







| 视觉探测任务 |
一、初始探测任务

1.1、silding windows & IoU
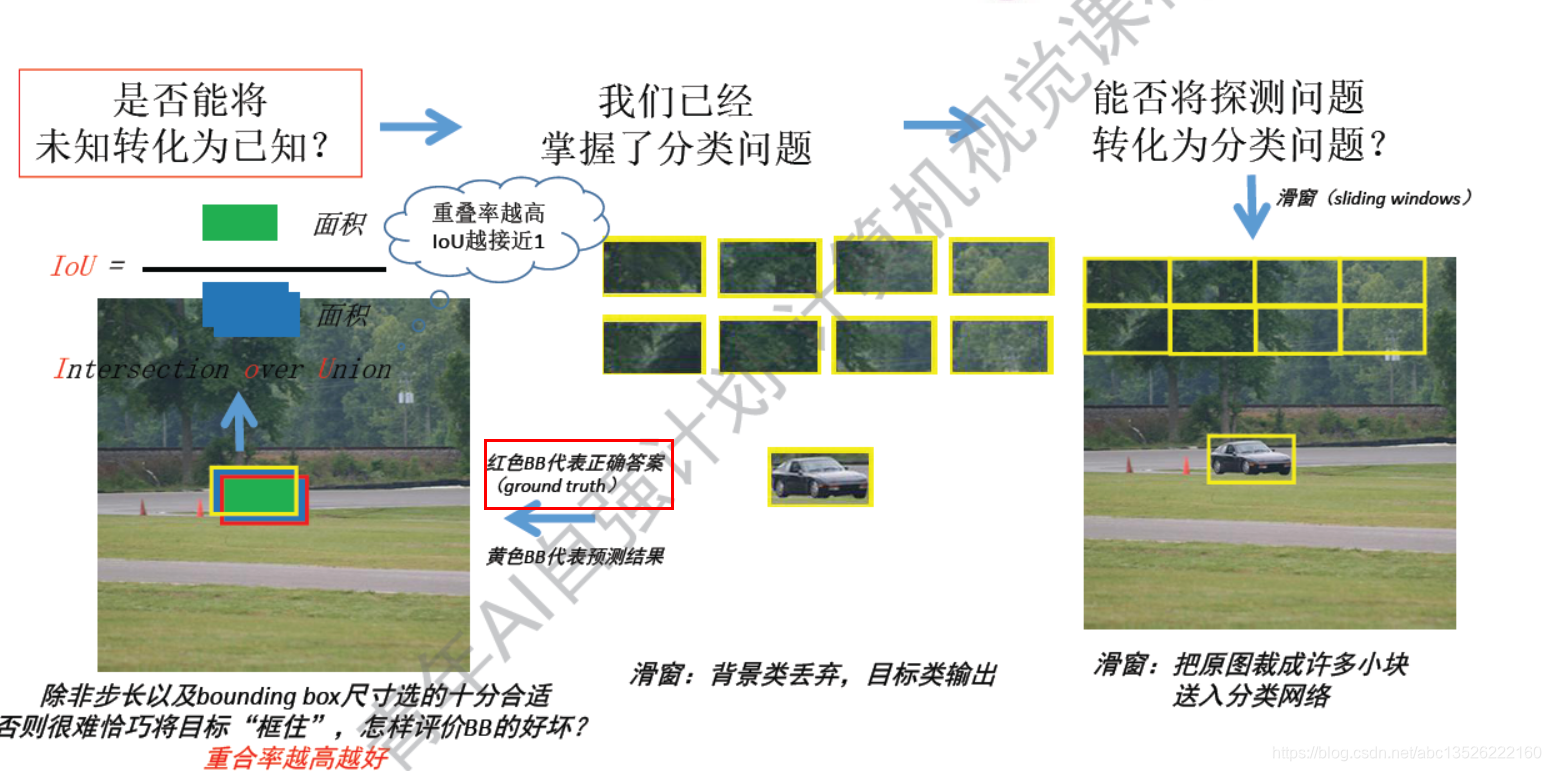
注意: 能否将探测任务转换成分类问题,silding windows(滑窗) & IoU(交并比,交叠率,重合率)
- 就是交集比并集,比值越大越好。
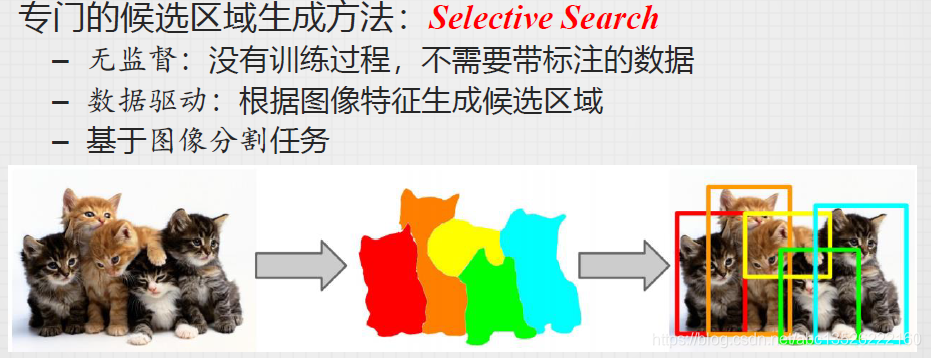
1.2、Region Proposal

注意: 这么多候选框中如何挑选出想要的呢?这里用的非极大值抑制(除了最大的都不要)
- 首先把所有的候选框送入分类器中,所有的框框都会得到一个概率。但是是逐一类别进行分类的。
也就是这2000个框子,首先去查一下是不是车,然后在送去查看是不是人。
来看看是不是车:如果把它们送入汽车的分类器,能得到每个框框的概率,图中标记出来了。- 1、第一步就是设定一个阈值,小于某个概率的我们都不要,像这些0.1,0.2等等指的是是车的概率这些都不要;
- 2、踢掉了一部分之后,图像看起来清爽很多了。但是交叠在一起的候选框如何选择呢?图中中间的图片。按照除了最大的都不要:首先挑选出一个概率最大的0.9,然后跟它交叠率大于一定阈值的都丢弃(这里设置的超参数是0.7),简单的说就是:概率最大框周围的都不要。然后往复进行下去挑选出一个0.8,跟它交叠率大于某一个阈值的的不要,所以留下了想要的。
- 送入人分类器:把这些框框都喂进去和刚才一样,先是小于某一个阈值的都不要,然后大于某一个阈值的都不要
- 看下图:
1.3、Non-Max Suppression (NMS)非极大值抑制

注意: 首先所有选出来的框框送进去分类器,所有款款都会得到一个概率。但是逐一类别分类,先送去汽车分类器是不是汽车。再送去查看是不是人。
- 先送去汽车分类器,会得到一个概率,途中左下角标记的有。
- 第一步设置一个阈值,比如小于0.5的都不要,是车的概率非常小,可以踢掉了,去掉之后,框框少了很多了。但是交叠在一起的几个候选框怎么选择呢?除了最大的都不要。这里图中间最大的是0.9,然后跟它交叠率大于一定阈值的都丢弃(这里设置的超参数是0.7)简单说的就是最大框框周围的都不要!
- 之后再按照刚刚的规则往复现在最大的0.8,处理完一个类别之后,再处理下一个类别,现在该处理人这个类了,一样的过程,先送去探测器分类,得到一个概率,小于某一个阈值的都不要,再选出一个概率最大,与其交叠率大于某一阈值的都不要,往复进行!
