










要爬取信息,最关键的是获取一个正确的url,有时候我们在F12看到的请求是不完整的,是掩盖了真实的url后的结果,所以我们一直找不到所需的url,那么如何获取真正的所需url,下面就拿某猪的搜索来做介绍
先打开某猪网站的首页
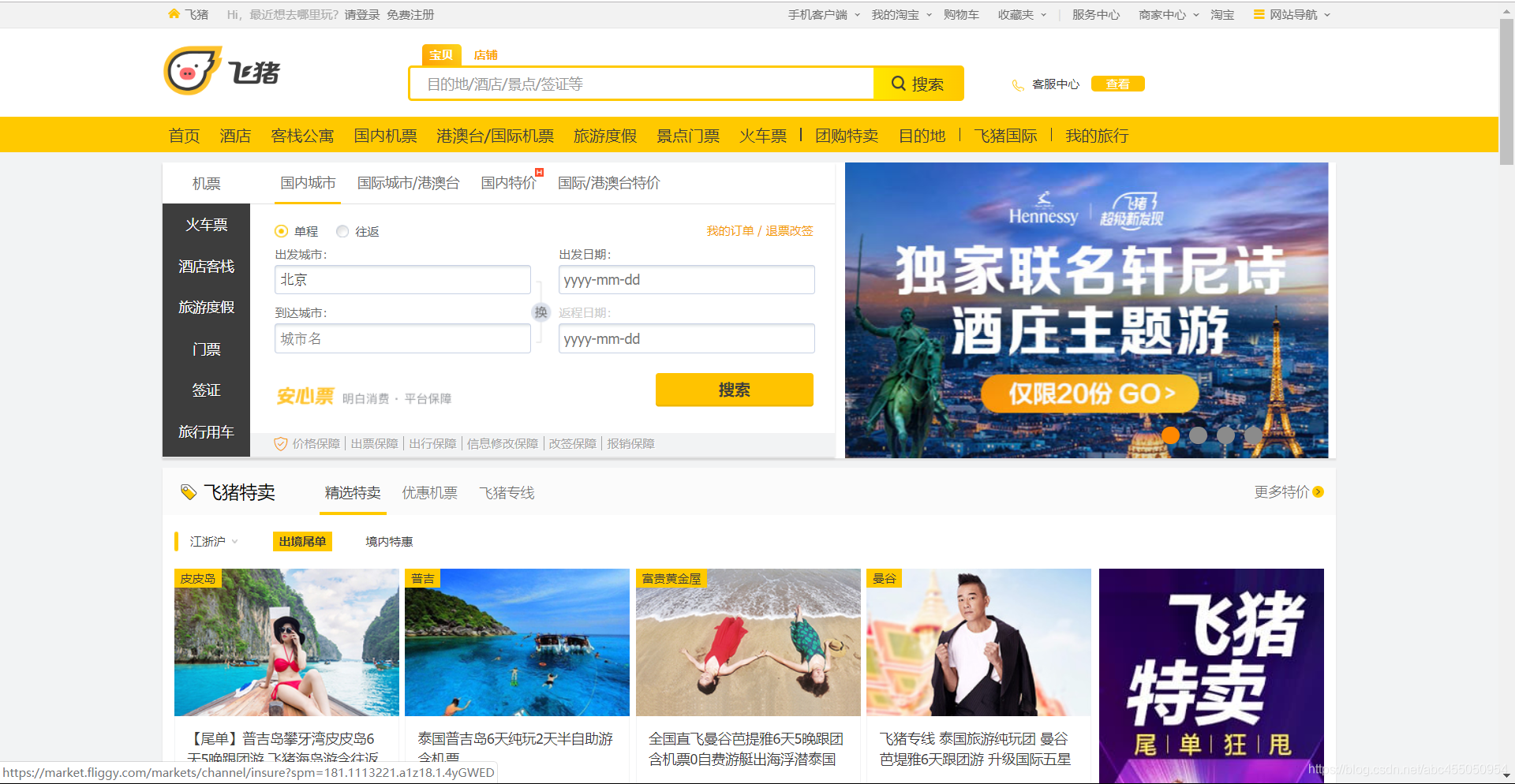
我们想要爬取旅游的信息,那就要通过搜索各个地点,查看其中的月售
通过月售信息来判断这个景点在一段时间内的热度
那么用爬虫的第一步是什么:
获取url
这里的URL是哪个?
