







本博客中的ppt参考自七月在线的机器学习系列课程。
文章目录
是什么

为什么
信息过载,需要过滤。
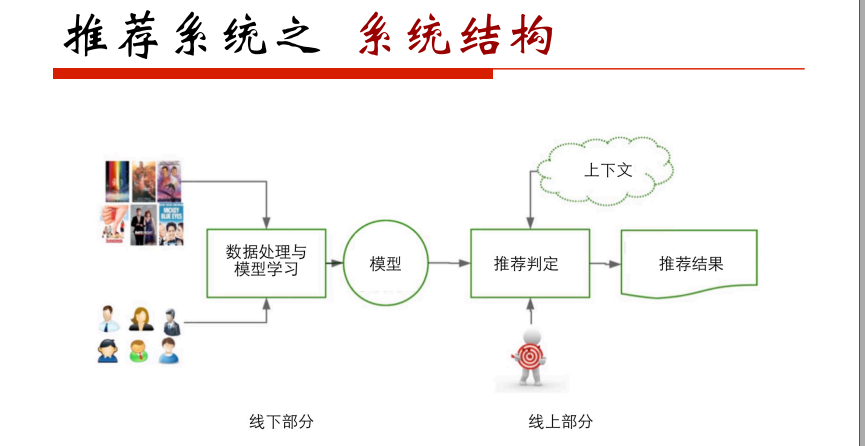
系统结构
评定标准

分母的T是所有的测试样本集,



推荐算法初步
https://www.cnblogs.com/baihuaxiu/p/6617389.html
基于内容的推荐
基于内容的推荐算法,原理是基于用户喜欢的item的属性/内容进行推荐,比如你看了哈利波特I,基于内容的推荐算法发现哈利波特II-VI,与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你,这种方法可以避免Item的冷启动问题(冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是基于内容的推荐算法可以分析Item之间的关系,实现推荐),弊端在于推荐的Item可能会重复,典型的就是新闻推荐,如果你看了一则关于MH370的新闻,很可能推荐的新闻和你浏览过的,内容一致;另外一个弊端则是对于一些多媒体的推荐(比如音乐、电影、图片等)由于很难提内容特征,则很难进行推荐,一种解决方式则是人工给这些Item打标签。
TF-IDF算法(参考)
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
https://blog.csdn.net/qq_32690999/article/details/77434381
协同过滤推荐算法(CF)
协同过滤算法分两种:
1. 基于用户的协同过滤算法(user-based collaboratIve filtering),
原理是基于用户对物品的偏好找到相邻邻居用户, 找到他们看/买过但当前用户没看/买过的item, 根据距离加权打分, 找得分最高的推荐(将当前用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 )
2. 基于Item的协同过滤算法(item-based collaborative filtering),
根据用户对商品/内容的偏好,计算item和item相似度, 找到和当前item最近的进行推荐。(基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。)
这两种方法都是将用户的所有数据读入到内存中进行运算的,因此成为Memory-based Collaborative Filtering,另一种则是Model-based collaborative filtering,包括Aspect Model,pLSA,LDA,聚类,SVD,Matrix Factorization等,这种方法训练过程比较长,但是训练完成后,推荐过程比较快。
协同过滤的实现步骤:
- 收集数据(用户的历史行为数据)
- 找到相似用户和物品
- 进行推荐
协同过滤算法总结


推荐系统之冷启动问题
https://www.jianshu.com/p/97e46f933010
https://blog.csdn.net/javaisnotgood/article/details/79487372
有哪些解决推荐系统中冷启动的思路和方法? https://www.zhihu.com/question/19843390/answer/37456028
推荐算法进阶
隐语义模型

隐语义模型
- 最简单的办法是直接矩阵分解
- CF简单直接可解释性强, 但隐语义模型能更好地挖掘用户和item关联中的隐藏因子














 83
83











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