二、探测任务-网络发展概览
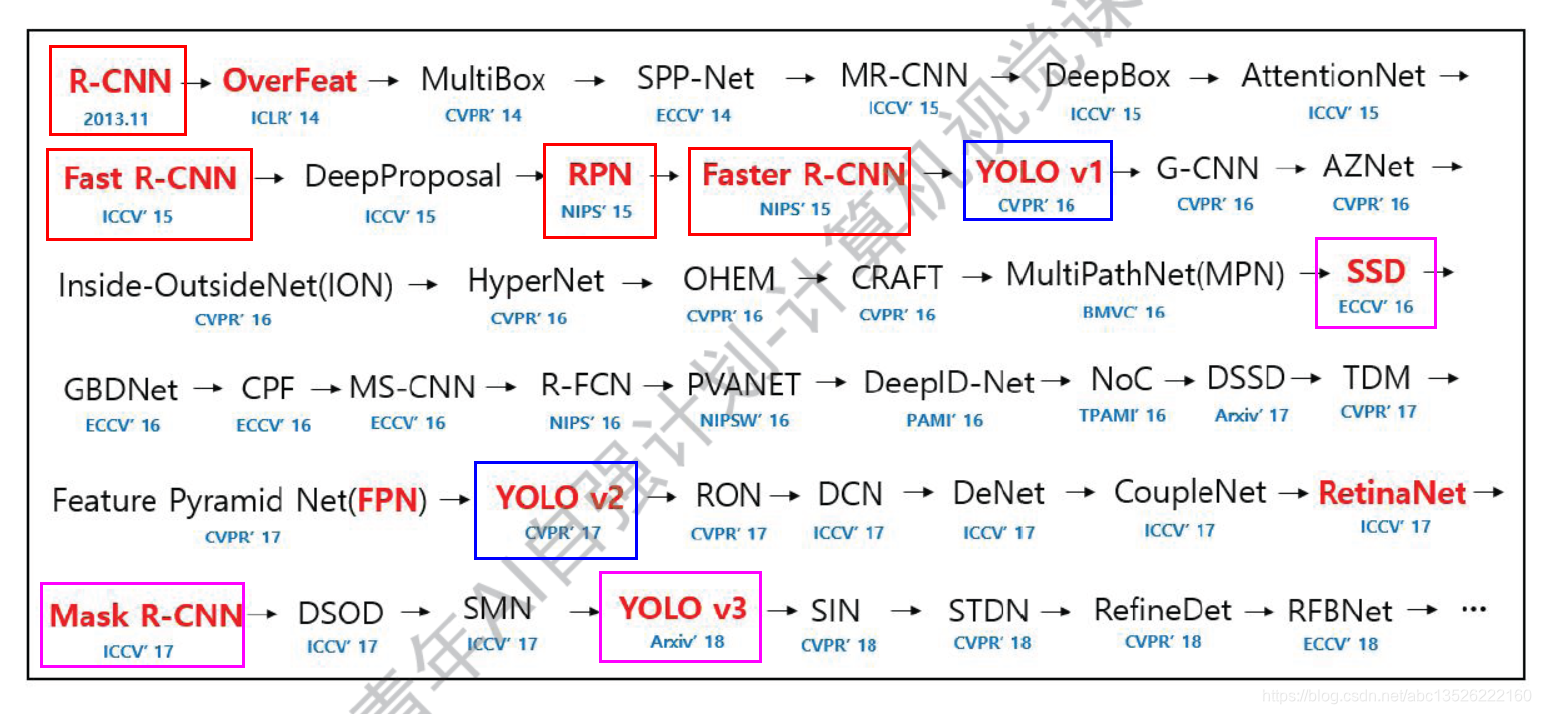
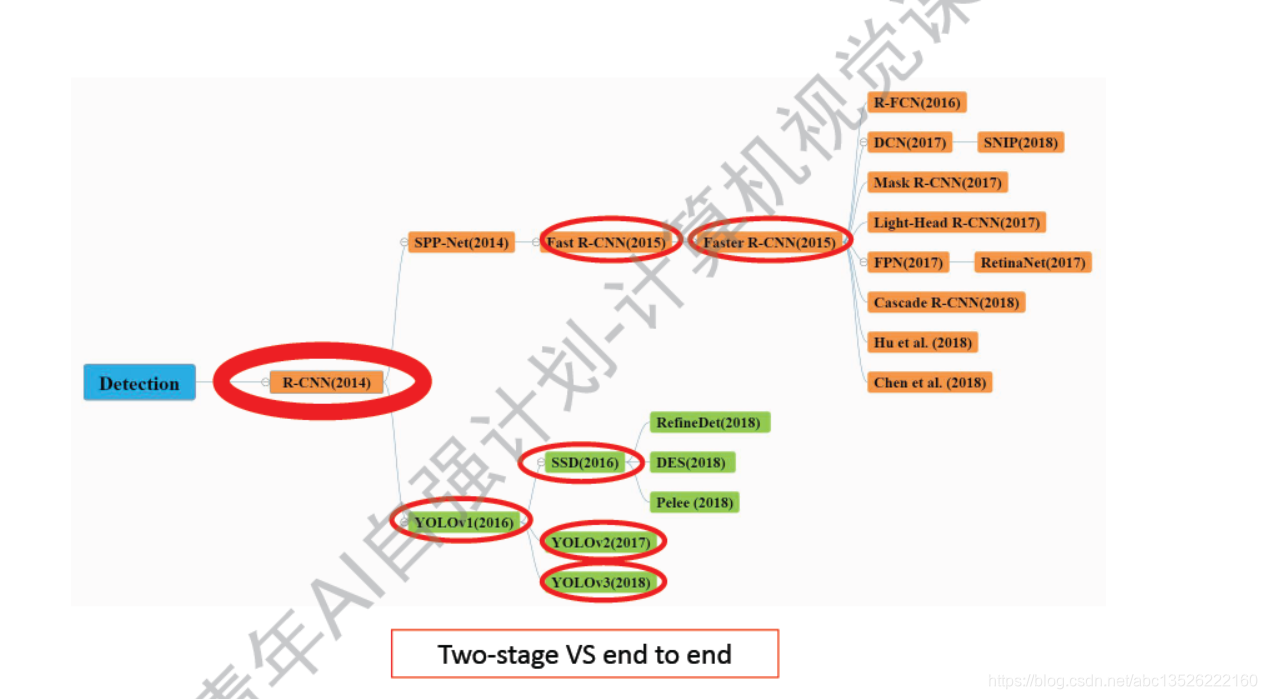
注意: 这里只是一些知名度比较高的网络。R-CNN可以看做开山之作,Faster-RCNN升级版本。
2.1、PASCAL VOC 数据集简介
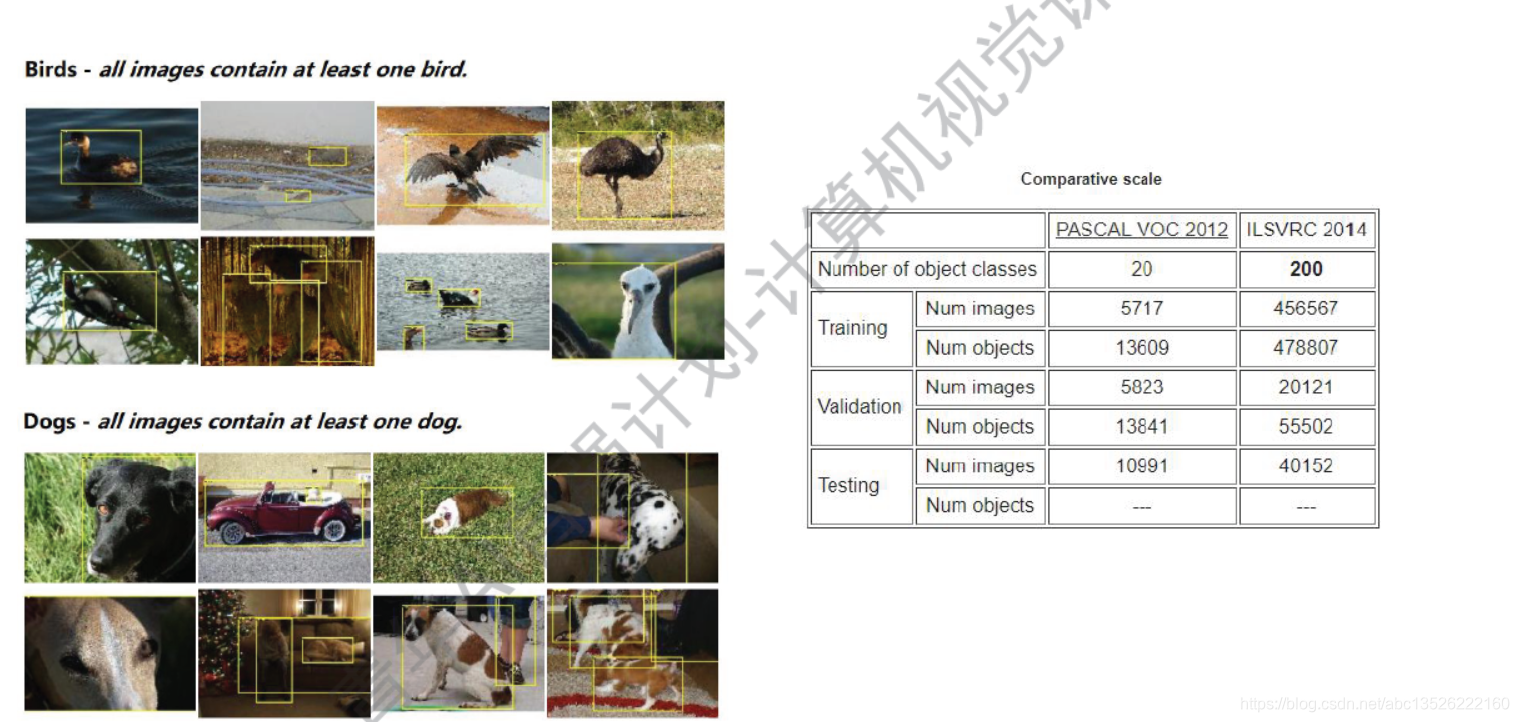
注意: 这个数据集更接近生活,所有的鸟都管叫鸟,所有的狗都是狗,只有一个类别,和Imagenet的区别。类别不很多就只有20类,主要用来做探测工作的。
2.2、R-CNN(Region)-前馈工作流
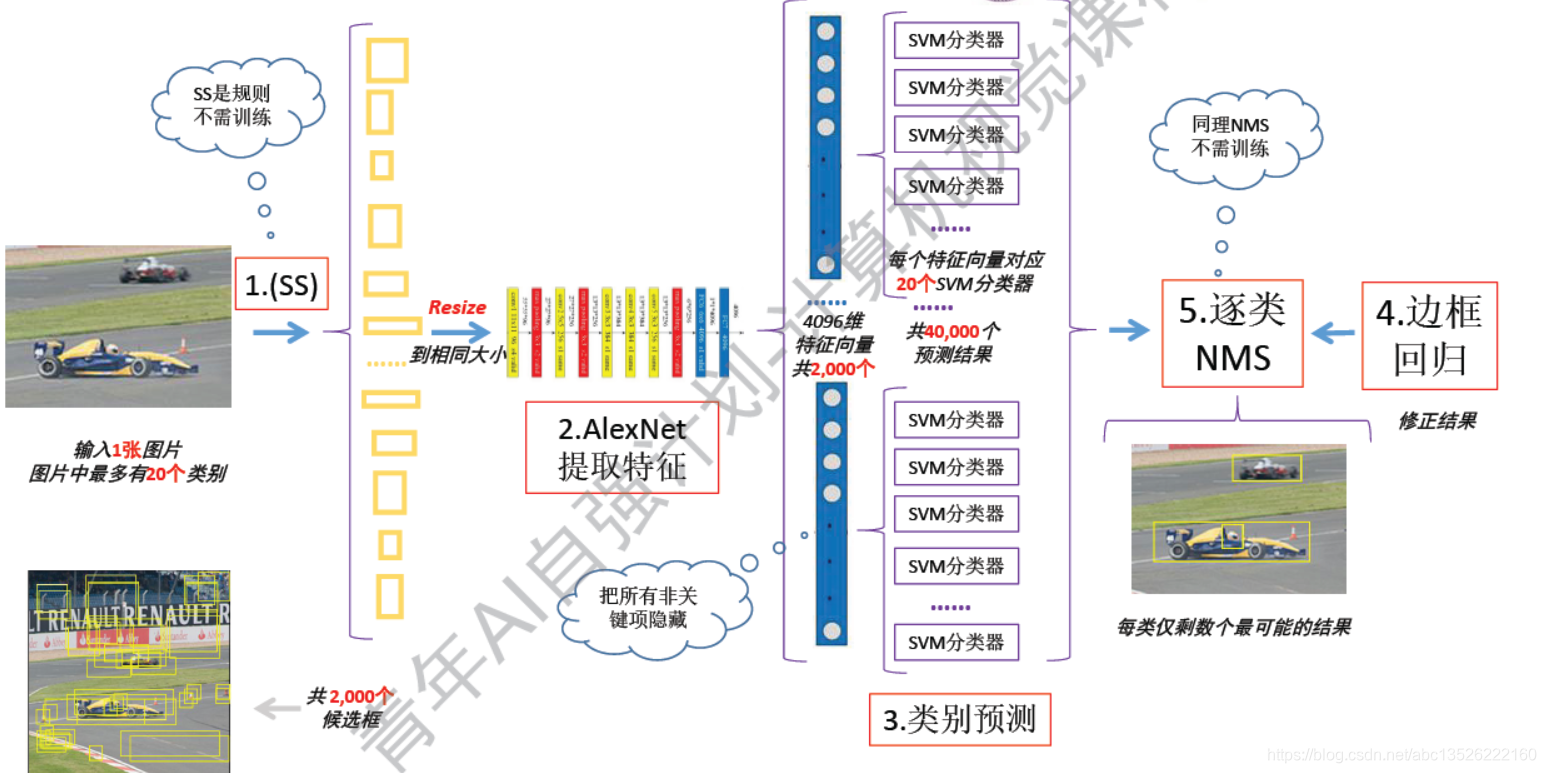
注意: 首先输出一张图片,可能会有20个类别。
- 1、然后先走一个select search,结果会生成好多候选框,大约是2000个候选框。
- 2、然后所有候选框需要缩放到同一个大小,喂入到后面的CNN中(看上图);缩放到一致大小是因为:它的输出要保持一致,才能和后面的网络接起来,这一步是迫不得已的。缩放对特征提取是有伤害的。但是R-CNN就是这么操作的,后面来解决这个问题。
- 3、提取特征使用AlexNet,其最后输出的是一个4096维的向量(卷积核全连接之后)。
- 4、一共有2000个特征向量,每个候选框都会经过一个AlexNet,都会得到一个向量。一张图把这2000个向量存起来!
