






如果你在安装的过程中出现了下面的错误,不妨先看看这些安装步骤:
cl: 命令行 error D8021 :无效的数值参数“/Wno-register” error: command 'C:\
windows ERROR: Failed building wheel for pynini
卷完了文本,卷图片,卷完了图片,卷视频,也许语音就是最后一个AI领域卷的最后一个方向。ChatTTS火热了一段时间了,github上的安装说明并不友好,这里做简单的安装记录,让windows也用上ChatTTS。
环境安装
如果在windows 还没有安装Conda的需要先安装一下,因为有些ChatTTS的一些库,需要用Conda来安装,单纯的pip 是搞不定的。而且用Conda 来管理python的虚拟环境也非常的方便。
下载地址:https://docs.anaconda.com/free/miniconda/

下载安装完成以后,需要配置一下参数地址,环境变量:
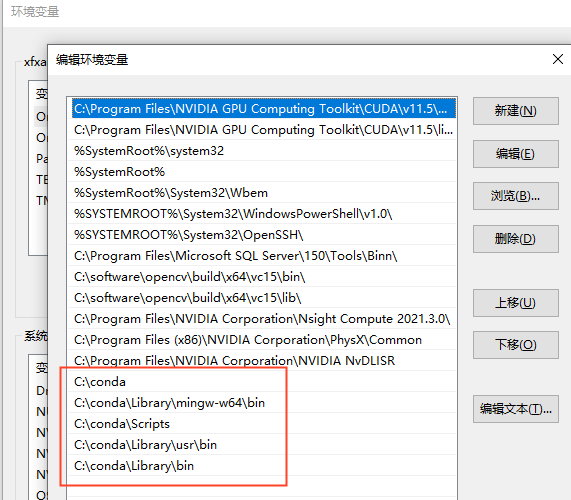
到cmd命令窗口下,试试命令:
conda info
- 1
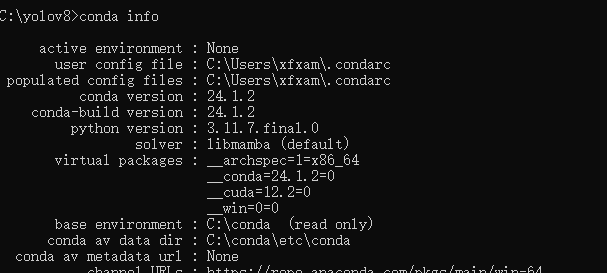
证明我们的配置成功了。
创建虚拟环境并下载模型
为了python的环境不会互相污染,使用python虚拟环境是一种常见的方法,因为每个项目需要的库版本可能不一样而导致了冲突,这里创建一个虚拟环境 命令如下:
conda create -n chattts_env python=3.10
- 1
创建完成以后,进入虚拟环境:
conda activate chattts_env
- 1
(chattts_env) C:\Users\Administrator>
- 1
在运行conda activate 命令的时候如果出现CondaError: Run 'conda init' before 'conda activate' 错误,在打开CMD的时候需要用管理员权限。
注意就是pynini 这个库不容易安装,需要使用conda命令
conda install -c conda-forge pynini=2.1.5
- 1
下载ChatTTS代码:
git clone https://huggingface.co/2Noise/ChatTTS.git
- 1
注意,代码中requirements.txt 需要在添加几个库,requirements.txt 文件的内容如下:
torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 omegaconf~=2.3.0 tqdm einops vector_quantize_pytorch transformers~=4.41.1 vocos IPython WeTextProcessing nemo_text_processing gradio到代码的目录下运行安装命令:
pip install -r requirements.txt很快就能安装完成,需要的环境就已经齐全了。如果你的网络可以直接访问外网,那么可以不用使用特殊方法下载模型,如果你使用的是代理,可以像这样,下把模型下载下来;
import ChatTTS import torch import torchaudio from IPython.display import Audio import os
os.environ[“http_proxy”] = “http://127.0.0.1:1080”
os.environ[“https_proxy”] = “http://127.0.0.1:1080”
chat = ChatTTS.Chat()
chat.load_models(compile=False) # Set to True for better performance
# Define the text input for inference (Support Batching)
texts = [
“So we found being competitive and collaborative was a huge way of staying motivated towards our goals, so one person to call when you fall off, one person who gets you back on then one person to actually do the activity with.”,