当然是搜索的url,一般搜索的信息都是通过json格式返回,那么我们要找到那个请求是返回json(包含搜索结果)的
F12查看
先清空所有请求,然后点击搜索
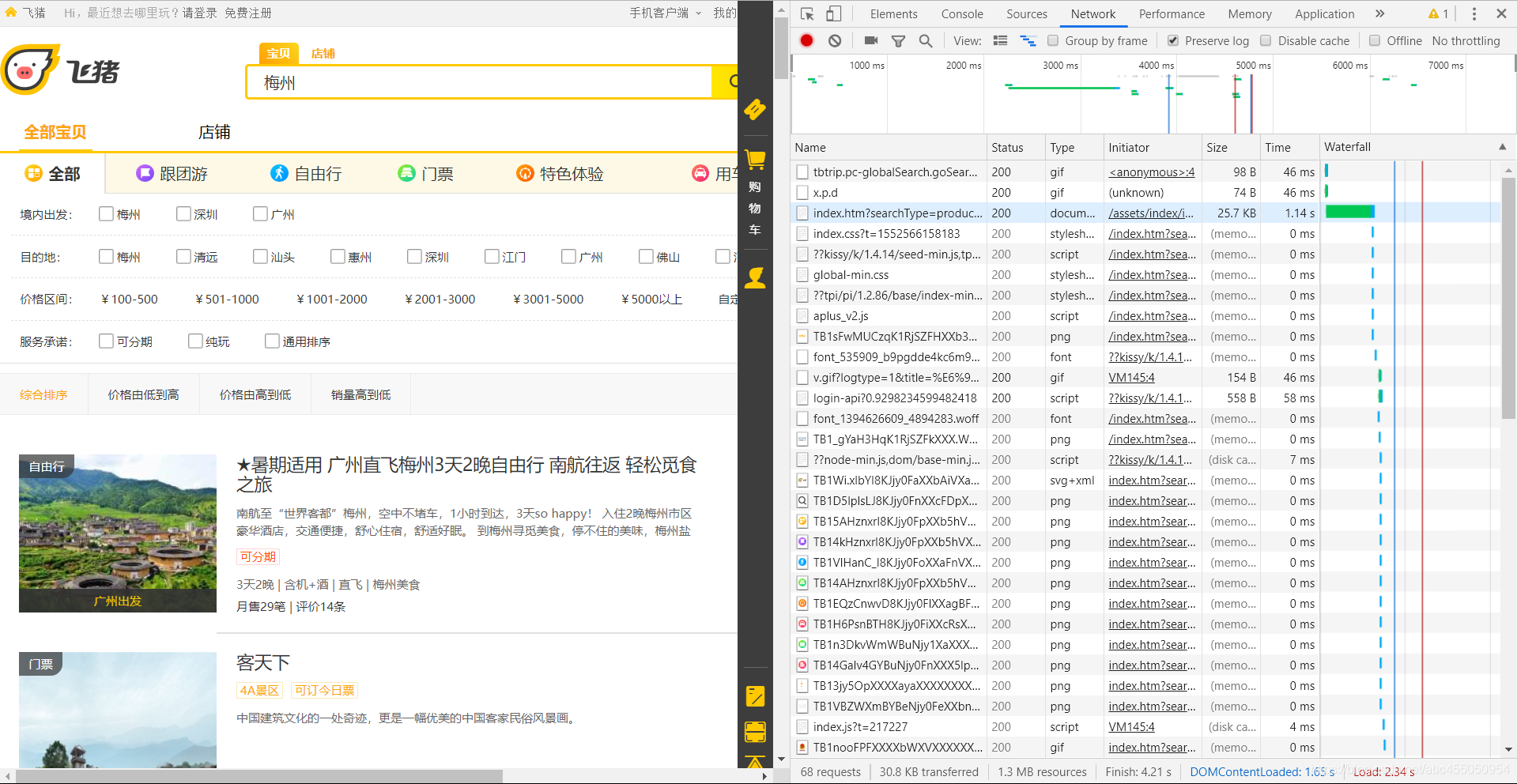
可以看到有一堆数据返回,但是有没有看到我们想要的搜索结果呢?