- 5、用的SVM分类器,典型的二分类。需要用20个2分类的分类器。20类别用20个二分类的分类器。
- 6、每一个特征向量都要过20个分类器,也就是说每提取的一个候选框都要送去判断20次,判断到底是哪一个类别,所以到这里预测结果会非常的多了,就是40000个,一张图片4万个。
- 7、然后做完预测会有一个边框回归,这个边框和ground truth是由差别的,我们使用一个线性回归,把它给解决了。线性回归无非就是对边框做一个平移和伸缩的变化,理论上讲:可以把不太好的候选框缩放到ground truth。
- 8、最后过一个非极大值抑制,然后输出最终的结果,这就是RCNN的前馈工作流,这个看起来时连续的,但其实中间的反向传播不一定回传过来,需要分开训练。
- 9、 SS(select serach):基于规则的方法不需要训练的。
- 10、NMS:也是不需要训练的,然后把这2个非关键项拿走,训练过程下节。
2.3、R-CNN(Region)-如何训练
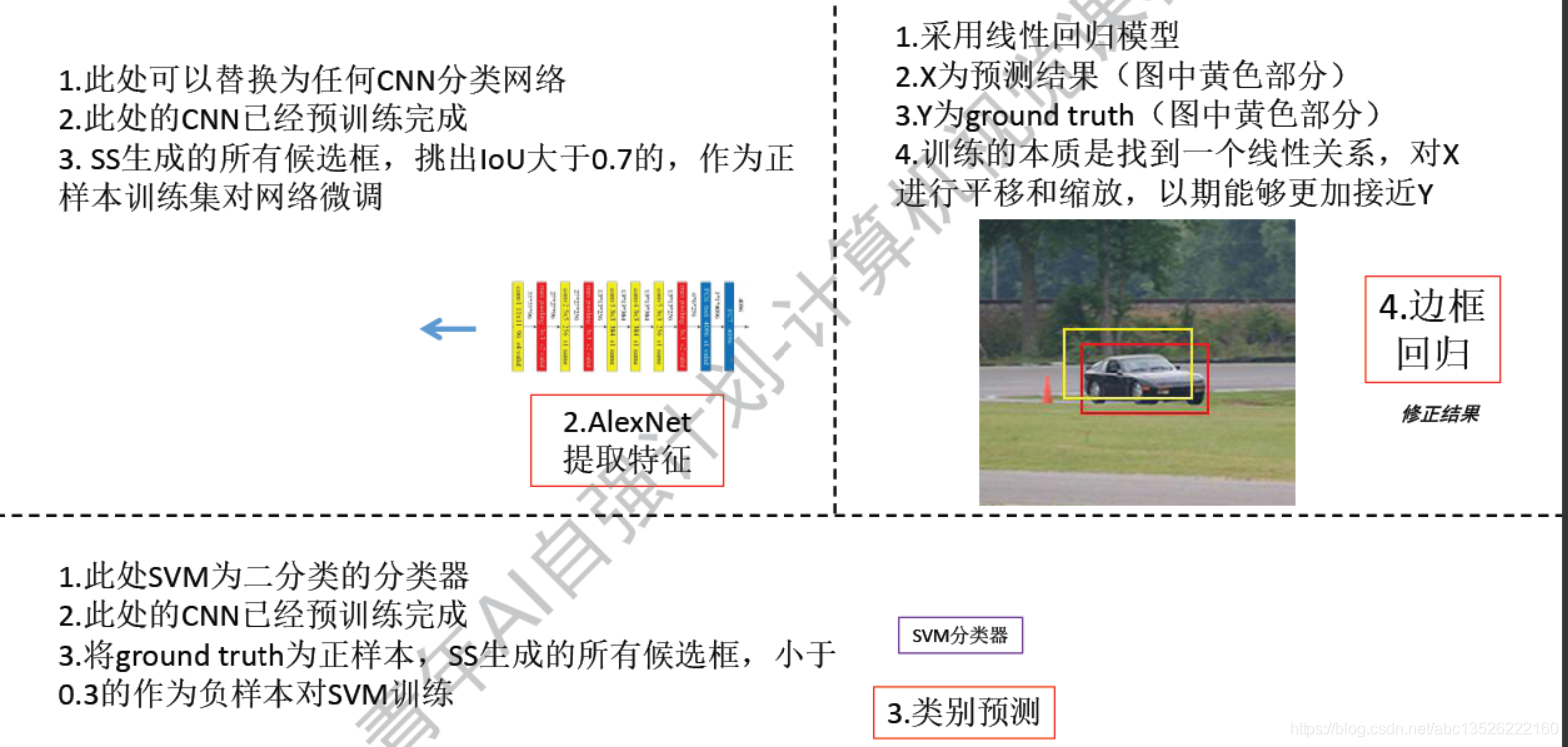
注意: 分成上面3部分。
- 1、中间这个CNN其实是已经预训练好的。你直接想靠这个探测网络训练好是不太可能的,这里可以理解为我们的迁移学习!一般是在pasvcal voc分类数据集或者是imageNet数据集训练好了之后,当做一个组件插入进来的。这里除了AlexNet,可以用Vgg,GoogleNet等等。