for i in range(6):
result = preprocess_for_train(img_data, 299, 299, boxes)
plt.imshow(result.eval())
plt.show()
3、多线程输入数据处理框架
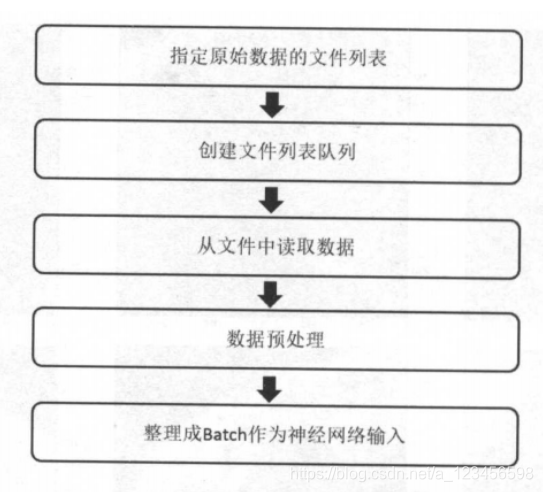
复杂的预处理会减慢神经模型训练的效率,所以采用多线程的方式来加速,TensorFlow提供了一套处理数据输入的框架。
框架的输入流程:
3.1、队列与多线程
队列与多线程有什么关系?
队列--吃了拉,先进先出的数据结构。
队列是用来储存数据的,而线程是来操作队列的。当有多个线程时,称之为多线程。
(1)队列
FIFOQueue:先进先出队列。
RandomShuffleQueue:将队列中的元素打乱,每次出队列操作得到的是从当前队列所有元素中随机选择的一个。(训练网络时希望每次使用的训练数据尽可能随机,推荐使用)
import tensorflow as tf
# 创建一个先进先出队列,指定队列中最多可以保存两个元素,并指定类型为整数。
q = tf.FIFOQueue(2, "int32")
# enqueue_many 函数:初始化队列中的元素,需要明确的调用这个初始化过程。
init = q.enqueue_many(([0, 10],))
# Dequeue 函数:队列中的第一个元素出队列,并存入x中
x = q.dequeue()
y = x + 1
# 将y重新加入队列。
q_inc = q.enqueue([y])
with tf.Session() as sess:
# 运行初始化队列的操作。
init.run()
for _ in range(5):
# 运行q_inc将执行数据出队列、出队的元素+1、重新归入队列的整个过程。
v, _ = sess.run([x, q_inc])
print(v)
(2)多线程协同方法:
a、tf.Coordinator类:用于协同多个线程一起停止, 并提供了 should_stop、request_stop 和 join 三个函数。
# 线程中运行的程序,这个程序每隔1秒判断是否需要停止并打印向己的ID 。
def MyLoop(coord, worker_id):
# 使用 tf.Coordinator 类提供的协同工具判断当前线程是否要停止。
while not coord.should_stop():
# 随机停止所有的线程。
if np.random.rand() < 0.1:
print("Stoping from id: %d\n" % worker_id)
# 调用 coord.request_stop() 函数来通知其他线程停止。
coord.request_stop()
else:
# 打印当前线程的Id。
print("Working on id: %d\n" % worker_id)
time.sleep(1)
# 声明一个 tf.train.Coordinator 类来协同多个线程。
coord = tf.train.Coordinator()
# 声明创建 5 个线程
threads = [threading.Thread(target=MyLoop, args=(coord, i)) for i in range(5)]
# 启动所有线程
for t in threads:
t.start()
# 等待所有线程退出
coord.join(threads)
b、tf.QueueRunner 类
# 声明一个先进先出的队列,队列中最多100个元素,类型是实数
queue = tf.FIFOQueue(100, "float")
# 定义队列的入队操作
enqueue_op = queue.enqueue([tf.random_normal([1])])
# 使用 tf.train.QueueRunner 创建多个线程运行队列的入队操作。
# 第1个参数:被操作的队列,
# [enqueue_op]*5 需要启动5个线程,每个线程中运行的是 enqueue_op 操作。
qr = tf.train.QueueRunner(queue, [enqueue_op] * 5)
# 将定义过的QueueRunner加入TensorFlow 计算图上指定的集合。
# tf.train.add_queue_runner 函数没有指定集合,则加入默认集合 tf.GraphKeys.QUEUE_RUNNERS。
# 下面的函数就是将刚刚定义的 qr 加入默认的 tf.GraphKeys.QUEUE_RUNNERS 集合。
tf.train.add_queue_runner(qr)
# 定义出队操作。
out_tensor = queue.dequeue()
with tf.Session() as sess:
# 使用 tf.train.Coordinator 来协同启动的线程。
coord = tf.train.Coordinator()