]
# Perform inference and play the generated audio
wavs = chat.infer(texts)
这里没什么特别的,就是为了用代理,下把模型下载下来。
运行WebUI
在代码的目录下有一个webui.py的文件,运行webui.py,启动web程序:
(chattts_env) D:\ChatTTS-main>python webui.py
loading ChatTTS model...
INFO:ChatTTS.core:Load from cache: C:\Users\Administrator/.cache/huggingface\hub/models--2Noise--ChatTTS/snapshots\d7474137acb4f988874e5d57ad88d81bcb7e10b6
WARNING:ChatTTS.utils.gpu_utils:No GPU found, use CPU instead
INFO:ChatTTS.core:use cpu
INFO:ChatTTS.core:vocos loaded.
INFO:ChatTTS.core:dvae loaded.
INFO:httpx:HTTP Request: GET https://api.gradio.app/pkg-version "HTTP/1.1 200 OK"
INFO:ChatTTS.core:gpt loaded.
INFO:ChatTTS.core:decoder loaded.
INFO:ChatTTS.core:tokenizer loaded.
INFO:ChatTTS.core:All initialized.
INFO:httpx:HTTP Request: GET https://checkip.amazonaws.com/ "HTTP/1.1 200 "
Running on local URL: http://0.0.0.0:8080
INFO:httpx:HTTP Request: GET http://localhost:8080/startup-events "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: HEAD http://localhost:8080/ "HTTP/1.1 200 OK"
To create a public link, set </span><span class="token assign-left variable">share</span><span class="token operator">=</span>True<span class="token variable"> in </span>launch<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token variable">.
INFO:matplotlib.font_manager:generated new fontManager
INFO:ChatTTS.core:All initialized.
16%|█████████████ | 62/384 [00:05<00:31, 10.34it/s]
INFO:ChatTTS.core:All initialized.
23%|██████████████████▏ | 471/2048 [00:37<02:04, 12.63it/s]
访问http://localhost:8080/
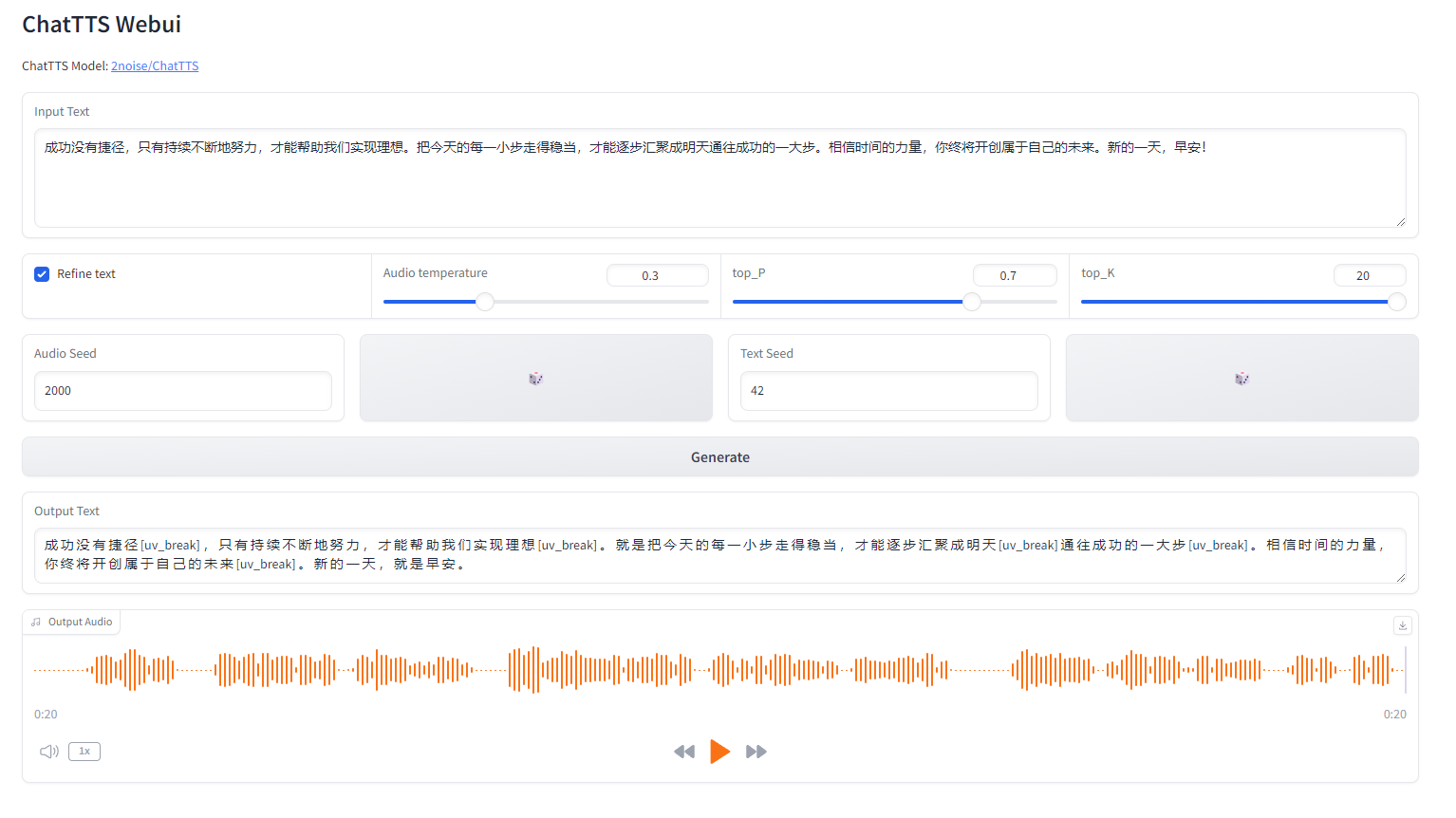 可以试试,这开源效果还是很不错的,几个参数也可以调一调,Audio Seed 比较小的是女声,比较大的是男声。
可以试试,这开源效果还是很不错的,几个参数也可以调一调,Audio Seed 比较小的是女声,比较大的是男声。















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