把它们接入到我们的网络之后,可以进行微调,在我们跑过一些前馈网络之后,会得到一些候选框,这些候选框是比较真实的,符合我们的数据集的,我们把中间跟ground truth 交叠率大于0.7的当做正样本,给它进行训练,然后就可以对网络微调。
- 2、然后是SVM分类器:参考上图。
- 3、边框回归,上图是画出的边框和ground truth是有偏差的,这里只是位置偏差,但是真实情况下有可能尺寸也有一些偏差,有可能比ground truth要大些,讲道理可以用线性回归模型,训练一个好的参数,线性回归模型中也有X,也有Y;X就是我们预测的边框,Y就是ground truth;(目的实现让我们的边框离ground truth越靠越近,如果损失函数到0的话,那么我们的边框就可以到达ground truth重合)
2.4、R-CNN(Region)-开山之作的不足
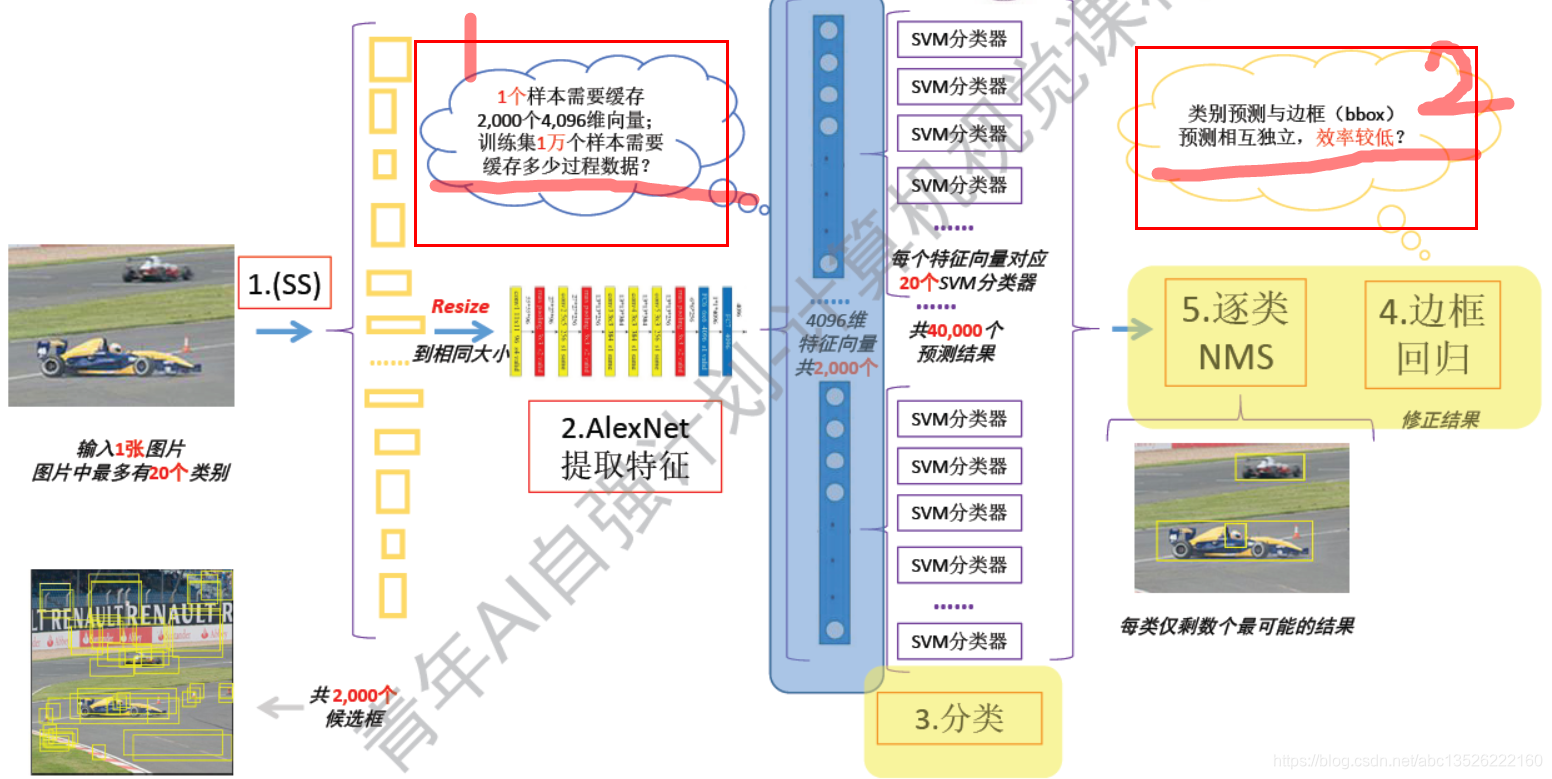
注意: 这一部分数据是中间过程量,不需要留到最后,图中间有介绍,太占用存储。
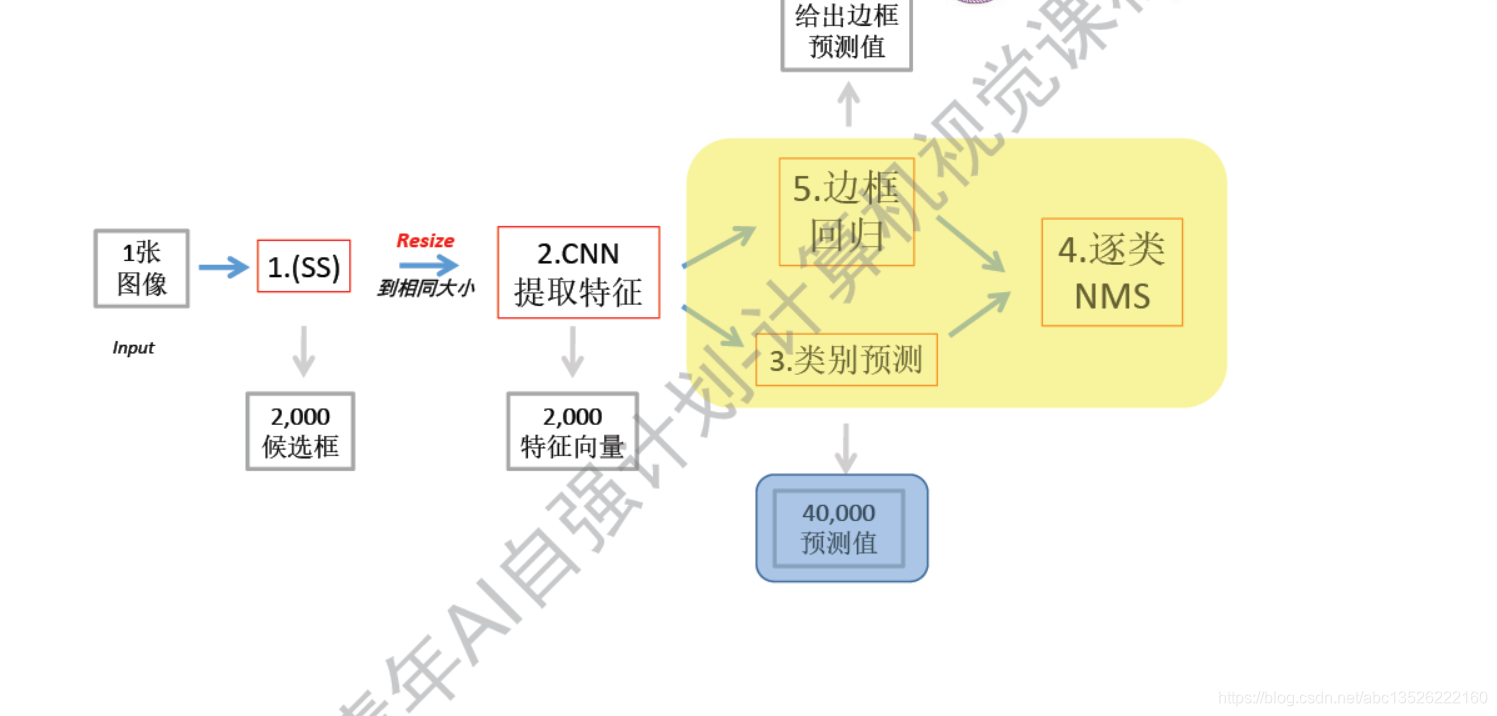
三、Fast R-CNN&Faster R-CNN
3.1、Fast R-CNN 区域映射
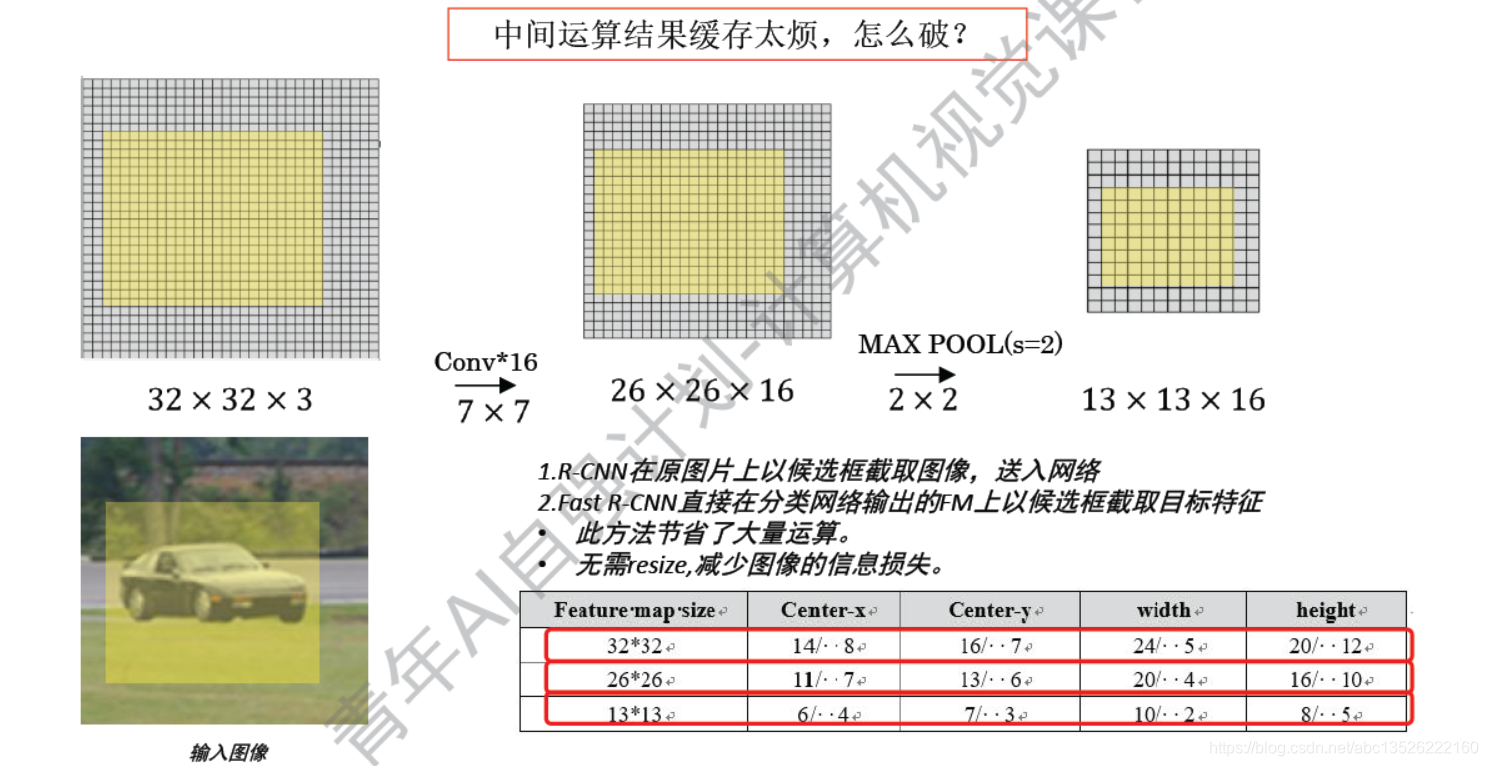
注意: 这里通道数没有画出来,为了下面方便;