可以点击一个,然后在右边的请求信息中选择response中查看返回结果
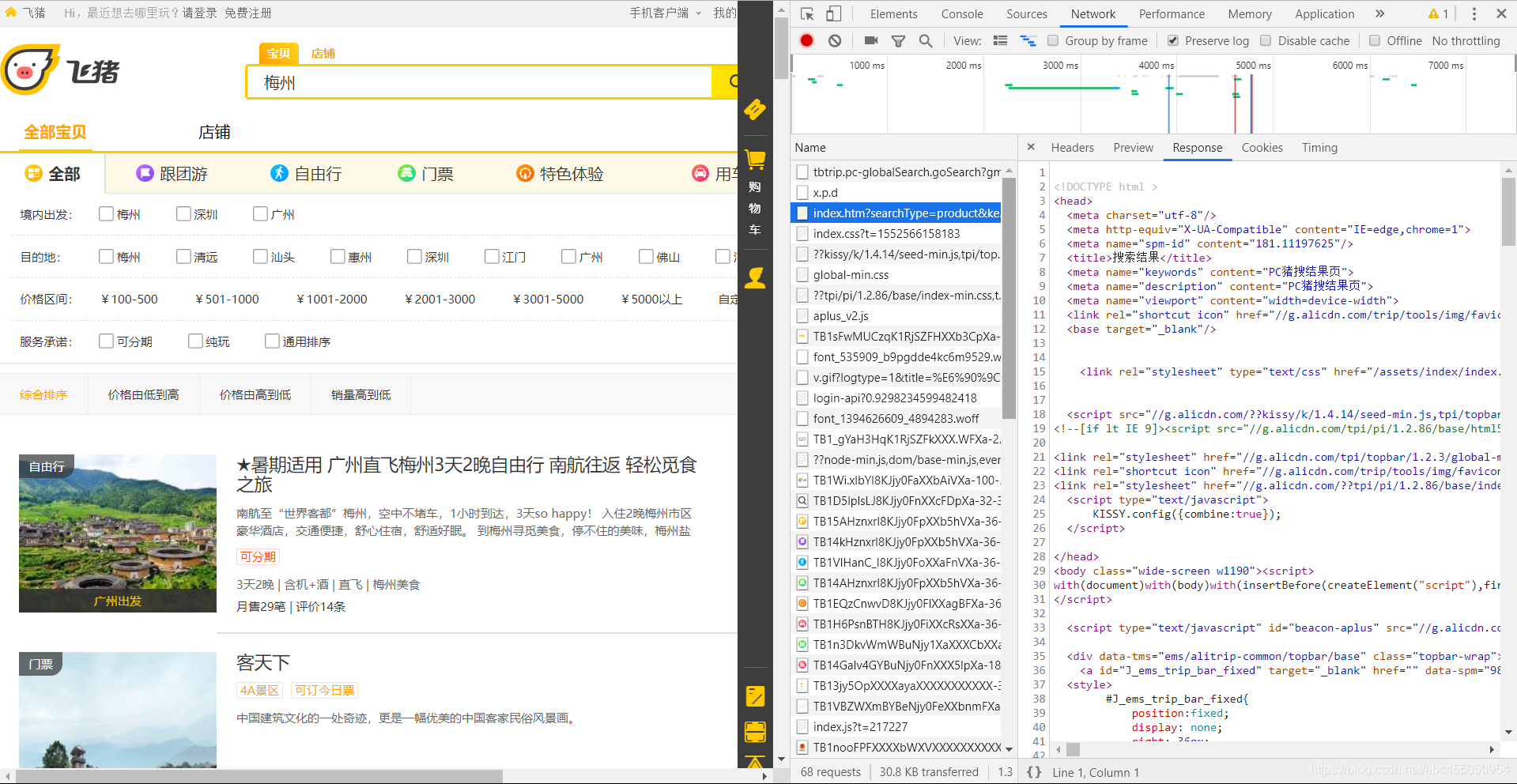
然而经过仔细查看,并没有发现有包含了返回结果的请求
啧啧,那么这个请求估计是被隐藏了,看来要启用Fiddler了。
打开Fiddler
cls清空所有请求
回到某猪首页
输入“湛江”,搜索
我看到了在chrome没看到的一个请求