# 使用tf.train.QueueRunner时,需要明确调用tf.train.start_queue_runners来启动所有线程。
# 否则因为没有线程运行入队操作,当调用出队操作时,程序会一直等待入队操作被运行。
# tf.train.start_queue_runners 函数会默认启动tf.GraphKeys.QUEUE_RUNNERS集合中所有的QueueRunner。
# 这个函数只支持启动指定集合中的 QueueRnner,
# 所以一般来说 tf.train.add_queue_runner 函数和tf.train.start_queue_runners函数会指定同一个集合。
threads = tf.train.start_queue_runners(sess = sess, coord=coord)
# 获取队列中的取值。
for _ in range(3):
print(sess.run(out_tensor)[0])
# 使用 tf.train.Coordinator 来停止所有的线程。
coord.request_stop()
coord.join(threads)
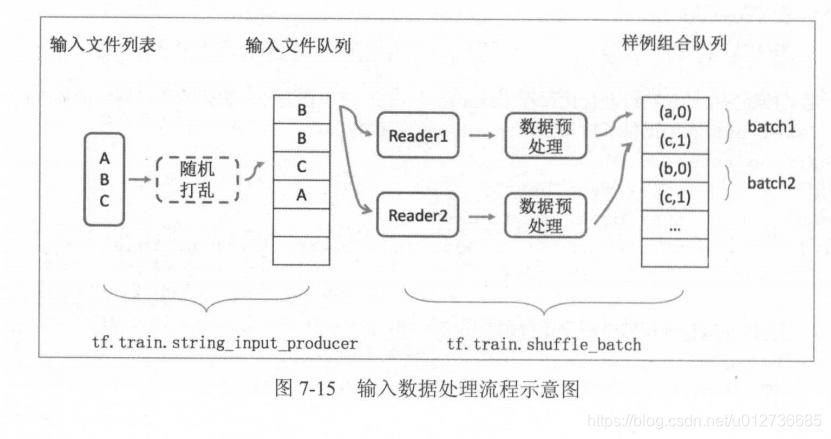
3.2、输入文件队列
输入队列的就是TensorFlow的数据格式TFRecord。
虽然一个TFRecord文件可以存储多个训练样本,但当训练数据量较大时,可以将数据分成多个TFRecord文件来提高处理效率。
(1)获取一个正则表达式的所有文件: tf.train.match_filenames_once
(2)进行有效的管理:tf.train.string_input_producer
生成样例:
# 创建 TFRecord 文件的帮助函数。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 模拟海量数据情况下将数据写入不同文件
# num_shards : 总共写入多少个文件,
# instances_per_shard : 每个文件中有多少个数据。
num_shards = 2
instances_per_shard = 2
for i in range(num_shards):
# 将数据分为多个文件时,可以将不同文件以类似 OOOOn-of-OOOOm 的后缀区分。
# m:表示数据总共被存在了多少个文件中
# n:表示当前文件的编号
# 式样的方式既方便了通过正则表达式获取文件列表,又在文件名中加入了更多的信息
filename = ('./datasets/data.tfrecords-%.5d-of-%.5d' % (i, num_shards))
writer = tf.python_io.TFRecordWriter(filename)
# 将数据封装成 Example 结构并写入 TFRecord 文件 。
for j in range(instances_per_shard):
# Example 结构仅包含当前样例属于第几个文件以及是当前文件的第几个样本。
example = tf.train.Example(features=tf.train.Features(feature={
'i':_int64_feature(i),
'j':_int64_feature(j)}))
writer.write(example.SerializeToString())
writer.close()

生成样例之后,以下代码展示了两个函数的使用方法:
# 使用 tf.train.match_filenames_once 函数获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 通过 tf.train.string_input_producer 函数创建输入队列.
# 输入队列巾的中的文件列表为tf.train.string_input_producer函数获取的文件列表。
# 参数设置:shuffle为False,在一般解决真实问题时,shuffle设置为True
filename_queue = tf.train.string_input_producer(files, shuffle=False)
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'i':tf.FixedLenFeature([], tf.int64),
'j':tf.FixedLenFeature([], tf.int64),
})
with tf.Session() as sess:
# 虽然在本段程序中没有声明任何变量,
# 但使用 tf.train.match_filenames_once 函数时前要初始化一些变量 。
tf.local_variables_initializer().run()
print(sess.run(files))
# 声明 tf.train.Coordinator 类来协同不同线程,并启动线程。
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 多次执行技取数据的操作。
for i in range(6):
print(sess.run([features['i'], features['j']]))
coord.request_stop()3.3、组合训练数据(batching)
此处的batching和反向传播的batch的区别?