- 1、可以发现框的图片经过CNN之后,可以准确找出相关联的映射,如果这样的话,为什么不能再最后的feature map上面滑这个窗呢?如果在最后的feature map中提取这个候选框其实简答了很多,我们就不需要先选择2000个候选框子出来,逐一的过。而是先过一遍CNN,再选择框子。
- 2、存在一个问题,实际情况中不可能一个候选框(下面的图),直接在feature map中截取的候选框,很明显他们的尺寸是不一样的。尺寸不一样没有办法后面往里送?下面是解决方法 Rol pooling
3.2、Fast R-CNN 统一输出特征维度RoI pooling
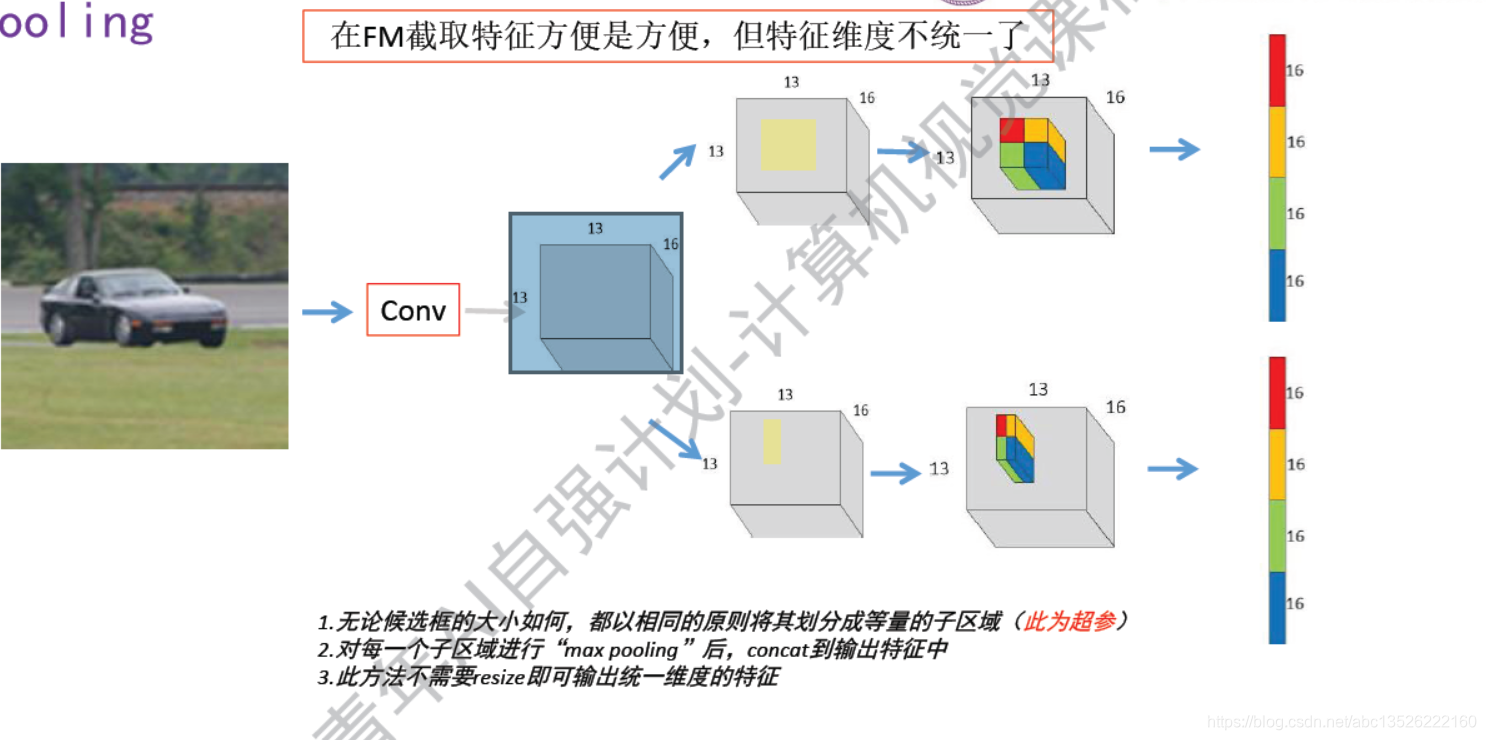
注意: 上图在输出的feature map上面:画出的这么一个区域,也是三维的,有通道数的。
- 1、把候选区域不管是多大多小的,都可以以一定原则等分成固定的子区域,在图中把该区域化成了一个2×2的子区域,一共4个区域。这个也是超参数,现在一般选择为3×3,这里选择2×2为了方便。
- 2、然后每一个子区域做一个max pooling,就是区域里面选择一个最大的数字输出,最终每1层feature map上面只剩下一个数了,把它们拼接起来就变成一个一维向量了,右边画出来的。
- 3 、这就是Rol pooling,除了这一个工作,还有下面的工作;
3.3、Fast R-CNN 升级总结
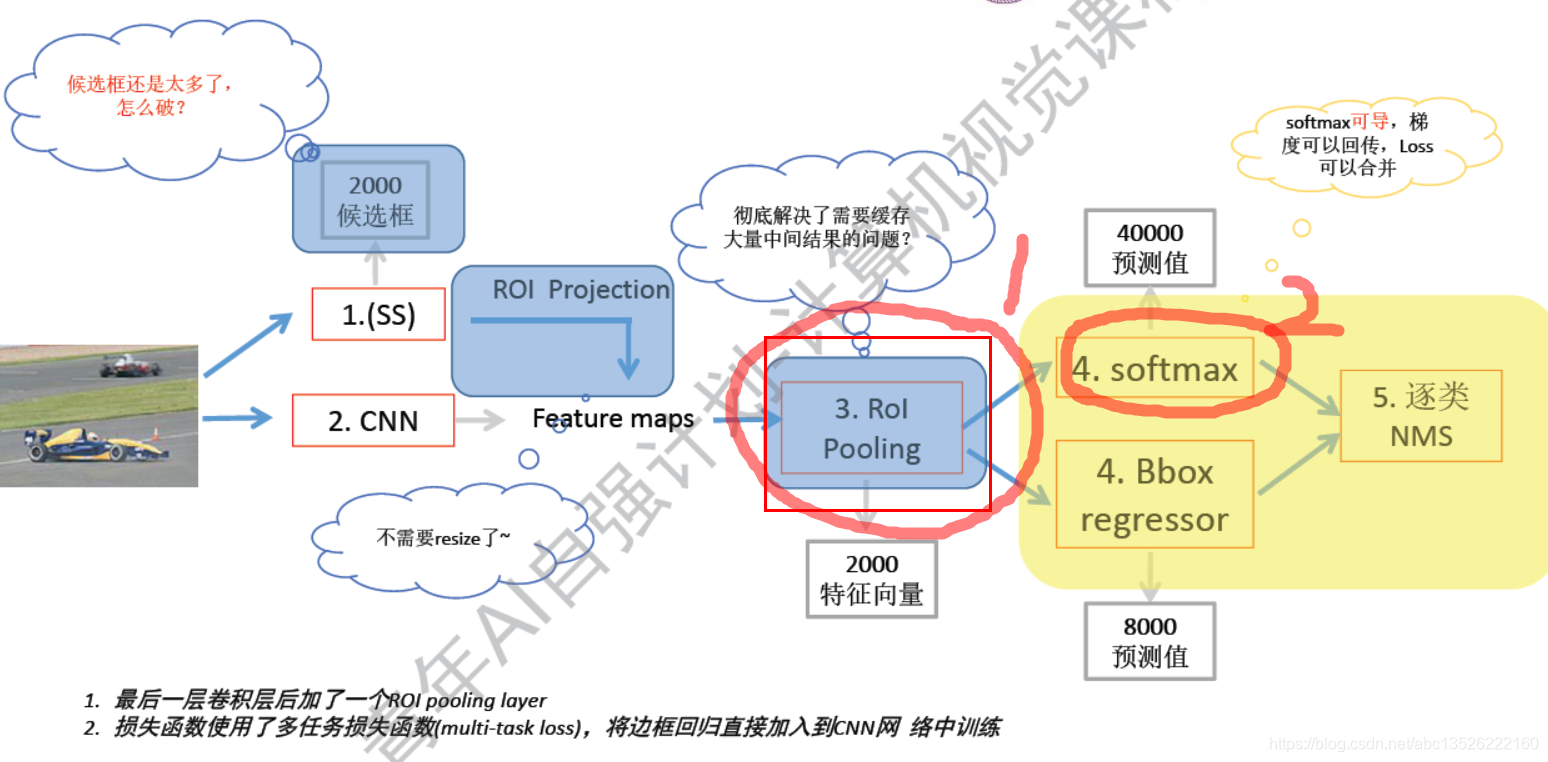
注意: 2方面升级:
- 1、Rol pooling