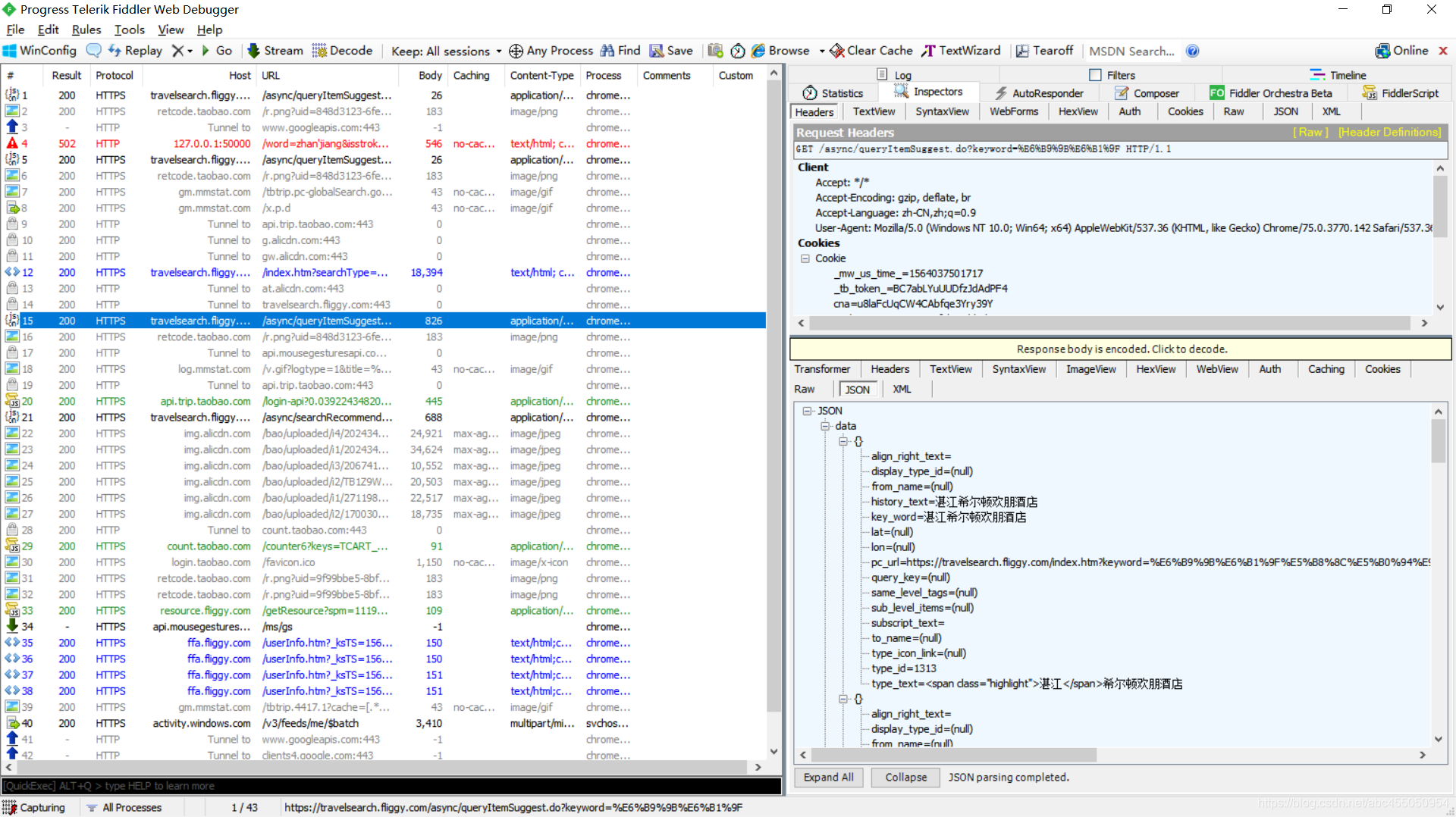
打开,选择json查看
果然,是我们要的搜索结果
好,继续,这个请求返回结果包含了页数说明,但我们可以看到这个请求地址的参数并没有页数(EX:?page= | ?pagenum=)
很简单 ==>
在搜索结果页面拉到最下面
点击第二页(第一页的disable了)
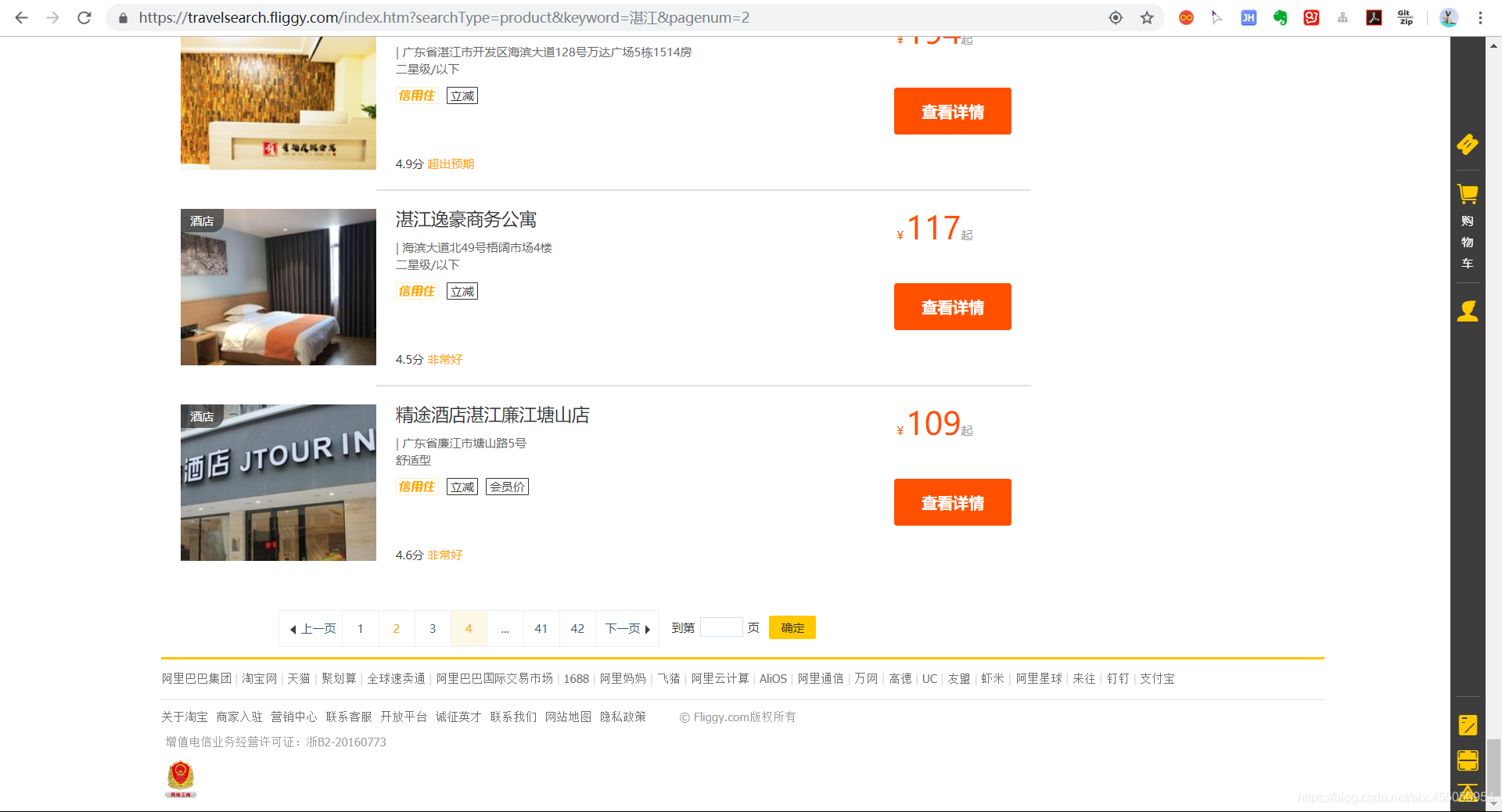