是同一个batch,取的batch先通过图像预处理,然后通过前向传播算法算出loss,然后通过反向传播算法来优化。
两个生成batch的函数:
tf.train.batch 和 tf.train.shuffle_batch 函数来将单个的样例组织成 batch 的形式输出。这两个函数都会生成一个队列,队列的入队操作是生成单个样例的方法,而每次出队得到的是一个 batch 的样例 。
唯一区别:是否会将数据顺序打乱 。tf.train.shuffle_batch 为乱序。
(1)tf.train.batch
import tensorflow as tf
# 使用 tf.train.match_filenames_once 函数获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 通过 tf.train.string_input_producer 函数创建输入队列.
# 输入队列巾的中的文件列表为tf.train.string_input_producer函数获取的文件列表。
# 参数设置:shuffle为False,在一般解决真实问题时,shuffle设置为True
filename_queue = tf.train.string_input_producer(files, shuffle=False)
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'i':tf.FixedLenFeature([], tf.int64),
'j':tf.FixedLenFeature([], tf.int64),
})
# 使用上面样例。这里假设 Example 结构中 i 表示一个样例的特征向量,
# 比如一张图像的像索矩阵。而 j 表示该样例对应的标签 。
example, label = features['i'], features['j']
# 一个 batch 中样例的个数。
batch_size = 3
# 文件队列中最多可以存储的样例个数
capacity = 1000 + 3 * batch_size
# 使用 tf.train.batch 函数来组合样例。[example, label]参数给出需组合的元素.
# 当队列长度等于容量时,TF将暂停入队操作,而只是等待元索出队。
# 当元素个数小于容量时, TF将自动重新启动入队操作。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=batch_size, capacity=capacity)
tf.local_variables_initializer().run()
with tf.Session() as sess:
# tf.initialize_all_variables().run()
tf.local_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 获取并打印组合之后的样例。在真实问题中,这个输出一般会作为神经网络的输入。
for i in range(2):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
print(cur_example_batch, cur_label_batch)
coord.request_stop()
coord.join(threads)(2)tf.train.shuffle_batch
import tensorflow as tf
# 获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 创建文件输入队列
filename_queue = tf.train.string_input_producer(files, shuffle=False)
# 读取并解析Example
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'i':tf.FixedLenFeature([], tf.int64),
'j':tf.FixedLenFeature([], tf.int64),
})
# i代表特征向量,j代表标签
example, label = features['i'], features['j']
# 一个 batch 中样例的个数。
batch_size = 3
# 文件队列中最多可以存储的样例个数
capacity = 1000 + 3 * batch_size
# 组合样例。
# `min_after_dequeue` 是该函数特有的参数,参数限制了出队时队列中元素的最少个数,
# 但当队列元素个数太少时,随机的意义就不大了
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size,
capacity=capacity, min_after_dequeue=30)
with tf.Session() as sess:
# 使用match_filenames_once需要用local_variables_initializer初始化一些变量
tf.local_variables_initializer().run()
# 用Coordinator协同线程,并启动线程
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 获取并打印组合之后的样例。在真实问题中,这个输出一般会作为神经网络的输入。
for i in range(2):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
print(cur_example_batch, cur_label_batch)
coord.request_stop()
coord.join(threads)3.4、输入数据处理框架
这一节把前面的所有整合到一起,组成完整的tensorflow图像预处理框架。主要是三步:
(1)将图片格式变为TFRecord格式
(2)需要的话开辟多线程
(3)一系列的图像预处理(解码、翻转、大小、处理标注框等等)
import tensorflow as tf
# 获取文件列表。
files = tf.train.match_filenames_once('./datasets/data.tfrecords-*')
# 创建文件输入队列
filename_queue = tf.train.string_input_producer(files, shuffle=False)
# 读取并解析Example
reader = tf.TFRecordReader()
_, seraialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
seraialized_example,
features={
'image':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([], tf.int64),
'height':tf.FixedLenFeature([], tf.int64),
'width':tf.FixedLenFeature([], tf.int64),
'channels':tf.FixedLenFeature([], tf.int64),
})
image, label = features['image'], features['label']
height, width = features['height'], features['width']
channels = features['channels']
# 从原始图像数据解析出像素矩阵,并根据图像尺寸还原图像。
decoded_image = tf.decoded_raw(image, tf.int8)
decoded_image.set_shape([height, width, channels])
# 定义神经网络输入层图片的大小。
image_size = 299
# 图像预处理
distorted_image = preprocess_for_train(decoded_image, image_size, image_size, None)
# 将处理后的图像和标续数据通过 tf.train.shuffle_batch 整理成神经网络训练时需要的 batch,
min_after_dequeue = 10000
batch_size = 100
capacity = min_after_dequeue + 3 * batch_size
# 组合样例。
# `min_after_dequeue` 是该函数特有的参数,参数限制了出队时队列中元素的最少个数,
# 但当队列元素个数太少时,随机的意义就不大了
image_batch, label_batch = tf.train.shuffle_batch(
[distorted_image, label], batch_size=batch_size,