- 2、换成了Softmax,因为softmax是可导的,所以我们可以把原来拆分开的分类的损失和边框预测的损失合起来,简单的说呢:梯度可以从一个接口(图中右方),2个通道(softmax,Bbox regressor)全部返回回去。训练起来很简单了。
- Rol pooling彻底解决了:缓存大量中间量的问题!,
- 然后用了softmax解决了,梯度回传和loss合并的问题,,
- 还有一个潜藏好处原来分类和边框预测试分开的,相互独立的,只能凭借自己对特征的理解做判断。当损失合在一起的时候,他们有相互作用;简单来说就是他们两个能互相提高精度。
- 还有Rol pooling就不需要resize了,(resize 就是为了保证输出的尺寸是统一的)。
- 但是还存在一个问题:就是候选框太多了,怎么办呢?下面介绍
3.4、Faster R-CNN 创新点
- 注意和上面的进行类比:
- faster RCNN可以简单地看做“区域生成网络(RPN)+fast RCNN“,的系统,用区域生成网络代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
- 1、如何设计区域生成网络
- 2、如何训练区域生成网络
- 3、如何让区域生成网络和fast RCNN网络共享特征提取网络
- 详细可以参考:【目标检测】Faster RCNN算法详解
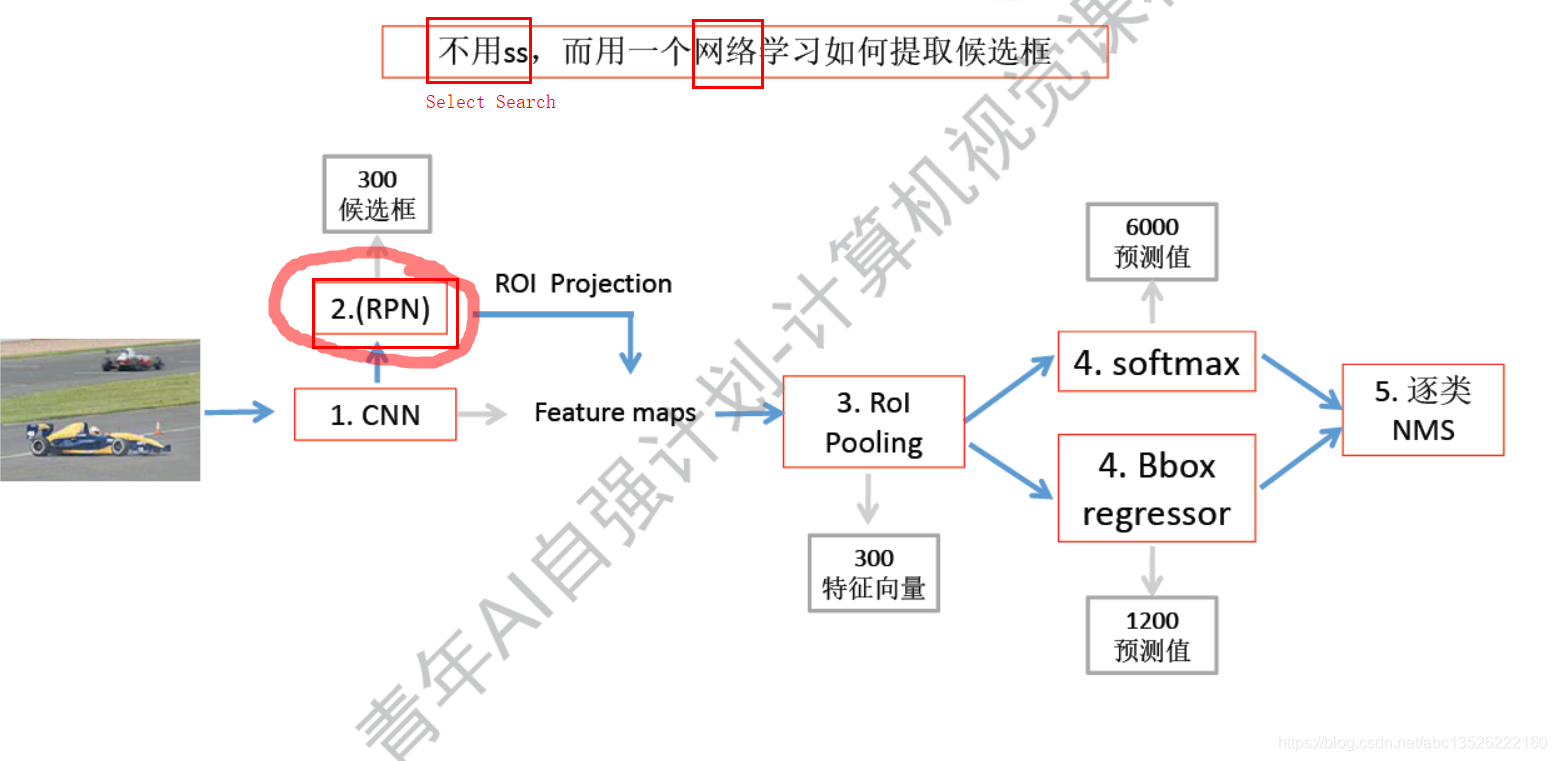
