







TCP拥塞控制
关键字:
慢开始算法:
避免拥塞算法:
快重传: 如果发送端接收到三个相同number的ack包,则不用等待发送包的的记时器超时,立即重传接收方ack的包。
快恢复:
拥塞控制
网络中的链路容量和交换结点中的缓存和处理机都有着工作的极限,当网络的需求超过它们的工作极限时,就出现了拥塞。拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。常用的方法就是:
- 慢开始、拥塞控制
快重传、快恢复
一切的基础还是慢开始,这种方法的思路是这样的:
-1. 发送方维持一个叫做“拥塞窗口”的变量,该变量和接收端窗口共同决定了发送者的发送窗口;发送窗口等于拥塞窗口和接收窗口当中的小者。
-2. 当主机开始发送数据时,避免一下子将大量字节注入到网络,造成或者增加拥塞,选择发送一个1字节的试探报文;然后拥塞窗口等于 当前拥塞窗口+返回的ack的分节。
-3. 当收到第一个字节的数据的确认后,就发送2个字节的报文;
-4. 若再次收到2个字节的确认,则发送4个字节,依次递增2的指数级;
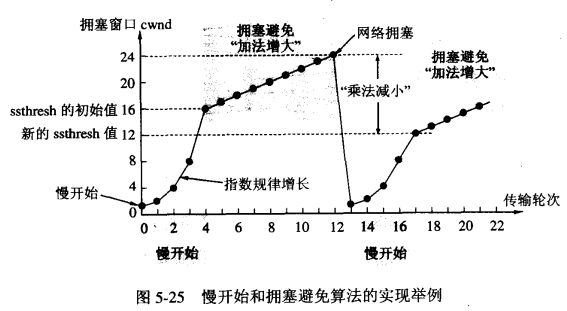
-5. 最后会达到一个提前预设的“慢开始门限”,比如24,即一次发送了24个分组,此时遵循下面的条件判定:
*1. cwnd < ssthresh, 继续使用慢开始算法;
*2. cwnd > ssthresh,停止使用慢开始算法,改用拥塞避免算法;
*3. cwnd = ssthresh,既可以使用慢开始算法,也可以使用拥塞避免算法;
-6. 所谓拥塞避免算法就是:每经过一个往返时间RTT就把发送方的拥塞窗口+1,即让拥塞窗口缓慢地增大,按照线性规律增长;
-7. 当出现网络拥塞,比如丢包时,将慢开始门限设为原先的一半,然后将cwnd设为1,执行慢开始算法(较低的起点,指数级增长);
上述方法的目的是在拥塞发生时循序减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够的时间把队列中积压的分组处理完毕。慢开始和拥塞控制算法常常作为一个整体使用,而快重传和快恢复则是为了减少因为拥塞导致的数据包丢失带来的重传时间,从而避免传递无用的数据到网络。快重传的机制是:
-1. 接收方建立这样的机制,如果一个包丢失(即收到错序的包),则不用延迟确认原则,立即针对收到的后续包继续发送针对该包(丢失包)的重传请求;
-2. 一旦发送方接收到三个一样的确认,就知道该包之后出现了错误,立刻重传该包;而不用等待超时,这就是快重传。
-3. 此时发送方开始执行“快恢复”算法:
*1. 慢开始门限设置成为当前拥塞窗口的一半;
*2. cwnd设为慢开始门限减半后的数值;
*3. 执行拥塞避免算法(高起点,线性增长);
















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