capacity=capacity, min_after_dequeue=min_after_dequeue)
# 定义神经网络的结构以及优化过程
learing_rate = 0.01
logit = inferenece(image_batch)
loss = calc_loss(logit, label_batch)
train_step = tf.train.GradientDescentOptimizer(learing_rate).minimize(loss)
with tf.Session() as sess:
# 使用match_filenames_once需要用local_variables_initializer初始化一些变量
sess.run((tf.global_variables_initializer(), tf.local_variables_initializer()))
# 用Coordinator协同线程,并启动线程
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 神经网络训练过程
TRAINING_ROUNDS = 5000
for i in range(TRAINING_ROUNDS):
sess.run(train_step)
coord.request_stop()
coord.join(threads)4、数据集API(Dataset)
TF核心组件:tf.data。
这是一个数据集的API,可以使数据的输入和处理大大简化。(一种新的方式,和3.4节并列)
使用数据集的方式实现3.4节的代码功能:
import tensorflow as tf
import tempfile
# 1. 列举输入文件
TRAIN_PATH = 'output.tfrecords'
TEST_PATH = 'output_test.tfrecords'
train_files = tf.train.match_filenames_once(TRAIN_PATH)
test_files = tf.train.match_filenames_once(TEST_PATH)
# 2. 定义parser方法TFRecord中解析数据
# 解析一个TFRecord的方法。
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw':tf.FixedLenFeature([],tf.string),
'pixels':tf.FixedLenFeature([],tf.int64),
'label':tf.FixedLenFeature([],tf.int64)
})
decoded_images = tf.decode_raw(features['image_raw'],tf.uint8)
retyped_images = tf.cast(decoded_images, tf.float32)
images = tf.reshape(retyped_images, [784])
labels = tf.cast(features['label'],tf.int32)
#pixels = tf.cast(features['pixels'],tf.int32)
return images, labels
image = 299 # 定义神经网络输入层图片的大小
batch_size = 100 # 定义组合数据 batch 的大小
shuffle_buffer = 10000 # 定义随机打乱数据时buffer大小
# 定义读取训练集和测试集
dataset = tf.data.TFRecordDataset(train_files)
dataset = dataset.map(parser)
# 对数据依次进行预处理、shuffle、batching操作
# dataset = dataset.map(
# lambda image, label: (
# preprocess_for_train(image, image_size, image_size, None), label))
dataset = dataset.shuffle(shuffle_buffer).batch(batch_size)
# 重复NUM_EPOCHS 个epoch
NUM_EPOCHS = 10
dataset = dataset.repeat(NUM_EPOCHS)
# 定义数据集迭代器。
iterator = dataset.make_initializable_iterator()
image_batch, label_batch = iterator.get_next()
# 4. 定义神经网络结构和优化过程
def inference(input_tensor, weights1, biases1, weights2, biases2):
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
REGULARAZTION_RATE = 0.0001
TRAINING_STEP = 5000
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y = inference(image_batch, weights1, biases1, weights2, biases2)
# 计算交叉熵及其平均值
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=label_batch)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 损失函数的计算
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
regularaztion = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularaztion
# 优化损失函数
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 5. 定义测试用数据集
# 定义测试用的Dataset。
test_dataset = tf.data.TFRecordDataset(test_files)
test_dataset = test_dataset.map(parser)
test_dataset = test_dataset.batch(batch_size)
# 定义测试数据上的迭代器
test_iterator = test_dataset.make_initializable_iterator()
test_image_batch, test_label_batch = test_iterator.get_next()
# 定义测试数据上的预测结果
test_logit = inference(test_image_batch, weights1, biases1, weights2, biases2)
predictions = tf.argmax(test_logit, axis=-1, output_type=tf.int32)
# 声明会话并运行神经网络的优化过程。
with tf.Session() as sess:
# 初始化变量。
sess.run((tf.global_variables_initializer(),
tf.local_variables_initializer()))
# 初始化训练数据的迭代器。
sess.run(iterator.initializer)
# 循环进行训练,直到数据集完成输入、抛出OutOfRangeError错误。
while True:
try:
sess.run(train_step)
except tf.errors.OutOfRangeError as e:
break
# 初始化测试数据的迭代器。
test_results = []
test_labels = []
sess.run(test_iterator.initializer)
while True:
try:
pred, label = sess.run([predictions, test_label_batch])
test_results.extend(pred)
test_labels.extend(label)
except tf.errors.OutOfRangeError as e:
break
# 计算准确率
correct = [float(y==y_) for (y, y_) in zip(test_results, test_labels)]
accuarcy = sum(correct)/len(correct)
print("Test accuarcy is: ", accuarcy)














 2974
2974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