注意: 专门用一个网络结构替换了SS,也是一个神经网络,它是可以学习的。不再是SS的规则模式,显示可以进行学习,可以更加精细化的如何学习提取候选区域!具体的深度细节,之后补充。这里当做一个黑盒子。
3.5、RPN 略解
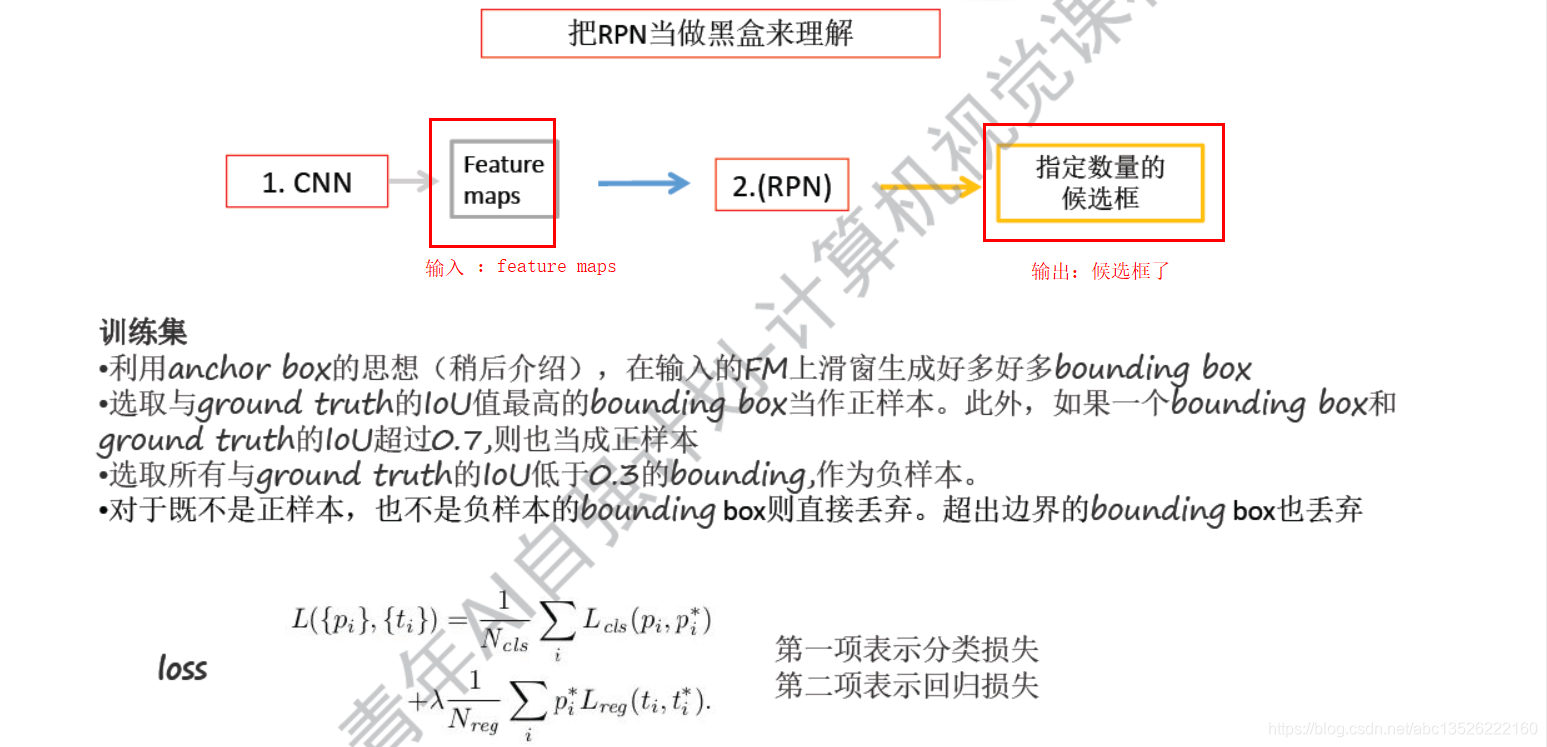
注意: anchor box的思想类似滑窗的方法。参看上图
- 小结:
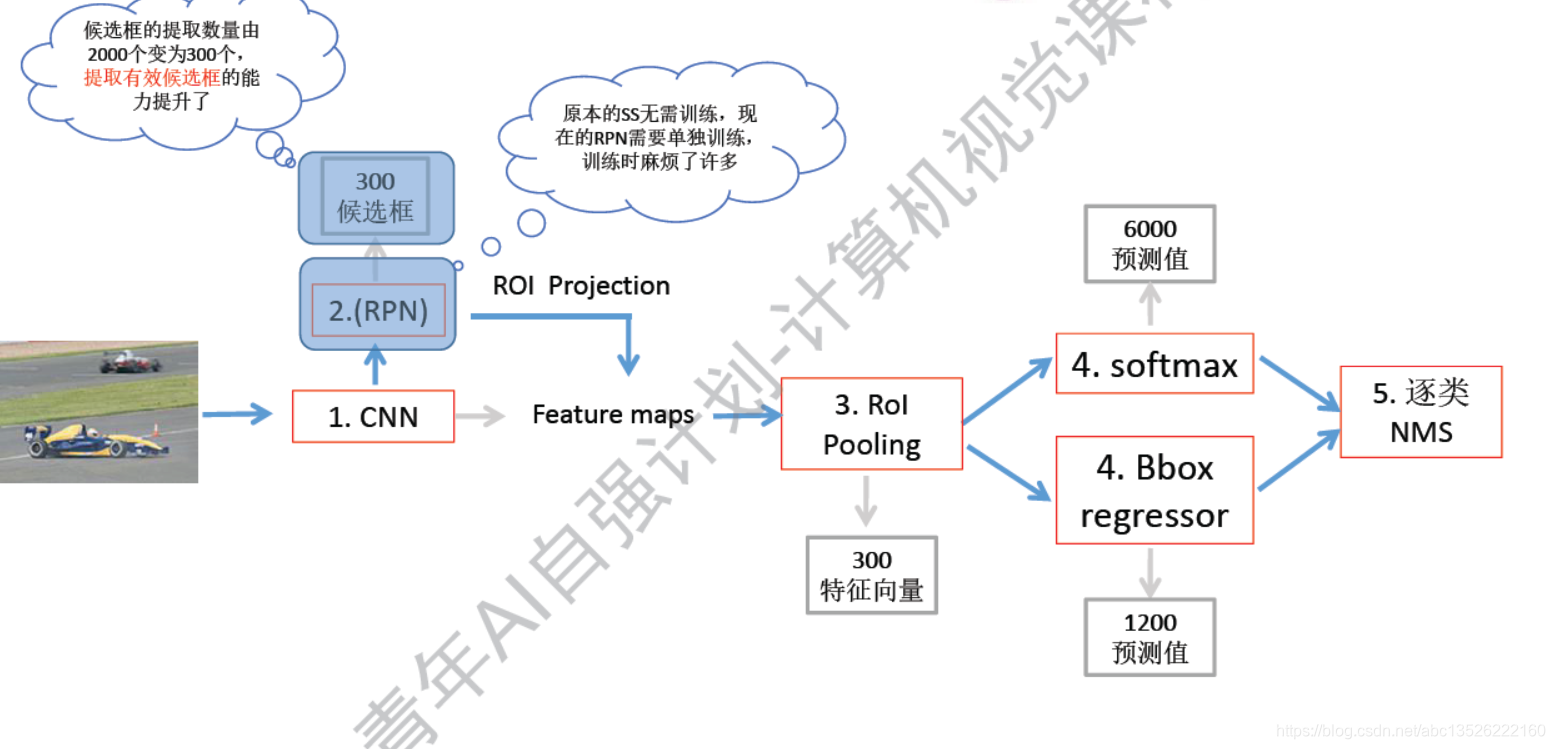
- 注意: RPN网络最大的作用就是:把原来的2000个窗口减成300个窗口了,也是一个实验值,许多实验中总结出来的,选择300就够用了。
- 说明RPN选择窗口的效率是很高的,我滑300个就足够从里面选择一个满意的预测值,但是原来的SS需要2000个候选框。
- 但是有一个麻烦:就是又需要从新训练了,

四、YOLO 分而治之
- end to end 端到端的思想。
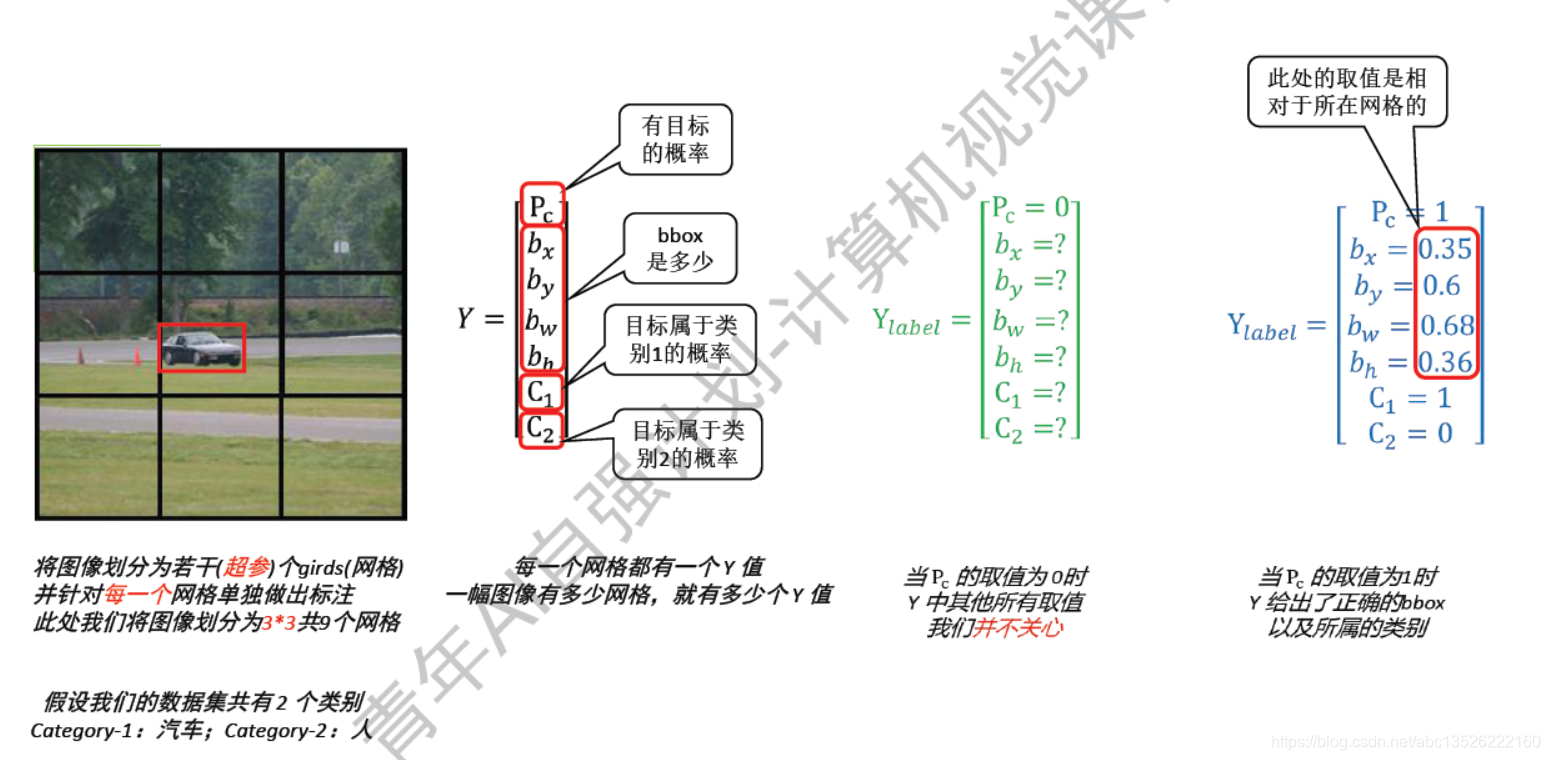
4.1、YOLO = You Only Look Once
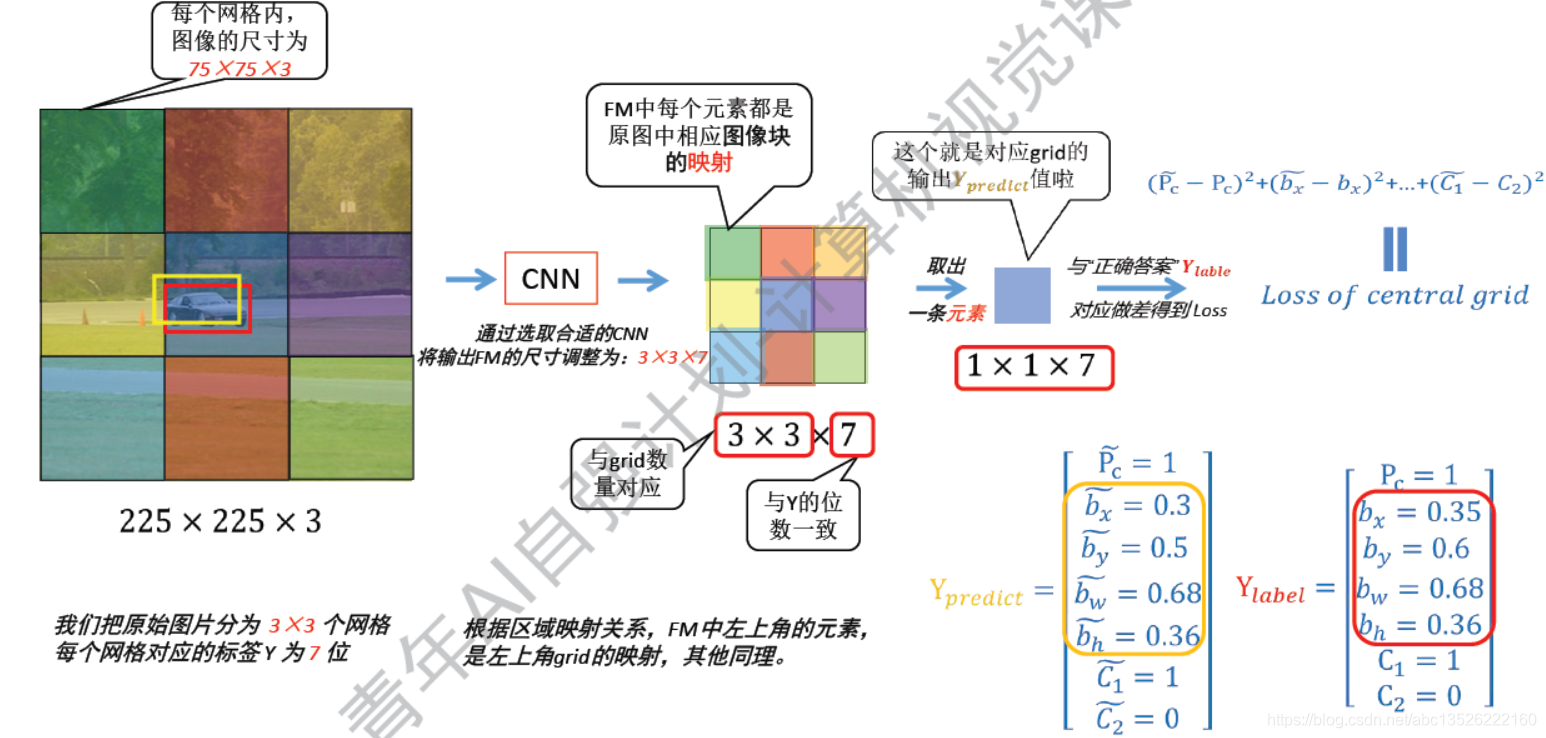
注意: 以中间的网格为例子,预测值 Y p r e d i c t Ypredict Ypredict为中间的,右边为标签值 Y l a b e l Ylabel Ylabel;然后把它们2个直接 L 2 L2 L2范数,也是比较简单的损失函数。这样就解决了YOLO的训练问题!