可以看到地址栏的地址直接变了
![]()
同时看到Fiddler中,我们之前看到的那个请求地址也多了一个pagenum参数
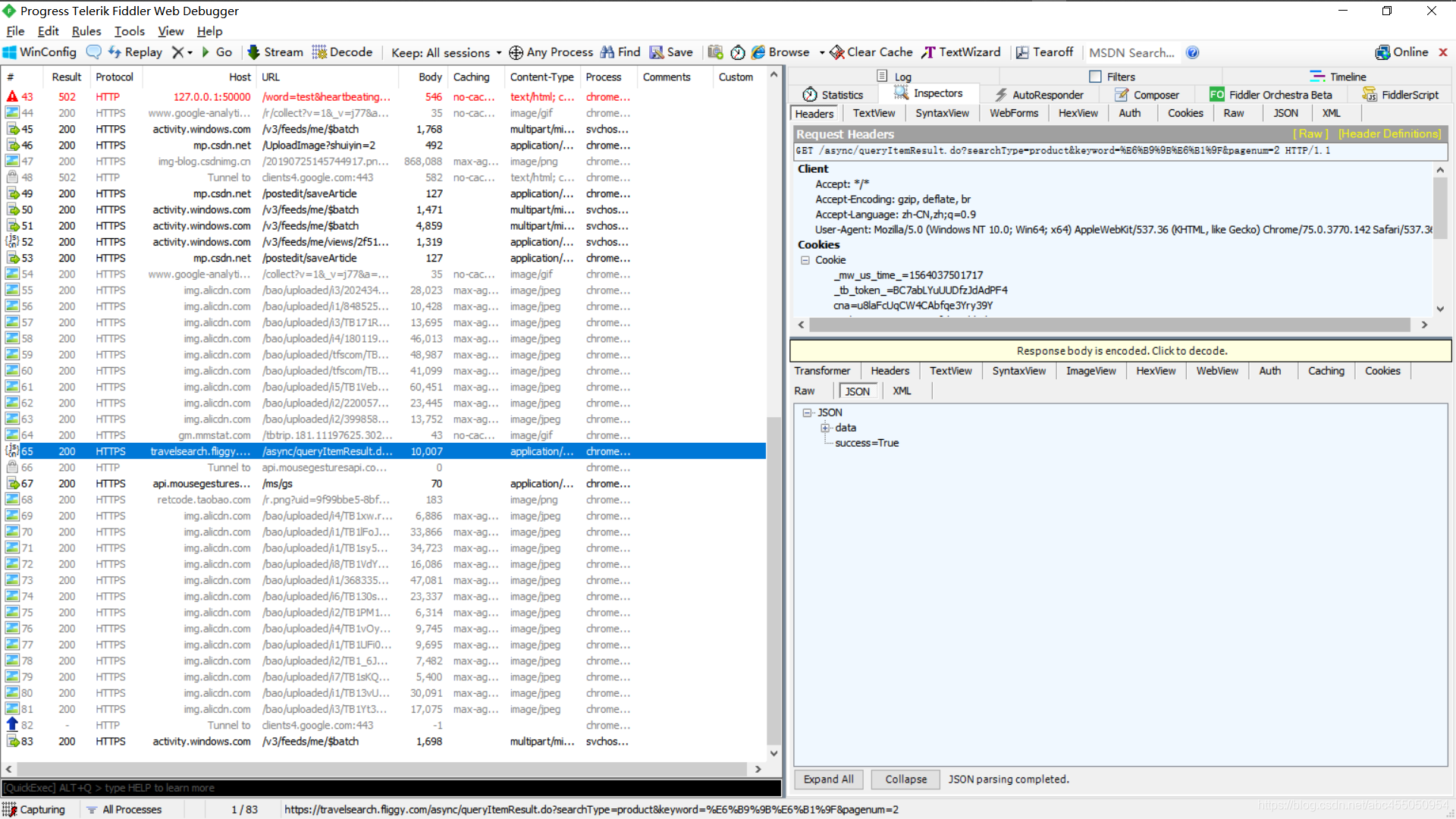
那么我们知道搜索地址为host + url,选择地址,copy=>Just Url
我们把这个网址拿到浏览器用json-handle插件打开