- 具体的yolov1的细节请参考博客:YOLOV1最全面解读!
四、YOLO 进阶&尾声
4.1、网格中有多个目标:YOLO + anchor box
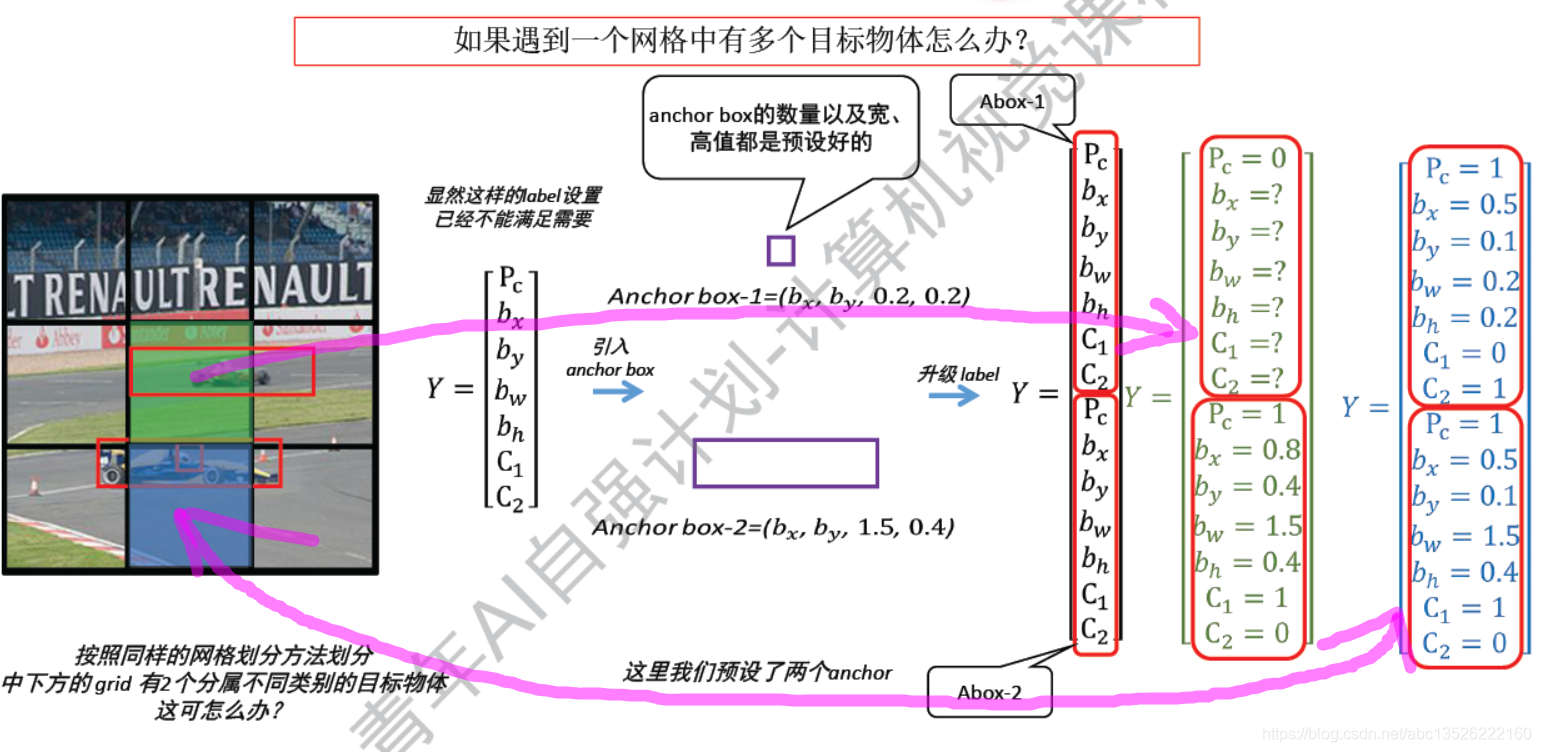
注意: 什么叫做anchor box?
- 就是我预先选择好的尺寸的候选框。
- 具体的yolov1的细节请参考博客:YOLOV1最全面解读!
4.2、横向对比
- arXiv:1809.02165v1 [cs.CV] 6 Sep 2018
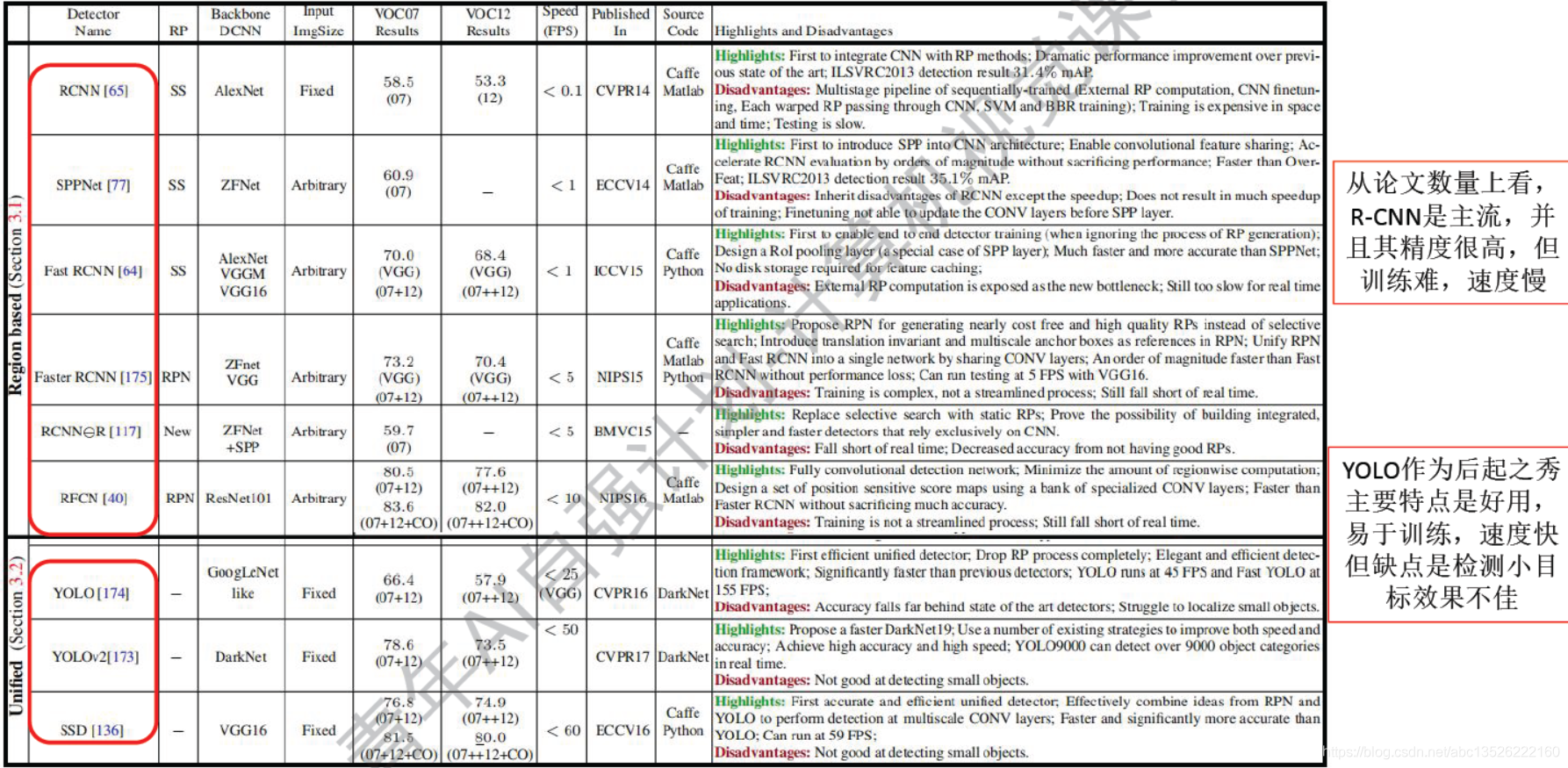
注意: YOLO在2016年发展起来的,作为后起之秀!
参考文献:
- 青年AI自强计划
- YOLOV1最全面解读!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