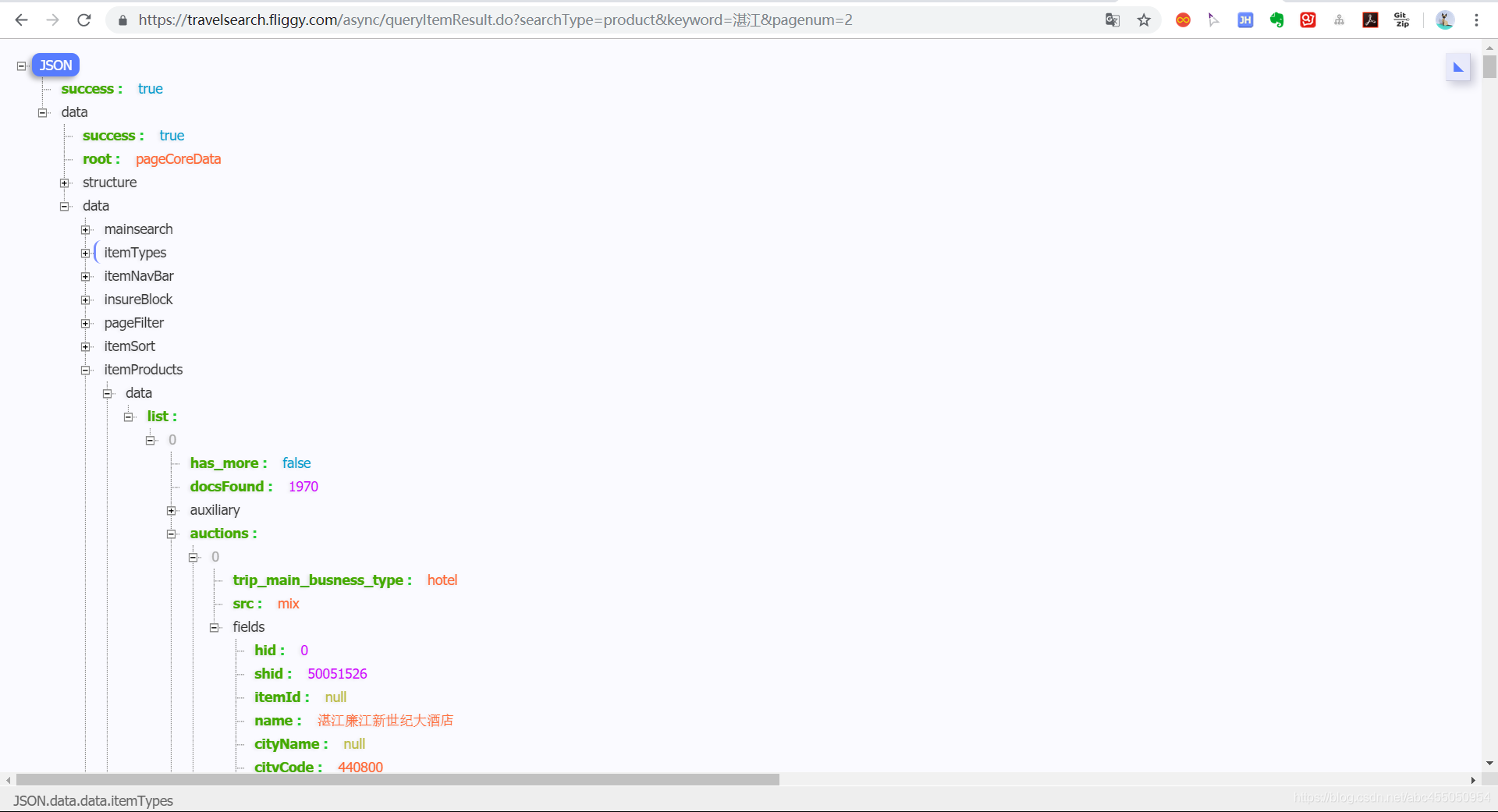
我们可以看到结果很清楚,我们需要拿到的数据就是在auctions中
那么我们修改请求url就可以拿到我们需要的信息了
"https://travelsearch.fliggy.com/async/queryItemResult.do?searchType=product&keyword={}&pagenum={}".format("地点","页码")
PS:获取URL的过程中,有些网站用了缓存,也就是你搜索的东西重复的话,它是不会向服务器请求的,所以有些请求只会出现一次,所以要不断更换参数去请求,总能在一堆请求中找到那个包含了搜索结果的请求信息














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









